JAVA学习——集合小结
------Java培训、Android培训、iOS培训、.Net培训、期待与您交流! -------
在多数情况下,由于保存数据的数目不确定性,显然无法用定长的数组进行保存,在这种情况下,我们就将用到集合。
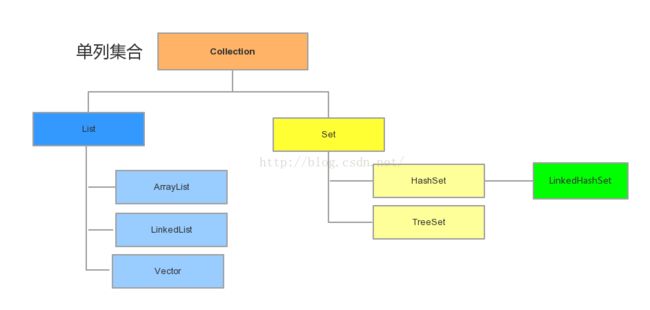
集合按照存储结构可以分为两大类,,即单列集合Collection和双列集合Map。
Collection:
单列集合根接口,他有两个重要的子接口,分别是List和Set。
|--List 的特点:元素有序,即元素存入顺序和取出顺序一致。元素可重复,即所有的元素是以一种线性方式进行存储的。实现类主要有ArrayList和LinkedList。
|--Set 的特点:元素无序,元素不可重复,实现类主要有HashSet和Treeset
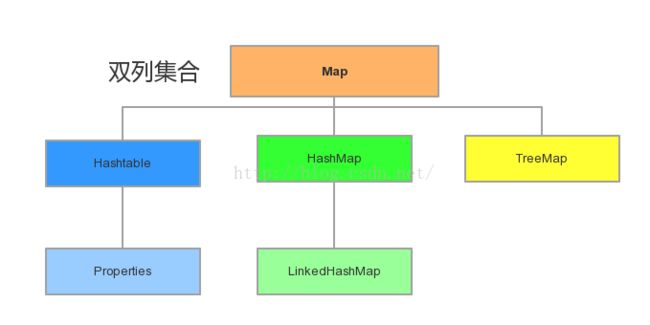
Map:
双列集合根接口,用于存储具有键(Key)值(Value)映射关系的元素,每个元素都包含一个键值对,并且可以利用Key来找到相应的Value。
实现类有HashMap和TreeMap
Iterrator:
他与Collection和Map都不相同,但也是集合框架中的一员,,他的作用主要是迭代访问,即遍历,可以遍历Collection里面的所有元素,因此,Iterrator对象也被称为迭代器对象。
import java.util.ArrayList;
import java.util.Iterator;
/**
* Iterator使用方法
* @author Shawn·Zhang
*/
public class Example03 {
public static void main(String[] args) {
ArrayList list = new ArrayList();//创建ArrayList集合
list.add("stu1");//添加元素
list.add("stu2");
list.add("stu3");
list.add("stu4");
list.add("stu5");
Iterator it = list.iterator();//获取Iterator对象
while(it.hasNext()){//判断ArrayList集合中是否存在下一个元素
String str = it.next();//取出ArrayList集合中的元素
System.out.println(str);
}
}
} ArrayList:
是List接口的实现类,同样的,他也是程序中最常见的一种集合。
其大部分的方法都继承与父类List和Collection,其中add()和get()方法用于元素的存取。
import java.util.ArrayList;
/**
* ArrayList常用方法
* @author Shawn·Zhang
*/
public class Example01 {
public static void main(String[] args) {
ArrayList list = new ArrayList();//创建ArrayList集合
list.add("stu1");//添加元素
list.add("stu2");
list.add("stu3");
list.add("stu4");
list.add("stu5");
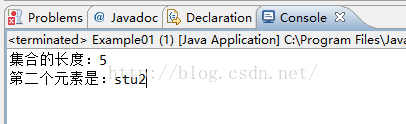
System.out.println("集合的长度:"+list.size());//获取集合中元素的个数
System.out.println("第二个元素是:"+list.get(1));//取出并打印指定位置的元素
}
} 
注:1、如同数组,最后一个元素为list.size()-1;
2、在代码中出现了
由于底层是使用一个数组来保存元素,因此再做大量的增删方面的效率比较低。但这种数组的结构允许程序通过索引来访问数组,所以使用ArrayList集合查找元素很方便。
LinkedList::
由于ArrayList在增删元素时效率较低,为了克服这种局限性,我们使用另一个实现类LinkedList。
该集合内部维护了一个双向循环链表,链表中的每一个元素都使用引用的方式来记住他的前一个元素和后一个元素,从而可以将所有的元素彼此连接起来。

专门针对元素的增删操作定义了一些特有的方法:
import java.util.LinkedList;
/**
* LinkedList特有方法
* @author Shawn·Zhang
*
*/
public class Example02 {
public static void main(String[] args) {
LinkedList link = new LinkedList();//创建LinkedList集合
link.add("stu1");//添加元素
link.add("stu2");
link.add("stu3");
link.add("stu4");
link.add("stu5");
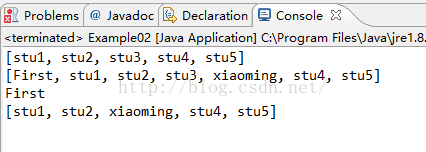
System.out.println(link.toString());//打印元素
link.add(3,"xiaoming");//向该集合指定位置中插入元素
link.addFirst("First");//向该集合第一个位置插入元素
System.out.println(link);
System.out.println(link.getFirst());//取出该集合中第一个元素
link.remove(3);//移除该集合中指定位置的元素
link.removeFirst();//移除该集合中第一个元素
System.out.println(link);//打印集合
}
} 
HashSet:
根据对象的哈希值来确定元素在集合中的存储位置,因此具有良好的存取和查找性能。
当向HashSet集合中添加元素时,首先会调用该对象的hashCode()方法来确定元素的存储位置,然后再调用对象的equals()方法来确保该位置没有重复元素。
import java.util.HashSet;
import java.util.Iterator;
/**
* HashSet集合
* @author Shawn·Zhang
*
*/
public class Example04 {
public static void main(String[] args) {
HashSet set = new HashSet();
set.add("stu1");
set.add("stu2");
set.add("stu1");
Iterator it = set.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
} 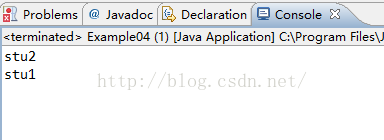
从结果可以看出,相同元素stu1由于相同,被舍弃,只存在一次,不重复。
TreeSet:
是Set集合中的另一个实现类,采用平衡的排序二叉树来储存元素,这样做不仅保证了没有重复的元素,还可以对元素进行排序。
举个例子:
我们依次放入13、8、17、17、1、11、15、25,利用Treeset集合进行存放,可以得到这样的二叉树

从图中可以看出,再向TreeSet集合依次放入元素时,首先将第一个元素放在二叉树的顶端,之后存入的元素与第一个进行比较,小于第一个元素,就将该元素放在左子树上,若大于第一个元素,则放在右子树上,以此类推,按照左子树元素小于右子树元素的顺序进行排序。当遇到重复的元素,就会去掉。
代码实现如下:
import java.util.Iterator;
import java.util.TreeSet;
/**
* TreeSet用法说明
* @author Shawn·Zhang
*
*/
public class Example05 {
public static void main(String[] args) {
TreeSet set = new TreeSet();
set.add(13);
set.add(8);
set.add(17);
set.add(17);
set.add(1);
set.add(11);
set.add(15);
set.add(25);
Iterator it = set.iterator();
while(it.hasNext()){
System.out.print(it.next()+" ");
}
}
} 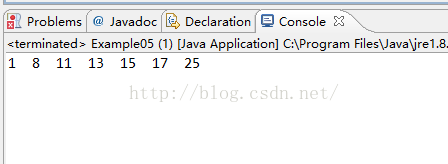
从结果可以看出,我们对加入的元素进行了从小到大的排序。
HashMap:
是Map接口的实现类,用于存储键值映射关系,并且需要保证不能出现重复的键,键相同,值覆盖。利用put(Obkect key, Object value)和get(Object key)方法来进行存取操作
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
/**
* HashMap基本用法
* @author Shawn·Zhang
*
*/
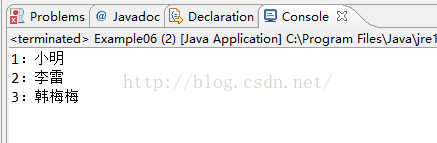
public class Example06 {
public static void main(String[] args) {
Map map = new HashMap();//创建Map集合
map.put(1, "小明");//存储键和值
map.put(2, "李雷");
map.put(3, "韩梅梅");
Set set = map.keySet();//获取键的集合
Iterator it = set.iterator();//迭代键的集合
while(it.hasNext()){
int key = it.next();
String value = map.get(key);//获取每个键所对应的值
System.out.println(key+":"+value);
}
}
} 
TreeMap:
存储原理类似于TreeSet,通过二叉树来保证键的唯一性,并且如同TreeSet一样,键也进行了顺序的排列。
import java.util.Iterator;
import java.util.Set;
import java.util.TreeMap;
/**
* TreeMap集合
* @author Shawn·Zhang
*
*/
public class Example07 {
public static void main(String[] args) {
TreeMap map = new TreeMap();//创建TreeMap集合
map.put(1, "小明");//存储键和值
map.put(3, "韩梅梅");
map.put(2, "李雷");
Set set = map.keySet();//获取键的集合
Iterator it = set.iterator();//迭代键的集合
while(it.hasNext()){
int key = it.next();
String value = map.get(key);//获取每个键所对应的值
System.out.println(key+":"+value);
}
}
} 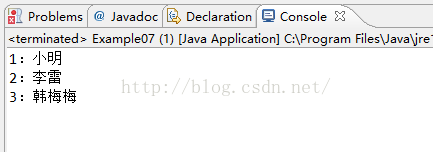
从测试结果可以看出,虽然添加顺序不同,但输出还是按照数字大小进行了排序,这就是treeMap的作用。
Properties:
Properties类是Hashtable的子类,Hashtable由于存取元素慢,目前基本已被HashMap类取代,但他的子类Properties却在实际应用中非常的广泛。
在实际开发中,经常使用Properties集合来存取应用的配置项。
PS:以上基本是对集合框架进行了总结,集合框架各自有自己的特性,在实际的开发应用中一定要根据相应特性来选择合适的集合类进行使用。