全网最通俗的条件随机场CRF
前言
本文是我尽量以通俗易懂的口吻来讲解CRF的一篇博文,标题虽然取得有点自不量力,但也是我付出了十分心血总结出来的,如果你还是没能看懂那说明我能力不够没能讲清楚,烦请不要在我的留言区展现出你的杠精本性。
网上其实有很多讲解CRF的文章了,但为什么我还要写这篇看似多此一举的博文呢。首先不管是csdn还是知乎,大部分讲解CRF的博文基本都是“取材”自《统计学习方法》没有个人理解,《统计学习方法》是本很好的书,但是这本书更像是教材,充斥着大量难懂的公式,而大部分读者又都是小白,面对这些没有说明的公式注定望而生怯。其次,大部分做NLP的同学对LSTM,transsformer理解的很透彻,但是在解决序列问题的时候为什么要加上CRF知其然而不知其所以然。
于是乎,我决定写一篇尽量通俗易懂的CRF博文让有一点数理基础的同学就能看懂,当然本文都是个人的理解,可能存在偏差,如果有错误的地方欢迎大家指正批评。
预备知识
CRF是一个比较难理解的模型,所以需要读者有一定的预备知识,如果没有也没有关系,只是阅读起来可能会有些吃力,特别是公式推导部分,如果你只是想简单了解下什么是CRF,那你只需要阅读下文的两节即可。
建议预备知识:
- 逻辑回归
- 动态规划
- 条件概率,联合概率,边缘概率,概率的期望值
- 积分
CRF解决的是什么问题
这个例子是在其他博文中看到的,大家也可以点进去查看原文
假设你有许多小明同学一天内不同时段的照片,从小明提裤子起床到脱裤子睡觉各个时间段都有(小明是照片控!)。现在的任务是对这些照片进行分类。比如有的照片是吃饭,那就给它打上吃饭的标签;有的照片是跑步时拍的,那就打上跑步的标签;有的照片是开会时拍的,那就打上开会的标签。问题来了,你准备怎么干?
一个简单直观的办法就是,不管这些照片之间的时间顺序,想办法训练出一个多元分类器。就是用一些打好标签的照片作为训练数据,训练出一个模型,直接根据照片的特征来分类。例如,如果照片是早上6:00拍的,且画面是黑暗的,那就给它打上睡觉的标签;如果照片上有车,那就给它打上开车的标签。
这样可行吗?
乍一看可以!但实际上,由于我们忽略了这些照片之间的时间顺序这一重要信息,我们的分类器会有缺陷的。举个例子,假如有一张小明闭着嘴的照片,怎么分类?显然难以直接判断,需要参考闭嘴之前的照片,如果之前的照片显示小明在吃饭,那这个闭嘴的照片很可能是小明在咀嚼食物准备下咽,可以给它打上吃饭的标签;如果之前的照片显示小明在唱歌,那这个闭嘴的照片很可能是小明唱歌瞬间的抓拍,可以给它打上唱歌的标签。
所以,为了让我们的分类器能够有更好的表现,在为一张照片分类时,我们必须将与它相邻的照片的标签信息考虑进来。这就是条件随机场(CRF)大显身手的地方!
什么是CRF
接下来我们先简单介绍一下什么是CRF,CRF全名条件随机场,是一个概率无向图模型,它和HMM很类似,但是CRF没有隐变量,并且是一个判别模型。CRF属于log linear model,什么是log linear model呢,如下面公式所示
P ( y ∣ x ) = 1 Z ( x ) e x p ( ∑ k = 1 K w k F k ( x , y ) ) P(y|x)=\frac{1}{Z(x)} exp(\sum_{k=1}^Kw_kF_k(x,y)) P(y∣x)=Z(x)1exp(k=1∑KwkFk(x,y))
Z ( x ) = ∑ y e x p ( ∑ k = 1 K w k F k ( x , y ) ) Z(x)= \sum_yexp(\sum_{k=1}^Kw_kF_k(x,y)) Z(x)=y∑exp(k=1∑KwkFk(x,y))
其中 P ( y ∣ x ) P(y|x) P(y∣x)是我们的似然函数,所以log linear model的优化问题是基于极大似然估计来的。 F k ( x , y ) F_k(x,y) Fk(x,y)叫做特征函数, w k w_k wk表示的是参数,CRF的训练目标就是要求这个参数。 Z ( x ) Z(x) Z(x)叫做规范化因子,可以看到,规范化因子就是对所有的Y进行了求和,因为我们求的是一个概率值,就好比10个球,其中一个是红色球,那抽到红球的概率是1/10而不是1,所以这里我们需要除以一个规范化因子。
看到这你们可能已经有点懵逼了,不是说好的通俗易懂吗,为什么一上来就摆公式,别着急,请继续往下看。有一个大家都很熟悉的模型logistic regression,也属于log linear model,只是其特征函数如下
F k ( x , y ) = x k ⋅ I ( y = c ) F_k(x,y) = x_k·I(y=c) Fk(x,y)=xk⋅I(y=c)
其中 I ( y = c ) I(y=c) I(y=c)表示的是y属于c这个类别则为1,否则为0,假如y有三种取值 y ∈ { 1 , 2 , 3 } y\in \{1,2,3\} y∈{1,2,3},c为1,那么只有当y为1的时候 F k ( x , y ) = x k F_k(x,y) = x_k Fk(x,y)=xk,其它时候都为0,如果我们用向量来表示,则有
P ( y ∣ x ) = e x p ( W X ) ∑ y e x p ( W X ) P(y|x)=\frac{exp(WX)}{\sum_yexp(WX)} P(y∣x)=∑yexp(WX)exp(WX)
这不就是咋们熟悉的softmax嘛,如果是二分类,那就完全是逻辑回归了。
ok我们回过头来看CRF,CRF也属于log linear model,只是其特征函数不太一样。回忆下上文举的小明的例子,如果我们只用softmax来做分类,不考虑时序那注定会导致错误率提升,如果引入了时序的概念,那我们的特征函数肯定不能只关注当前时刻的状态值,还需要考虑其他时刻的值。所以,CRF的衍生出了如下的特征函数。
F k ( x , y ) = ∑ i = 2 n f k ( y i − 1 , y i , x , i ) F_k(x,y)=\sum_{i=2}^nf_k(y_{i-1},y_i,x,i) Fk(x,y)=i=2∑nfk(yi−1,yi,x,i)
要注意CRF的特征函数的值要么是1要么是0。所以CRF其实和多元逻辑回归差不多,只是特征函数不一样,只要我们把CRF的特征函数搞明白了,CRF也就差不多搞明白了。
概率无向图模型
CRF实际上是一个概率无向图模型,所以在讲解下面内容前我们需要对概率无向图模型的内容进行一个补充讲解。概率无向图模型,也称为马尔科夫随机场,对概率无向图模型建模,首先需要求其联合概率分布,求一个无向图的联合概率,则需要求其最大团,下面给下最大团的定义,定义很好理解,就不过多赘述了。
无向图G中任何两个节点均有边连接的节点子集成为团,如果C是G的团,并且不能再加进任何一个G的结点使其成为更大的团,那么C就是最大团

其中 [ Y 1 , Y 2 , Y 3 ] [Y1,Y2 ,Y3] [Y1,Y2,Y3]构成了一个最大团, [ Y 4 , Y 2 , Y 3 ] [Y4,Y2 ,Y3] [Y4,Y2,Y3]也构成了一个最大团。
设每个最大团的概率为 Φ c ( Y c ) \Phi_c(Y_c) Φc(Yc),那么无向图的联合概率为:
P ( Y ) = 1 Z ∏ c Φ c ( Y c ) P(Y) = \frac{1}{Z} \prod_c \Phi_c(Y_c) P(Y)=Z1c∏Φc(Yc)
Z = ∑ Y ∏ c Φ c ( Y c ) Z= \sum_Y \prod_c \Phi_c(Y_c) Z=Y∑c∏Φc(Yc)
Z Z Z是规范化因子(normalization factor)
CRF是给定了随机变量X的条件下,随机变量Y的马尔科夫随机场,因此也叫做条件随机场,本文主要讨论的是线性链条件随机场。根据马尔科夫性有
P ( Y I ∣ X , Y 1 , . . . , Y i − 1 , Y i + 1 , . . . , Y n ) = P ( Y I ∣ X , Y i − 1 , Y i + 1 ) P(Y_I|X,Y_1,...,Y_{i-1},Y_{i+1},...,Y_n)=P(Y_I|X,Y_{i-1},Y_{i+1}) P(YI∣X,Y1,...,Yi−1,Yi+1,...,Yn)=P(YI∣X,Yi−1,Yi+1)
设K是状态特征个数+转移特征个数,也即最大团的个数,i表示时刻,则有
P ( y ∣ x ) = 1 Z ( x ) e x p ∑ k w k ∑ i f k ( y i − 1 , y i , x , i ) P(y|x) = \frac{1}{Z(x)} exp\sum_k w_k \sum_if_k(y_{i-1},y_i,x,i) P(y∣x)=Z(x)1expk∑wki∑fk(yi−1,yi,x,i)
Z ( X ) = ∑ y e x p ∑ k w k ∑ i f k ( y i − 1 , y i , x , i ) Z(X) = \sum_y exp\sum_k w_k \sum_if_k(y_{i-1},y_i,x,i) Z(X)=y∑expk∑wki∑fk(yi−1,yi,x,i)
CRF的三个问题
到此为止大家应该知道什么是CRF了,那么CRF该怎么用呢?CRF和HMM一样,也有自己需要求解的几个问题
1、概率计算问题,计算某时刻的条件概率 P ( y i ∣ x ) P(y_i|x) P(yi∣x)与 P ( y i − 1 , y i ∣ x ) P(y_{i-1},y_i|x) P(yi−1,yi∣x)
2、预测问题,求CRF的最优路径,因为是序列问题,所以可以理解为预测每一个时刻的状态
3、学习问题,即CRF的训练过程
概率计算问题
概率计算问题是指给定参数W,X与Y,求条件概率 P ( Y i ∣ X ) P(Y_i|X) P(Yi∣X), P ( Y i − 1 , Y i ∣ X ) P(Y_{i-1},Y_i|X) P(Yi−1,Yi∣X),这个条件概率的计算过程是一个递推的过程,所以被称为前向、后向算法,接下来我们看下其细节。
由上文我们知道
P ( y ∣ x ) = 1 Z ( x ) e x p ∑ k w k ∑ i f k ( y i − 1 , y i , x , i ) P(y|x) = \frac{1}{Z(x)} exp\sum_k w_k \sum_if_k(y_{i-1},y_i,x,i) P(y∣x)=Z(x)1expk∑wki∑fk(yi−1,yi,x,i)
设 g i ( y i − 1 , y i ) = ∑ k w k f k ( y i − 1 , y i , x , i ) g_i(y_{i-1},y_i)=\sum_k w_k f_k(y_{i-1},y_i,x,i) gi(yi−1,yi)=k∑wkfk(yi−1,yi,x,i)
则有
P ( y ∣ x ) = 1 Z ( x ) e x p ( ∑ i g i ( y i − 1 , y i ) ) P(y|x) = \frac{1}{Z(x)}exp(\sum_i g_i(y_{i-1},y_i)) P(y∣x)=Z(x)1exp(i∑gi(yi−1,yi))
假设我们要求 t t t时刻 y t = v y_t=v yt=v的概率,则可表示为
P ( v ∣ x ) = 1 Z ( x ) e x p ( ∑ i = 1 t g i ( y i − 1 , y i ) ) ) P(v|x) = \frac{1}{Z(x)}exp(\sum_{i=1}^{t} g_i(y_{i-1},y_i))) P(v∣x)=Z(x)1exp(i=1∑tgi(yi−1,yi)))
如果把 t t t时刻的值单独出来,则有
P ( v ∣ x ) = 1 Z ( x ) e x p ( ∑ i = 1 t − 1 g i ( y i − 1 , y i ) + g t ( y i − 1 , v ) ) P(v|x) = \frac{1}{Z(x)}exp(\sum_{i=1}^{t-1} g_i(y_{i-1},y_i)+g_t(y_{i-1},v)) P(v∣x)=Z(x)1exp(i=1∑t−1gi(yi−1,yi)+gt(yi−1,v))
再把 t − 1 t-1 t−1时刻的值单独出来,则有
P ( v ∣ x ) = 1 Z ( x ) e x p ( ∑ i = 1 t − 2 g i ( y i − 1 , y i ) + g t − 1 ( y i − 2 , y i − 1 ) + g t ( y i − 1 , v ) ) P(v|x) = \frac{1}{Z(x)}exp(\sum_{i=1}^{t-2} g_i(y_{i-1},y_i)+g_{t-1}(y_{i-2},y_{i-1})+g_t(y_{i-1},v)) P(v∣x)=Z(x)1exp(i=1∑t−2gi(yi−1,yi)+gt−1(yi−2,yi−1)+gt(yi−1,v))
可以发现,后一个时刻的条件概率其实就是等于前一个时刻的条件概率加上 g i ( y i − 1 , y i ) g_i(y_{i-1},y_i) gi(yi−1,yi),我们用 α t ( v ) \alpha_t(v) αt(v)来表示没有规范化因子的 P ( v ∣ x ) P(v|x) P(v∣x),那么,可以得到以下递推公式,v是t时刻的转态,u是t-1时刻的状态,注意此处是乘号不是加号,因为 g i g_i gi这一项从 e x p exp exp中分离出来的,加号需要变乘号
α t ( v ) = ∑ u α t − 1 ( u ) ⋅ e x p ( g t ( u , v ) ) \alpha_t(v)=\sum_u \alpha_{t-1}(u)·exp(g_t(u,v)) αt(v)=u∑αt−1(u)⋅exp(gt(u,v))

该公式如果用自然语言解释一下就是:t时刻状态为v的概率,等于t-1时刻,所有状态的概率乘上状态变为v的概率的和,即上图中红色点的概率=绿色点的概率乘上箭头的概率的和
可以发现,该计算方法是从前往后的,因此称为前向算法。如果计算方向从后往前,则称为后向算法(推理过程和前向类似,不再赘述)
β i ( v ) = ∑ u β i + 1 ( u ) ⋅ e x p ( g i ( v , u ) ) \beta_i(v) = \sum_u \beta_{i+1}(u)·exp(g_i(v,u)) βi(v)=u∑βi+1(u)⋅exp(gi(v,u))
根据前向算法与后向算法,我们即可计算条件概率
P ( y i ∣ x ) = 1 Z ( x ) α i ( y i ) β i ( y i ) P(y_i|x) = \frac{1}{Z(x)} \alpha_i(y_i)\beta_i(y_i) P(yi∣x)=Z(x)1αi(yi)βi(yi)
这里说下我的理解,开始我一直无法理解为什么是前向的值乘后向的值,后面突然想到CRF是一个无向图啊,求解i时刻的概率值需要计算和i相关的最大团的概率并相乘,而前向和后向算法刚好计算的是和i有关系的最大团的概率。
Z ( x ) = ∑ y i α i ( y i ) β i ( y i ) Z(x)=\sum_{y_i} \alpha_i(y_i)\beta_i(y_i) Z(x)=yi∑αi(yi)βi(yi)
规范化因子当然就是i时刻所有y的情况考虑进去,所以要累加。
P ( y i − 1 , y i ∣ x ) = 1 Z ( x ) α i ( y i ) g i ( y i − 1 , y i ) β i ( y i ) P(y_{i-1},y_i|x) = \frac{1}{Z(x)} \alpha_i(y_i) g_i(y_{i-1},y_i) \beta_i(y_i) P(yi−1,yi∣x)=Z(x)1αi(yi)gi(yi−1,yi)βi(yi)
同理, P ( y i − 1 , y i ∣ x ) P(y_{i-1},y_i|x) P(yi−1,yi∣x)只是多了一个最大团,把转移概率添加进去就ok了。
最后再提一点,《统计学习方法》中是用向量的形式来表示,所以在表示前向后向的值时不需要使用累加符号 ∑ \sum ∑。
预测问题
预测问题是指给定X与参数W,求使 P ( Y ∣ X ) P(Y|X) P(Y∣X)最大的Y,说白了就是模型训练好了,输入x怎么输出y,对于逻辑回归这样的模型来说,这个过程很简单,就是一个加和的过程,但对于CRF来说其实是求解无向图的最优路径。
看个具体的例子,例如我们有一个这样一个句子:[我 喜欢 白色的 鞋],假如我们要对这个句子做词性标注,最终的结果是 [ n , v , a d j , n ] [n,v,adj,n] [n,v,adj,n],预测问题实际上就是指输出 [ n , v , a d j , n ] [n,v,adj,n] [n,v,adj,n],那为什么说这个过程需要优化呢?我们先看一下正常流程解决这个问题的时间复杂度。

还是举词性标注的例子,假如我们序列长度是n,一共有m种词性,每一个时刻都可以取m种情况,例如上图的 y 1 y_1 y1时刻,对应了m种情况, 这个时刻我们可以直接判断一下m种词性哪个概率值最大,那当前时刻的词性就是最大概率的对应的词性, y 2 y_2 y2时刻也可以取m种情况,如果我们要计算当前时刻对应的词性,就需要用 y 1 y_1 y1时刻所有词性的概率乘上由 y 1 y_1 y1时刻的状态转变为 y 2 y_2 y2时刻的状态的概率值,可以发现时间复杂度是 O ( m 2 ) O(m^2) O(m2),那如果序列的长度是n,那么时间复杂度就是 O ( m n ) O(m^n) O(mn),很显然这是我们无法接受的,那这种情况该怎么解决呢?
既然是求最优问题,那大概率离不开动态规划,而此处的优化算法叫做维特比算法,该算法的本质就是动态规划。说白了就是计算t+1时刻的值的时候,我把t时刻所有词性的最优解先保存好。继续以上面为例,对于t2时刻我采用一样的求解方法,此时可以得到t2时刻所有词性的解并保存到数组里,t3时刻,只需要用t2时刻的最优解乘上转态转移概率,所以时间复杂度恒定为 O ( m 2 ) O(m^2) O(m2)
接下来我们来看下详细的推导过程,先回顾下问题,给定W,X求使 P ( Y ∣ X ) P(Y|X) P(Y∣X)最大的Y,有没有觉得和上一个任务差不多,因为要求Y也需要求出对应的 P ( Y ∣ X ) P(Y|X) P(Y∣X),只不过这里不需要计算出具体 P ( Y ∣ X ) P(Y|X) P(Y∣X)是多大,所以可以不考虑规范化因子和exp函数。
如果用公式表示我们要求的值即为:
y ^ = arg max y p ( y ∣ x , w ) = arg max y ∑ j = 1 m w j F j ( X , Y ) = arg max y ∑ j = 1 m w j ∑ i = 2 n f i ( y i − 1 y i , x , i ) \begin{aligned} \hat y &= \argmax_y p(y|x,w)\\ &=\argmax_y \sum_{j=1}^m w_jF_j(X,Y)\\ &=\argmax_y \sum_{j=1}^m w_j \sum_{i=2}^nf_i(y_{i-1}y_i,x,i) \end{aligned} y^=yargmaxp(y∣x,w)=yargmaxj=1∑mwjFj(X,Y)=yargmaxj=1∑mwji=2∑nfi(yi−1yi,x,i)
和上一个问题一样令
g i ( y i − 1 , y i ) = ∑ j = 1 m w j f i ( y i − 1 y i , x , i ) g_i(y_{i-1},y_i) = \sum_{j=1}^mw_jf_i(y_{i-1}y_i,x,i) gi(yi−1,yi)=j=1∑mwjfi(yi−1yi,x,i)
则有
y ^ = arg max y p ( y ∣ x , w ) = ∑ i = 2 n g i ( y i − 1 , y i ) \hat y = \argmax_y p(y|x,w) = \sum_{i=2}^n g_i(y_{i-1},y_i) y^=yargmaxp(y∣x,w)=i=2∑ngi(yi−1,yi)
在继续讲解下面的内容之前,我这里简单提一下动态规划,动态规划看似高深,实际上就是把暴力遍历的情况由递归改为递推,然后用空间换时间,把之前计算好的值保存好从而达到去冗余的效果。
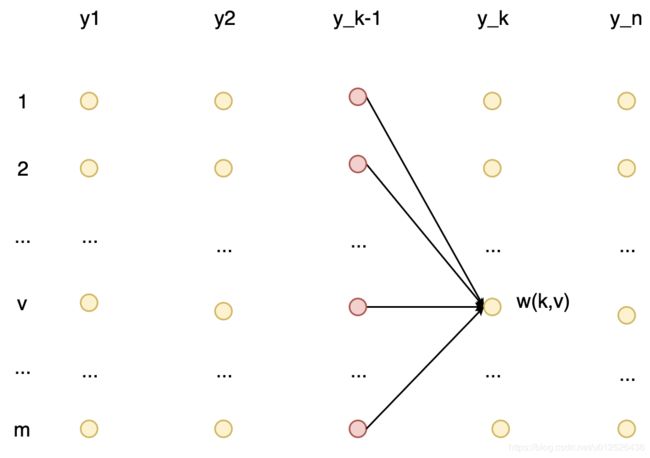
既然要使用动态规划,那么我们需要先初始化一个二维数组w,w大小为[n,m],每个点保存的是当前时刻当前状态的概率最大值,即如上图所示,图中w(k,v)表示的是在k时刻状态为v的概率值,如果我们要求对应的y,那么只需要最大化这个值就好了。根据上图的递推关系,我们可以得到如下公式。
w ( k , v ) = max y 1 : k − 1 ∑ i = 1 k − 1 g i ( y i − 1 y i ) + g k ( y k − 1 , v ) w(k,v)=\max_{y_{1:k-1 }}\sum_{i=1}^{k-1}g_i({y_{i-1}y_i})+g_k(y_{k-1},v) w(k,v)=y1:k−1maxi=1∑k−1gi(yi−1yi)+gk(yk−1,v)
这里再简单解释一下:k时刻状态为v的概率=从1时刻到k-1时刻的概率最大值+k时刻状态由 y i − 1 y_{i-1} yi−1变为v的概率值,即图中红色点的值加上箭头的值。
如果把上面的递推公式的k-1时刻再分出来一项,则有
w ( k , v ) = max y k − 1 [ max y 1 : k − 2 ∑ i = 1 k − 2 g i ( y i − 1 y i ) + g k − 1 ( y k − 2 , y k − 1 ) ] + g k ( y k − 1 , v ) w(k,v)=\max_{y_{k-1}}[\max_{y_{1:k-2 }}\sum_{i=1}^{k-2}g_i({y_{i-1}y_i})+g_{k-1}(y_{k-2},y_{k-1})]+g_k(y_{k-1},v) w(k,v)=yk−1max[y1:k−2maxi=1∑k−2gi(yi−1yi)+gk−1(yk−2,yk−1)]+gk(yk−1,v)
假设 y i − 1 y_{i-1} yi−1时刻的状态为 u u u,那么我们可以把地推公式简化为如下形式,是不是和第一个问题很类似,只是这里我们只需要找最大值而不需要计算具体值。
w ( k , v ) = max u [ w ( k − 1 , u ) ] + g k ( u , v ) w(k,v)=\max_u [w(k-1,u)]+g_k(u,v) w(k,v)=umax[w(k−1,u)]+gk(u,v)
求出最大值之后,我们就可以找到对应的y值了,什么?你还是不知道怎么求y,行吧,我这里再啰嗦几句。
此时我们已经得到了 w ( k , v ) w(k,v) w(k,v),w的参数中是包含y的,只需要看下此时最大值对应的y值是啥就ok了,然后再回到k-1时刻,以同样的方式得到k-1时刻的y,直到到第一个时刻,此时 y ^ \hat y y^就全部求解出来了,整个过程就是维特比算法。
学习问题
其实学习问题我是不太想推的,因为其过程就是最大似然再采用梯度下降法更新w,但是都解决两个问题了,总不能半途而废吧,那就静下心来把这部分也补充完整吧。
既然要采用梯度下降法,那首先就是要对参数w求导,从上文我们知道
P ( y ∣ x ) = 1 Z ( x ) e x p ( ∑ k = 1 K w k F k ( x , y ) ) P(y|x)=\frac{1}{Z(x)} exp(\sum_{k=1}^Kw_kF_k(x,y)) P(y∣x)=Z(x)1exp(k=1∑KwkFk(x,y))
为了简化计算难度,我们取个log
α α w k l o g P ( y ∣ x ) = α α w k ∑ k = 1 K w k F k ( x , y ) − l o g Z ( x ) = F k ( x , y ) − 1 Z ( x ) α α w k Z ( x ) (1) \tag{1} \begin{aligned} \frac{\alpha}{\alpha w_k}log P(y|x)&=\frac{\alpha}{\alpha w_k}\sum_{k=1}^Kw_kF_k(x,y)-logZ(x)\\ &=F_k(x,y)-\frac{1}{Z(x)} \frac{\alpha}{\alpha w_k}Z(x) \end{aligned} αwkαlogP(y∣x)=αwkαk=1∑KwkFk(x,y)−logZ(x)=Fk(x,y)−Z(x)1αwkαZ(x)(1)
接下来我们求 Z ( x ) Z(x) Z(x)的导数,由上文我们知道
Z ( x ) = ∑ y ′ e x p ( ∑ k ′ = 1 K w k ′ F k ′ ( x , y ′ ) ) Z(x)= \sum_{y'}exp(\sum_{{k'}=1}^Kw_{k'}F_{k'}(x,{y'})) Z(x)=y′∑exp(k′=1∑Kwk′Fk′(x,y′))
α α w k Z ( x ) = α α w k ∑ y ′ e x p ( ∑ k ′ w k ′ F k ′ ( x , y ′ ) ) = ∑ y ′ α α w k e x p ( ∑ k ′ w k ′ F k ′ ( x , y ′ ) ) = ∑ y ′ e x p ( ∑ k ′ w k ′ F k ′ ( x , y ′ ) ) ⋅ α α w k ∑ k ′ w k ′ F k ′ ( x , y ′ ) = ∑ y ′ e x p [ ( ∑ k ′ w k ′ F k ′ ( x , y ′ ) ) ] F k ′ ( x , y ′ ) (2) \begin{aligned} \frac{\alpha}{\alpha w_k}Z(x) &=\frac{\alpha}{\alpha w_k}\sum_{y'}exp(\sum_{k'}w_{k'}F_{k'}(x,{y'})) \\ &=\sum_{y'}\frac{\alpha}{\alpha w_k}exp(\sum_{k'}w_{k'}F_{k'}(x,{y'})) \\ &=\sum_{y'}exp(\sum_{k'}w_{k'}F_{k'}(x,{y'}))·\frac{\alpha}{\alpha w_k}\sum_{k'}w_{k'}F_{k'}(x,y') \\ &=\sum_{y'}exp[(\sum_{k'}w_{k'}F_{k'}(x,{y'}))]F_{k'}(x,y') \end{aligned} \tag{2} αwkαZ(x)=αwkαy′∑exp(k′∑wk′Fk′(x,y′))=y′∑αwkαexp(k′∑wk′Fk′(x,y′))=y′∑exp(k′∑wk′Fk′(x,y′))⋅αwkαk′∑wk′Fk′(x,y′)=y′∑exp[(k′∑wk′Fk′(x,y′))]Fk′(x,y′)(2)
把公式2带到公式1中则有
α α w k l o g P ( y ∣ x ) = F k ( x , y ) − 1 Z ( x ) ∑ y ′ e x p [ ( ∑ k ′ w k ′ F k ′ ( x , y ′ ) ) ] F k ′ ( x , y ′ ) = F k ( x , y ) − ∑ y ′ F k ′ ( x , y ′ ) 1 Z ( x ) e x p [ ( ∑ k ′ w k ′ F k ′ ( x , y ′ ) ) ] = F k ( x , y ) − ∑ y ′ F k ′ ( x , y ′ ) ⋅ P ( y ′ ∣ x ) = F k ( x , y ) − E y ′ ∽ P ( y ′ ∣ x ) [ F k ′ ( x , y ′ ) ] \begin{aligned} \frac{\alpha}{\alpha w_k}log P(y|x)&=F_k(x,y)-\frac{1}{Z(x)} \sum_{y'}exp[(\sum_{k'}w_{k'}F_{k'}(x,{y'}))]F_{k'}(x,y') \\ &=F_k(x,y)- \sum_{y'}F_{k'}(x,y') \frac{1}{Z(x)} exp[(\sum_{k'}w_{k'}F_{k'}(x,{y'}))]\\ &=F_k(x,y)- \sum_{y'}F_{k'}(x,y')·P(y'|x)\\ &=F_k(x,y)-E_{y' \backsim P(y'|x)} [F_{k'}(x,y')] \end{aligned} αwkαlogP(y∣x)=Fk(x,y)−Z(x)1y′∑exp[(k′∑wk′Fk′(x,y′))]Fk′(x,y′)=Fk(x,y)−y′∑Fk′(x,y′)Z(x)1exp[(k′∑wk′Fk′(x,y′))]=Fk(x,y)−y′∑Fk′(x,y′)⋅P(y′∣x)=Fk(x,y)−Ey′∽P(y′∣x)[Fk′(x,y′)]
这里解释下 E y ′ ∽ P ( y ′ ∣ x ) { F k ′ ( x , y ′ ) } E_{y' \backsim P(y'|x)} \{F_{k'}(x,y')\} Ey′∽P(y′∣x){Fk′(x,y′)},这里表示的是 y ′ y' y′服从 P ( y ′ ∣ x ) P(y'|x) P(y′∣x)分布 F k ′ ( x , y ′ ) F_{k'}(x,y') Fk′(x,y′)的期望值。这里可以做个简化,用 y ˉ \bar y yˉ表示 y ′ ∽ P ( y ′ ∣ x ) y' \backsim P(y'|x) y′∽P(y′∣x),因为我们遵循马尔科夫假设,所以期望值实际只和i与i-1时刻有关系,所有有以下公式
α α w k l o g P ( y ∣ x ) = F k ( x , y ) − E y ˉ { F k ′ ( x , y ′ ) } = F k ( x , y ) − E y ˉ [ ∑ i = 2 n f k ( y i − 1 , y i , x , i ) ] = F k ( x , y ) − ∑ i = 2 n E y i − 1 , y i [ f k ( y i − 1 , y i , x , i ) ] \begin{aligned} \frac{\alpha}{\alpha w_k}log P(y|x)&=F_k(x,y)-E_{\bar y} \{F_{k'}(x,y')\} \\ &=F_k(x,y)-E_{\bar y}[\sum_{i=2}^nf_k(y_{i-1},y_i,x,i)] \\ &=F_k(x,y)-\sum_{i=2}^nE_{y_{i-1},y{i}}[f_k(y_{i-1},y_i,x,i)] \\ \end{aligned} αwkαlogP(y∣x)=Fk(x,y)−Eyˉ{Fk′(x,y′)}=Fk(x,y)−Eyˉ[i=2∑nfk(yi−1,yi,x,i)]=Fk(x,y)−i=2∑nEyi−1,yi[fk(yi−1,yi,x,i)]
然后我们把期望值展开
α α w k l o g P ( y ∣ x ) = F k ( x , y ) − ∑ i = 2 n E y i − 1 , y i [ f k ( y i − 1 , y i , x , i ) ] = F k ( x , y ) − ∑ i = 2 n ∑ y i − 1 ∑ y i f k ( y i − 1 , y i , x , i ) P ( y i − 1 , y i ∣ x ) \begin{aligned} \frac{\alpha}{\alpha w_k}log P(y|x)&=F_k(x,y)-\sum_{i=2}^nE_{y_{i-1},y{i}}[f_k(y_{i-1},y_i,x,i)] \\ &=F_k(x,y)-\sum_{i=2}^n \sum_{y_{i-1}} \sum_{y_{i}} f_k(y_{i-1},y_i,x,i) P(y_{i-1},y_i|x) \\ \end{aligned} αwkαlogP(y∣x)=Fk(x,y)−i=2∑nEyi−1,yi[fk(yi−1,yi,x,i)]=Fk(x,y)−i=2∑nyi−1∑yi∑fk(yi−1,yi,x,i)P(yi−1,yi∣x)
上式中,第一项和第二项都是特征函数,可以直接求出来, P ( y i − 1 , y i ∣ x ) P(y_{i-1},y_i|x) P(yi−1,yi∣x)的值则是我们上文说的第一个问题,根据前先后向算法即可得到。
α α w k l o g P ( y ∣ x ) = F k ( x , y ) − ∑ i = 2 n ∑ y i − 1 ∑ y i f k ( y i − 1 , y i , x , i ) α i − 1 ( y i − 1 ) e x p ( g i ( y i − 1 , y i ) ) β i ( y i ) Z ( x ) \frac{\alpha}{\alpha w_k}log P(y|x)=F_k(x,y)-\sum_{i=2}^n \sum_{y_{i-1}} \sum_{y_{i}} f_k(y_{i-1},y_i,x,i) \frac{\alpha_{i-1}(y_{i-1})exp(g_i(y_{i-1},y_i)) \beta_i(y_i)}{Z(x)} αwkαlogP(y∣x)=Fk(x,y)−i=2∑nyi−1∑yi∑fk(yi−1,yi,x,i)Z(x)αi−1(yi−1)exp(gi(yi−1,yi))βi(yi)
Z ( x ) Z(x) Z(x)的值也可以根据 α i ( y i ) \alpha_i(y_i) αi(yi)求得,所以 w k w_k wk的导数是可以很高效的求解出来,最后采用梯度下降法更新 w k w_k wk即可
w k = w k − η w k ′ w_k = w_k - \eta w_k' wk=wk−ηwk′
总结
本文介绍的是线性链条件随机场,也是最简单的一种形式,CRF除了解决离散数据外,其实也能用来解决连续型的值,这就涉及到蒙特卡洛,吉布斯采样等算法了。在实际应用场景中大家只需要会线性链的CRF就足矣了(主要是我也不会没法讲啊),最后欢迎大家留言讨论,希望这篇博文能真的让你了解CRF。
References
1、李航 《统计学习方法》
2、Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data
3、如何轻松愉快地理解条件随机场