大数据常见面试题整理
今年参加了校园秋招,主要针对招聘大数据研发相关岗位,最后也如愿以偿找到了大数据软件开发的工作,在此期间整理了一下比较常见的相关面试题。
1.Mapreduce实际处理过程:
Input ![]() Map
Map ![]() Sort
Sort![]() Combine
Combine![]() Partition
Partition![]() Reduce
Reduce![]() Output
Output
2.列出Yarn中的关键组件,并简述各关键组件内部的交互原理。
Yarn资源管理框架包括ResourceManager(资源管理器)、ApplicationMaster、NodeManager(节点管理器)。
ResourceManager是一个全局的资源管理器,负责整个系统的资源管理和分配,由两个组件组成:sheduler(调度器)和ApplicationManager(应用程序管理器)。sheduler负责分配最少但满足Application运行所需要的资源给Application,ApplicationManager负责处理客户端提交的job以及协商第一个container以供ApplicationMaster运行,并且在ApplicationMaster运行,并且在ApplicationMaster失败的时候重启ApplicationMaster。
ApplicationMaster是一个框架特殊的库,主要管理和监控部署在Yarn集群上的各种应用。
NodeManager主要负责启动ResourceManager分配给ApplicationMaster的container,并且会监视container的运行情况。
3.Mapreduce的原理理解。
(1)把文件分片分别到各个Mapper中;
(2)Mapper中的Inputformat负责读取记录,Mapper负责记录怎么解析重新组织成新的格式,并把处理结果进行排序;
(3)shuffle吧取到的结果送给Reduce中的sort,由sort负责把所有Mapper的结果排好序,然后送给Reduce来进行汇总以得到最终结果;
(4)Reduce中的Outputformat记录到规定位置并存档。
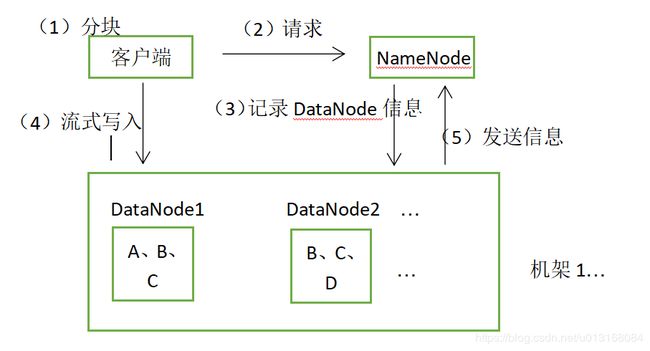
4.HDFS上传文件流程。
(1)客户端将要上传的文件按照128MB的大小分块;
(2)客户端向名称节点发送写数据请求;
(3)名称节点记录各个DataNode信息,并返回可用的DataNode列表;
(4)客户端直接向DataNode发送分割后的文件块,发送过程以流式写入;
(5)写入完成后,DataNode向NameNode发送信息,更新元数据。
整理流程框架如下图所示。
5.介绍zookeeper。
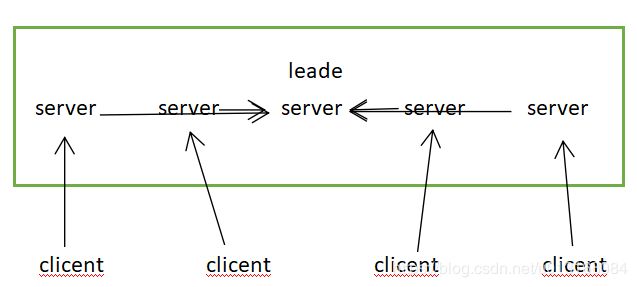
zookeeper用来解决分布式应用中的一些数据管理问题,如统一命名服务、状态同步服务、集群管理等。
一个leader:主要负责写服务和数据同步。
多个follower:提供读服务,leader失效后会在follower中重新选举新的leader。
需要注意的是:
(1)客户端可以连接到每一个server,每个server的数据完全相同;
(2)每个follower都和leader有连接,接受leader的数据更新操作;
(3)server记录事务日志和快照到持久存储;
(4)大多数server可用,整体服务就可用。
整体框架图如下所示。
配置:环境变量![]() 配置文件zoo.cfg(添加datadir路径)
配置文件zoo.cfg(添加datadir路径)![]() 创建myid文件(添加server的ip地址)
创建myid文件(添加server的ip地址)
6.NameNode在启动的时候会做哪些操作?
NameNode启动的时候,会加载fsimage。NameNode从fsimage中不停地顺序读取文件与目录的元数据信息。
7.hive中外部表和内部表的区别。
(元数据存储在/root/hive/warehouse)
内部表:数据存储在hive的数据仓库目录下,删除表时,除了删除元数据,还会删除实际表文件。(删表删数据)
外部表:数据并不存储在hive的数据仓库目录下,删除表时,只是删除元数据,并不删除实际表文件。(删表不删数据)
8.MapReduce中combiner和partition的区别。
combiner就是在map端先进行一次reduce操作,减少map端到reduce端的数据传输量,省网络带宽,提高执行效率。
partition就是将map输出按key分区,送到不同的reduce上去并行执行,提高效率。
9.hive中的分区表和桶表。
分区表:避免在查询中扫描整个表内容,会消耗很多时间做没必要的工作。
桶表:对指定列计算hash,根据hash值切分数据,目的是并行,每个桶对应一个文件。
10.hadoop建立动态节点步骤:
(1)在新节点安装好Hadoop,并把namenode的有关配置文件复制到该节点;
(2)修改namenode节点的master和salves文件,增加该节点;
(3)设置各节点ssh免密码进出该节点,设置ip映射;
(4)单独启动该节点上的datanode与nodemanager;
(5)运行start-balancer.sh进行数据负载均衡。