LoadRunner参数化详解
转载于虫师blog:http://www.cnblogs.com/fnng/archive/2012/06/22/2558900.html
参考:http://blog.csdn.net/aovenus/article/details/7378052
距离上次使用loadrunner 已经有一年多的时间了。初做测试时在项目中用过,后面项目中用不到,自己把重点放在了工具之外的东西上,认为性能测试不仅仅是会用工具,最近又想有一把好的利器毕竟可以帮助自己更好的完成性能测试工作。这算是一个认知的过程吧!
在次安装打开loadrunner时,发现虽然自己的思想还在,但已经非常生疏了,好多设置都找不到了具体的位置。下面说参数化参数化是性能测试中时最常用的一种技巧吧!这里需要说明的是,不是只有loadrunner才可以设置参数化,我以前所使用的JMeter同样也有类似的设置。
我们知道性能测试工具是模拟多个用户对系统的性能进行验证(这种说法不完全正确),有些系统允许多个完全相同的用户同时对完全相同的数据做完全相同的操作,有些则不允许。比如,邮箱一般允许同一个账号在多处登陆。而我们的QQ账号肯定是不允许的。再比如,你注册某个系统时,用户名是不能有重复。但密码却可以。所以,这么多个情况都要用到参数化技巧。
我们这里通过loadurnner录制一个139邮箱的登陆。下面是截取的一小段代码

........
web_submit_form("Login.ashx",
"Snapshot=t3.inf",
ITEMDATA,
"Name=UserName", "Value=chongshi", ENDITEM,
"Name=Password", "Value=123456", ENDITEM,
"Name=VerifyCode", "Value=", ENDITEM,
"Name=auto", "Value=
下面看一下如何通过loadrunner对用户名密码参数化。标红的内容就是登陆的用户名和密码。
参数化的方法
选中要参数化的内容。
方法一,右键---【Replace with a new parameter】
方法二,菜单【insert】----【new Parameter…】
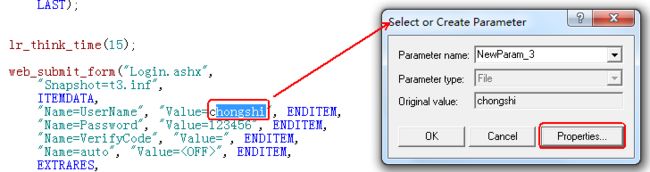
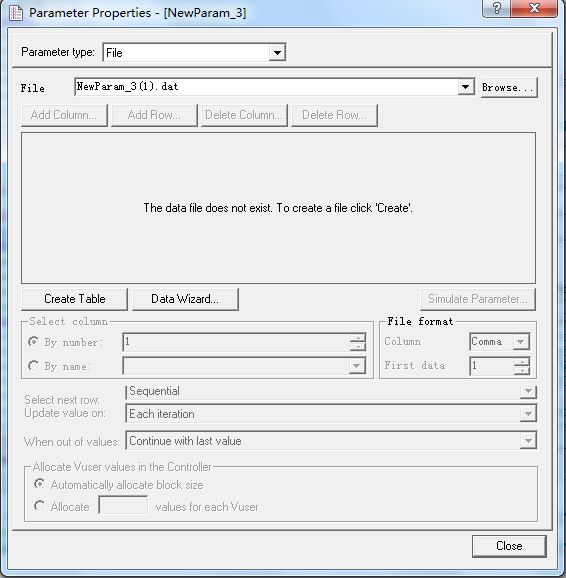
Parameter Properties (参数属性对话框)----我们的参数化设置就通过这个对话框完成。
参数化的方式:
其实参数化得方式有很多种,这里简述几种比较常见人方式。其实方式略有不同,但其结果都是将数据添加进来。
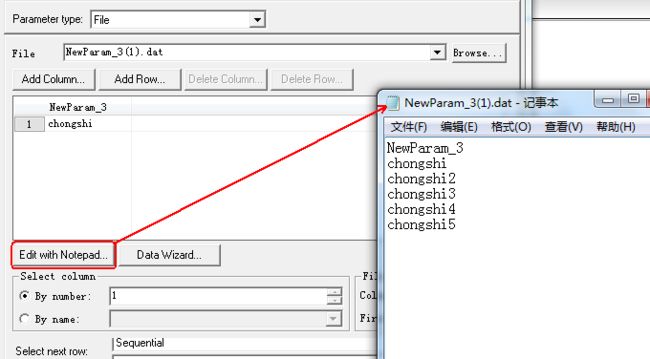
1、 编辑数据
点击Create Table 会出现表格,在表格,再次点击Edit with Notepad ,然后会打开一个记事本,我们可以对记事本进行添加数据
2、 添加dat数据文件
点击File输入框后面的“Browse..”按钮,找到本地的txt数据文件,进行添加就可以了。
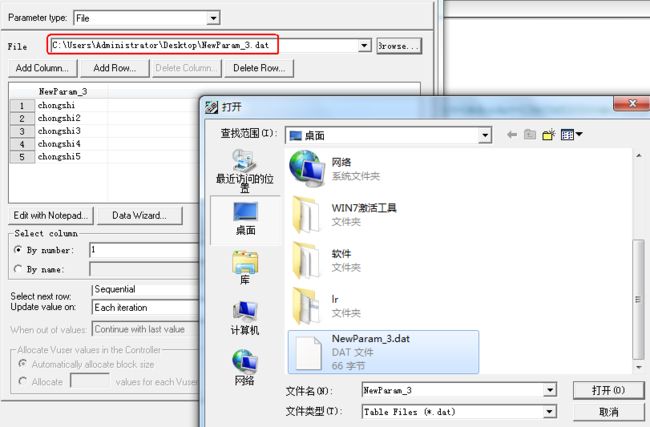
需要注意的是,文件里面的数据不要乱写,每条数据一行,不然会读取有误。
3、 数据库添加数据
在很多情况下,我添加的数据不是十条二十条,也不是一百两百,如果还通过上面的两种方式添加,我想会是一件非常纠结的事情。所以我们可以通过数据库将数据导入。你是否疑虑数据库的数据怎么弄,数据库的数据生成非常简单,可以写一段简单的代码生成,也可以通过数据库数据生成工具来完成
点击Date Wizard 打开连接数据库向导。

这里先告诉你有这种方式,后面再介绍具体操作。^_^
4、 其他类型设置
如果我们要参数化的不是一个文件,比如是特定的日期时间,可以从Parameter type 列表中进行选择
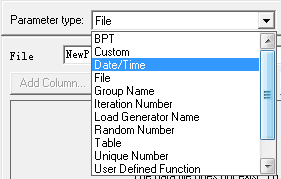

这里可以设置日期时间格式,循环迭代方式,不过除了file类型外,其他用的不多。其他类型用法我也不是十分了解。
【注意】对于参数类型为File/Table的数据文件:
l 在参数数据显示区中,最多只显示前100条数据,之后的不显示,但不影响正常取数据。
l 在记事本中编辑参数数据时,数据文件一定要以一个空行结束,否则,最后一行输入的数据不会被参数所使用。
参数化之间的关联
前面我们已经对用户名进行了参数化,或对密码进行了参数化,这样是不是脚本就能正常跑了,不好说。因为用户名和密码不是一一对应关系,每次运行脚本时取的用户名和密码没有对应上的话肯定就会出问题。
假设,我们已经对用户名已经进行了参数化,参数名为【username】,下面设置密码参数化与用户名关联。
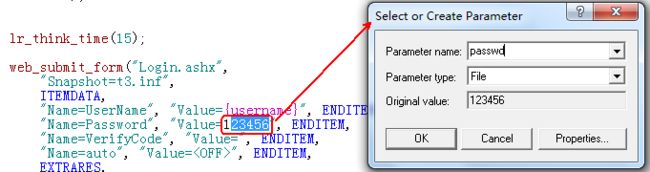
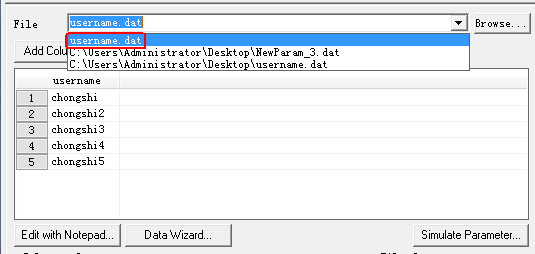
点击“Properites…”会打开编辑用户名参数化窗口。File列表框中,刚才保存用户名信息的文件"username.dat"。
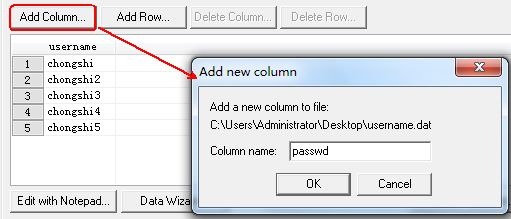
点击“Add Column…”,添加新的一列信息,用于放置密码。
点击“Edit with Notepad”再次编辑参数化数据文件,使用户名密码建立一一对应关系。

完成之后,我们已经成功对用户名和密码进行了参数化,并且让用户名和密码形成了对应关系。
数据分配与更新方式
脚本设置完参数化,脚本运行的每一遍所取的参数化的值都不一样,那么这个值按照个什么情况来取呢?会有很多种方式
Select next row【选择下一行】:

顺序(Sequential):按照参数化的数据顺序,一个一个的来取。
随机(Random):参数化中的数据,每次随机的从中抽取数据。
唯一(Unique):为每个虚拟用户分配一条唯一的数据
Update value on【更新时的值】:

每次迭代(Each iteration) :每次迭代时取新的值,假如50个用户都取第一条数据,称为一次迭代;完了50个用户都取第二条数据,后面以此类推。
每次出现(Each occurrence):每次参数时取新的值,这里强调前后两次取值不能相同。
只取一次(once) :参数化中的数据,一条数据只能被抽取一次。(如果数据轮次完,脚本还在运行将会报错)
上面两个选项都有三种情况,如果将他们进行组合,将产生九种取值方式。
| Select Next Row 【选择下一行】 |
Update Value On 【更新时的值】 |
Replay Result 【结果】 |
| 顺序(Sequential) |
每次迭代(Each iteration) |
结果:分别将15条数据写入数据表中 功能说明:每迭代一次取一行值,从第一行开始取。当所有的值取完后,再从第一行开始取 如:如果参数化文件中有15条数据,而迭代设置为16次,那执行结果中,参数化文件第一行的数据有两条 |
| 顺序(Sequential) |
每次出现(Each occurrence) |
结果:分别将15条数据写入数据表中 功能说明:每迭代一次取一行值,从第一行开始取。当所有的值取完后,再从第一行开始取 如:如果参数化文件中有15条数据,而迭代设置为16次,那执行结果中,参数化文件第一行的数据有两条 |
| 顺序(Sequential) |
只取一次(once) |
结果:表中写入15条一模一样的数据。 功能说明:每次迭代都取参数化文件中第一行的数据。 |
| 随机(Random) |
每次迭代(Each iteration) |
结果:表中写入15条数据,但可能有重复数据出现 功能说明:每次从参数化文件中随机选择一行数据进行赋值 |
| 随机(Random) |
每次出现(Each occurrence) |
结果:表中写入15条数据,但可能有重复数据出现 功能说明:每次从参数化文件中随机选择一行数据进行赋值 |
| 随机(Random) |
只取一次(once) |
结果:表中写入15条相同数据 功能说明:第一次迭代时随机从参数化文件中取一行数据,后面每次迭代都用第一次迭代的数据。 |
| 唯一(Unique) |
每次迭代(Each iteration) 自动分配块大小 |
结果:分别将15条数据写入数据表中 功能说明:第一次迭代取参数化文件中的第一条数据,第二次迭代取第二条数据,以此类推。 注:如果设置迭代次数为16次。结果:在执行第16次迭代时会抛异常,异常日志可在LoadRunner的回放日志(replayLog)中看到。 |
| 唯一(Unique) |
每次出现(Each occurrence) 步长为1 |
结果:分别将15条数据写入数据表中 功能说明:第一次迭代取参数化文件中的第一条数据,第二次迭代取第二条数据,以此类推。 注:如果设置迭代次数为16次,而参数化文件中只有15条数据,明显数据不够。此时可以设置“when out of values”属性来判断当数据不够时的处理方式 Abort Vuser:中断虚拟用户 Countinue in a cylic manage:循环取参数化文件中的值,即:当参数化文件中的值取完后又从参数化文件的第一行开始取值。 Countinue with last value:继续用最后一条数据 |
| 唯一(Unique) |
只取一次(once) |
结果:表中写入15条相同数据 功能说明:每次都取参数文件中的第一条数据进行赋值 |
Ps:关于调用数据库实现参数化的方式,放在后一篇细说。被一个蛋疼的问题和这篇文章折腾一天。