深度学习如何入门?
序言
人工智能现在这么火,很多人都想转行,跃跃欲试,但是如果方法不对,就会走很多弯路
比如:有的人就非要系统学习数学知识、然后再系统学习Python、然后再学习机器学习,最后才学深度学习,
其实如果想尽快入门并且入职,完全没必要,你可以直接学习深度学习,大量练习项目,再回头研究算法机理。这样你就更加容易理解算法。企业面试也是重点考察你的代码能力,所以先务实代码基础,再回头深挖算法机理。这样的的学习效率最高,而且更容易帮你入职。

本文将从如下三个方面教你如何入门深度学习
如何了解——哪些人适合学?哪些人不适合学?
如何学习——帮你规划学习路径;
学习什么——讲解入门基础知识;神经网络核心机理
我会通俗易懂的表达,不用专业术语,配合图文,保证零基础也听得懂
哪些人适合学
这几类人不要学
-
- 有的人说初中毕业的,也可以入行,我完全不赞同。试想初中毕业也就14岁左右,假如现在25岁,你让他学习高中、大学数学知识,可能么?求求你放过这些人,让他们做适合他们做的事
- 一直以来学习文学和语言专业等的文科生,我知道他们有高中数学基础,但是长期的文科发散思维,突然要变成理科逻辑思维,还是有些困难
- 期待学习两三个月,就变大神,拿年薪20+,基本上不可能
这几类人可以学
大学里学习过高等数学的本科生,硕博士研究生
有高等数学基础的公司技术岗在职人员,需要AI赋能的
过去PC、ios、安卓开发的码农,有编程基础的
准备引入AI技术的产品经理
误解:人工智能是门槛很高,很高大尚的技术,一般人是没办法入行的
规划学习路径,帮助大家入行:
step1:科普——深度学习为什么会爆发?代表性技术、公司及行业应用
step2:深度学习概论知识——深度学习框架到底是什么?为什么要用框架?
step3:深度学习预备知识——数学和Python知识要求
step4:深度学习核心知识——神经网络、卷积神经网络机理
step5:深度学习扩展知识——强化学习的基础机理
step1:科普
在踏入人工智能大门前,我先讲一下,为什么这几年深度学习突然火了?
主要原因是大数据和GPU

第一个原因:大数据,以前我们收集数据的成本非常高,同时数据的采集也比较困难,存储数据的工具也比较昂贵,这就导致了数据量非常小。到了21世纪硬件发展非常快,存储设备也非常便宜,而且互联网时代大家的数据都在云端,收集数据也就非常方便,这样我们就有了非常多非常大的数据量。
第二个原因:GPU快速的发展,因为数据量大,训练一个模型需要的时间非常久,时间成本非常高。但有了GPU,使得我们在训练模型上的速度非常的快。
看看这张图,是有了GPU加速的效果,我们发现,如果只使用CPU去训练一个模型,即使是一个简单的模型,都需要40多天才能训练完,但有了GPU之后,时间可以瞬间缩短十倍,只需要三天或者四天,这在时间上的节省效果是非常明显的。
代表事件:2016年AlphaGo 4比1 战胜李世石,掀起了一波AI热潮,DeepMind背后所用的深度学习一下子火了起来了。其实在内行看来,AlphaGo对阵李世石的结果是毫无悬念的,真正的突破在几年前就发生了
深度学习目前的行业应用、一些标志性公司、代表性的技术等
语音识别技术,国内公司讯飞、百度。国外公司亚马逊,微软等,行业应用就是智能音箱等产品
图像识别技术,比如做安防的海康威视,图森科技,依图科技,旷视科技,代表性的就是面部识别,iphone X的人脸识别
自动驾驶技术,比如特斯拉,uber,百度等公司开发的
金融领域的预测股价、医疗领域的疾病监测,教育领域的技术赋能等
阿里巴巴淘宝网的千人千面等
Step2:深度学习概论知识
概念1:先了解一下人工智能、机器学习、深度学习,他们之间得关系是什么?
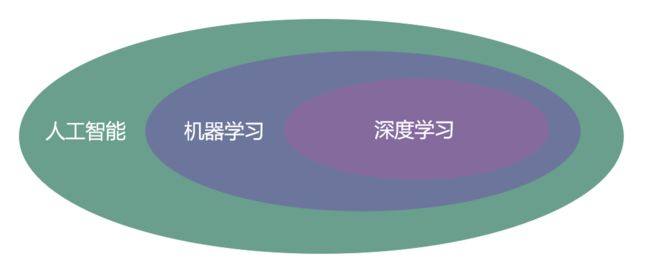
概念2:机器学习和深度学习的具体区别和联系是啥?
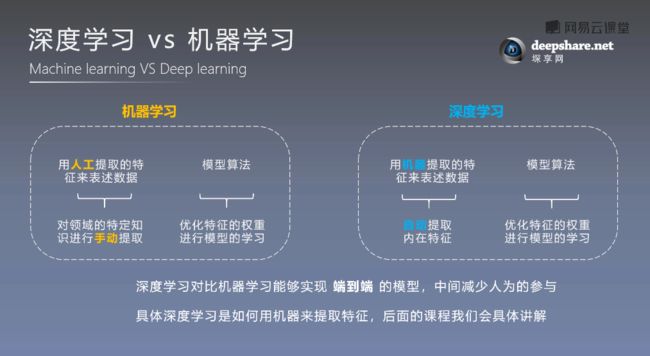
机器学习有两个步骤:
第一步:通过人工来提取特征,通过这个特征来表述我们需要的数据,这个需要对特定领域进行手动提取特征,
第二步:等提取完特征之后,就可以使用机器学习的模型来解决问题。在模型中,通过学习不断去优化模型里面的参数,最终得到优化好的模型。
深度学习也有两个步骤:
第一步:深度学习是通过机器来自动地提取数据的内在特征,而不需要使用人工手动提取。
第二步:提取完特征之后,仍然使用一个算法模型,通过模型自我学习来优化模型中的权重和参数。深度学习相对于机器学习来讲,它更能够实行一种端到端的模型,中间减少了人为参与。
总结:
从进化过程来看,解决任务的方式从编程到机器学习,最后到深度学习,算法流程经历了一个需要人整个把控,到机器学习人工只需要干预其中一小部分,到最后深度学习人工基本不需要干预,整个都可以用机器来实现。当模型越来越智能,人对它的干预也就越来越少。
深度学习框架介绍
概念1:为什么要使用框架?
为了降低开发人工智能技术难度,很多大公司把底层算法都封装到了一个黑盒子里面,这个黑盒子就叫深度学习框架,有了这个框架,我们就不需要所有代码都自己写,直接通过一个调用函数直接调用就行。

有两种主流的框架类型
符号式编程:最主流的代表,当然就是TensorFlow了。
命令式编程:最主流主流的代表就是PyTorch。
概念2:使用框架有以下几个好处

框架的文档详细,可以帮助我们快速上手,而不需要自己再去重复造轮子;
使用框架比自己写更加简单,降低了前期的入门门槛;
使用框架之后大家的代码都是简洁、相似的,方便大家互相阅读、交流代码;
框架的底层都是由工程师精心优化好的,所以使用框架能够降低我们构建模型的时间和运行模型的时间,提高执行效率;
使用模型还能够方便我们部署最后训练好的模型。除此之外,框架还有很多优势,这里就不再一一赘述。
概念3:目前有如下三个主流的框架
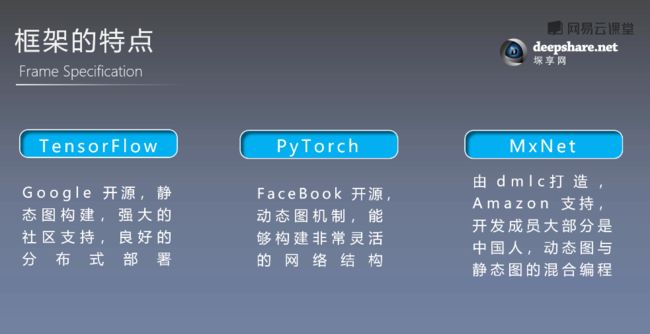
- 首先当然是业内老大TensorFlow。TensorFlow是现在最流行的深度学习框架,在 github 上有超过90000 个star,他的特点非常明显,google开源,质量有保证,社区强大,同时TensorFlow是一个静态图的结构,而且不管是在服务器端还是手机端都有非常好的部署方式,分布式部署。
接着就是PyTorch,PyTorch是17年1月由Facebook开源的深度学习框架,在短短的时间内获得了大量的使用者,其最大的特点是不同于TensorFlow的静态图结构,他是一个动态图的机制,debug非常方便,能够构建很灵活的网络结构。
最后我们讲一下MxNet,MxNet是由distributed machine learning community(dmlc) 开发的框架,开发成员大部分都是中国人,很早就在github上开源,目前是 Amazon 的官方框架,其特点是动态图和静态图混合编程的方式。
step3:深度学习预备知识
为了直观理解,我列举了预备内容大纲,你一看就明白了
1、基础数学知识
导数概念、如何求导、
矩阵概念、矩阵基本运算、
概率的概念、正态分布的概念等
【注意】以上内容入门深度学习足够,强烈不建议大家拿上一本数学教材从头到尾去读,更不要被网上对人工智能中数学知识高深莫测的描述吓到
2、Python基础知识
基本概念——列表、循环、遍历、字典、函数、类
科学计算库 numpy
【注意】 入门深度学习,以上Python知识足够, 强烈不建议一开始就花很多时间去系统学习Python,避免程序语言还没学完,你就放弃了
step4:深度学习核心知识
概念1:神经网络
讲神经网络,首先我们理解一下神经网络。神经网络的想法来自于人脑的神经元,左边就是人脑的神经元结构,人脑的神经元它有很多的突触,这些突触接受周围的信息,经过一些激活传递,就可以传到后面的神经元,让他们得到信息。
类似的,我们的神经网络如右边这种结构,输入的是一些X0,X1,X3的这些信息,神经元就能接受这些信息,然后再接着往后面传递,这就是一个简单的神经网络的来源
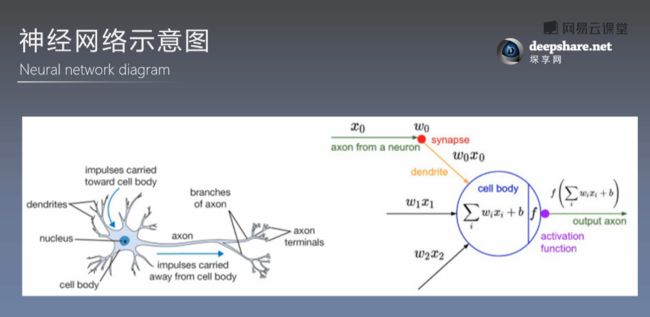
人脑处理这些信息,用大脑神经单元,而神经网络处理信息用的单元,就是这些数学公式。
当然这里面,有的人又纠结了,这个公式看不懂啊。入门阶段,不要尝试去理解,直接学会调用这些函数就够了。
等你能熟练搭建模型,训练模型的时候,再回头研究算法和这些数学机理。这个时候,你应该能理解的更加深刻,主要是因为知道这些东西到底是干嘛的了。
明白什么是最高效的学习方式了么?这也是更加符合人的认知学习规律的学习方式
概念2:神经网络是怎么工作的
这里我用一个多层神经网络的例子来举例
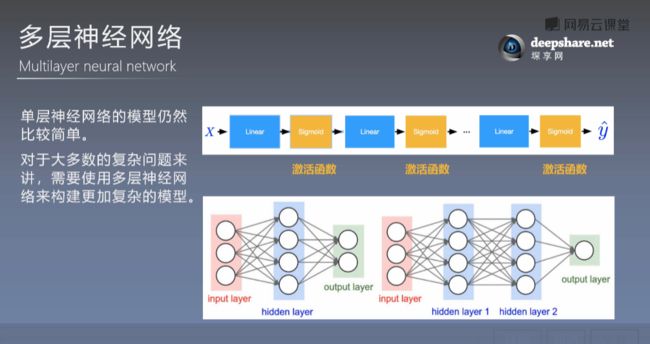
从图片看,里面有输入层,隐藏层、输出层
输入层就是,你要给网络大量的数据,输入到这个网络里面,让网络去学习,学习的过程就是这个隐藏层干的事情。当你训练好这个网络之后,你就可以给一个新的数据,然后让隐藏层去判断,判断的结果就会通过输出层输出来
具体隐藏层怎么工作的,我通过一个最简单的线性模型,一次函数来说
我们可以建一个模型来判断每天的学习时间跟学生考试的分数有什么关系。

比如说每天学习两个小时,能得三分,每天学习三个小时能得五分,每天学习四个小时能得八分,问题来了,如果每天学习五个小时能得多少分?这就是一个简单的线性模型,可以通过建立一个模型来预测。上面每学习两小时三小时四小时得到的成绩就是我们的训练集,在训练集里面所有的数据都是已经被标记好的,有输入和结果,我们希望做的事情就是预测。给一个新的输入,比如说五个小时或者六个小时,能预测出得多少分,这就是一个简单的线性模型。
线性模型的数学表达, y=wx+b,其中W是系数,B也是系数,这里面的W和B就是隐藏层里面需要训练的参数
概念3:卷积神经网络
卷积神经网络主要是为解决图像问题而诞生的,为什么需要卷积神经网络

一张图片在我们正常人的眼里就是一个形象的图片,但是在计算机的眼里,就是有很多像素点组成的集合,每一个像素点的参数都是RGB三原色里面具体颜色数值。
看到右边这张图,最左边这是一张猫的图片,它的图片大小是1000×1000像素,因为这是一个彩色图,它有RGB (红黄蓝)3个通道,所以它的数据量其实是1000×1000×3。如果展开成一个一维的向量,那么这个向量的大小应该跟这个图像本来的像素点数是一样的,也就是说它有3×10的6次方的数据量。前文提到的隐藏层里面,假如有1000个节点,就有3百万×1000这样一个数据量,非常大。
这样计算机就无法进行训练,那么卷积就是通过一些运算,在基本保持图像的一些特性不受损失的前提下,降低数据量。
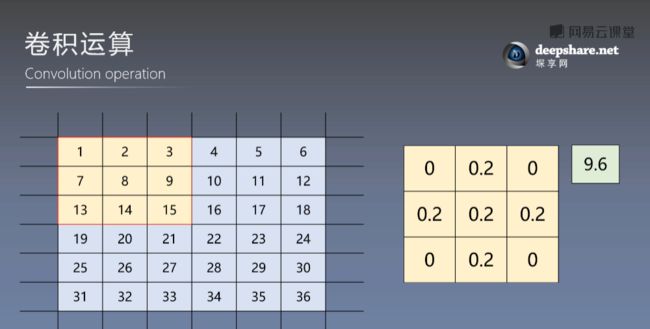
相当于就是做了一个矩阵运算,把原图的图像数据放到一个矩阵里面,然后和另一个小矩阵相乘,最终会算出一个数字,然后用这个一个数字代替之前一个大方格里面的数据。这样就可以减小数据量。
以上就是卷积为什么诞生,和它的最基础的运行机理
step5:深度学习扩展知识
概念1:强化学习
强化学习的一个典型应用就是AlphaGo下围棋

我们举一个通俗易懂的例子
比如说小时候我们回到家里面没有做作业,就出去玩了,结果被被妈妈打,
第二次又没有做作业又被打了,
第三次的时候我们根据前面两次惩罚,就知道不能够出去玩,应该先做作业。好,先做作业的话,妈妈就会奖励一个糖果,
第四次我们就还是会先做作业,这样就建立了一个简单的强化学习的模型,基于这些奖励来建立了一个小的机器人。
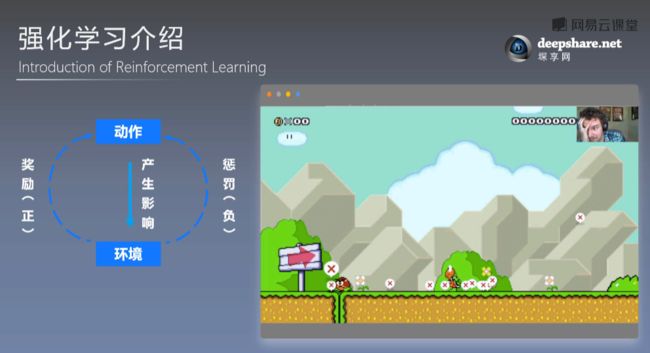
就如上图,左边这个反馈机制,通过环境得到,激励或者惩罚,来决定以后该怎么行动。
关于深度学习里面的神经网络还有很多,考虑到篇幅不能过长,就只写这么多了