干货 | 阿里巴巴混沌测试工具ChaosBlade两万字解读
点击上方“朱小厮的博客”,选择“设为星标”
回复”1024“获取独家整理的学习资料
欢迎跳转到本文的原文链接:https://honeypps.com/chaos/alibaba-chaos-tool-chaosblade-analysis/
一、前言
ChaosBlade 是一款遵循混沌工程实验原理,建立在阿里巴巴近十年故障测试和演练实践基础上,并结合了集团各业务的最佳创意和实践,提供丰富故障场景实现,帮助分布式系统提升容错性和可恢复性的混沌工程工具。

Chaosblade 可直接编译运行,cli 命令提示使执行混沌实验更加简单。目前支持的演练场景有操作系统类的 CPU、磁盘、进程、网络,Java 应用类的 Dubbo、MySQL、Servlet 和自定义类方法延迟或抛异常等以及杀容器、杀 Pod,具体可执行 blade create -h 查看:
Create a chaos engineering experiment
Usage:
blade create [command]
Aliases:
create, c
Examples:
create dubbo delay --time 3000 --offset 100 --service com.example.Service --consumer
Available Commands:
cplus c++ experiment
cpu Cpu experiment
disk Disk experiment
docker Execute a docker experiment
druid Druid experiment
dubbo dubbo experiment
http http experiment
jvm method
k8s Kubernetes experiment
mysql mysql experiment
network Network experiment
process Process experiment
rocketmq Rocketmq experiment,can make message send or pull delay and exception
script Script chaos experiment
servlet java servlet experiment
Flags:
-h, --help help for create
Global Flags:
-d, --debug Set client to DEBUG mode
Use "blade create [command] --help" for more information about a command.
在分布式架构环境下,服务间的依赖日益复杂,可能没有人能说清单个故障对整个系统的影响,构建一个高可用的分布式系统面临着很大挑战。在可控范围或环境下,使用 ChaosBlade 工具,对系统注入各种故障,持续提升分布式系统的容错和弹性能力,以构建高可用的分布式系统。
github地址: https://github.com/chaosblade-io/chaosblade
二、概述
1. ChaosBlade 能解决哪些问题?
1)衡量微服务的容错能力
通过模拟调用延迟、服务不可用、机器资源满载等,查看发生故障的节点或实例是否被自动隔离、下线,流量调度是否正确,预案是否有效,同时观察系统整体的 QPS 或 RT 是否受影响。在此基础上可以缓慢增加故障节点范围,验证上游服务限流降级、熔断等是否有效。最终故障节点增加到请求服务超时,估算系统容错红线,衡量系统容错能力。
2)验证容器编排配置是否合理
通过模拟杀服务 Pod、杀节点、增大 Pod 资源负载,观察系统服务可用性,验证副本配置、资源限制配置以及 Pod 下部署的容器是否合理。
3)测试 PaaS 层是否健壮
通过模拟上层资源负载,验证调度系统的有效性;模拟依赖的分布式存储不可用,验证系统的容错能力;模拟调度节点不可用,测试调度任务是否自动迁移到可用节点;模拟主备节点故障,测试主备切换是否正常。
4)验证监控告警的时效性
通过对系统注入故障,验证监控指标是否准确,监控维度是否完善,告警阈值是否合理,告警是否快速,告警接收人是否正确,通知渠道是否可用等,提升监控告警的准确和时效性。
5)定位与解决问题的应急能力
通过故障突袭,随机对系统注入故障,考察相关人员对问题的应急能力,以及问题上报、处理流程是否合理,达到以战养战,锻炼人定位与解决问题的能力。
2. 功能和特点
1)场景丰富度高
ChaosBlade 支持的混沌实验场景不仅覆盖基础资源,如 CPU 满载、磁盘 IO 高、网络延迟等,还包括运行在 JVM 上的应用实验场景,如 Dubbo 调用超时和调用异常、指定方法延迟或抛异常以及返回特定值等,同时涉及容器相关的实验,如杀容器、杀 Pod。后续会持续的增加实验场景。
2)使用简洁,易于理解
ChaosBlade 通过 CLI 方式执行,具有友好的命令提示功能,可以简单快速的上手使用。命令的书写遵循阿里巴巴集团内多年故障测试和演练实践抽象出的故障注入模型,层次清晰,易于阅读和理解,降低了混沌工程实施的门槛。
3)场景扩展方便
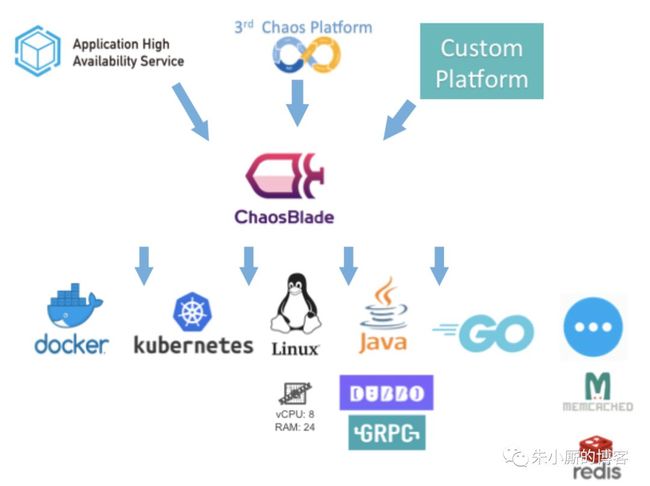
Ecosystem Architecture
3. ChaosBlade 的演进史
EOS(2012-2015):
故障演练平台的早期版本,故障注入能力通过字节码增强方式实现,模拟常见的 RPC 故障,解决微服务的强弱依赖治理问题。
MonkeyKing(2016-2018):
故障演练平台的升级版本,丰富了故障场景(如:资源、容器层场景),开始在生产环境进行一些规模化的演练。
AHAS(2018.9-至今):
阿里云应用高可用服务,内置演练平台的全部功能,支持可编排演练、演练插件扩展等能力,并整合了架构感知和限流降级的功能。
ChaosBlade(2019.3):
是 MonkeyKing 平台底层故障注入的实现工具,通过对演练平台底层的故障注入能力进行抽象,定义了一套故障模型。配合用户友好的 CLI 工具进行开源,帮助云原生用户进行混沌工程测试。
4. 组件架构
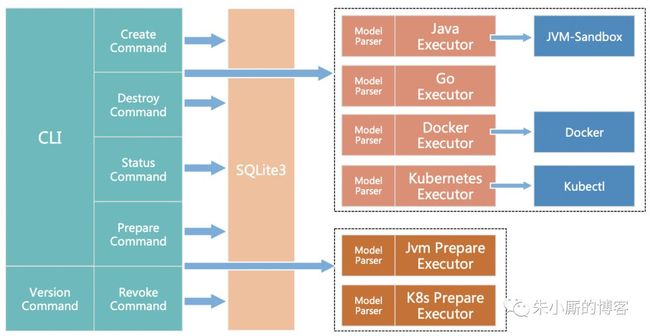
Component Architecture
-
Cli 包含 create、destroy、status、prepare、revoke、version 6 个命令
-
相关混沌实验数据使用 SQLite 存储在本地(chaosblade 目录下)
-
Create 和 destroy 命令调用相关的混沌实验执行器创建或者销毁混沌实验
-
Prepare 和 revoke 命令调用混沌实验准备执行器准备或者恢复实验环境,比如挂载 jvm-sandbox
-
混沌实验和混沌实验环境准备记录都可以通过 status 命令查询
三、ChaosBlade使用指南
获取 ChaosBlade 最新的 release 包,目前支持的平台是 linux/amd64 和 darwin/64,下载对应平台的包。
wget https://github.com/chaosblade-io/chaosblade/releases/download/v0.2.0/chaosblade-0.2.0.linux-amd64.tar.gz
下载完成后解压即可,无需编译。解压后的目录如下:
.
├── bin
│ ├── chaos_burncpu
│ ├── chaos_burnio
│ ├── chaos_changedns
│ ├── chaos_delaynetwork
│ ├── chaos_dropnetwork
│ ├── chaos_filldisk
│ ├── chaos_killprocess
│ ├── chaos_lossnetwork
│ ├── chaos_stopprocess
│ ├── cplus-chaosblade.spec.yaml
│ ├── jvm.spec.yaml
│ └── tools.jar
├── blade
└── lib
├── cplus
│ ├── chaosblade-exec-cplus.jar
│ └── script
│ ├── shell_break_and_return_attach.sh
│ ├── shell_break_and_return.sh
│ ├── shell_check_process_duplicate.sh
│ ├── shell_check_process_id.sh
│ ├── shell_initialization.sh
│ ├── shell_modify_variable_attch.sh
│ ├── shell_modify_variable.sh
│ ├── shell_remove_process.sh
│ ├── shell_response_delay_attach.sh
│ └── shell_response_delay.sh
└── sandbox
├── bin
│ └── sandbox.sh
├── cfg
│ ├── sandbox-logback.xml
│ ├── sandbox.properties
│ └── version
├── example
│ └── sandbox-debug-module.jar
├── install-local.sh
├── lib
│ ├── sandbox-agent.jar
│ ├── sandbox-core.jar
│ └── sandbox-spy.jar
├── module
│ ├── chaosblade-java-agent-0.2.0.jar
│ └── sandbox-mgr-module.jar
└── provider
└── sandbox-mgr-provider.jar
其中 blade 是可执行文件,即 chaosblade 工具的 cli,混沌实验执行的工具。执行 ./blade help 可以查看支持命令有哪些:
zhuzhonghua@n224-008-172:~/chaos/chaosblade-0.2.0$ ./blade help
An easy to use and powerful chaos engineering experiment toolkit
Usage:
blade [command]
Available Commands:
create Create a chaos engineering experiment
destroy Destroy a chaos experiment
help Help about any command
prepare Prepare to experiment
query Query the parameter values required for chaos experiments
revoke Undo chaos engineering experiment preparation
status Query preparation stage or experiment status
version Print version info
Flags:
-d, --debug Set client to DEBUG mode
-h, --help help for blade
Use "blade [command] --help" for more information about a command.
blade 命令列表如下:
-
prepare:简写 p,混沌实验前的准备,比如演练 Java 应用,则需要挂载 java agent。要演练应用名是 business 的应用,则在目标主机上执行 blade p jvm --process business。如果挂载成功,返回挂载的 uid,用于状态查询或者撤销挂载使用。
-
revoke:简写 r,撤销之前混沌实验准备,比如卸载 java agent。命令是 blade revoke UID
-
create: 简写是 c,创建一个混沌演练实验,指执行故障注入。命令是 blade create [TARGET] [ACTION] [FLAGS],比如实施一次 Dubbo consumer 调用 xxx.xxx.Service 接口延迟 3s,则执行的命令为 blade create dubbo delay --consumer --time 3000 --service xxx.xxx.Service,如果注入成功,则返回实验的 uid,用于状态查询和销毁此实验使用。
-
destroy:简写是 d,销毁之前的混沌实验,比如销毁上面提到的 Dubbo 延迟实验,命令是 blade destroy UID
-
status:简写 s,查询准备阶段或者实验的状态,命令是 blade status UID 或者 blade status --type create
以上命令帮助均可使用 blade help [COMMAND]。
应用示例
首先我们来演示一下CPU使用率100%的故障,即使用blade create cpu fullload命令。blade create cpu的用法如下:
hidden@hidden:~/chaos/chaosblade-0.2.0$ ./blade create cpu -h
Cpu experiment, for example full load
Usage:
blade create cpu [flags]
blade create cpu [command]
Examples:
cpu fullload
Available Commands:
fullload cpu fullload
Flags:
--cpu-count string Cpu count
--cpu-list string CPUs in which to allow burning (0-3 or 1,3)
-h, --help help for cpu
Global Flags:
-d, --debug Set client to DEBUG mode
Use "blade create cpu [command] --help" for more information about a command.
执行实验:
hidden@hidden:~/chaos/chaosblade-0.2.0$ ./blade create cpu fullload
{"code":200,"success":true,"result":"d9e3879cb68416a2"}
注意上面的result: d9e3879cb68416a2中的d9e3879cb68416a2,这个在停止实验的时候会用到(./blade destroy UID)。
采用iostat -c 1 1000命令查看CPU使用率(%idle):
avg-cpu: %user %nice %system %iowait %steal %idle
98.75 0.00 1.25 0.00 0.00 0.00
查看CPU的使用率还可以使用sar命令、top命令等。
此时命令已经生效。下一步停止实验,执行:
hidden@hidden:~/chaos/chaosblade-0.2.0$ ./blade destroy d9e3879cb68416a2
{"code":200,"success":true,"result":"command: cpu fullload --debug false --help false"}
再观察CPU的情况,负载已经回到正常状态:
avg-cpu: %user %nice %system %iowait %steal %idle
0.25 0.00 0.50 2.00 0.00 97.25
至此,一次CPU满负荷的故障演练完成。
三、ChaosBlade 模型实现
1. 模型定义
遵循此模型,可以简单明了的执行一次混沌实验,控制实验的最小爆炸半径。并且可以方便快捷的扩展新的实验场景或者增强现有场景。chaosblade 和 chaosblade-exec-jvm 工程都根据此模型实现。
在给出模型之前先讨论实施一次混沌实验明确的问题:
-
对什么做混沌实验?
-
混沌实验实施的范围是是什么?
-
具体实施什么实验?
-
实验生效的匹配条件有哪些?
举个例子:一台 ip 是 10.0.0.1 机器上的应用,调用 [email protected] Dubbo 服务延迟 3s。根据上述的问题列表,先明确的是要对 Dubbo 组件混沌实验,实施实验的范围是 10.0.0.1 单机,对调用 [email protected] 服务模拟 3s 延迟。明确以上内容,就可以精准的实施一次混沌实验,抽象出以下模型:

-
Target:实验靶点,指实验发生的组件,例如 容器、应用框架(Dubbo、Redis、Zookeeper)等。
-
Scope:实验实施的范围,指具体触发实验的机器或者集群等。
-
Matcher:实验规则匹配器,根据所配置的 Target,定义相关的实验匹配规则,可以配置多个。由于每个 Target 可能有各自特殊的匹配条件,比如 RPC 领域的 HSF、Dubbo,可以根据服务提供者提供的服务和服务消费者调用的服务进行匹配,缓存领域的 Redis,可以根据 set、get 操作进行匹配。
-
Action:指实验模拟的具体场景,Target 不同,实施的场景也不一样,比如磁盘,可以演练磁盘满,磁盘 IO 读写高,磁盘硬件故障等。如果是应用,可以抽象出延迟、异常、返回指定值(错误码、大对象等)、参数篡改、重复调用等实验场景。
回到上述的例子,可以叙述为对 Dubbo 组件(Target)进行故障演练,演练的是 10.0.0.1 主机(Scope)的应用,调用 [email protected] (Matcher)服务延迟 3s(Action)。
伪代码可以写成:
Toolkit.
// 实验靶点
dubbo.
// 范围,此处是主机
host("1.0.0.1").
// 组件匹配器,消费者还是服务提供者
consumer().
// 组件匹配器,服务接口
service("com.example.HelloService").
// 组件匹配器,1.0.0 接口版本
version("1.0.0").
// 实验场景,延迟 3s
delay(3000);
针对上述例子,ChaosBlade 调用命令是:
blade create dubbo delay --time 3000 --consumer --service com.example.HelloService --version 1.0.0
-
dubbo: 模型中的 target,对 dubbo 实施实验。
-
delay: 模型中的 action,执行延迟演练场景。
-
--time: 模型中 action 参数,指延迟时间。
-
--consumer、--service、--version:模型中的 matchers,实验规则匹配器。
注:由于 ChaosBlade 是在单机执行的工具,所以混沌实验模型中的 scope 默认为本机,不再显示声明。
2. ChaosBlade 模型结构
为了有个更加直观的认识,我们先通过一下的模型结构图来大致看一下模型之间的关系。核心接口模型是:ExpModelCommandSpec,由它引申出来的是ExpActionCommandSpec和ExpFlagSpec这两个接口。其中,ExpModelCommandSpec已有的具体实现有:cpu、network、disk等;ExpActionCommandSpec则是如cpu下的fullload之类的;ExpFlagSpec是各类自定义参数,比如--timeout。
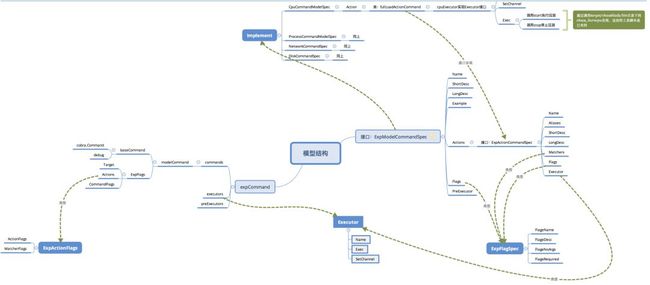
ChaosBlade 模型定义
// ExpModelCommandSpec defines the command interface for the experimental plugin
type ExpModelCommandSpec interface {
// FlagName returns the command FlagName
// 组件名称
Name() string
// Actions returns the list of actions supported by the command
// 支持的场景列表
Actions() []ExpActionCommandSpec
// <snip>
}
注:一个组件混沌实验模型的定义,包含组件名称和所支持的实验场景列表。
// ExpActionCommandSpec defines the action command interface for the experimental plugin
type ExpActionCommandSpec interface {
// FlagName returns the action FlagName
// 演练场景名称
Name() string
// Matchers returns the list of matchers supported by the action
// 规则匹配器列表
Matchers() []ExpFlagSpec
// Flags returns the list of flags supported by the action
// Action列表参数
Flags() []ExpFlagSpec
// Executor returns the action command executor
// Action执行器
Executor(channel Channel) Executor
// <snip>
}
注:一个实验场景 action 的定义,包含场景名称,场景所需参数和一些实验规则匹配器
type ExpFlagSpec interface {
// 参数名
FlagName() string
// 参数描述
FlagDesc() string
// 是否需要参数值
FlagNoArgs() bool
// 是否是必须参数
FlagRequired() bool
}
注:实验匹配器定义。
ChaosBlade 模型具体实现
以 network 组件举例,network 作为混沌实验组件,目前包含网络延迟、网络屏蔽、网络丢包、DNS 篡改演练场景,则依据模型规范,具体实现为:
type NetworkCommandSpec struct {
}
func (*NetworkCommandSpec) Name() string {
return "network"
}
func (*NetworkCommandSpec) Actions() []exec.ExpActionCommandSpec {
return []exec.ExpActionCommandSpec{
&DelayActionSpec{},
&DropActionSpec{},
&DnsActionSpec{},
&LossActionSpec{},
}
}
// <snip>
network target 定义了 DelayActionSpec、DropActionSpec、DnsActionSpec、LossActionSpec 四中混沌实验场景,其中 DelayActionSpec 定义如下:
type DelayActionSpec struct {
}
func (*DelayActionSpec) Name() string {
return "delay"
}
func (*DelayActionSpec) Matchers() []exec.ExpFlagSpec {
return []exec.ExpFlagSpec{
&exec.ExpFlag{
Name: "local-port",
Desc: "Port for local service",
},
&exec.ExpFlag{
Name: "remote-port",
Desc: "Port for remote service",
},
&exec.ExpFlag{
Name: "exclude-port",
Desc: "Exclude one local port, for example 22 port. This flag is invalid when --local-port or --remote-port is specified",
},
&exec.ExpFlag{
Name: "interface",
Desc: "Network interface, for example, eth0",
Required: true,
},
}
}
func (*DelayActionSpec) Flags() []exec.ExpFlagSpec {
return []exec.ExpFlagSpec{
&exec.ExpFlag{
Name: "time",
Desc: "Delay time, ms",
Required: true,
},
&exec.ExpFlag{
Name: "offset",
Desc: "Delay offset time, ms",
},
}
}
type NetworkDelayExecutor struct {
channel exec.Channel
}
// <snip>
DelayActionSpec 包含 2 个场景参数和 4 个规则匹配器。
通过以上事例,可以看出此模型简单、易实现,并且可以覆盖目前已知的实验场景。后续可以对此模型进行完善,成为一个混沌实验标准。
四、ChaosBlade 内部实现逻辑简述
为了更好的理解chaosblade的实现逻辑,这里就再以cpu满载(使用率达到100%)举例。在./blade create cpu命令中,我们可以通过--cpu-count用来指定cpu满载的内核个数;还可以通过--cpu-list来指定需要的满载的cpu内核编号,可以使用“1,3”这种形式来分别指定编号为1和3的cpu内核满载,也可以“0-3”这种形式来指定编号为0至3(0,1,2,3)的cpu内核满载。
我们可以通过以下命令来查看cpu信息:
cat /proc/cpuinfo
查看cpu内核编号示例:
hidden@hidden:~$ cat /proc/cpuinfo | grep processor | uniq -c
1 processor : 0
1 processor : 1
1 processor : 2
1 processor : 3
前面的例子中我们使用了iostat来查看cpu的使用情况,这里我们再换一个sar命令来观察一下:
hidden@hidden:~$ sar -u 1 2
Linux 4.4.0-33.bm.1-amd64 (n224-008-172) 08/15/2019 _x86_64_ (4 CPU)
11:26:55 AM CPU %user %nice %system %iowait %steal %idle
11:26:56 AM all 0.25 0.00 0.50 0.50 0.00 98.75
11:26:57 AM all 0.25 0.00 0.25 0.00 0.00 99.50
其中%idle表示cpu的空闲情况。
1. 逻辑剖析
逻辑实现
如果不是直接使用下载的release版本,而是使用源码。那么在使用 ChaosBlade 前需要将源码(project)编译,其中就会把project下的exec/os/bin/目录下的文件编译成chaos_***类型的可执行文件。
exec/os/bin/目录内容如下:
hidden@hidden:~/chaos/chaosblade$ cd exec/os/bin/
hidden@hidden:~/chaos/chaosblade/exec/os/bin$ tree
.
├── burncpu
│ ├── burncpu.go
│ └── burncpu_test.go
├── burnio
│ ├── burnio.go
│ └── burnio_test.go
├── changedns
│ ├── changedns.go
│ └── changedns_test.go
├── common.go
├── delaynetwork
│ ├── delaynetwork.go
│ └── delaynetwork_test.go
├── dropnetwork
│ ├── dropnetwork.go
│ └── dropnetwork_test.go
├── filldisk
│ ├── filldisk.go
│ └── filldisk_test.go
├── killprocess
│ ├── killprocess.go
│ └── killProcess_test.go
├── lossnetwork
│ ├── lossnetwork.go
│ └── lossnetwork_test.go
└── stopprocess
└── stopprocess.go
在project中Makefile文件中也能证明这一点(截取自Makefile文件):
# build burn-cpu chaos tools
build_burncpu: exec/os/bin/burncpu/burncpu.go
$(GO) build $(GO_FLAGS) -o $(BUILD_TARGET_BIN)/chaos_burncpu $<
如果你下载的是直接可运行的release版本,那么可以在bin/目录下看到这些chao_***文件:
hidden@hidden:~/chaos/chaosblade-0.2.0$ tree
.
├── bin
│ ├── chaos_burncpu
│ ├── chaos_burnio
│ ├── chaos_changedns
│ ├── chaos_delaynetwork
│ ├── chaos_dropnetwork
│ ├── chaos_filldisk
│ ├── chaos_killprocess
│ ├── chaos_lossnetwork
│ ├── chaos_stopprocess
│ ├── cplus-chaosblade.spec.yaml
│ ├── jvm.spec.yaml
│ └── tools.jar
├── blade
├── chaosblade.dat
└── lib
// <snip>
之后我们在使用./blade create cpu fulloload命令的时候其实在内部就转化为了直接调用bin/chaos_burncpu。而blade这个可执行文件只是使用了Cobra来实现的CLI入口。
Cobra既是用于创建强大的现代CLI应用程序的库,也是用于生成应用程序和命令文件的程序。许多使用最广泛的Go项目都是使用Cobra构建的,其中包括:kubernetes、docker、openshift、Hugo等。
也就是说,实际上我们不需要使用./blade create cpu fulloload命令来使得cpu满载,使用bin/目录下的chaos_burncpu即可。
逻辑验证
首先我们使用bin/chaos_burncpu来让cpu满载,通过查看源码发现调用的方式是这样的:
# 等同于./blade create cpu fullload
bin/chaos_burncpu --start
# 可以使用cpu-count指定需要满载的cpu的内核个数
bin/chaos_burncpu --start --cpu-count 4
停止可以使用如下的命令:
# 等同于./blade destroy UID
bin/chaos_burncpu --stop
我们通过测试可以发现效果和./blade的方式等同。
2. burncpu实现简述
假设现在测试所使用的机器的cpu共有4个内核,那么我们让其中三个内核满载,效果如何呢?首先运行sar -u 1 100命令来监测cpu的使用情况,然后运行:
bin/chaos_burncpu --start --cpu-count 3
可以在持续运行sar命令的shell终端中看到cpu的%idle数值变成了25%左右:
02:21:35 PM CPU %user %nice %system %iowait %steal %idle
02:21:44 PM all 73.95 0.00 1.24 0.00 0.00 24.81
我们还可以指定让某个cpu内核满载,比如下面的示例中让内核编号为1的满载:
bin/chaos_burncpu --start --cpu-list 1
sar命令中还可以通过—P参数查看指定内核的使用情况,比如使用sar -u -P 1 1 100来指定编号为1的cpu内核的使用情况:
hidden@hidden:~$ sar -u -P 1 1 100
Linux 4.4.0-33.bm.1-amd64 (n224-008-172) 08/15/2019 _x86_64_ (4 CPU)
02:45:19 PM CPU %user %nice %system %iowait %steal %idle
02:45:20 PM 1 98.00 0.00 2.00 0.00 0.00 0.00
02:45:21 PM 1 98.99 0.00 1.01 0.00 0.00 0.00
可以看到这个内核已经满载。
我们再来通过-P 0来看一下编号为0的cpu内核的使用情况:
02:47:32 PM CPU %user %nice %system %iowait %steal %idle
02:47:33 PM 0 1.00 0.00 2.00 0.00 0.00 97.00
02:47:34 PM 0 0.00 0.00 0.00 0.00 0.00 100.00
可以看到这个内核还是处于空闲状态(%idle接近100%)。
chaos_burncpu中实现CPU满载负荷的逻辑其实相当简单,通过程序让CPU一直运作即可。代码如下:
func burnCpu() {
runtime.GOMAXPROCS(cpuCount)
for i := 0; i < cpuCount; i++ {
go func() {
for {
for i := 0; i < 2147483647; i++ {
}
runtime.Gosched() //让出CPU时间片
}
}()
}
select {} // wait forever
}
关闭CPU满载负荷的过程也比较简单粗暴,总共分为两步:
-
使用
ps -ef | grep …命令找出chaos_burncpu的pid。 -
使用
kill -9 pid命令干掉它。
指定内核满载
我们在上面就了解到通过--cpu-count可以指定CPU满载的内核个数,通过--cpu-list可以指定内核满载。
--cpu-count的功能很好实现,在上面的func burnCpu()函数中的cpuCount就是--cpu-count所指定的值。
--cpu-list的功能比较复杂,总共分为3步:
-
第一步:执行
nohup bin/chaos_burncpu --nohup --cpu-count 1 --cpu-processor [cpu内核编号] > /dev/null 2>&1 &。假设我们要指定编号为1的内核满载,那么对应的命令即为:nohup bin/chaos_burncpu --nohup --cpu-count 1 --cpu-processor 1 > /dev/null 2>&1 &。其实这个只是个烟雾弹,实际上还是调用原本的bin/chaos_burncpu --start --cpu-count 1而已,只不过这里多了一个cpu-processor的信息,这个在下面有用。 -
第二步:执行
ps -ef | grep …命令找出对应的pid。 -
第三步:将进程pid绑定到编号为
cpu-processor的内核上。那么这一步怎么操作呢?我们先来看一下CPU Affinity。
3. CPU Affinity
基本概念
CPU affinity (亲和力/亲和性)是一种调度属性(scheduler property), 它可以将一个进程"绑定" 到一个或一组CPU上。
将进程与cpu绑定,最直观的好处就是减少cpu之间的cache同步和切换,提高了cpu cache的命中率,提高代码的效率。
从cpu架构上,NUMA拥有独立的本地内存,节点之间可以通过互换模块做连接和信息交互,因此每个CPU可以访问整个系统的内存,但是访问远地内存访问效率大大降低,绑定cpu操作对此类系统运行速度会有较大提升,UMA架构下,多cpu通过系统总线访问存储模块。不难看出,NUMA使用cpu绑定时,每个核心可以更专注地处理一件事情,资源体系被充分使用,减少了同步的损耗。
表示方法
CPU affinity 使用位掩码(bitmask)表示, 每一位都表示一个CPU, 置1表示"绑定"。最低位表示第一个逻辑CPU, 最高位表示最后一个逻辑CPU。CPU affinity典型的表示方法是使用16进制,具体如下:
0x00000001
is processor #0
0x00000003
is processors #0 and #1
0xFFFFFFFF
is all processors (#0 through #31)
taskset命令
taskset命令用于获取或者设定CPU affinity。
# 命令行形式
Usage: taskset [options] [mask | cpu-list] [pid|cmd [args...]]
PARAMETER
mask : cpu亲和性,当没有-c选项时, 其值前无论有没有0x标记都是16进制的,
当有-c选项时,其值是十进制的.
command : 命令或者可执行程序
arg : command的参数
pid : 进程ID,可以通过ps/top/pidof等命令获取
OPTIONS
-a, --all-tasks (旧版本中没有这个选项)
这个选项涉及到了linux中TID的概念,他会将一个进程中所有的TID都执行一次CPU亲和性设置.
TID就是Thread ID,他和POSIX中pthread_t表示的线程ID完全不是同一个东西.
Linux中的POSIX线程库实现的线程其实也是一个进程(LWP),这个TID就是这个线程的真实PID.
-p, --pid
操作已存在的PID,而不是加载一个新的程序
-c, --cpu-list
声明CPU的亲和力使用数字表示而不是用位掩码表示. 例如 0,5,7,9-11.
-h, --help
display usage information and exit
-V, --version
output version information and exit
USAGE
1) 使用指定的CPU亲和性运行一个新程序
taskset [-c] mask command [arg]...
举例:使用CPU0运行ls命令显示/etc/init.d下的所有内容
taskset -c 0 ls -al /etc/init.d/
2) 显示已经运行的进程的CPU亲和性
taskset -p pid
举例:查看init进程(PID=1)的CPU亲和性
taskset -p 1
3) 改变已经运行进程的CPU亲和力
taskset -p[c] mask pid
举例:打开2个终端,在第一个终端运行top命令,第二个终端中
首先运行:[~]# ps -eo pid,args,psr | grep top #获取top命令的pid和其所运行的CPU号
其次运行:[~]# taskset -cp 新的CPU号 pid #更改top命令运行的CPU号
最后运行:[~]# ps -eo pid,args,psr | grep top #查看是否更改成功
PERMISSIONS
一个用户要设定一个进程的CPU亲和性,如果目标进程是该用户的,则可以设置,如果是其他用户的,则会设置失败,提示 Operation not permitted.当然root用户没有任何限制.
任何用户都可以获取任意一个进程的CPU亲和性.
4. 回顾指定内核满载
下面我们就来详细实践一下CPU指定内核满载的过程。
首先我们让某个内核满载,这里我们还并未指定哪一个内核(对应前面所说第一步):
bin/chaos_burncpu --start --cpu-count 1
第二步,我们找到这个进程的pid:
hidden@hidden:~$ ps -ef | grep chaos_burncpu
hidden 572792 490371 99 18:20 pts/0 00:00:14 bin/chaos_burncpu --nohup --cpu-count 1 --cpu-processor 1
hidden 572860 551590 0 18:20 pts/3 00:00:00 grep chaos_burncpu
此时,我们查看pid=572792的进程的亲和力为f(0-3),也就是说CPU中的4个内核都有可能运行这个满载程序。
hidden@hidden:~$ taskset -p 572792
pid 572792's current affinity mask: f
hidden@hidden:~$ taskset -c -p 572792
pid 572792's current affinity list: 0-3
上面第一步中,指定某个单独的内核满载的实际效果应该时每个内核都会有一定的时间处于满载状态。对此有疑问的同学可以通过sar -u -P [cpu-processor] 1 1000来验证一下。
第三步,我们指定编号为0的内核满负荷:
hidden@hidden:~$ taskset -cp 0 572792
pid 572792's current affinity list: 0-3
pid 572792's new affinity list: 0
此时我们可以通过sar -u -P [cpu-processor] 1 1000命令来检测4个内核的各个使用情况。不出意外的话,内核编号为0的检测结果应该和下面的类似:
hidden@hidden:~$ sar -u -P 0 1 1000
Linux 4.4.0-33.bm.1-amd64 (n224-008-172) 08/15/2019 _x86_64_ (4 CPU)
06:22:08 PM CPU %user %nice %system %iowait %steal %idle
06:38:46 PM 0 100.00 0.00 0.00 0.00 0.00 0.00
06:38:47 PM 0 100.00 0.00 0.00 0.00 0.00 0.00
06:38:48 PM 0 100.00 0.00 0.00 0.00 0.00 0.00
而其他内核的%idle应该都接近在100%。
五、OS级故障实现原理解析
在上一章中我们了解了burncpu的故障实现原理,本章主要来描述一下下面列表中除burncpu之外的故障实现原理。
├── bin
│ ├── chaos_burncpu
│ ├── chaos_burnio
│ ├── chaos_changedns
│ ├── chaos_delaynetwork
│ ├── chaos_dropnetwork
│ ├── chaos_filldisk
│ ├── chaos_killprocess
│ ├── chaos_lossnetwork
│ ├── chaos_stopprocess
1. chaos_burnio
功能:模拟I/O读写满负荷运作。
使用示例:
bin/chaos_burnio --file-system /dev/sda1 --size 1 --count 1024 --read=true --write=false --nohup=true
bin/chaos_burnio --file-system /dev/sda1 --size 1 --count 1024 --read=false --write=true --nohup=true
原理:dd命令。
# read
dd if=/dev/sda1 of=/dev/null bs=1M count=1024 iflag=dsync,direct,fullblock
# write
dd if=/dev/zero of=/tmp/chaos_burnio.log.dat bs=1M count=1024 oflag=dsync
dd命令解析:
if指定输入的文件名,of指定输出的文件名,bs同时设置读写块的大小为1M,count是指仅拷贝1024个块,块大小等于bs指定的字节数。
可以使用iostat命令查看I/O负载情况。
2. chaos_filldisk
功能:磁盘填充。
使用示例:
# 其中size是指定填充磁盘的大小,单位为MB
./blade create disk fill --size 1000
原理:dd命令。
dd if=/dev/zero of=/chaos_filldisk.log.dat bs=1M count=1000 iflag=fullblock
3. chaos_changedns
功能:域名设定
使用示例:
./blade create network dns --domain www.hidden.com --ip localhost
实际效果会在/etc/hosts中添加一行记录:
localhost www.hidden.com #claosblade
反之,就是删除掉这一行
4. chaos_delaynetwork
功能:网络延迟
使用示例:
# time指定延迟时间,单位为ms, offset指定延迟波动大小
./blade create network delay --interface eth0 --time 300
./blade create network delay --interface eth0 --time 300 --offset 50
原理:tc命令。
tc qdisc add dev eth0 root netem delay 300ms
#该命令将 eth0 网卡的传输设置为延迟 300ms ± 50ms (250 ~ 350 ms 之间的任意值)发送
tc qdisc add dev eth0 root netem delay 300ms 50ms
恢复
tc qdisc del dev eth0 root netem
5. chaos_dropnetwork
功能:网络中断
使用示例:
./blade create network drop --local-port 100 --remote-port 100
原理:iptables命令
iptables -A INPUT -p tcp --dport [localPort] -j DROP
iptables -A INPUT -p udp --dport [localPort] -J DROP
iptables -A OUTPUT -p tcp --dport [remotePort] -j DROP
iptables -A OUTPUT -p udp --dport [remotePort] -j DROP
恢复:
iptables -D INPUT -p tcp --dport [localPort] -j DROP
iptables -D INPUT -p udp --dport [localPort] -J DROP
iptables -D OUTPUT -p tcp --dport [remotePort] -j DROP
iptables -D OUTPUT -p udp --dport [remotePort] -j DROP
6. chaos_lossnetwork
功能:网络丢包
使用示例:
./blade create network loss --interface eth0 --percent 10
原理:tc命令。
tc qdisc add dev eth0 root netem loss 10%
7. chaos_killprocess
功能:杀死进程
使用示例:
./blade create process kill --process chaos
原理:kill -9
8. chaos_stopprocess
功能:进程假死
使用示例:
./blade create process stop --process chaos
原理:kill -19
附录:各种信号及其用途。
hidden@hidden$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
参考资料及衍生读物
-
阿里巴巴为何坚持对混沌工程的研发迭代?
-
实践 | 混沌工程工具 ChaosBlade 构建高可用的分布式系统
-
好玩又实用,阿里巴巴开源混沌工程工具 ChaosBlade
-
做混沌工程是什么样的体验?阿里:有点刺激
-
一文理解分布式服务架构下的混沌工程实践(含PPT)
-
https://github.com/chaosblade-io/chaosblade/blob/master/README_CN.md
-
https://github.com/chaosblade-io/chaosblade/wiki/%E6%96%B0%E6%89%8B%E6%8C%87%E5%8D%97
-
cpu亲和性绑定
-
Linux中CPU亲和性(affinity)
-
https://github.com/chaosblade-io/chaosblade
欢迎跳转到本文的原文链接:https://honeypps.com/chaos/alibaba-chaos-tool-chaosblade-analysis/
想知道更多?扫描下面的二维码关注我

相关推荐:
-
《科普 | 明星公司之Netflix》
-
《看我如何作死 | 将CPU、IO打爆》
-
《看我如何作死 | 网络延迟、丢包、中断一个都没落下》
-
《看我如何假死!》
-
《这次我们看看阿里的人是如何蹂躏CPU的》
加技术群入口(备注:技术):>>>Learn More<<
免费资料入口(备注:1024):>>>Learn More<<
免费星球入口:>>>Free<<<
内推通道>>>>
点个"在看"呗^_^