Stacked Autoencoders
博文内容参照网页Stacked Autoencoders,Stacked Autocoders是栈式的自编码器(参考网页Autoencoder and Sparsity和博文自编码与稀疏性),就是多层的自编码器,把前一层自编码器的输出(中间隐藏层)作为后一层自编码器的输入,其实就是把很多自编码器的编码部分叠加起来,然后再叠加对应自编码器的解码部分,这样就是一个含有多个隐含层的自编码器了。本博文介绍栈式自编码、微调栈式自编码算法,然后用栈式自编码算法实现MNIST的数字识别。
1、栈式自编码概述
前面博文Self-Taught Learning to Deep Networks说到训练深度网络可以采用逐层贪婪训练方法,每次只训练一个隐藏层,训练时可以采用有监督(比如对每一层隐藏层输入到softmax回归计算分类误差)或无监督(比如稀疏自编码),这里就采用无监督的稀疏自编码算法来学习隐藏层的特征。由于是多层的稀疏自编码神经网络,并且是逐层编码的,我们把它叫做stacked autocoders。
栈式自编码神经网络的编码步骤:
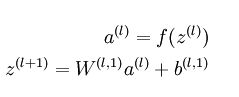
解码步骤为:

其实就类似hinton用栈式RBM组成的神经网络模型(论文是06年在science上发表的,有兴趣可以看看):
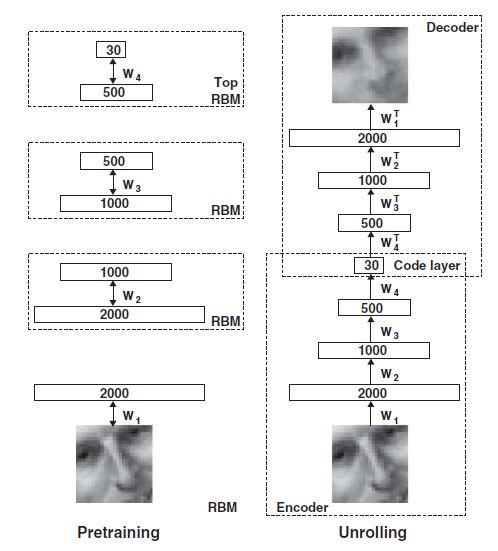
只是我们这里是用稀疏自编码器,而不是用RBM。
如果我们把最后一层隐藏层,即对原数据最高阶的特征表示,输入到softmax回归模型,就可以实现分类啦。把整个网络模型合起来得到:
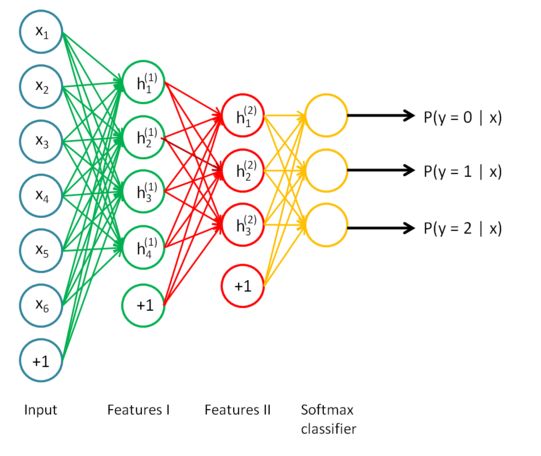
栈式自编码具有更强大的表达能力及深度网络的所有优点,自编码器倾向于学习到数据的特征表示,那么对于栈式自编码器,第一层可以学习到一阶特征,第二层可以学到二阶特征等等,对于图像而言,第一层可能学习到边,第二层可能学习到如何去组合边形成轮廓、点,更高层可能学习到更形象且更有意义的特征,学到的特征方便我们更好地处理图像,比如对图像分类、检索等等。
2、微调栈式自编码算法
前面也说过微调可以改善深度网络的学习效果,微调就是在原来训练好的模型参数下再稍微修改各层权重以更好地学习数据,哪该如何微调呢?没错,就是用BP算法(参考网页Backpropogation algorithm和博文浅谈神经网络),利用BP微调的算法如下:
要注意的是第二步中对输出层即softmax的输入层求导时,不是BP算法中的平方损失函数,而是softmax损失函数对x的求导,认真推算是可以得到那个表达式的。
3.Exercise:Implement deep networks for digit classification
该实验是用两层隐藏层是stacked autocoders + softmax对MNIST数字进行分类。
实验步骤:
- 初始化参数;
- 在原数据上训练第一个自编码器,然后算出L1 features;
- 在L1 features上训练第二个自编码器,然后算出L2 features;
- 在L2 features上训练softmax分类器;
- stacked autocoders+softmax模型,用BP算法微调参数;
- 测试模型

After Finetuning Test Accuracy: 98.210%
After Finetuning Test Accuracy: 97.430%
%% CS294A/CS294W Stacked Autoencoder Exercise
% Instructions
% ------------
%
% This file contains code that helps you get started on the
% sstacked autoencoder exercise. You will need to complete code in
% stackedAECost.m
% You will also need to have implemented sparseAutoencoderCost.m and
% softmaxCost.m from previous exercises. You will need the initializeParameters.m
% loadMNISTImages.m, and loadMNISTLabels.m files from previous exercises.
%
% For the purpose of completing the assignment, you do not need to
% change the code in this file.
%
%%======================================================================
%% STEP 0: Here we provide the relevant parameters values that will
% allow your sparse autoencoder to get good filters; you do not need to
% change the parameters below.
inputSize = 28 * 28;
numClasses = 10;
hiddenSizeL1 = 200; % Layer 1 Hidden Size
hiddenSizeL2 = 200; % Layer 2 Hidden Size
sparsityParam = 0.1; % desired average activation of the hidden units.
% (This was denoted by the Greek alphabet rho, which looks like a lower-case "p",
% in the lecture notes).
lambda = 3e-3; % weight decay parameter
beta = 3; % weight of sparsity penalty term
%%======================================================================
%% STEP 1: Load data from the MNIST database
%
% This loads our training data from the MNIST database files.
% Load MNIST database files
trainData = loadMNISTImages('mnist/train-images-idx3-ubyte');
trainLabels = loadMNISTLabels('mnist/train-labels-idx1-ubyte');
trainLabels(trainLabels == 0) = 10; % Remap 0 to 10 since our labels need to start from 1
%添加L-BFGS算法的目录路径
addpath minFunc/
%%======================================================================
%% STEP 2: Train the first sparse autoencoder
% This trains the first sparse autoencoder on the unlabelled STL training
% images.
% If you've correctly implemented sparseAutoencoderCost.m, you don't need
% to change anything here.
% Randomly initialize the parameters
sae1Theta = initializeParameters(hiddenSizeL1, inputSize);
%% ---------------------- YOUR CODE HERE ---------------------------------
% Instructions: Train the first layer sparse autoencoder, this layer has
% an hidden size of "hiddenSizeL1"
% You should store the optimal parameters in sae1OptTheta
%训练第一个自编码器
sae1OptTheta = sae1Theta;
options.Method = 'lbfgs';
options.maxIter = 400;
options.display = 'on';
[sae1OptTheta, cost] = minFunc( @(p) sparseAutoencoderCost(p, ...
inputSize, hiddenSizeL1, ...
lambda, sparsityParam, ...
beta, trainData), ...
sae1Theta, options);
% -------------------------------------------------------------------------
fprintf('第一个自编码器训练完成\n');
%%======================================================================
%% STEP 2: Train the second sparse autoencoder
% This trains the second sparse autoencoder on the first autoencoder
% featurse.
% If you've correctly implemented sparseAutoencoderCost.m, you don't need
% to change anything here.
%利用第一个自编码器的编码得到输入数据的一阶表示
[sae1Features] = feedForwardAutoencoder(sae1OptTheta, hiddenSizeL1, ...
inputSize, trainData);
% Randomly initialize the parameters
sae2Theta = initializeParameters(hiddenSizeL2, hiddenSizeL1);
%% ---------------------- YOUR CODE HERE ---------------------------------
% Instructions: Train the second layer sparse autoencoder, this layer has
% an hidden size of "hiddenSizeL2" and an inputsize of
% "hiddenSizeL1"
%
% You should store the optimal parameters in sae2OptTheta
%训练第二个自编码器
sae2OptTheta = sae2Theta;
[sae2OptTheta, cost] = minFunc( @(p) sparseAutoencoderCost(p, ...
hiddenSizeL1, hiddenSizeL2, ...
lambda, sparsityParam, ...
beta, sae1Features), ...
sae2Theta, options);
% -------------------------------------------------------------------------
fprintf('第二个自编码器训练完成\n');
%%======================================================================
%% STEP 3: Train the softmax classifier
% This trains the sparse autoencoder on the second autoencoder features.
% If you've correctly implemented softmaxCost.m, you don't need
% to change anything here.
% 利用第二个自编码器得到输入数据的二阶表示
[sae2Features] = feedForwardAutoencoder(sae2OptTheta, hiddenSizeL2, ...
hiddenSizeL1, sae1Features);
% Randomly initialize the parameters
saeSoftmaxTheta = 0.005 * randn(hiddenSizeL2 * numClasses, 1);
%% ---------------------- YOUR CODE HERE ---------------------------------
% Instructions: Train the softmax classifier, the classifier takes in
% input of dimension "hiddenSizeL2" corresponding to the
% hidden layer size of the 2nd layer.
%
% You should store the optimal parameters in saeSoftmaxOptTheta
%
% NOTE: If you used softmaxTrain to complete this part of the exercise,
% set saeSoftmaxOptTheta = softmaxModel.optTheta(:);
% 用softmax模型对二阶特征进行训练
options.maxIter = 100;
lambda = 1e-4;
softmaxModel = softmaxTrain(hiddenSizeL2, numClasses, lambda, ...
sae2Features, trainLabels, options);
saeSoftmaxOptTheta = softmaxModel.optTheta(:);
% -------------------------------------------------------------------------
fprintf('softmax训练完成\n');
%%======================================================================
%% STEP 5: Finetune softmax model
%微调,要计算出整个网络模型的损失函数和梯度
% Implement the stackedAECost to give the combined cost of the whole model
% then run this cell.
% Initialize the stack using the parameters learned
stack = cell(2,1);
stack{1}.w = reshape(sae1OptTheta(1:hiddenSizeL1*inputSize), ...
hiddenSizeL1, inputSize);
stack{1}.b = sae1OptTheta(2*hiddenSizeL1*inputSize+1:2*hiddenSizeL1*inputSize+hiddenSizeL1);
stack{2}.w = reshape(sae2OptTheta(1:hiddenSizeL2*hiddenSizeL1), ...
hiddenSizeL2, hiddenSizeL1);
stack{2}.b = sae2OptTheta(2*hiddenSizeL2*hiddenSizeL1+1:2*hiddenSizeL2*hiddenSizeL1+hiddenSizeL2);
% Initialize the parameters for the deep model
[stackparams, netconfig] = stack2params(stack);
stackedAETheta = [ saeSoftmaxOptTheta ; stackparams ]; %得到fine-tune前的模型参数
%% ---------------------- YOUR CODE HERE ---------------------------------
% Instructions: Train the deep network, hidden size here refers to the '
% dimension of the input to the classifier, which corresponds
% to "hiddenSizeL2".
%
%
%BP算法fine-tuning
[stackedAEOptTheta, cost] = minFunc( @(p) stackedAECost(p, inputSize, hiddenSizeL2, ...
numClasses, netconfig, ...
lambda, trainData, trainLabels), ...
stackedAETheta, options);
% -------------------------------------------------------------------------
fprintf('整个模型微调完成\n');
%%======================================================================
%% STEP 6: Test
% Instructions: You will need to complete the code in stackedAEPredict.m
% before running this part of the code
%
% Get labelled test images
% Note that we apply the same kind of preprocessing as the training set
testData = loadMNISTImages('mnist/t10k-images-idx3-ubyte');
testLabels = loadMNISTLabels('mnist/t10k-labels-idx1-ubyte');
testLabels(testLabels == 0) = 10; % Remap 0 to 10
[pred] = stackedAEPredict(stackedAETheta, inputSize, hiddenSizeL2, ...
numClasses, netconfig, testData);
acc = mean(testLabels(:) == pred(:));
fprintf('Before Finetuning Test Accuracy: %0.3f%%\n', acc * 100);
[pred] = stackedAEPredict(stackedAEOptTheta, inputSize, hiddenSizeL2, ...
numClasses, netconfig, testData);
acc = mean(testLabels(:) == pred(:));
fprintf('After Finetuning Test Accuracy: %0.3f%%\n', acc * 100);
% Accuracy is the proportion of correctly classified images
% The results for our implementation were:
%
% Before Finetuning Test Accuracy: 87.7%
% After Finetuning Test Accuracy: 97.6%
%
% If your values are too low (accuracy less than 95%), you should check
% your code for errors, and make sure you are training on the
% entire data set of 60000 28x28 training images
% (unless you modified the loading code, this should be the case)
stackedAECost.m
function [ cost, grad ] = stackedAECost(theta, inputSize, hiddenSize, ...
numClasses, netconfig, ...
lambda, data, labels)
% stackedAECost: Takes a trained softmaxTheta and a training data set with labels,
% and returns cost and gradient using a stacked autoencoder model. Used for
% finetuning.
% theta: trained weights from the autoencoder
% visibleSize: the number of input units
% hiddenSize: the number of hidden units *at the 2nd layer*
% numClasses: the number of categories
% netconfig: the network configuration of the stack
% lambda: the weight regularization penalty
% data: Our matrix containing the training data as columns. So, data(:,i) is the i-th training example.
% labels: A vector containing labels, where labels(i) is the label for the
% i-th training example
%% Unroll softmaxTheta parameter
% We first extract the part which compute the softmax gradient
softmaxTheta = reshape(theta(1:hiddenSize*numClasses), numClasses, hiddenSize);
% Extract out the "stack"
stack = params2stack(theta(hiddenSize*numClasses+1:end), netconfig);
% You will need to compute the following gradients
softmaxThetaGrad = zeros(size(softmaxTheta));
stackgrad = cell(size(stack));
for d = 1:numel(stack)
stackgrad{d}.w = zeros(size(stack{d}.w));
stackgrad{d}.b = zeros(size(stack{d}.b));
end
cost = 0; % You need to compute this
% You might find these variables useful
M = size(data, 2);
groundTruth = full(sparse(labels, 1:M, 1));
%% --------------------------- YOUR CODE HERE -----------------------------
% Instructions: Compute the cost function and gradient vector for
% the stacked autoencoder.
%
% You are given a stack variable which is a cell-array of
% the weights and biases for every layer. In particular, you
% can refer to the weights of Layer d, using stack{d}.w and
% the biases using stack{d}.b . To get the total number of
% layers, you can use numel(stack).
%
% The last layer of the network is connected to the softmax
% classification layer, softmaxTheta.
%
% You should compute the gradients for the softmaxTheta,
% storing that in softmaxThetaGrad. Similarly, you should
% compute the gradients for each layer in the stack, storing
% the gradients in stackgrad{d}.w and stackgrad{d}.b
% Note that the size of the matrices in stackgrad should
% match exactly that of the size of the matrices in stack.
%
depth = size(stack, 1);
a = cell(depth+1, 1);
a{1} = data; %输入层
Jweight = 0; %权重惩罚项
m = size(data, 2); %样本数
for i=2:numel(a)
a{i} = sigmoid(stack{i-1}.w*a{i-1}+repmat(stack{i-1}.b, [1 size(a{i-1}, 2)]));
%Jweight = Jweight + sum(sum(stack{i-1}.w).^2);
end
M = softmaxTheta*a{depth+1};
M = bsxfun(@minus, M, max(M, [], 1));
M = exp(M);
p = bsxfun(@rdivide, M, sum(M));
Jweight = Jweight + sum(sum(softmaxTheta.^2));
%与目标误差项+权重惩罚项
cost = -1/m .* groundTruth(:)'*log(p(:)) + lambda/2*Jweight;
%计算softmax层梯度
softmaxThetaGrad = -1/m .* (groundTruth - p)*a{depth+1}' + lambda*softmaxTheta;
%隐藏层节点误差,对z的求导
delta = cell(depth+1, 1);
%对最后一层隐藏层,即softmax的输入层求导,delta{depth+1}的每一列是对每个样本的求导
delta{depth+1} = -softmaxTheta' * (groundTruth - p) .* a{depth+1} .* (1-a{depth+1});
for i=depth:-1:2
delta{i} = stack{i}.w'*delta{i+1}.*a{i}.*(1-a{i});
end
for i=depth:-1:1
stackgrad{i}.w = 1/m .* delta{i+1}*a{i}';
stackgrad{i}.b = 1/m .* sum(delta{i+1}, 2);
end
% -------------------------------------------------------------------------
%% Roll gradient vector
grad = [softmaxThetaGrad(:) ; stack2params(stackgrad)];
end
% You might find this useful
function sigm = sigmoid(x)
sigm = 1 ./ (1 + exp(-x));
end
stackedAEPredict.m
function [pred] = stackedAEPredict(theta, inputSize, hiddenSize, numClasses, netconfig, data)
% stackedAEPredict: Takes a trained theta and a test data set,
% and returns the predicted labels for each example.
% theta: trained weights from the autoencoder
% visibleSize: the number of input units
% hiddenSize: the number of hidden units *at the 2nd layer*
% numClasses: the number of categories
% data: Our matrix containing the training data as columns. So, data(:,i) is the i-th training example.
% Your code should produce the prediction matrix
% pred, where pred(i) is argmax_c P(y(c) | x(i)).
%% Unroll theta parameter
% We first extract the part which compute the softmax gradient
softmaxTheta = reshape(theta(1:hiddenSize*numClasses), numClasses, hiddenSize);
% Extract out the "stack"
stack = params2stack(theta(hiddenSize*numClasses+1:end), netconfig);
%% ---------- YOUR CODE HERE --------------------------------------
% Instructions: Compute pred using theta assuming that the labels start
% from 1.
depth = numel(stack);
a = cell(depth+1);
a{1} = data;
m = size(data, 2);
for i=2:depth+1
a{i} = sigmoid(stack{i-1}.w*a{i-1}+ repmat(stack{i-1}.b, [1 m]));
end
[prob pred] = max(softmaxTheta*a{depth+1});
% -----------------------------------------------------------
end
% You might find this useful
function sigm = sigmoid(x)
sigm = 1 ./ (1 + exp(-x));
end