# Keras:2.1 回归神经网络
- Keras21 回归神经网络 Regressor
- 数据准备
- 用keras构建神经网络
- 激活模型
- 训练training
- 检验模型
- 可视化结果
- 总代码
Keras:2.1 回归神经网络 Regressor
导入必要的架包
import numpy as np
np.random.seed(1337) # for reproducibility
from keras.models import Sequential # 好像keras中有两种model,其中Sequential是一种简单叠加的简单版。另一种是Model,需要自己详细定义。
from keras.layers import Dense
import matplotlib.pyplot as plt # 可视化模块知识点 : seed( ) 用于指定随机数生成时所用算法开始的整数值,如果使用相同的seed( )值,则每次生成的随即数都相同,如果不设置这个值,则系统根据时间来自己选择这个值,此时每次生成的随机数因时间差异而不同。 也就是说,作者想把每次的随机数设置成一样的,这样每个人的实验结果都相同,很有成就感。
1 数据准备
导入必要的架包
import numpy as np
np.random.seed(1337) # for reproducibility
from keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt老规矩,造点数据~
X = np.linspace(-1, 1, 200)
np.random.shuffle(X) # randomize the data
Y = 0.5 * X + 2 + np.random.normal(0, 0.05, (200, )) # 这是答案~
# plot data
plt.scatter(X, Y)
plt.show()
X_train, Y_train = X[:160], Y[:160] # first 160 data points
X_test, Y_test = X[160:], Y[160:] # last 40 data points
2 用keras构建神经网络
首先用 Sequential 建立 model, 再用 model.add 添加神经层,添加的是 Dense (全连接)神经层。
model = Sequential()
model.add(Dense(output_dim=1, input_dim=1))定义神经层的时候参数有两个,一个是输入数据和输出数据的维度,本代码的例子中 x 和 y 是一维的。
如果需要添加下一个神经层的时候,不用再定义输入的纬度,因为它默认就把前一层的输出作为当前层的输入。在这个例子里,只需要一层就够了。
3 激活模型
接下来要激活神经网络,上一步只是定义模型。
参数中,误差函数用的是 mse 均方误差;优化器用的是 sgd 随机梯度下降法。
# choose loss function and optimizing method
model.compile(loss='mse', optimizer='sgd')以上三行就构建好了一个神经网络,它比 Tensorflow 要少了很多代码,很简单。
4 训练training
训练的时候用 model.train_on_batch 一批一批的训练 X_train, Y_train。默认的返回值是 cost,每100步输出一下结果。
# training
print('Training -----------')
for step in range(301):
cost = model.train_on_batch(X_train, Y_train)
if step % 100 == 0:
print('train cost: ', cost)
结果:
"""
Training -----------
train cost: 4.111329555511475
train cost: 0.08777070790529251
train cost: 0.007415373809635639
train cost: 0.003544030711054802
"""5 检验模型
用到的函数是 model.evaluate(评估),输入测试集的x和y(X_test,Y_test), 输出 cost,weights 和 biases。
其中 weights 和 biases 是取在模型的第一层 model.layers[0] 学习到的参数。从学习到的结果你可以看到, weights 比较接近0.5,bias 接近 2。
# test
print('\nTesting ------------')
cost = model.evaluate(X_test, Y_test, batch_size=40)
print('test cost:', cost)
W, b = model.layers[0].get_weights()
print('Weights=', W, '\nbiases=', b)
结果:
"""
Testing ------------
40/40 [==============================] - 0s
test cost: 0.004269329831
Weights= [[ 0.54246825]]
biases= [ 2.00056005]
"""
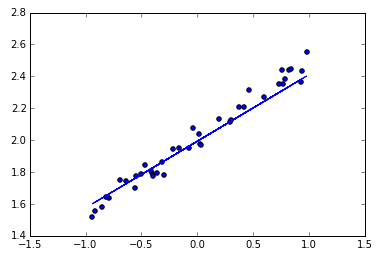
6 可视化结果
最后可以画出预测结果,与测试集的值进行对比。
# plotting the prediction
Y_pred = model.predict(X_test)
plt.scatter(X_test, Y_test)
plt.plot(X_test, Y_pred)
plt.show()
7 总代码Σ( ° △ °|||)︴:
import numpy as np
np.random.seed(1337)
# 作者想把每次的随机数设置成一样的,这样每个人的实验结果都相同,很有成就感。
from keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt # 可视化的模块
# 1 数据准备,造点数据
X = np.linspace(-1,1,200) # 200个有序数字
np.random.shuffle(X) # 把X顺序打乱
Y = 0.5 * X + 2 + np.random.normal(0,0.05,(200,)) # 这是“答案” 看看keras能不能找到“0.5和2"
## 画出数据
plt.scatter(X,Y)
plt.show()
## 把数据分为,训练和测试两部分
X_train,Y_train = X[:160],Y[:160]
X_test,Y_test = X[160:],Y[160:]
# 2 用keras构建神经网络,这次就一层,而且就一个神经元,有点搓啊~
model = Sequential() # 建立模型
model.add(Dense(input_dim=1,output_dim=1)) # 添加一层,一个输入一个输出
# 3 激活模型
model.compile(loss='mse',optimizer='sgd')
## 这样2和3 一共三行代码就实现了,所以比tensorflow简单多了
# 4 训练模型
print("----------------------training--------------------------")
for step in range(301):
cost = model.train_on_batch(X_train,Y_train)
if step % 100 == 0:
print("train cost:",cost)
# 5 检验模型
print("--------------testing-------------------")
cost = model.evaluate(X_test,Y_test,batch_size=40)
print("test cost:",cost)
W,b = model.layers[0].get_weights()
print("Weights:",W,"\nbaise:",b)
# 6 结果可视化
Y_pred = model.predict(X_test)
plt.scatter(X_test,Y_test)
plt.plot(X_test,Y_pred)
plt.show()