一、MapReduce入门
在使用java编写MaReduce程序之前,先让我们解决一个基本问题——MapReduce是什么?它的运行机制是怎么样的?
能够打开这篇文章的读者,应该或多或少都有一些技术基础。但是为了使得下面的解说更加清楚明白,这里还是要简单描述一下。
一、MapReduce是什么
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言
里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)
函数,用来保证所有映射的键值对中的每一个共享相同的键组。
——百度百科
是不是还没看懂?用一句话总结一下:
MapReduce是一种适用于大数据下分布式并行计算的编程模型,只要按照规定完成Map(分发数据)和Reduce(处理数据)两部分工作,就可以快速得出结果。
二、MapReduce的运行机制
从MapReduce的名字以及上面的介绍中,应该也可以知道,MapReduce实现中最重要的两个概念:Map和Reduce
1、Map
Map的任务是:处理原始数据、为数据打标签、对数据进行分发(严格来说这并不完全是map的职责)
处理原始数据
这一阶段是对原始数据进行预处理的阶段,可以从行和列两个角度来考虑。
行:比如我们需要对数据按照时间过滤,只选择本周一的数据,其他数据过滤掉不处理。
列:比如原始数据有10列,我们只需要其中的5列,其他列过滤掉不处理。
举例:
hdfs上有一周的支出数据,我们想统计周一周二的支出情况,接下来我们会一步步解释这个过程。下图是其中一部分记录:

map:处理原始数据
可以看出过滤掉了非周一周二的数据,并且删除了使用人的字段。
为数据打标签
map处理完原始数据之后,接下来就要将数据分组,从而分配给合适的reduce去处理,分组的第一步就是打标签。
举例:

map:为数据打标签
可以看出,对每一条数据加了一条对应天数的标签。
对数据进行分发
打完标签之后,就需要对数据进行分发,严格来说,这并不完全属于Map的职责,其中也用到了一个神秘的中间环节:shuffle。不过入门来看,我们就单纯任务这属于Map。
分发的意思是,打完标签之后,要对数据进行分类处理,然后再发送给Reduce;分类的依据,就是上面对其打的自定义标签。
举例:

map:分发有标签的数据
可以看出,对每一条数据,按照标签分配,由原来的一个列表,变成了现在的两个列表。
Map阶段到此完成,接下来的任务就是要等着Reduce来取数了。
2、Reduce
Reduce的任务是:拉取Map分类好的数据(这也并不完全是Reduce的职责)、执行具体的计算
2.1、拉取Map分类好的数据
之前说到,Map已经将数据分类,我们直接拉取Reduce需要的数据就好了;但是要注意的是,我们是在一个分布式的环境中执行的任务,所以,Reduce的数据来源可能是多个Map中属于自己的块。
举例:

reduce:获取map分发的数据
可以看到,Reduce按照Map分类的key拉取到了自己应该处理的当日数据。
2.2、执行具体的计算
Reduce在拿到所有自己的数据之后,接下来就可以执行自定义的计算逻辑了,最简单的就是计数、去重。
举例:

reduce:执行具体的计算
可以看到,Reduce已经完成了所需要的单日支出计算功能。
说明
Map和Reduce的职责并不是完全绝对的,比如过滤操作可以在Map,也可以在Reduce,只是因为在Map做可以减少传输的数据量,减少网络IO压力和时间消耗,所以做了上述的分工。
三、拯救你于水火之中
如果以上说明还不够形象的话,那么可以参考下面这句话:
如果我们的任务是数清楚一袋子水果糖里,不同口味的糖有多少块。那么Map就是把糖分类,比如苹果味的放在第一个盘子里,草莓味的放在第二个盘子里;而Reduce就是执行的具体的计算任务,比如一个人数第一个盘子里的苹果味糖有几块,另一个人数第二个盘子里的草莓味糖有几块。最后通过这两个阶段来完成最开始的目标。
四、图解MapReduce原理
硬核,慎入!
之前说的原理更多的是从单个Map或者Reduce角度进行讲解的,接下来我们从整个集群的角度去看一下一个MapReduce任务的具体执行过程。
不说废话,先上图。

MapReduce工作原理原理
1 map先从HDFS上读取不同的文件,然后对其进行map操作,生成一个个带有标签(也就是key)的数据块。
2 带有相同标签(key)的数据块,会被分配到同一个Reduce上进行操作,从而得到最终结果,并将最终结果写回HDFS。
再看一个更细节一点的:单词计数的MapReduce执行过程
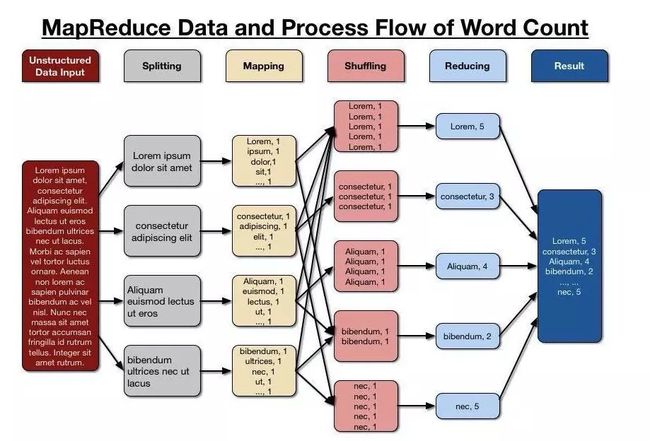
单词计数的MapReduce流程
1 可以看到因为不是自带分区的文件,而是文本文件,所以多了一个拆分的步骤。
2 接下来对分割的文本进行Map阶段的操作,其分发的标签(key)是单词本身,分发的内容是每一段文本里出现该单词的数量。
3 接下来会进行一个分发操作,即相同标签(key)的数据会被收集到一起。
4 Reduce对收集之后分配过来的数据进行处理,最终结果汇总,就是单词计数的结果。