systemd和awk命令的使用
1.简述systemd的新特性及unit常见类型分析,能够实现编译安装的如nginx\apache实现通过systemd来管理
Systemd概述
1. systemd是一种新的linux系统服务管理器,用于替换init系统,能够管理系统启动过程和系统服务,一旦启动起来,就将监管整个系统。
在centos7系统中,PID1被systemd所占用;在centos7系统中,PID1被systemd所占用;
2.systemd可以并行地启动系统服务进程,并且最初仅启动确实被依赖的服务,极大减少了系统的引导时间,这也就是为什么centos7系统
启动速度比centos6快许多的原因;
3.systemctl 是 systemd 的主命令,用于管理系统及服务
systemd的新特性:
- 在系统引导时实现服务并行启动(服务之间没有依赖关系)
- 能按需激活进程(减少系统的资源浪费)
- 能做系统状态快照
- 基于依赖关系定义服务控制逻辑
提高了系统的启动速度,尽可能减少了启动的程序以及采用多进程减少了程序依赖启动的等待时间。
systemd的关键特性
- 基于socket的激活机制:socket与程序分离;systemd为支持此机制的服务监听socket,当接收到来自客户端的socket通信时,由systemd激活对应的服务,应答客户端的请求;
- 基于bus的激活机制;基于总线的激活;
- 基于device的激活机制,当有设备接入到系统时,systemd会自动激活device、mount、automount等unit来识别、挂载、接入对应的设备,如果挂载点不存在还能自动创建;
- 基于path的激活机制,当某个文件路径变得可用时或路径出现相应的文件时,激活相应的服务;
- 系统快照机制,保存各unit的当前状态信息到持久存储中,在下次开机时可恢复之前某次快照时的系统状态,必要时可自动载入;
- 兼容Centos 5的SysV init 以及Centos 6的upstart机子,能够继续使用/etc/rc.d/init.d目录中的服务管理脚本。
- 系统引导时,其服务的启动时并行的;
- 按需激活进程;
- 基于依赖关系定义了服务控制逻辑;
不兼容:
- systemctl的命令是固定不变的:不能自定义命令,旧版能自定义如start、stop等命令,在脚本中可随意定义命令使用;而systemctl的命令是固定不变的
- 非由systemd启动的服务,systemctl无法与之通信,无法控制此服务:例如启动web进程httpd,直接在命令行键入httpd也能启动,这种服务在CentOS 5和6上使用servcie httpd stop有时也能停掉服务,但是systemd就不行,但可自定义unit脚本来实现
systemd核心概念:unit
- Systemd可以管理系统中所有资源。不同的资源统称为unit(单位)。Unit表示不同类型的systemd对象,通过配置文件进程标识和配置;文件中主要包含了系统服务、监听socket、保存的系统快照以及其它与init相关的信息。
- systemd启动后,首先会去三个目录下找相应的配置文件,按优先级从高到底为/etc/systemd/,/usr/lib/systemd/和/lib/systemd/,优先级高的配置文件会覆盖优先级低的配置文件。
- systemd的配置文件又叫unit文件,主要有以下几种:
- Service unit:用于定义系统服务,文件扩展名为.service
- Target unit:用于模拟实现“运行级别”,文件扩展名为.target
- Device unit:用于定义内核识别的设备,文件扩展名为.device
- Mount unit:用于定义文件系统挂载点,文件扩展名为.mount
- Socket unit:用于标识进程间通行用的socket文件,文件扩展名为.socket
- Snapshot unit:管理系统快照,文件扩展名为.snapshot
- Swap unit:用于标识swap设备,文件扩展名为.swap
- Automount unit:文件系统的自动挂载点,文件扩展名为.automount
- Path unit:用于根据文件系统上特定对象的变化来启动其他服务,文件扩展名为.path
- Timer unit:用于管理计划任务,文件扩展名为.timer
- Slice unit:用于资源管理,文件扩展名为.slice
- Scope unit:用于外部创建的进程,文件扩展名为.scope
- 系统管理服务Service unit:
系统服务新老机制对应(Centos6–>Centos7)
-
启动:service name start ==> systemctl start name.service
-
停止:service name stop ==> systemctl stop name.service
-
重启:service name restart ==> systemctl restart name.service
-
状态:service name startus ==> systemctl startus name.service
-
条件式重启:service name condrestart ==> systemctl try-restart name.service
-
重载或重启服务:systemctl reload-or-restart name.service
-
重载或条件式重启服务:systemctl reload-or-try-restart name.service
-
禁止设定为开机自启:systemctl mask name.service
-
消禁止设定为开机自启:systemctl unmask name.service
-
查看某服务当前激活与否的状态:systemctl is-active name.service
-
查看所有已经激活的服务:systemctl list-units --type service
-
查看所有服务:systemctl list-units --type service --all
chkconfig命令的对应关系 -
设定某服务开机自启:chkconfig name on ==> systemctl enable name.service
-
禁止:chkconfig name off ==> systemctl disable name.service
-
查看所有服务的开机自启状态:chkconfig --list ==> systemctl list-unit-file --type service
-
查看服务是否开机自启:systemctl is-enable name.service
-
查看服务的依赖关系:systemctl list-dependencies name.service
- target unit 的运行级别
- 0 ==> runlevel0.target,poweoff.target
- 1 ==> runlevel1.target, rescue.target
- 2 ==> runlevel2.target,multi-user.target
- 3 ==> runlevel3.target,multi-user.target
- 4 ==> runlevel4.target,multi-user.target
- 5 ==> runlevel5.target,graphical.target
- 6 ==> runlevel6.target,reboot.target
级别切换:init N ==> systemctl isolate name.target
如果需要查看级别则是 查看级别:runlevel ==> systemctl list-units --type targe
获取默认运行级别:/etc/initab ==> systemctl get-default
修改默认级别:/etc/initab ==> systemctl set-default name.target
切换至紧急救援模式:systemctl rescue
切换至emergency模式:systemctl emergency
unit的配置文件
文件通常由三段组成:
[Unit]
主要定义与Unit类型无关的通用选项;用于提供当前unit的描述信息、unit行为及依赖关系;
Description:简短描述
Documentation:man文档地址
Requires:强依赖关系,当前 Unit 依赖的其他 Unit,如果它们没有运行,当前 Unit 会启动失败
Wants:弱依赖关系,与当前 Unit 配合的其他 Unit,如果它们没有运行,当前 Unit 不会启动失败
BindsTo:与Requires类似,它指定的 Unit 如果退出,会导致当前 Unit 停止运行
Before:如果该字段指定的 Unit 也要启动,那么必须在当前 Unit 之后启动
After:如果该字段指定的 Unit 也要启动,那么必须在当前 Unit 之前启动
Conflicts:这里指定的 Unit 不能与当前 Unit 同时运行
Condition...:当前 Unit 运行必须满足的条件,否则不会运行
Assert...:当前 Unit 运行必须满足的条件,否则会报启动失败
[Service]
与特定类型相关的专用选项;此处为service类型;(UNIT-TYPE,类似是什么就为相对应的名称)
service unit的配置,只有service类型才有
Type:定义启动时的进程行为,它有以下几种值
Type=simple:默认值,执行ExecStart指定的命令,启动主进程
Type=forking:以 fork 方式从父进程创建子进程,创建后父进程会立即退出
Type=oneshot:一次性进程,Systemd 会等当前服务退出,再继续往下执行
Type=dbus:当前服务通过D-Bus启动
Type=notify:当前服务启动完毕,会通知Systemd,再继续往下执行
Type=idle:若有其他任务执行完毕,当前服务才会运行
ExecStart:启动当前服务的命令
ExecStartPre:启动当前服务之前执行的命令
ExecStartPost:启动当前服务之后执行的命令
ExecReload:重启当前服务时执行的命令
ExecStop:停止当前服务时执行的命令
ExecStopPost:停止当其服务之后执行的命令
RestartSec:自动重启当前服务间隔的秒数
Restart:定义何种情况 Systemd 会自动重启当前服务,可能的值包括always(总是重启)、on-success、on-failure、on-abnormal、 on-abort、on-watchdog
TimeoutSec:定义 Systemd 停止当前服务之前等待的秒数
Environment:指定环境变量
[Install]
定义由"systemctl enable"以及"systemctl disable"命令在实现服务启用或禁用时用到的一些选项;
WantedBy:可以是一个或多个Target,当前unit enable时,符号链接会放入/etc/systemd/system/TARGET.wants目录下
RequiredBy:可以是一个或多个Target,当前unit enable时,符号链接会放入/etc/systemd/system/TARGET.requires目录下
Alias:别名
Also:当前 Unit enable 时,会被同时激活的其他 Unit
编译安装nginx\apache,并通过systemd来管理
安装编译环境用于编译nginx程序
yum -y install gcc gcc-c++ autoconf automake
yum install pcre pcre-devel.x86_64 openssl-devel.x86_64 -y
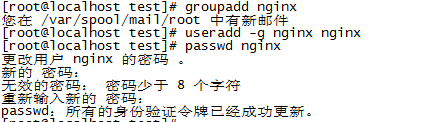
创建nginx用户和组以运行nginx,后面用这个用户的身份来运行nginx
从ftp上下载nginx包,
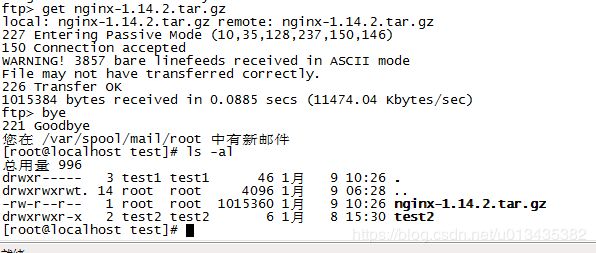
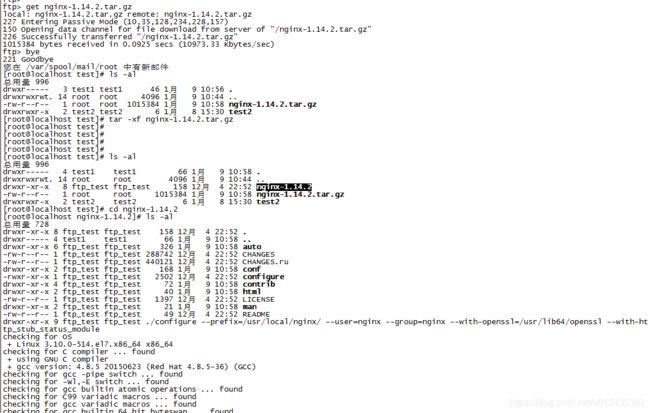
这里出了个小问题。ftp传输的时候选择了ASCII码的方式传输,导致解压的时候解压失败,需要选择二进制的方式进行下载。其中–prefix= 这里是指定安装的目录,–with这些是选择启动程序是调用的接口模块。
nginx配置安装文件详解
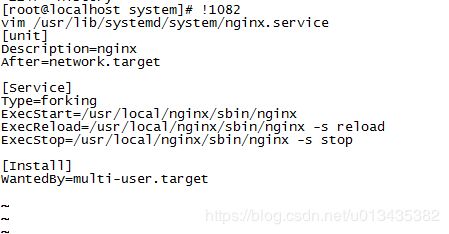
nginx的配置文件修改,指定了在网络服务后启动。service配置段中设置为forking表示ExecStart 所设定的进程将会在启动过程中使用 fork() 系统调用。就是当所有的通信渠道都已建好、启动亦已成功之后,父进程将会退出,而子进程将作为该服务的主进程继续运行,ExecReload=和ExecStop=表示重载或者进程要被停止时所执行的命令
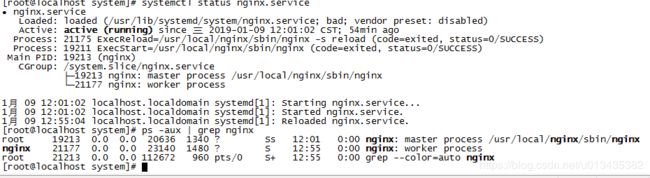
配置完成后重载一下nginx,并且查看是否在运行
[root@localhost system]# systemctl daemon-reload
您在 /var/spool/mail/root 中有新邮件
[root@localhost system]# systemctl start nginx.service
2.描述awk命令用法及示例(至少3例)
文本三剑客之awk
awk是一种报表生成器,与sed,grep都是文本处理工具,可以将编辑的文本进行格式化排版处理后以更加美观的形式输出,在linux上使用的awk是GNUawk即gawk,gawk是awk的套接字文件,二者相同。
语法:
gawk [options] ‘program’ FILE …
program: PATTERN{ACTION STATEMENTS}
语句之间用分号分隔
选项:
-F:指明输入时用到的字段分隔符;
-v var=value: 自定义变量
例如:
使用-F 指定分割符号,program 中指定的输出分割后的段落

print:
print item1, item2, …
要点:
(1) 逗号分隔符;
(2) 输出的各item可以字符串,也可以是数值;当前记录的字段、变量或awk的表达式;
(3) 如省略item,相当于print $0;
例如:
[root@localhost tmp]# awk -F g '{print $1}' text
Do one thin
[root@localhost tmp]#
变量
- 内建变量
常用内置变量之记录变量
FS:input field seperator,输入分隔符,默认为空白字符;
OFS:output field seperator,输出分隔符,默认为空白字符;
RS:input record seperator,输入时的换行符;一行为一条record;默认为行分隔符;
ORS:output record seperator,输出时的换行符;一行为一条record;默认为行分隔符;
awk内置变量的数据变量
NF:number of field,字段数量,即每行的字段数量;
注意:{print NF}, {print $NF}的区别;
NR:number of record, 行数;即对文件中的行进行编号;
FNR:各文件分别计数;行数;
FILENAME:当前文件名;即显示每行的文件名;
ARGC:命令行中参数的个数;
ARGV:数组,保存的是命令行中所给定的各参数;
例如:
#!显示text文件中每一行有多少字段;
[root@localhost tmp]# awk '{print NF}' text
9
0
统计行数,显示行号;
[root@localhost tmp]# awk '{print NR}' /etc/issue
1
2
3
#!显示内容:两文件的总行数
[root@localhost tmp]# awk '{print NR}' text /etc/issue
1
2
3
4
5
#!显示内容:两文件分别显示行数;
[root@localhost tmp]# awk '{print FNR}' text /etc/issue
1
2
1
2
3
awk内置变量的自定义变量
(1) -v VAR=VALUE变量名区分字符大小写;
(2) 在program中直接定义(使用时定义即可)
[root@localhost tmp]# awk -v test='check' '{print test}' text
check
check
[root@localhost tmp]#
printf(格式化输出命令)
printf FORMAT, item1, item2, …
FORMAT是格式符,为每个item按位占一个位留一个特殊符号,所以item最终会显示在format指定格式符号的位置上;
要点:
(1)FORMAT必须给出;
(2) 在显示多行文本时,不会自动换行,需要显式给出换行控制符,\n;
(3) FORMAT中需要分别为后面的每个item指定一个格式化符号;
格式符:
%c: 显示字符的ASCII码;
%d, %i: 显示十进制整数;decimal,integer;
%e, %E: 科学计数法数值显示;
%f:显示为浮点数;
%g, %G:以科学计数法或浮点形式显示数值;
%s:显示字符串;
%u:无符号整数;
%%: 显示%自身;
例如:
#!显示/etc/passwd最后三行中每行的段首内容
[root@localhost tmp]# tail -3 /etc/passwd | awk -F : '{printf "%s\n" ,$1}'
sadad
mysql
ftp_test
#!显示指定字符串username 来表示/etc/passwd最后三行中每行的段首内容,
[root@localhost tmp]# tail -3 /etc/passwd | awk -F : '{printf "username:%s\n" ,$1}'
username:sadad
username:mysql
username:ftp_test
printf 中的修饰符:
#[.#]:第一个数字控制显示的宽度;第二个#表示小数点后的精度;默认右对齐;
%3.1f:3表示显示3个字符的宽度;
-: 左对齐
+:显示数值的符号
4、操作符
算术操作符:
x+y, x-y, x*y, x/y, x^y(x的y次方), x%y(取模)
-x:把整数转为负数;
+x: 把字符串转换为数值;
字符串操作符:
没有符号的操作符,字符串连接(一般使用内建函数进行字符串切片)
赋值操作符:
=, +=, -=, *=, /=, %=, ^=(增强相赋值)
++, --(自增、自减运算)
比较操作符:
, >=, <, <=, !=, ==(等值比较)
模式匹配符:
~:左侧字符串是否能被右侧模式匹配;
!~:左侧字符串是否不能被右侧模式匹配;
逻辑操作符:将多个操作连接起来;
&& 与运算
|| 或运算
! 非运算
PATTERN(实现地址定界功能):
(1) empty:空模式,匹配每一行;
(2) /regular expression/:仅处理能够被此处的(正则表达式)模式匹配到的行;前面加!表示对模式过滤的条件取反;
[root@localhost tmp]# awk -F: '/^s/{print $1}' /etc/passwd
sync
shutdown
systemd-bus-proxy
(3) relational expression: 关系(比较)表达式;结果有“真”有“假”;结果为“真”才会被处理;
真:结果为非0值,非空字符串;
假:0,空字符串;
[root@localhost tmp]# awk -F: '(NR>10) {print $1}' text /etc/passwd
mail
operator
games
ftp
nobody
(4) line ranges:行范围,
/pat1/,/pat2/:startline,endline表示地址定界;
注意: 不支持直接给出数字的格式
[root@localhost tmp]# awk -F: '(NR>=2&&NR<=4){print $1}' /etc/passwd
bin
daemon
adm
(5) BEGIN/END模式
BEGIN{program}: 仅在开始处理文件中的文本之前执行一次程序;显示表头;
END{program}:仅在文本处理完成之后命令结束之前执行一次程序;
常用的action
(1) Expressions
(2) Control statements:if, while等;
(3) Compound statements:组合语句;
(4) input statements
(5) output statements
控制语句
(1)if(condition) {statments}
if(condition) {statments} else {statements}
语法格式:if(condition) statement [else statement]
语句如果有多个,需要用{}括起来;如果有else语句,各语句都要用{};
使用场景:对awk取得的整行或某个字段做条件判断时使用;
(2)while(conditon) {statments}
语法格式:while(condition) statement
条件“真”,进入循环;条件“假”,退出循环;语句如果有多个,需要用{}括起来;
要根据初始条件判断为真或假,如果为假,则一次都不会执行;
使用场景:对一行内的多个字段逐一进行类似处理时使用;或对数组中的各元素逐一处理时使用;
(3)do {statements} while(condition)
语法:do statement while(condition)
(4)for(expr1;expr2;expr3) {statements}
语法格式:for(expr1;expr2;expr3) statement
expr1:控制变量初始化;
expr2:条件判断;
expr3:控制变量的数值修正表达式;
for(variable assignment;condition;iteration process) {for-body}
即:for(变量赋值;条件判断表达式;变量修正表达式) {循环体语句} 意义:无论条件真假,先执行一次,即至少执行一次循环体
(5)break和continue
(6)array数组
关联数组:array[index-expression]
index-expression:索引表达式
(1) 可使用任意字符串;字符串要使用双引号;不能随便使用单引号;
(2) 如果某数组元素事先不存在,在引用时,awk会自动创建此元素,并将其值初始化为“空”;允许未经声明直接引用;
若要判断数组中是否存在某元素,要使用"index in array"格式进行;
三、描述awk函数示例(至少3例)
1.数值处理:
rand():返回0和1之间一个随机数;
使用rand()函数只能随机产生一个数字,这个数字是不会变的,配合使用strand()函数,才生成一个大于0小于1的随机数。
[root@localhost tmp]# awk 'BEGIN{srand();print rand()}'
0.0362516
[root@localhost tmp]# awk 'BEGIN{srand();print rand()}'
0.695741
[root@localhost tmp]# awk 'BEGIN{srand();print rand()}'
0.695741
[root@localhost tmp]# awk 'BEGIN{srand();print rand()}'
0.588531
[root@localhost tmp]# awk 'BEGIN{srand();print rand()}'
0.13613
[root@localhost tmp]# awk 'BEGIN{srand();print rand()}'
0.836846
[root@localhost tmp]# awk 'BEGIN{srand();print rand()}'
0.501607
[root@localhost tmp]#
2.字符串处理:
length([s]):返回指定字符串的长度;
sub(r,s,[t]):以r表示的模式来查找t所表示的字符中的匹配的内容,并将其第一次出现替换为s所表示的内容;
gsub(r,s,[t]):以r表示的模式来查找t所表示的字符中的匹配的内容,并将其所有出现的内容均替换为s所表示的内容;
split(s,a[,r]):以r为分隔符切割字符s,并将切割后的结果保存至a所表示的数组中;数组元素从1开始编号;
将第一次匹配的l切换成大写的L
[root@localhost tmp]# awk '{sub("l","L");print $0}' text
Do one thing at a time, and do weLl
ALlen phillips
Green Lee
WiLliam Lee
将所有的l切换成大写的L
[root@localhost tmp]# awk '{gsub("l","L");print $0}' text
Do one thing at a time, and do weLL
ALLen phiLLips
Green Lee
WiLLiam Lee
[root@localhost tmp]#
统计访问本机的网络地址的ip连接数
[root@localhost tmp]# netstat -tan | awk '/^tcp\>/{split($5,ip,":");count[ip[1]]++}END{for (i in count) {print i,count[i]}}'
10.35.128.234 1
0.0.0.0 6