混淆矩阵以及ROC图像
一、混淆矩阵
总结一下混淆矩阵,分类描述及其绘制;ROC曲线含义,及其绘制
1、矩阵图示
如下图就是CM混淆矩阵Confusion Matrix

左边栏是数据的真实的类别,右栏是预测出的类别。简介一下TP,TN,FP,FN含义。
TP 就是 Ture Positive :原来是+,判别为 + 简记为—->“判对为正”
FP 就是 False Positive :原来是 -,判别为 + 简记为—-> “错判为正”
FN 就是False Negative :原来是 +,判别为 - 简记为—-> “错判成负”
TN 就是 True Negative:原来是 -,判别为 - 简记为—-> “判对为负”
很显然上述混淆矩阵适合而分类问题。
sensitivity: 正,判对的概率为 TP / (TP + FN)
specificity: 负,判对的概率为 TN/ (FP + TN)
precision : TP / (TP + FP) 在判为正的里面,判对的概率
recall :TP / (TP + FN) 正的里面判对的概率。== sensitivity
后两者简记,精确度就纵向求和;召回率横向求和。
2、F-score
F-score:精度和召回率的评定函数。Precision高,Recall就低,Recall高,Precision就低。在保证召回率的条件下,尽量提升精确率。而像癌症检测、地震检测、金融欺诈等,则在保证精确率的条件下,尽量提升召回率。所以,很多时候我们需要综合权衡这2个指标,这就引出了一个新的指标F-score。这是综合考虑Precision和Recall的调和值。
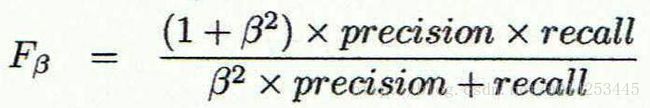
β=1时,就是五五开,同等重要。精确率更重要的时候,就把β调小;召回率重要就把β调大。
3、混淆矩阵CM的绘制方法
# y:真实类别;yp:预测结果类别
def cm_plot(y, yp):
from sklearn.metrics import confusion_matrix #导入混淆矩阵函数
cm = confusion_matrix(y, yp) #混淆矩阵如下
#48 5
# 0 6
import matplotlib.pyplot as plt #导入作图库
plt.matshow(cm, cmap=plt.cm.Greens)#画混淆矩阵图
plt.colorbar() #颜色标签
for x in range(len(cm)): #数据标签
for y in range(len(cm)):
plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center',verticalalignment='center')
plt.ylabel('True label') #坐标轴标签
plt.xlabel('Predicted label') #坐标轴标签
return plt
#执行画图:第四列为真实的类别;前三列为预测集数据
plt = cm_plot(test[:, 3], tree.predict(test[:, :3]))
plt.show()二、ROC曲线
首先列出下表数据,绘制TPR-FPR的关系图(y-x)
设置阈值,来确定最佳曲线

from sklearn.metrics import roc_curve # 导入ROC曲线函数
#获取FPR,TPR的值
fpr, tpr, thresholds = roc_curve(test[:, 3], tree.predict_proba(test[:, :3])[:, 1], pos_label=1)
plt.plot(fpr, tpr, linewidth=2, label='ROC of CART', color='green') # 作出ROC曲线
plt.xlabel('False Positive Rate') # 坐标轴标签
plt.ylabel('True Positive Rate') # 坐标轴标签
plt.ylim(0, 1.05) # 边界范围
plt.xlim(0, 1.05) # 边界范围
plt.legend(loc=4) # 图例
plt.show() # 显示作图结果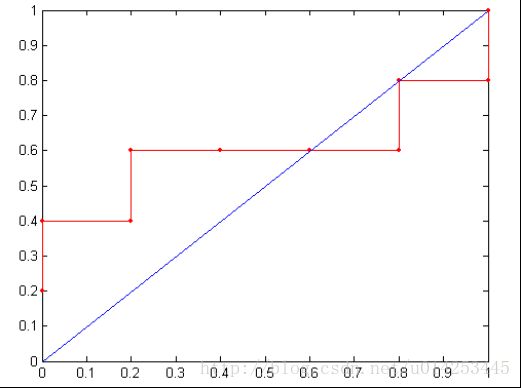
多个ROC曲线,越靠近左上角,效果越好!