利用python3爬虫爬取全国天气数据并保存入Mysql数据库
使用的python版本:3.6
导入的库:
from bs4 import BeautifulSoup
import requests
import pymysql首先开始观察要爬取的网页(此处为中国天气网天气预报)
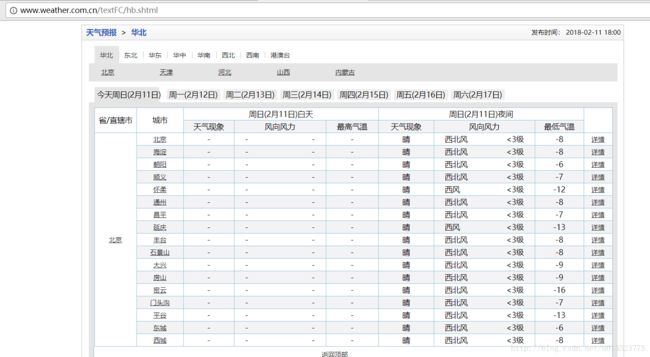
这是华北地区的天气预报,可以观察到网页url为:http://www.weather.com.cn/textFC/hb.shtml
那么切换到东北地区
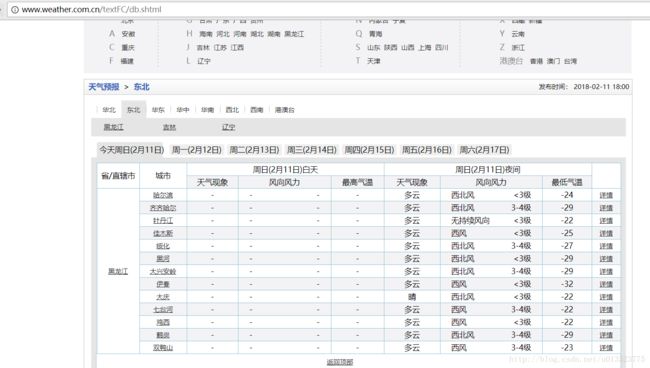
发现url只有textFC/后面的字符改变了,hb代表华北,db代表东北,所以由此可以建立一个url列表
urls = ['http://www.weather.com.cn/textFC/hb.shtml',
'http://www.weather.com.cn/textFC/db.shtml',
'http://www.weather.com.cn/textFC/hd.shtml',
'http://www.weather.com.cn/textFC/hz.shtml',
'http://www.weather.com.cn/textFC/hn.shtml',
'http://www.weather.com.cn/textFC/xb.shtml',
'http://www.weather.com.cn/textFC/xn.shtml']只要循环遍历此表,便可以获取各个地区的天气预报网页url(由于港澳台网页结构较为特殊,此处不做处理)
接下来定义一个get_temperature函数来查找网页中需要的天气信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} # 设置头文件信息
response = requests.get(url, headers=headers).content # 提交requests get 请求
soup = BeautifulSoup(response, "lxml") # 用Beautifulsoup 进行解析构建一个headers参数,并提交request.get请求,接下来使用BeautifulSoup进行网页的解析
在浏览器中按F12观察网页结构,可以发现页面所有的城市信息及该城市的天气信息都在
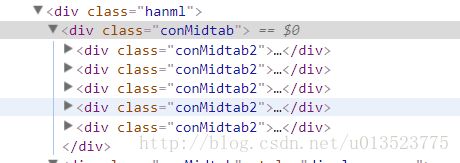
而每个conMidtab2的标签下的内容则为该地区各个省的天气信息

而该省不同城市的天气信息还在conMidtab2的标签下的table的标签下的tbody里的tr标签内的td下,
而且还发现每个省的conMidtab2内的第3个tr标签开始才为真正的城市天气信息,
而每个含有天气信息的tr标签的第一个td标签里含有省份信息,
分析完毕,开始编写代码
conmid = soup.find('div', class_='conMidtab')
conmid2 = conmid.findAll('div', class_='conMidtab2')
for info in conmid2:
tr_list = info.find_all('tr')[2:] # 使用切片取到第三个tr标签
for index, tr in enumerate(tr_list): # enumerate可以返回元素的位置及内容
td_list = tr.find_all('td')
if index == 0:
province_name = td_list[0].text.replace('\n', '') # 取每个标签的text信息,并使用replace()函数将换行符删除
city_name = td_list[1].text.replace('\n', '')
weather = td_list[5].text.replace('\n', '')
wind = td_list[6].text.replace('\n', '')
max = td_list[4].text.replace('\n', '')
min = td_list[7].text.replace('\n', '')
print(province_name)
else:
city_name = td_list[0].text.replace('\n', '')
weather = td_list[4].text.replace('\n', '')
wind = td_list[5].text.replace('\n', '')
max = td_list[3].text.replace('\n', '')
min = td_list[6].text.replace('\n', '')
print(city_name, weather, wind, max, min)利用BeautifulSoup库查找并输出每个标签的text天气信息,再进行处理即为想要的天气信息,最后输出。
完整代码如下:
from bs4 import BeautifulSoup
import requests
def get_temperature(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} # 设置头文件信息
response = requests.get(url, headers=headers).content # 提交requests get 请求
soup = BeautifulSoup(response, "lxml") # 用Beautifulsoup 进行解析
conmid = soup.find('div', class_='conMidtab')
conmid2 = conmid.findAll('div', class_='conMidtab2')
for info in conmid2:
tr_list = info.find_all('tr')[2:] # 使用切片取到第三个tr标签
for index, tr in enumerate(tr_list): # enumerate可以返回元素的位置及内容
td_list = tr.find_all('td')
if index == 0:
province_name = td_list[0].text.replace('\n', '') # 取每个标签的text信息,并使用replace()函数将换行符删除
city_name = td_list[1].text.replace('\n', '')
weather = td_list[5].text.replace('\n', '')
wind = td_list[6].text.replace('\n', '')
max = td_list[4].text.replace('\n', '')
min = td_list[7].text.replace('\n', '')
print(province_name)
else:
city_name = td_list[0].text.replace('\n', '')
weather = td_list[4].text.replace('\n', '')
wind = td_list[5].text.replace('\n', '')
max = td_list[3].text.replace('\n', '')
min = td_list[6].text.replace('\n', '')
print(city_name, weather, wind, max, min)
if __name__=='__main__':
urls = ['http://www.weather.com.cn/textFC/hb.shtml',
'http://www.weather.com.cn/textFC/db.shtml',
'http://www.weather.com.cn/textFC/hd.shtml',
'http://www.weather.com.cn/textFC/hz.shtml',
'http://www.weather.com.cn/textFC/hn.shtml',
'http://www.weather.com.cn/textFC/xb.shtml',
'http://www.weather.com.cn/textFC/xn.shtml']
for url in urls:
get_temperature(url)
现在开始将爬取的信息利用pymysql保存入Mysql数据库中
首先打开数据库连接,并使用cursor()建立一个游标对象
(在此之前你需要手动在数据库中新建一个数据库并新建一个表)
conn=pymysql.connect(host='localhost',user='你的用户名',passwd='你的密码',db='数据库的名称',port=3306,charset='utf8')
cursor=conn.cursor()利用cursor,execute()函数将数据写出你新建的表中
cursor.execute('insert into 你新建的表的名字(city,weather,wind,max,min) values(%s,%s,%s,%s,%s)',(city_name,weather,wind,max,min))最后,使用commit( ) 将所写的数据提交入数据库即可
conn.commit()最终完整代码如下:
from bs4 import BeautifulSoup
import requests
import pymysql
conn=pymysql.connect(host='localhost',user='你的用户名',passwd='你的密码',db='你的数据库名称',port=3306,charset='utf8')
cursor=conn.cursor()
def get_temperature(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} # 设置头文件信息
response = requests.get(url, headers=headers).content # 提交requests get 请求
soup = BeautifulSoup(response, "lxml") # 用Beautifulsoup 进行解析
conmid = soup.find('div', class_='conMidtab')
conmid2 = conmid.findAll('div', class_='conMidtab2')
for info in conmid2:
tr_list = info.find_all('tr')[2:] # 使用切片取到第三个tr标签
for index, tr in enumerate(tr_list): # enumerate可以返回元素的位置及内容
td_list = tr.find_all('td')
if index == 0:
province_name = td_list[0].text.replace('\n', '') # 取每个标签的text信息,并使用replace()函数将换行符删除
city_name = td_list[1].text.replace('\n', '')
weather = td_list[5].text.replace('\n', '')
wind = td_list[6].text.replace('\n', '')
max = td_list[4].text.replace('\n', '')
min = td_list[7].text.replace('\n', '')
print(province_name)
else:
city_name = td_list[0].text.replace('\n', '')
weather = td_list[4].text.replace('\n', '')
wind = td_list[5].text.replace('\n', '')
max = td_list[3].text.replace('\n', '')
min = td_list[6].text.replace('\n', '')
print(city_name, weather, wind, max, min)
cursor.execute('insert into 你新建的表的名字(city,weather,wind,max,min) values(%s,%s,%s,%s,%s)',(city_name,weather,wind,max,min))
if __name__=='__main__':
urls = ['http://www.weather.com.cn/textFC/hb.shtml',
'http://www.weather.com.cn/textFC/db.shtml',
'http://www.weather.com.cn/textFC/hd.shtml',
'http://www.weather.com.cn/textFC/hz.shtml',
'http://www.weather.com.cn/textFC/hn.shtml',
'http://www.weather.com.cn/textFC/xb.shtml',
'http://www.weather.com.cn/textFC/xn.shtml']
for url in urls:
get_temperature(url)
conn.commit()谢谢大家!
源代码下载链接 https://download.csdn.net/download/u013523775/10589499