Kettle — 安装和部署
前提
Kettle是纯Java编写的ETL开源工具,目前Kettle7和Kettle8都需要Java8或者以上才能正常运行。所以开运行Kettle前先检查Java环境是否正确配置,Java版本是否是8或者以上。

Kettle安装
1)创建Kettle的目录,并将Kettle的zip包解压到Kettle目录下
![]()

2)查看一下sh文件使用都有执行的权限,如果没请加上。
4)执行kitchen.sh脚本
3)如果出现以下的错误,这是因为sh文件有可能是在Windows下编写的并打包到Zip包中的,编码格式不一样linux是utf-8,windows是gbk的。我这里提供两种解决方案。

1.单个文件修改
利用Vim进行修改,可以使用:set ff查看文件格式;可以使用:set ff=unix修改文件格式。

2.批量执行
运行下面的脚本命令即可。创建一个sh文件,将下面的shell代码复制到该文件执行即可。注意路径修改一下。
for file in `ls /opt/kettle/data-integration/*.sh`
do
echo ${file}
vim +':w ++ff=unix' +':q' ${file}
done4)执行后如果出现下面的WARNING,根据提示安装即可,不然可能会导致部分特性无法使用(主要是Spoon的使用,如果是无界面环境,可以忽略)。

5)安装好以后,WARNING就没有了。出现以下的提示界面说明Kettle可以正常使用了。
同时home目录下应该会有一个.kettle的目录
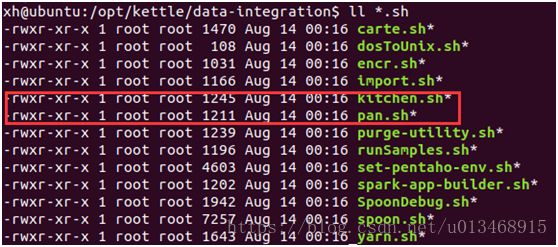
Kettle转换与作业执行
在Kettle中pan和kitchen两个工具分别用来执行transformation(转换)和job(作业),如下所示:
对于文件存储,不是数据库资源库,可以如下的方式存放文件:
所有的transformation文件存放在/srv/kettle/transformations/
所有的job文件存放在/srv/kettle/jobs/
所有的日志文件存放在/var/kettle/logs/
使用pan执行transformation
pan语法:./pan.sh -option=value arg1 arg2

具体使用参考:https://www.cnblogs.com/xiaopan-cp9/p/7608203.html(非常仔细的介绍)
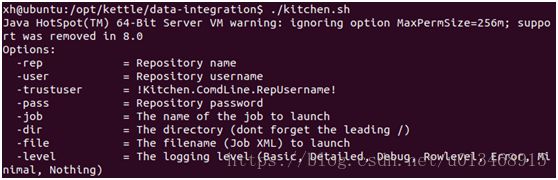
使用kitchen执行job
kitchen语法:./kitchen.sh -option=value arg1 arg2

常用参数列表:
| 命令 |
描述 |
| -rep |
选择一个资源库的名字 |
| -user |
资源库用户名 |
| -pass |
资源库密码 |
| -file |
job文件路径 |
| -job |
资源库中的job名称 |
| -dir |
指定资源库目录 |
| -norep |
标明不是资源库里的文件 |
| -level |
日志级别(Basic, Detailed, Debug, Rowlevel, Error, Nothing) |
| -logfile |
日志输出到指定的文件 |
| -listdir |
在使用 -dir 时,打印出资源库目录下所有子目录 |
| -listjob |
列出资源库中的所有jobs |
| -listrep |
列出当前所有已经定义的资源库 |
| -export |
导出所有的job到一个zip包中 |
| -version |
显示版本 |
| -listparam |
列出所有的参数 |
| -param |
参数设置,例如-param:FOO=bar |
| -level |
log级别 (Basic, Detailed, Debug, Rowlevel, Error, Nothing) |
Kettle服务器端部署
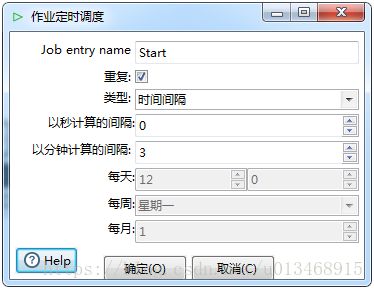
通过Start组件定时执行任务
在Kettle中我们可以通过Start组件来设置定时任务,如下所示,这种方式不推荐使用,因为该Job会一直占有一个进程,容易内存溢出。
通过crontab执行Kettle任务
在Linux中crontab是用来提交和管理用户周期性执行的任务。
例如(文件存放位置):
所有的transformation文件存放在/srv/kettle/transformations/
所有的job文件存放在/srv/kettle/jobs/
所有的日志文件存放在/var/kettle/logs/
所有的执行脚本存放在/srv/kettle/script/
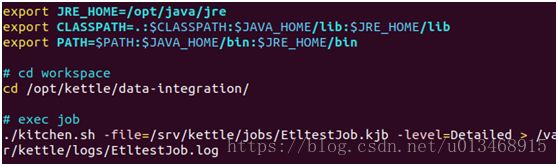
1)首先我们创建一个脚本。因为是crontab执行任务,我们需要重新导入Java配置。
2)在终端上,键入“crontab-e”,进入定时任务文件,添加任务。
![]()
3)重启cron 并查看任务

Kettle通过Carte远程调度
Kettle的部署有很多种模式,上面讲的是最原生的模式(Pan/Kitchen)。但是这种方式不利于监控、调度和资源分配。Kettle本身提供了一个用于调度的Web服务Carte。Carte允许远程请求HTTP进行监控、启动、停止在Carte服务上运行的job和trans。要部署使用Carte的大致过程如下所示:
1)修改xml配置文件
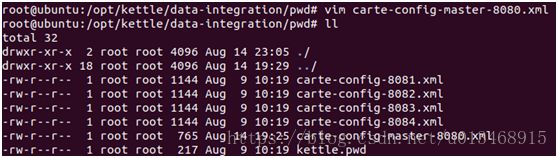

在kettle.pwd的描述中可以知道默认的用户名密码都是cluster(不放心的话可以通过
2)启动Carte
启动时将刚刚的配置文件加上。
![]()
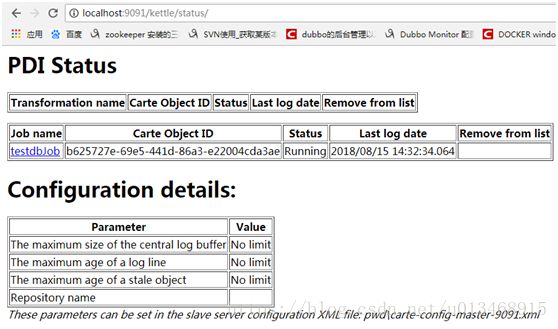
启动完成后就可以访问Carte了,界面非常的简陋。
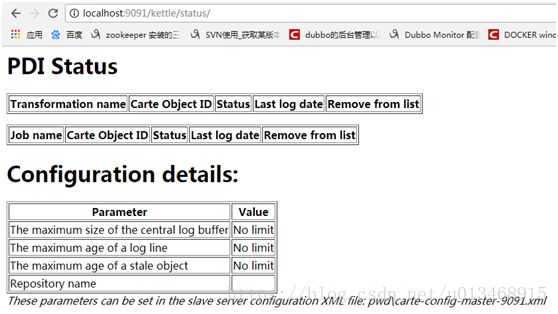
PDI Status应该可以理解,下面的Configuration details上面三条代表日志最大长度、日志存活时间和指定转换或者作业产生的对象的存活时间,这三个属性都是为了防止Out Of Memory。在上面的配置文件中的配置如下所示:

最后一个参数是资源库名称。
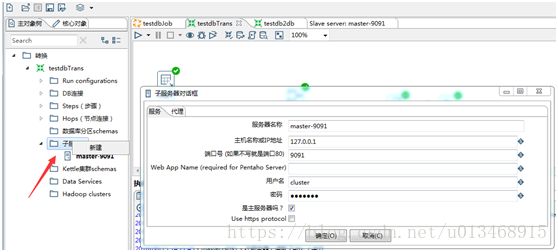
3)配置子服务器
上面是成功的将Carte服务打开,下面就需要将Spoon连接到Carte。在左侧的树中我们需要增加一个子服务器。如下所示:
4)创建一个新的运行配置,setting选择Slave Server。
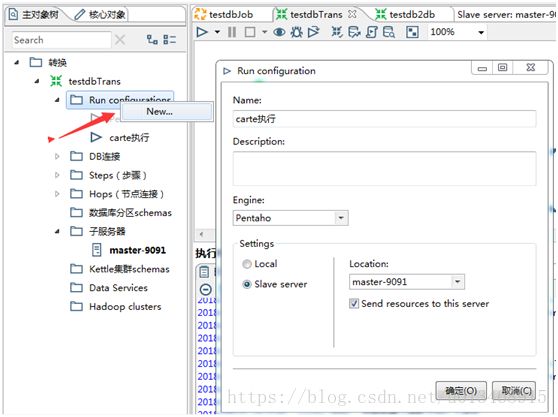
5)提交任务
运行时选择刚刚配置的Carte执行。这样我们执行文件就会上传到Carte服务器指定的目录然后执行。
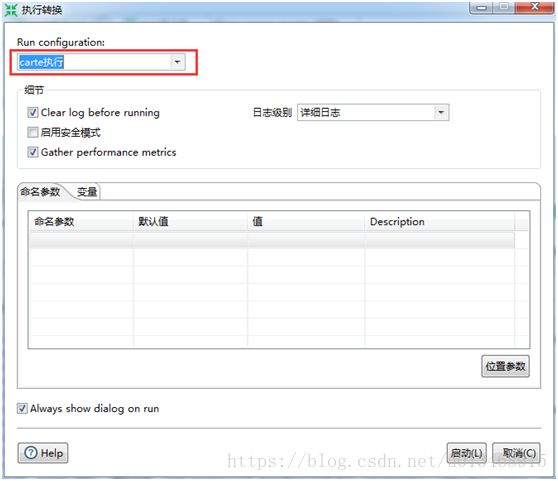
然后在PDI Status界面就能看到执行的任务。点击进行可以看到详细的任务详情。