利用ARIMA进行时间序列数据分析(Python)
0 导读
阅读本文需要有掌握基本的ARIMA知识,倘若ARIMA相关内容已经遗忘,此处提供以下博文帮你回忆一下:
- 时间序列预测之--ARIMA模型
- 时间序列模型学习笔记
- ARIMA模型的拖尾截尾问题
本文主要分为四个部分:
- 用pandas处理时序数据
- 检验序数据的稳定性
- 处理时序数据变成稳定数据
- 时序数据的预测
和许多时间序列分析一样,本文同样使用航空乘客数据(AirPassengers.csv)作为样例。
下载数据请点击:https://download.csdn.net/download/u012735708/10649619
1 用pandas导入和处理时序数据
import numpy as np
import pandas as pd
from datetime import datetime
import matplotlib.pylab as plt
# 读取数据,pd.read_csv默认生成DataFrame对象,需将其转换成Series对象
df = pd.read_csv('F:/time/AirPassengers.csv', encoding='utf-8', index_col='TravelDate')
df.index = pd.to_datetime(df.index) # 将字符串索引转换成时间索引
ts = df['Passengers'] # 生成pd.Series对象
ts.head()运行结果如下:数据包括每个月对应的passenger的数目。
TravelDate
1949-01-01 112
1949-02-01 118
1949-03-01 132
1949-04-01 129
1949-05-01 121
Name: Passengers, dtype: int64此时时间为索引
ts.index结果如下
DatetimeIndex(['1949-01-01', '1949-02-01', '1949-03-01', '1949-04-01',
'1949-05-01', '1949-06-01', '1949-07-01', '1949-08-01',
'1949-09-01', '1949-10-01',
...
'1960-03-01', '1960-04-01', '1960-05-01', '1960-06-01',
'1960-07-01', '1960-08-01', '1960-09-01', '1960-10-01',
'1960-11-01', '1960-12-01'],
dtype='datetime64[ns]', name='TravelDate', length=144, freq=None)查看某日的值既可以使用字符串作为索引,又可以直接使用时间对象作为索引
第一种方式
ts['1949-01-01']112第二种方式
ts[datetime(1949,1,1)]112如果要查看某一年的数据,pandas也能非常方便的实现
ts['1949']TravelDate
1949-01-01 112
1949-02-01 118
1949-03-01 132
1949-04-01 129
1949-05-01 121
1949-06-01 135
1949-07-01 148
1949-08-01 148
1949-09-01 136
1949-10-01 119
1949-11-01 104
1949-12-01 118
Name: Passengers, dtype: int64切片操作:
ts['1949-1' : '1949-6']TravelDate
1949-01-01 112
1949-02-01 118
1949-03-01 132
1949-04-01 129
1949-05-01 121
1949-06-01 135
Name: Passengers, dtype: int642 检验序数据的稳定性
因为ARIMA模型要求数据是稳定的,所以这一步至关重要。
1. 判断数据是稳定的常基于对于时间是常量的几个统计量:
- 常量的均值
- 常量的方差
- 与时间独立的自协方差
用图像说明如下:
1)均值

X是时序数据的值,t是时间。可以看到左图,数据的均值对于时间轴来说是常量,即数据的均值不是时间的函数,所有它是稳定的;右图随着时间的推移,数据的值整体趋势是增加的,所有均值是时间的函数,数据具有趋势,所以是非稳定的。
2)方差

可以看到左图,数据的方差对于时间是常量,即数据的值域围绕着均值上下波动的振幅是固定的,所以左图数据是稳定的。而右图,数据的振幅在不同时间点不同,所以方差对于时间不是独立的,数据是非稳定的。但是左、右图的均值是一致的。
3)自协方差

一个时序数据的自协方差,就是它在不同两个时刻i,j的值的协方差。可以看到左图的自协方差于时间无关;而右图,随着时间的不同,数据的波动频率明显不同,导致它i,j取值不同,就会得到不同的协方差,因此是非稳定的。虽然右图在均值和方差上都是与时间无关的,但仍是非稳定数据。
2. python判断时序数据稳定性
平稳性检验一般采用观察法和单位根检验法。
观察法:需计算每个时间段内的平均的数据均值和标准差。
单位根检验法:通过Dickey-Fuller Test 进行判断,大致意思就是在一定置信水平下,对于时序数据假设 Null hypothesis: 非稳定。这是一种常用的单位根检验方法,它的原假设为序列具有单位根,即非平稳,对于一个平稳的时序数据,就需要在给定的置信水平上显著,拒绝原假设。
针对以上两种方法,进行Python编码
# 移动平均图
def draw_trend(timeseries, size):
f = plt.figure(facecolor='white')
# 对size个数据进行移动平均
rol_mean = timeseries.rolling(window=size).mean()
# 对size个数据移动平均的方差
rol_std = timeseries.rolling(window=size).std()
timeseries.plot(color='blue', label='Original')
rol_mean.plot(color='red', label='Rolling Mean')
rol_std.plot(color='black', label='Rolling standard deviation')
plt.legend(loc='best')
plt.title('Rolling Mean & Standard Deviation')
plt.show()
def draw_ts(timeseries):
f = plt.figure(facecolor='white')
timeseries.plot(color='blue')
plt.show()
#Dickey-Fuller test:
def teststationarity(ts):
dftest = adfuller(ts)
# 对上述函数求得的值进行语义描述
dfoutput = pd.Series(dftest[0:4], index=['Test Statistic','p-value','#Lags Used','Number of Observations Used'])
for key,value in dftest[4].items():
dfoutput['Critical Value (%s)'%key] = value
return dfoutput查看原始数据的均值和方差
draw_trend(ts,12)结果如下

通过上图,我们可以发现数据的移动平均值/标准差有越来越大的趋势,是不稳定的。接下来我们再看Dickey-Fuller的结果
teststationarity(ts)结果如下
Test Statistic 0.815369
p-value 0.991880
#Lags Used 13.000000
Number of Observations Used 130.000000
Critical Value (1%) -3.481682
Critical Value (5%) -2.884042
Critical Value (10%) -2.578770
dtype: float64此时p值为0.991880,说明并不能拒绝原假设。通过DF的数据可以明确的看出,在任何置信度下,数据都不是稳定的。
3 处理时序数据变成稳定数据
数据不稳定的原因主要有以下两点:
- 趋势(trend)-数据随着时间变化。比如说升高或者降低。
- 季节性(seasonality)-数据在特定的时间段内变动。比如说节假日,或者活动导致数据的异常。
由前面的分析可知,该序列是不平稳的,然而平稳性是时间序列分析的前提条件,故我们需要对不平稳的序列进行处理将其转换成平稳的序列。
1)对数变换
对数变换主要是为了减小数据的振动幅度,使其线性规律更加明显,同时保留其他信息。这里强调一下,变换的序列需要满足大于0,小于0的数据不存在对数变换。
ts_log = np.log(ts)我们看一下此时的数据分布
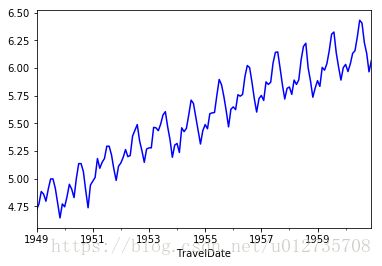
可以看出经过对数变换后,数据值域范围缩小了,振幅也没那么大了。
2)平滑法
根据平滑技术的不同,平滑法具体分为移动平均法和指数平均法。
移动平均即利用一定时间间隔内的平均值作为某一期的估计值,而指数平均则是用变权的方法来计算均值。
移动平均:
def draw_moving(timeSeries, size):
f = plt.figure(facecolor='white')
# 对size个数据进行移动平均
rol_mean = timeSeries.rolling(window=size).mean()
# 对size个数据进行加权移动平均
rol_weighted_mean = pd.ewma(timeSeries, span=size)
#rol_weighted_mean=timeSeries.ewm(halflife=size,min_periods=0,adjust=True,ignore_na=False).mean()
timeSeries.plot(color='blue', label='Original')
rol_mean.plot(color='red', label='Rolling Mean')
rol_weighted_mean.plot(color='black', label='Weighted Rolling Mean')
plt.legend(loc='best')
plt.title('Rolling Mean')
plt.show()
draw_moving(ts_log,12)
结果如下

从上图可以发现窗口为12的移动平均能较好的剔除年周期性因素,而指数平均法是对周期内的数据进行了加权,能在一定程度上减小年周期因素,但并不能完全剔除,如要完全剔除可以进一步进行差分操作。
3)差分
时间序列最常用来剔除周期性因素的方法当属差分了,它主要是对等周期间隔的数据进行线性求减。前面我们说过,ARIMA模型相对ARMA模型,仅多了差分操作,ARIMA模型几乎是所有时间序列软件都支持的,差分的实现与还原都非常方便。
diff_12 = ts_log.diff(12)
diff_12.dropna(inplace=True)
diff_12_1 = diff_12.diff(1)
diff_12_1.dropna(inplace=True)
teststationarity(diff_12_1)结果如下
Test Statistic -4.443325
p-value 0.000249
#Lags Used 12.000000
Number of Observations Used 118.000000
Critical Value (1%) -3.487022
Critical Value (5%) -2.886363
Critical Value (10%) -2.580009
dtype: float64从上面的统计检验结果可以看出,经过12阶差分和1阶差分后,该序列满足平稳性的要求了。
4)分解
所谓分解就是将时序数据分离成不同的成分。statsmodels使用的X-11分解过程,它主要将时序数据分离成长期趋势、季节趋势和随机成分。与其它统计软件一样,statsmodels也支持两类分解模型,加法模型和乘法模型,这里我只实现加法,乘法只需将model的参数设置为"multiplicative"即可。
from statsmodels.tsa.seasonal import seasonal_decompose
def decompose(timeseries):
# 返回包含三个部分 trend(趋势部分) , seasonal(季节性部分) 和residual (残留部分)
decomposition = seasonal_decompose(timeseries)
trend = decomposition.trend
seasonal = decomposition.seasonal
residual = decomposition.resid
plt.subplot(411)
plt.plot(ts_log, label='Original')
plt.legend(loc='best')
plt.subplot(412)
plt.plot(trend, label='Trend')
plt.legend(loc='best')
plt.subplot(413)
plt.plot(seasonal,label='Seasonality')
plt.legend(loc='best')
plt.subplot(414)
plt.plot(residual, label='Residuals')
plt.legend(loc='best')
plt.tight_layout()
plt.show()
return trend , seasonal, residual
trend , seasonal, residual = decompose(ts_log)
residual.dropna(inplace=True)
draw_trend(residual,12)
teststationarity(residual)结果如下

residual的均值、方差以及 DF结果

Test Statistic -6.332387e+00
p-value 2.885059e-08
#Lags Used 9.000000e+00
Number of Observations Used 1.220000e+02
Critical Value (1%) -3.485122e+00
Critical Value (5%) -2.885538e+00
Critical Value (10%) -2.579569e+00
dtype: float64如图所示,数据的均值和方差趋于常数,几乎无波动(看上去比之前的陡峭,但是要注意他的值域只有[-0.05,0.05]之间),所以直观上可以认为是稳定的数据。另外DFtest的结果显示,Statistic值原小于1%时的Critical value,所以在99%的置信度下,数据是稳定的。
4 时序数据的预测
在前面的分析可知,该序列具有明显的年周期与长期成分。对于年周期成分我们使用窗口为12的移动平进行处理,对于长期趋势成分我们采用1阶差分来进行处理。
rol_mean = ts_log.rolling(window=12).mean()
rol_mean.dropna(inplace=True)
ts_diff_1 = rol_mean.diff(1)
ts_diff_1.dropna(inplace=True)
teststationarity(ts_diff_1)结果如下
Test Statistic -2.709577
p-value 0.072396
#Lags Used 12.000000
Number of Observations Used 119.000000
Critical Value (1%) -3.486535
Critical Value (5%) -2.886151
Critical Value (10%) -2.579896
dtype: float64观察其统计量发现该序列在置信水平为95%的区间下并不显著,我们对其进行再次一阶差分。再次差分后的序列其自相关具有快速衰减的特点,t统计量在99%的置信水平下是显著的,这里我不再做详细说明。
ts_diff_2 = ts_diff_1.diff(1)
ts_diff_2.dropna(inplace=True)
teststationarity(ts_diff_2)结果如下
Test Statistic -4.443325
p-value 0.000249
#Lags Used 12.000000
Number of Observations Used 118.000000
Critical Value (1%) -3.487022
Critical Value (5%) -2.886363
Critical Value (10%) -2.580009
dtype: float64数据平稳后,需要对模型定阶,即确定p、q的阶数。先画出ACF,PACF的图像,代码如下:
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
def draw_acf_pacf(ts,lags):
f = plt.figure(facecolor='white')
ax1 = f.add_subplot(211)
plot_acf(ts,ax=ax1,lags=lags)
ax2 = f.add_subplot(212)
plot_pacf(ts,ax=ax2,lags=lags)
plt.subplots_adjust(hspace=0.5)
plt.show()
draw_acf_pacf(ts_diff_2,30)结果如下

观察上图,发现自相关和偏相系数都存在拖尾的特点,并且他们都具有明显的一阶相关性,所以我们设定p=1, q=1。下面就可以使用ARMA模型进行数据拟合了。(Ps.PACF是判定AR模型阶数的,也就是p。ACF是判断MA阶数的,也就是q)
from statsmodels.tsa.arima_model import ARIMA
model = ARIMA(ts_diff_1, order=(1,1,1))
result_arima = model.fit( disp=-1, method='css')模型拟合完后,我们就可以对其进行预测了。由于ARMA拟合的是经过相关预处理后的数据,故其预测值需要通过相关逆变换进行还原。
predict_ts = result_arima.predict()
# 一阶差分还原
diff_shift_ts = ts_diff_1.shift(1)
diff_recover_1 = predict_ts.add(diff_shift_ts)
# 再次一阶差分还原
rol_shift_ts = rol_mean.shift(1)
diff_recover = diff_recover_1.add(rol_shift_ts)
# 移动平均还原
rol_sum = ts_log.rolling(window=11).sum()
rol_recover = diff_recover*12 - rol_sum.shift(1)
# 对数还原
log_recover = np.exp(rol_recover)
log_recover.dropna(inplace=True)我们使用均方根误差(RMSE)来评估模型样本内拟合的好坏。利用该准则进行判别时,需要剔除“非预测”数据的影响。
ts = ts[log_recover.index] # 过滤没有预测的记录plt.figure(facecolor='white')
log_recover.plot(color='blue', label='Predict')
ts.plot(color='red', label='Original')
plt.legend(loc='best')
plt.title('RMSE: %.4f'% np.sqrt(sum((log_recover-ts)**2)/ts.size))
plt.show()结果如下

看上面的结果,均方根误差为11.8828,预测效果还是不错的。
5 总结
ARIMA的建模过程如下:
- 获取被观测系统时间序列数据;
- 对数据绘图,观测是否为平稳时间序列;对于非平稳时间序列要先进行d阶差分运算,化为平稳时间序列;
- 经过第二步处理,已经得到平稳时间序列。要对平稳时间序列分别求得其自相关系数ACF 和偏自相关系数PACF,通过对自相关图和偏自相关图的分析,得到最佳的阶层 p 和阶数 q
- 由以上得到的d、q、p,得到ARIMA模型。然后开始对得到的模型进行模型检验。
6 致谢
https://www.cnblogs.com/foley/p/5582358.html
https://www.cnblogs.com/bradleon/p/6832867.html