Redis深度历险记(一)基础
文章目录
- install
- 基础数据结构
- string
- set
- 引号
- exists
- list
- quicklist
- rpush rpop lpop lpush
- lindex lrange ltrim llen
- blpop brpop
- hash
- set
- zset
- zrange zrevrange
- zcard
- 限流
- 滑动窗口
- HyperLogLog
- Bloom Filter
- GeoHash
- keys vs scan
- rehash
- 大key的查找
本篇是对"Redis深度历险"的学习与思考
Remote dictionary service
install
书中提供了docker,源代码,直接安装三种方式,其他两种我都玩过,现在说下源代码安装.
书中给出的貌似2.8版本,但是现在已经是6.0版本了,所以我执行的命令和 书中略有不同.
关于6.0的新特性还没去仔细了解,貌似加入了多线程和ACL
# 这个指令和书中不一样
git clone https://github.com/antirez/redis.git
cd redis
# 速度巨慢,我吃了饭回来才好,看来源码安装被抛弃是有道理的
make
# 书中并没有make test这一步,我是在执行make后按照提示执行了下一步,但我执行后报了两次Error,心塞
make test
cd src
./redis-server --daemonize yes
基础数据结构
书中讲到有5种,这应该是老版本的了
string
Redis的字符串是动态字符串…内部结构的实现类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配.
如果这样的话不知道Redis能否预先制定value的capacity从而进一步减少重分配
字符串最大长度为512MB
这些指令对于其他数据结构有些也是适用的
set
引号
[qbit@manjaro src]$ ./redis-cli
127.0.0.1:6379> set Qbit qqq
OK
127.0.0.1:6379> get Qbit
"qqq"
127.0.0.1:6379> set Qbit "qqq"
OK
127.0.0.1:6379> get Qbit
"qqq"
127.0.0.1:6379> set Qbit "qqq
Invalid argument(s)
127.0.0.1:6379> set Qbit "thiis"whatisaid"1"
Invalid argument(s)
127.0.0.1:6379> set "Qbit" m
OK
127.0.0.1:6379> get Qbit
"m"
set Qb"it m
Invalid argument(s)
通过上面例子可以看出,如果key和value被双引号引起来,和没有双引号是一个效果.如果双引号不匹配或者出现其他位置就是非法的了
exists
官网说明
判断是否存在,后面可以接上n个key,然后返回存在的key的个数,对于最普通的情况(也就是3.0之前的版本),下面是官方例子帮助理解
redis> SET key1 "Hello"
"OK"
redis> EXISTS key1
(integer) 1
redis> EXISTS nosuchkey
(integer) 0
redis> SET key2 "World"
"OK"
redis> EXISTS key1 key2 nosuchkey
(integer) 2
list
Redis的列表相当于Java语言里面的LinkedList
quicklist
redis内部做了一些优化,当存储数据较少的时候倾向于使用ziplist,另外这两个会结合时候,后面再具体说
rpush rpop lpop lpush
xpush时可以接多个参数,依次push,一般优先用r
lindex lrange ltrim llen
看名字大概知道什么意思,具体适用到时候再参见官网
blpop brpop
书中也介绍了list也可以作为一个简单的MQ,
需要注意的一点是消费者在pop无法获得诗句的时候需要sleep一下,这样同时减轻自己和Redis的CPU消耗
更好的方案是使用blpop brpop,其中b是blocking的意思,但是这里还有一个坑,即使Redis的服务端对于长时间空闲的链接可能断开
hash
这里面有很多x开头的操作对应了redis本身的一些操作,例如hincrby对应incr
set
zset
这是一个带排序的set,排序规则就是分数,对应的,会有各种z开头的操作,这里讲下常用的.
zrange zrevrange
分别升序和降序输出,一般后面接0 -1表示从第0个到倒数第一个都输出
zcard
相当于count
限流
滑动窗口
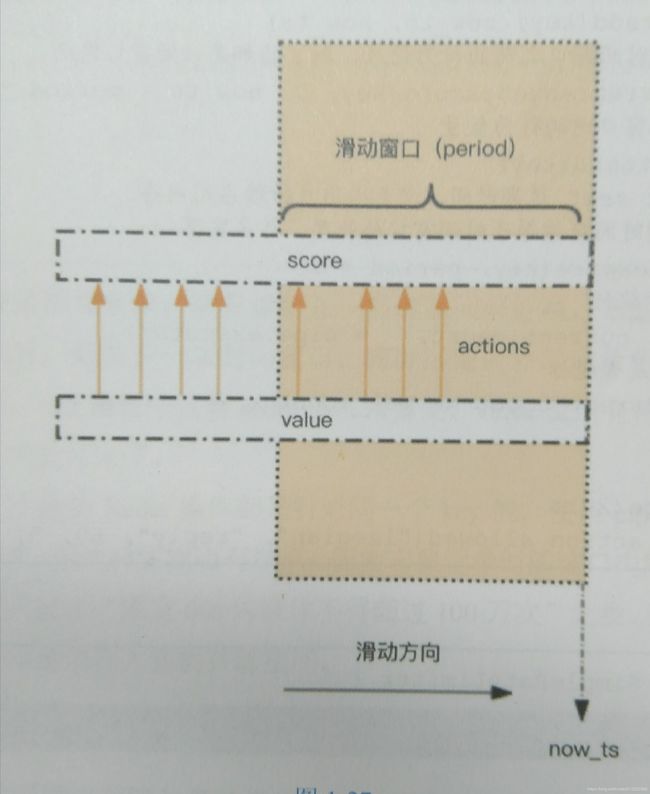
zset的一个用处是用来限流.限流是针对特定操作的限流,比如下面代码就是针对特定user_id的特定action
import time
import redis
client=redis.StrictRedis()
def is_allowed(user_id,action,period,max_count):
#这个key的意思是对这个user_id的这个action进行限流
key='hist:%s:%s'%(user_id,action)
now=int(time.time()*1000)
with client.pipeline() as pipe:
#记录本次操作
pipe.zadd(key,now,now)
#移除窗口外的操作
pipe.zremrangebyscore(key,0,now-period*1000)
#获取窗口内数量
pipe.zcard(key)
#设置过期时间用于剔除冷数据
pipe.expire(key,period+1)
#执行
_,_,count,_=pipe.execute()
return count<max_count
可以看出来,如果进行不停的操作,即使由于限流导致操作不成功,也会对后期操作有负面影响.
HyperLogLog
这种数据结构涉及到三个pf开头的指令(pf表示其发明人Philippe Flajolet):pfadd,pfcount,pfmerge,其中pfcount可以跟随多个key,相当于先把他们merge在得到数
Bloom Filter
当布隆过滤器所某个值存在时,这个值可能不存在;当它说某个值不存在时,那就肯定不存在.
让我诧异的是这些bf开头的指令居然不是官方原生支持的,我使用源码安装后不支持,以后再继续研究吧.不过书中提到使用bf.reserve来控制error_rate,可以记下来.
简单说下原理,附上书中的图
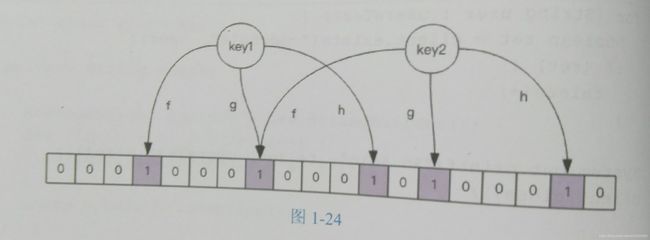
就是会对每个key做hash(图中使用了f,g,h三个hash函数),然后把对应位图中位置设置为1,查找的时候看看对应的位图是否为1就可以了.所以位图够大才能避免碰撞,另外hash函数越多则越精确.
这里有个网站帮助计算

GeoHash
毫无疑问,这又涉及到一些geo开头的数据,需要提到的是删除使用了zset的zrem指令来删除
另外一个问题是对于geo的key而言,value往往很大,在集群模式下迁移会有卡顿,所以建议单独非集群部署
keys vs scan
scan提供了查找功能,但是不像keys那样会阻塞,并且支持分页.不过这里有个坑爹的特性就是返回的条数并不精准,特别是返回集为空是并不代表没有后续数据.因为其limit其实是指定的slot的数量而不是记录条数,另外它采用的是高位加法(相应的,普通加法可以理解为低位加法),如图所示
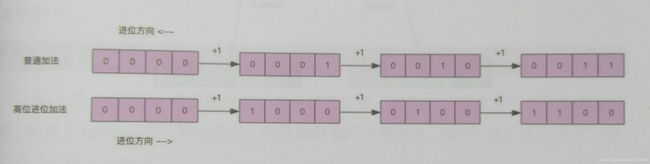
rehash
由于Redis采用了渐进式rehash,所以scan时要去新旧两个槽里去找
大key的查找
redis-cli -h 127.0.0.1 -p 6379 --bigkeys -i 0.1
上面的i参数是指每scan100就休眠0.1s,避免避免ops飙升触发运维监控的报警,当然这样会慢一些.所以也可以去掉.