一、序言
zookeeper工作原理图解
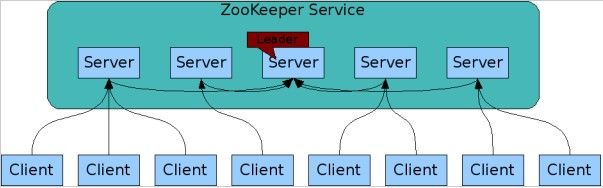
1. 客户端可以连接到每个server,每个server的数据完全相同。
2. 每个follower都和leader有连接,接受leader的数据更新操作。
3. Server记录事务日志和快照到持久存储。
4. 大多数server可用,整体服务就可用。
Zookeeper数据模型
Zookeeper表现为一个分层的文件系统目录树结构(不同于文件系统的是,节点可以有自己的数据,而文件系统中的目录节点只有子节点)。
数据模型结构图如下:
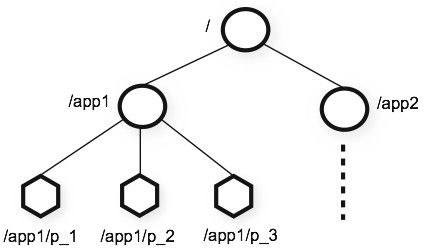
圆形节点可以含有子节点,多边形节点不能含有子节点。一个节点对应一个应用,节点存储的数据就是应用需要的配置信息。
Zookeeper 特点
- 顺序一致性:按照客户端发送请求的顺序更新数据。
- 原子性:更新要么成功,要么失败,不会出现部分更新。
- 单一性 :无论客户端连接哪个server,都会看到同一个视图。
- 可靠性:一旦数据更新成功,将一直保持,直到新的更新。
- 及时性:客户端会在一个确定的时间内得到最新的数据。
Zookeeper运用场景
- 配置管理
在我们的应用中除了代码外,还有一些就是各种配置。比如数据库连接等。一般我们都是使用配置文件的方式,在代码中引入这些配置文件。但是当我们只有一种配置,只有一台服务器,并且不经常修改的时候,使用配置文件是一个很好的做法,但是如果我们配置非常多,有很多服务器都需要这个配置,而且还可能是动态的话使用配置文件就不是个好主意了。这个时候往往需要寻找一种集中管理配置的方法,我们在这个集中的地方修改了配置,所有对这个配置感兴趣的都可以获得变更。比如我们可以把配置放在数据库里,然后所有需要配置的服务都去这个数据库读取配置。但是,因为很多服务的正常运行都非常依赖这个配置,所以需要这个集中提供配置服务的服务具备很高的可靠性。一般我们可以用一个集群来提供这个配置服务,但是用集群提升可靠性,那如何保证配置在集群中的一致性呢? 这个时候就需要使用一种实现了一致性协议的服务了。Zookeeper就是这种服务,它使用Zab这种一致性协议来提供一致性。现在有很多开源项目使用Zookeeper来维护配置,比如在HBase中,客户端就是连接一个Zookeeper,获得必要的HBase集群的配置信息,然后才可以进一步操作。还有在开源的消息队列Kafka中,也使用Zookeeper来维护broker的信息。在Alibaba开源的SOA框架Dubbo中也广泛的使用Zookeeper管理一些配置来实现服务治理。
- 名字服务
名字服务这个就很好理解了。比如为了通过网络访问一个系统,我们得知道对方的IP地址,但是IP地址对人非常不友好,这个时候我们就需要使用域名来访问。但是计算机是不能是别域名的。怎么办呢?如果我们每台机器里都备有一份域名到IP地址的映射,这个倒是能解决一部分问题,但是如果域名对应的IP发生变化了又该怎么办呢?于是我们有了DNS这个东西。我们只需要访问一个大家熟知的(known)的点,它就会告诉你这个域名对应的IP是什么。在我们的应用中也会存在很多这类问题,特别是在我们的服务特别多的时候,如果我们在本地保存服务的地址的时候将非常不方便,但是如果我们只需要访问一个大家都熟知的访问点,这里提供统一的入口,那么维护起来将方便得多了。
- 分布式锁
其实在第一篇文章中已经介绍了Zookeeper是一个分布式协调服务。这样我们就可以利用Zookeeper来协调多个分布式进程之间的活动。比如在一个分布式环境中,为了提高可靠性,我们的集群的每台服务器上都部署着同样的服务。但是,一件事情如果集群中的每个服务器都进行的话,那相互之间就要协调,编程起来将非常复杂。而如果我们只让一个服务进行操作,那又存在单点。通常还有一种做法就是使用分布式锁,在某个时刻只让一个服务去干活,当这台服务出问题的时候锁释放,立即fail over到另外的服务。这在很多分布式系统中都是这么做,这种设计有一个更好听的名字叫Leader Election(leader选举)。比如HBase的Master就是采用这种机制。但要注意的是分布式锁跟同一个进程的锁还是有区别的,所以使用的时候要比同一个进程里的锁更谨慎的使用。
- 集群管理
在分布式的集群中,经常会由于各种原因,比如硬件故障,软件故障,网络问题,有些节点会进进出出。有新的节点加入进来,也有老的节点退出集群。这个时候,集群中其他机器需要感知到这种变化,然后根据这种变化做出对应的决策。比如我们是一个分布式存储系统,有一个中央控制节点负责存储的分配,当有新的存储进来的时候我们要根据现在集群目前的状态来分配存储节点。这个时候我们就需要动态感知到集群目前的状态。还有,比如一个分布式的SOA架构中,服务是一个集群提供的,当消费者访问某个服务时,就需要采用某种机制发现现在有哪些节点可以提供该服务(这也称之为服务发现,比如Alibaba开源的SOA框架Dubbo就采用了Zookeeper作为服务发现的底层机制)。还有开源的Kafka队列就采用了Zookeeper作为Cosnumer的上下线管理。
以下是我对zookeeper 的一些理解:
zookeeper 作为一个服务注册信息存储的管理工具,好吧,这样说得很抽象,我们举个“栗子”。
栗子1号:
假设我是一家KTV的老板,我同时拥有5家KTV,我肯定得时刻监视我KTV 的情况吧,是不是有人打架,或者发生火灾什么的,这时候我会给设置一个视频监控,然后每一家都连接到我的视频监控里面,那么我就可以在家里看到所有KTV 的情况了,如果某一家出现问题,我就能及时发现,并且做出反应。
这个视频监控就相当于zookeeper,每一家的连接,就相当于KTV 的信息。
引用官方的说法: Zookeeper是一个高性能,分布式的,开源分布式应用协调服务。它提供了简单原始的功能,分布式应用可以基于它实现更高级 的服务,比如同步,配置管理,集群管理,名空间。它被设计为易于编程,使用文件系统目录树作为数据模型。服务端跑在java上,提供java和C的客户端 API”
二、安装过程
- 2.1 https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/ 下载
- 2.2 解压到 F:\zookeeper-*
- 3.3 到目录conf下修改zoo_sample.cfg名称为zoo.cfg(最好复制一份)
zoo.cfg 的内容
心跳检查的时间 2秒
tickTime=2000初始化时 连接到服务器端的间隔次数,总时间10*2=20秒
initLimit=10ZK Leader 和follower 之间通讯的次数,总时间5*2=10秒
syncLimit=5存储内存中数据库快照的位置,如果不设置参数,更新事务日志将被存储到默认位置。
dataDir=F:\\zk\\data错误日志的存放位置
dataLogDir=F:\\zk\\logs-
ZK 服务器端的监听端口
clientPort=2181上面的说明介绍:http://zookeeper.apache.org/doc/current/zookeeperStarted.html
然后 cd 到bin 目录下 执行zkServer.cmd 就启动成功了。
注意:dataDir 和 dataLogDir 目录不会自动创建,得手动创建才能启动。
可以用netstat -ano|findstr "2181" 看看是否OK。
也可以用JPS 查看启动的JAVA 进程的情况,会出现这样
查看时候启动
C:\windows\system32>jps
8068
10040 QuorumPeerMain // 这东西是zk的东西,源码有介绍
10556 Jps
也可以用自带客户端命令 : zkCli.cmd -server 127.0.0.1:2181
关于JPS的东西,可以自己去JAVA_HOME\bin 目录下去看,里面很多命令。
三、JAVA 操作zookeeper :
- 4.1 导入依赖:
org.apache.zookeeper
zookeeper
3.4.6
package test;
import org.apache.zookeeper.*;
import org.junit.Test;
import java.io.IOException;
import java.util.Arrays;
import java.util.List;
/**
* Created by Administrator on 2017/7/13.
*/
public class ZookeeperTest {
public final String ROOT = "/root-tuling";
@Test
public void stanModel() throws IOException, KeeperException, InterruptedException {
System.out.println("单机模式运行:");
ZooKeeper zk = new ZooKeeper("127.0.0.1:2181",30000, new Watcher(){
//监听事件发生(改变节点)
public void process(WatchedEvent event){
System.out.println("状态:" + event.getState()+" 类型:"+event.getType()+" 根目录:"+event.getWrapper()+" 目录:"+event.getPath());
}
});
// OPEN_ACL_UNSAFE不进行ACL权限控制,节点为永久性的
zk.create(ROOT, "root-tuling".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
// 然后深圳图灵 ,PERSISTENT_SEQUENTIAL 类型会自动加上 0000000000 自增的后缀(EPHEMERAL session 过期了就会自动删除 )
zk.create(ROOT+"/深圳图灵","深圳图灵".getBytes(),ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL);
zk.create(ROOT+"/上海图灵","上海图灵".getBytes(),ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL);
zk.create(ROOT+"/南京图灵","南京图灵".getBytes(),ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL_SEQUENTIAL);
//取得/root/childone节点下的数据,返回byte[]
byte[] data = zk.getData(ROOT+"/深圳图灵", true, null);
String str = new String(data);
System.out.println(str);
//取得ROOT节点下的子节点名称,返回List
List ktvs = zk.getChildren(ROOT, true);
System.out.println(Arrays.toString(ktvs.toArray()));
for(String node : ktvs){
// 删除节点
zk.delete(ROOT+"/"+node,-1);
}
//删除ROOT节点,第二个参数为版本,-1的话直接删除,无视版本
zk.delete(ROOT,-1);
//关闭session
zk.close();
}
}
四、zookeeper 伪集群
上面我们看到,如果我们的监控室也停电了,那不是就监测不到KTV情况了?一般情况下,zk 也是作为分布式部署了,也就是有多台监控,由于监控多了,肯定要有一定为准(比如直播会有一些延迟),就要涉及到选举的算法,这里暂时不介绍,先搭建一个伪集群,因为机器不够,只能再一台机器上模拟搭建,整个过程无非是将上面的一些配置copy 几份,然后配置不同的 地址和端口就行。
- 我们将F:\zookeeper-3.4.6\conf\下的zoo.cfg 改成zoo1.cfg,内容改为:
# 心跳检查的时间 2秒
tickTime=2000
# 初始化时 连接到服务器端的间隔次数,总时间10*2=20秒
initLimit=10
# ZK Leader 和follower 之间通讯的次数,总时间5*2=10秒
syncLimit=5
# 存储内存中数据库快照的位置,如果不设置参数,更新事务日志将被存储到默认位置。
dataDir=E:\\zk\\data
# 错误日志的存放位置
dataLogDir=E:\\zk\\logs
# ZK 服务器端的监听端口
# 对应分别:2181 2182 2183
clientPort=2181
# 2887 是server 之间通讯的(集群成员的信息交换),3887 是应用程序通讯的(第二个端口是在leader挂掉时专门用来进行选举leader所用)
# 同时加入其他两个服务的地址和端口信息
#server.X 这个数字就是对应 data/myid中的数字
server.1=127.0.0.1:2887:3887
server.2=127.0.0.1:2888:3888
server.3=127.0.0.1:2889:3889
之后在conf文件夹复制两份这个文件分别命名为zoo2.conf、zoo3.conf修改参数clientPort=2182、clientPort=2183
- 同时我们将F:\zookeeper-3.4.6\bin\下的zkServer.cmd改为zkServer1.cmd,内容加上
set ZOOMAIN=org.apache.zookeeper.server.quorum.QuorumPeerMain
# 读取配置的路径,每个启动服务对应一份
set ZOOCFG=..\conf\zoo1.cfg
# 同理创建3个zkServer1.cmd,zkServer2.cmd,zkServer3.cmd 记得改zoo 1 2 3.cfg
==一定得在dataDir 指定目录,也就是E:\zk\data下创建myid的文件,内容对应1 2 3 即可。==
这个的数字是唯一的,在1-255 之间,用来表示自身的id(其实我不明白 为啥zk 要这么设计- -!)启动3个zkServer*.cmd 就OK了,如果要多服务器配置,只需要要将 3份分开放到不同服务器就OK
依次启动的时刻有错误信息,这时会报大量错误?其实没什么关系,因为现在集群只起了1台server,zookeeper服务器端起来会根据zoo.cfg的服务器列表发起选举leader的请求,因为连不上其他机器而报错,那么当我们起第二个zookeeper实例后,leader将会被选出,从而一致性服务开始可以使用,这是因为3台机器只要有2台可用就可以选出leader并且对外提供服务(2n+1台机器,可以容n台机器挂掉)。。