Top9竞赛总结-NLP语义相似度 第三届拍拍贷“魔镜杯”大赛

因为微信外链限制,读者可以在公众号AI圈终身学习(ID:AIHomie)首页回复“2018语义相似度”,或者复制文中的链接在浏览器中打开外链。
目录
- 语义相似度任务介绍
- 数据介绍
- 模型介绍
- 数据增强、Finetune与模型融合
- 个人经验
- Trick
- 总结
作者介绍
殷剑宏,江湖人称Yin叔,业余做各种数据竞赛,喜欢NLP和交通类的竞赛。以下是部分竞赛参赛经历:
2016年 DataCastle 微博热度预测竞赛 第二名
2017年 DataCastle&成都市政府 智慧中国杯交通算法赛 第二名
2017年 Biendata&中国人工智能学会 知乎看山杯机器学习挑战赛 第七名
2017年 Biendata&中国人工智能学会 摩拜杯算法挑战赛 第一名
2018年 Biendata神州优车UAI数据大赛 第二名
2018年 Datafountain云移杯景区口碑评价分值预测 第一名
2018年 拍拍贷第三届魔镜杯大赛 第九名
2018年 DataCastle 华录杯 公交线路准点预测 第一名
2018年 DataCastle 达观杯 文本智能处理挑战赛 第五名
一、语义相似度任务介绍
第三届“魔镜杯”由拍拍贷智慧金融研究院主办,总奖池高达10万美金,是一个问题相似度问题。“问题相似度计算”这个问题,顾名思义,就是判断两个问题是否表达相同的含义。
比如用户询问:“彩虹年化多少?”就和知识库的“彩虹产品收益率”相似,从而app可以触发相应的业务。
语义相似度是NLP领域很重要的一个任务,有非常大的应用价值。目前它常用于:
- 通过标注数据找寻新的相似未标注数据,从而扩充训练集(和本题无关)
- 智能客服,计算客户提出的问题与知识库中问题的相似度(本赛题)
不论是在这个比赛之前,还是这个比赛之后,国内外竞赛平台都有很多类似题目,比如:
- Kaggle Quora
- 天池 CIKM
- 蚂蚁金服
笔者在2018年也投入了很多精力研究这个任务,因此有一些心得体会。为了巩固自身知识体系,并且可以帮助一些对NLP语义相似度比赛或任务感兴趣的朋友,我在DataCastle产出了自己的视频、PPT和开源代码。如果本文看得不过瘾的朋友可以作为额外的知识补充。
我比较高兴的是,在之后的比赛中,有选手也参考这个课程取得了不错的成绩。
感兴趣的同学可以看看,获取方式已经在文首给出。
二、数据介绍
2.1 任务定义
魔镜杯比赛的任务非常明确,就是给定一个句子q1和另一个句子q2,系统自动判断这两个句子的含义:
- 相同(label=1)
- 不同(label=0)。
2.2 数据集
拍拍贷提供真实客服对话数据,其中训练集25万条,正例(label=1)12万条,负例(label=0)13万条,样本较均衡。测试集17万条。
本次比赛使用了脱敏数据,所有原始文本信息都被编码成单字ID序列和词语ID序列,并提供由google word2vec训练的300维的word_embedding和char_embedding。
我们初步对数据集进行分析,发现该数据集有三个特点:
- 正负样本均衡
- 问题较短,最长39个词,58个字
- 语义相似正样本中(label=1),q1、q2相同词不多
2.3 评价指标
l o g l o s s = − ( y log ( p ) + ( 1 − y ) log ( 1 − p ) ) logloss=-{(y\log(p) + (1 - y)\log(1 - p))} logloss=−(ylog(p)+(1−y)log(1−p))
三、模型介绍
在传统的NLP语义相似度任务中,如果我们按照从原始特征到最终得到语义相似度的过程,在这个过程中我们需要考虑这样两个个问题:
- 如何把文本转化为机器可以学习的数据?
- 句子的相似我们是指语义上的相似,怎么抽取句子的语义信息,然后计算它们的距离呢?
没有使用传统的比较方法:比如计算公共子串、相同的词的比例、编辑距离等,因为本题目中句子都比较短、相同词少。所以需要更侧重于语义上的相似性,而不是简单的字面的相似。
由于官方直接提供了训练好的词向量,因此我们没有做更多的处理。我们使用的深度学习模型,模型分编码器和交互层两个主要部分,他们主要的作用是:
- 编码器:更好的把文本特征转成机器可以学习的数据
- 交互层:怎么样更好的计算句子的语义相似度
接下来我们分别展开。
3.1 编码器
我们的编码器长这个样子:
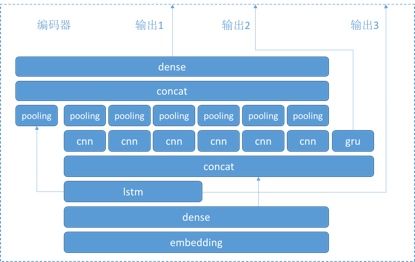
对照着我们的模型图看,总结起来我们的编码器有很多特点:
- q1、q2共享编码器
- 拼接lstm的输出和embedding的词向量
- 6中不同宽度的卷积层(cnn)
- 输出max-pooling拼接的编码
- 输出LSTM层每个时间步的编码
- 输出GRU层每个时间步的编码
这样设计的编码器,主要优点是使用了LSTM和CNN等多种编码方式,生成更好的句子向量。
3.2 交互层
我们的交互层长这个样子:
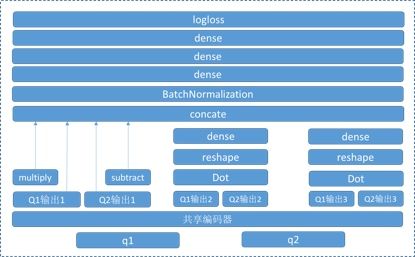
其中共享编码器即我们3.1节介绍的编码器层,对照着模型图,可以看出我们交互层的主要特点是:
- 对向量编码做subtract比较
- 对向量编码做multiply比较
- 对向量编码做直接输入dense层比较
- 对LSTM和GRU的输出序列做Dot (每个时间步的输出向量的夹角余弦)
- 融合了多种交互比较方式
因此他有以下优点能更好的计算q1和q2的语义相似度:
- 对句子向量做subtract、multiply等多种方式的比较
- 两次对时间步序列进行比较 每个时间步的输出向量的求夹角余弦
- 融合了多种交互比较方式,模型具有很好稳定性
四、数据增强、Finetune与模型融合
4.1 数据增强
数据增强:
- 正样本:训练集里正样本经过一次相等关系的传递,得到更多正样本
- 负样本:训练集里的问题随机配对
4.2 Finetune
- Embeding层各维度加dropout(跳过单词,跳过某维词向量)
- Embeding层开放/不开放train
- 微调dense层节点数
- 增加反向的LSTM
- 修改随机种子,训练集和验证集分劈方式 在字和词的层面分别进行模型训练
4.3 模型融合
我的融合是把多种模型的结果再取平均值。
多种有差异性的模型都判断一个样本有较大的相似概率时,例如:平均值=0.98,可以进一步增加这个概率值到0.998。
五、个人经验
我没有直接照搬现成的开源模型,而是自己耐心构造和调试了模型,这样可以更好的获得经验。下面是几点心得体会:
- 模型要有足够的复杂度
- 灵活应用层并列、层堆叠、跨层的连接等技巧
- 交互比较层的思路
- 调整好dropout
- 合理的学习速率和batch大小
现在有了开源的BERT模型,以后如果比赛数据不脱敏,估计会是BERT这类预训练模型一统天下了吧,我不知道。但个人觉得少了很多的乐趣啊。
六、trick
6.1 两次训练
- 先用原始的训练集训练,保存模型权重。
- 再用数据增强后的训练集训练,得到最终的模型。
6.2 10Fold CV
对每个模型做10Fold CV,对预测结果取平均值。
6.3 两次预测
对测试集的每个样本,先预测一次。交换q1q2的位置,再预测1次,取平均值。
6.4 传递闭包
对训练集中的相等关系求传递闭包,根据传递性修正预测结果,如:
q1=q2 q2=q3 => q1=q3
q1=q2 q2!=q3 => q1!=q3
6.5 不严格的负样本:
q1在训练集中有多个相似问题,q2在训练集中也有多个相似问题,但q1和q2的相似问题无交集,可以配合预测结果降低q1q2相似的概率。
七、总结
我们的成绩当然还有进一步提高的空间,比如:
- 没有对深度学习模型添加人工特征
- 受限于计算资源,没有做很多不同的模型,只是对一个模型做了多种微调
这次比赛做了很多事情,也学了很多东西,但是我始终是站在更符合实际业务场景需求的角度去做的这个比赛,比如:
- 我只利用了训练集相似关系的传递性做数据增强和后处理
- 没有把测试集和训练集拼接在一起做图特征,因为没有实际业务意义
- 没有使用伪标签等把测试集加入训练的技术,因为没有实际业务意义
虽然影响了成绩,但是得到了主办方的肯定和敬意。
最后感谢您的阅读,如果本文看得不过瘾的朋友可以看看我的相关PPT、视频和开源代码,作为额外的知识补充:
https://www.dcxueyuan.com/classDetail/classIntroduce/34/page.html (ps:DataCastle官方平台,需收费9.9)
【推荐阅读】
如何到top5%?NLP文本分类和情感分析竞赛总结
问题对语义相似度计算-参赛总结
如何成为竞赛大佬?AI圈为学习者们的第一次尝试
注:因微信bug,留言请点左下方的阅读原文蓝字。
点个好看鼓励小编~