【AI视野·今日CV 计算机视觉论文速览 第154期】Wed, 4 Sep 2019
AI视野·今日CS.CV 计算机视觉论文速览
Wed, 4 Sep 2019
Totally 95 papers
?上期速览✈更多精彩请移步主页

Interesting:
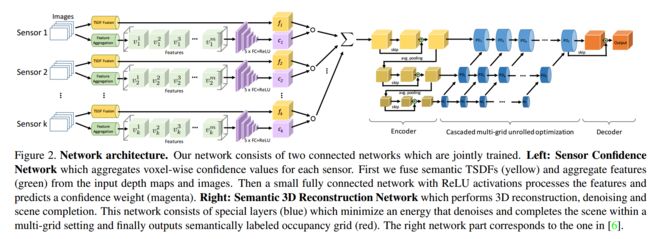
?多传感器语义深度图融合新方法, 研究人员提出了一种新的方法来实现体积深度的融合,将tsdf转变为了语义、多传感器和场景去噪补全三个内容上。在语义方面,语义信息可以丰富场景的表达并与融合过程相配合;在融合方面,深度信息可以与不同传感器或算法的结果进行融合;在场景去噪方面,传感器会在某些情形下缺失数据、这一方法可以对几何形状进行去噪、补全空洞,并为每个语义类别的表面进行严密的补全。最后提出了一个网络来实现上述所有过程的学习。(from 苏黎世理工)
多传感器融合网络,左边为传感器置信度网络,右边为语义三维重建网络。:
在RGB、法向量和深度图输入下这一方法融合的结果:

datasetSUNCG [41], ScanNet [11] and ETH3D [40].
?基于RGB图和mask得到去除某个主体的深度图, 由于场景的结构较为简单,像素往往超过了所需,所有研究人员提出利用掩膜和输入的rgb图除去图中的某些物体并预测出场景的深度信息。(from 伊利诺伊香槟)


下面是从深度图计算法向量的方法:

一些物体去除的结果:

?**假网站识别器WhiteNet, (from CISPA Helmholtz Center for Information Security)

?基于风格迁移来进行数据增强STaDA, (from 都柏林圣三一学院)

code will be:https://github.com/zhengxu001/
?自监督的深度信息去噪模型, (from )


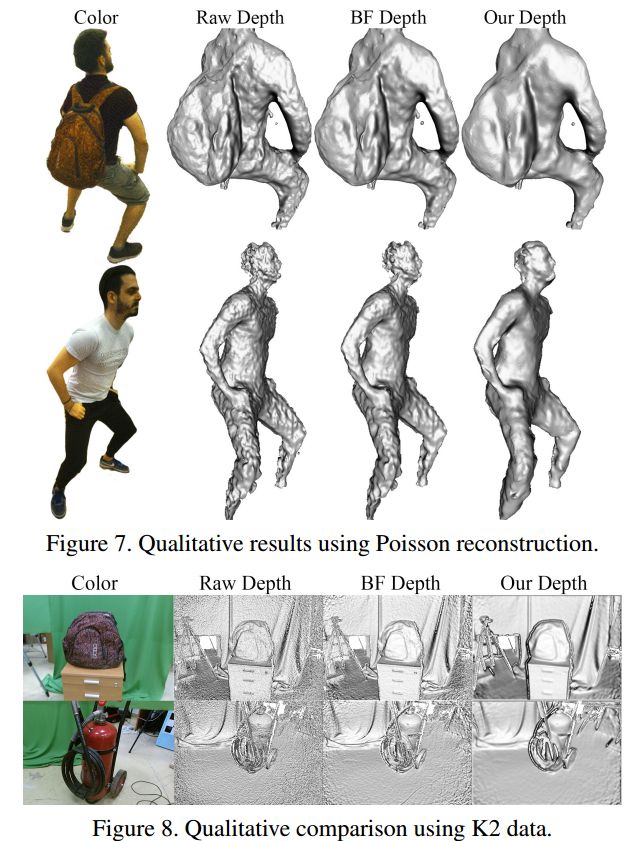
code:https://github.com/VCL3D/DeepDepthDenoising
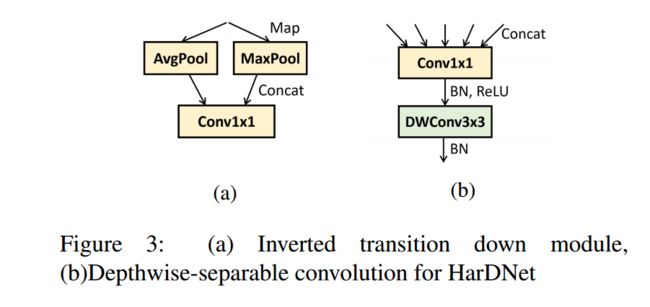
?HarDNet :Harmonic Densely Connected Network,高效的低内存消耗的信息交互网模块



?卫星的视觉6D姿态估计

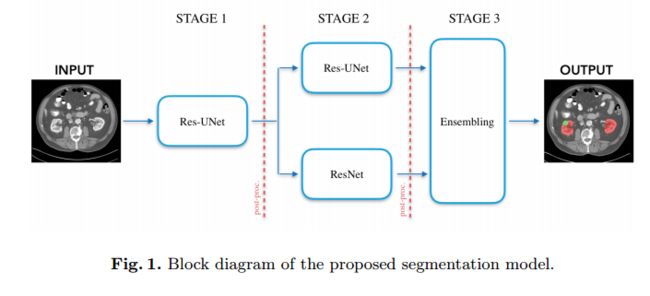
KiTS19 challenge肾脏肿瘤分割

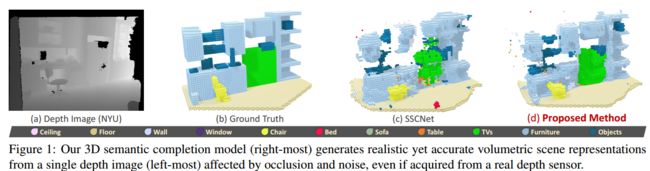
ForkNet 基于单深度图的多分支体积语义补全深度网络

PSDNet and DPDNet高效通道拓展、深度-点-深度的可逆网络模块
+++DeepHealth深度学习在健康信息领域的回顾、挑战和基于,包括医学图像、电子病历、基因、传感器、在线健康等
Daily Computer Vision Papers
| Robust Invisible Video Watermarking with Attention Authors Kevin Alex Zhang, Lei Xu, Alfredo Cuesta Infante, Kalyan Veeramachaneni 视频水印的目标是在视频文件中嵌入消息,使其最小化影响观看体验,但即使视频被重新分发和修改也可以恢复,允许媒体制作者声明对其内容的所有权。本文介绍了RivaGAN,一种用于鲁棒视频水印的新颖架构,它具有基于自定义注意的机制,用于嵌入任意数据,以及两个独立的对抗网络,这些网络对视频质量进行评判并优化稳健性。使用这种技术,我们能够在基于深度学习的视频水印中实现最先进的结果,并且产生具有最小视觉失真并且对常见视频处理操作具有鲁棒性的水印视频。 |
| Online Pedestrian Group Walking Event Detection Using Spectral Analysis of Motion Similarity Graph Authors Vahid Bastani, Damian Campo, Lucio Marcenaro, Carlo S. Regazzoni 本文提出了一种在线识别视频中运动目标群的方法。每个帧处的该方法使用运动相似性图上的谱聚类来识别具有相似局部瞬时运动模式的被跟踪对象组。然后,算法的输出用于检测PETS2015挑战所要求的两个以上物体一起移动的事件。在PETS2015数据集上评估算法的性能。 |
| A CNN-based approach to classify cricket bowlers based on their bowling actions Authors Md Nafee Al Islam, Tanzil Bin Hassan, Siamul Karim Khan 随着硬件技术和深度学习技术的进步,将这些技术应用于不同领域已变得可行。卷积神经网络CNN是深度学习领域的一种架构,它彻底改变了计算机视觉。体育是使用计算机视觉蓬勃发展的途径之一。板球是一个复杂的游戏,包括不同类型的投篮,保龄球动作和许多其他活动。每个投球手,在板球比赛中,用不同的保龄球击球。我们利用这一点来识别不同的保龄球。在本文中,我们提出了一个CNN模型,根据他们使用转移学习的保龄球动作来识别十八个不同的板球保龄球。此外,我们创建了一个全新的数据集,其中包含这18个保龄球运动员的8100张图像,用于训练拟议的框架并评估其性能。我们使用了预先使用ImageNet数据集训练的VGG16模型,并在其上添加了几个层来构建我们的模型。在尝试了不同的策略之后,我们发现冻结网络前14层的权重并训练其余层的效果最好。我们的方法在测试集上实现了93.3的总体平均准确度,并且收敛到非常低的交叉熵损失。 |
| Translating Visual Art into Music Authors Maximilian M ller Eberstein, Nanne van Noord 本研究中引入的Synesthetic变分自动编码器SynVAE能够在没有配对数据集的情况下学习视觉和听觉感官模态之间的一致映射。对MNIST以及Behance Artistic Media数据集BAM的定量评估表明,SynVAE能够在翻译期间保留足够的信息内容,同时保持交叉模态潜在空间的一致性。在定性评估试验中,人类评估员还能够将音乐样本与生成它们的图像进行匹配,准确度高达73。 |
| A Low-Cost, Flexible and Portable Volumetric Capturing System Authors Vladimiros Sterzentsenko, Antonis Karakottas, Alexandros Papachristou, Nikolaos Zioulis, Alexandros Doumanoglou, Dimitrios Zarpalas, Petros Daras 多视图捕获系统是工程师的复杂系统。它们需要技术知识来安装和复杂的过程,以便主要与传感器空间对准相关联,即外部校准。然而,随着新生产方法的不断发展,我们现在处于可以使用商品传感器生产高质量逼真3D资产的位置。尽管如此,使用这些方法开发的捕获系统与方法本身密切相关,依赖于定制解决方案,如果根本不公开,很少。鉴于此,我们设计,开发并公开提供基于最新RGB D传感器技术的多视图捕获系统。对于我们的系统,我们开发了一种便携且易于使用的外部校准方法,可大大减少所需的工作量和知识,并简化整个过程。 |
| Efficient Real-Time Camera Based Estimation of Heart Rate and Its Variability Authors Amogh Gudi, Marian Bittner, Roelof Lochmans, Jan van Gemert 远程照片体积描记术rPPG使用远程放置的相机来估计人的心率HR。类似于心率如何提供关于人的生命体征的有用信息,可以从心率变异性HRV获得关于潜在的生理心理状况的见解。 HRV是心跳之间间隔精细波动的量度。然而,这种措施需要以高精度暂时定位心脏搏动。我们引入了一种精确高效的实时rPPG流水线,具有新颖的滤波和运动抑制功能,不仅可以更准确地估计心率,还可以提取脉搏波形以计算心跳时间并测量心率变异性。该方法不需要rPPG特定培训,并且能够实时操作。我们在理想化的实验室设置下对自记录数据集验证我们的方法,并在具有真实条件VicarPPG和PURE的两个公共数据集上显示最新结果。 |
| Few-Shot Generalization for Single-Image 3D Reconstruction via Priors Authors Bram Wallace, Bharath Hariharan 最近关于单视图3D重建的工作显示了令人印象深刻的结果,但仅限于一些固定类别,其中提供了大量的培训数据。将这些模型推广到训练数据有限的新类的问题基本上是公开的。为了解决这个问题,我们提出了一种新的模型体系结构,该体系结构将单视图3D重建重新构建为所提供的类别特定先验的学习,类别无关的细化。所提供的用于新类的先前形状可以从该类中的少至一个3D形状获得。我们的模型可以使用此先前开始从小说类重建对象,而无需查看此类的任何训练图像并且无需任何再训练。我们的模型优于类别无关的基线,并且与更复杂的基线保持竞争力,这些基线可以对新类别进行微调。此外,尽管没有接受多视图重建任务的培训,但我们的网络能够改善多视图的重建。 |
| Cross View Fusion for 3D Human Pose Estimation Authors Haibo Qiu, Chunyu Wang, Jingdong Wang, Naiyan Wang, Wenjun Zeng 我们提出了一种方法,通过在我们的模型中结合多视图几何先验,从多视图图像中恢复绝对3D人体姿势。它包括两个单独的步骤1,用于估计多视图图像中的2D姿势,以及2从多视图2D姿势中恢复3D姿势。首先,我们将一种跨视图融合方案引入CNN,以共同估计多个视图的2D姿势。因此,每个视图的2D姿势估计已经从其他视图中受益。其次,我们提出了一个递归的图形结构模型,以从多视图2D姿势中恢复3D姿势。它以可承受的计算成本逐步提高3D姿态的准确性。我们在两个公共数据集H36M和Total Capture上测试我们的方法。两个数据集的平均每个关节位置误差分别为26毫米和29毫米,优于26毫米对52毫米,29毫米对35毫米的艺术状态。我们的代码在网址上发布 |
| Self-Supervised Deep Depth Denoising Authors Vladimiros Sterzentsenko, Leonidas Saroglou, Anargyros Chatzitofis, Spyridon Thermos, Nikolaos Zioulis, Alexandros Doumanoglou, Dimitrios Zarpalas, Petros Daras 深度感知被认为是各种视觉任务的宝贵信息来源。然而,使用消费者级传感器获取的深度图仍然遭受不可忽略的噪声。最近,这一事实促使研究人员利用传统滤波器以及深度学习范例,以便在保留几何细节的同时抑制上述非均匀噪声。尽管付出了努力,深度去噪仍然是一个开放的挑战,主要是由于缺乏可用作基本事实的清晰数据。在本文中,我们提出了一种完全卷积的深度自动编码器,它可以学习去噪深度图,超越缺乏地面实况数据。具体地,所提出的自动编码器利用来自不同视点的相同场景的多个视图,以便学习在训练期间使用深度和颜色信息以自我监督的端对端方式抑制噪声,而在推理期间仅使用深度。为了实施自我监控,我们利用可微分渲染技术来开发光度监控,并使用几何和表面先验进一步规范化。由于所提出的方法依赖于原始数据采集,因此使用英特尔实感传感器收集大型RGB D语料库。作为定量评估的补充,我们证明了所提出的自监督去噪方法对已建立的三维重建应用的有效性。代码可用于 |
| MRI Reconstruction Using Deep Bayesian Inference Authors GuanXiong Luo, Na Zhao, Wenhao Jiang, Peng Cao 目的开发基于深度学习的贝叶斯推断MRI重建。方法我们根据最近提出的PixelCNN方法,用贝叶斯定理模拟MRI重建问题。通过最大化后验可能性来获得不完全k空间测量的图像重建。利用生成网络作为图像先验,其在计算上易于处理,并且通过使用等式约束来强制执行k空间数据保真度。利用随机反向传播计算最大后验过程中的下降梯度,并使用投影的次梯度法来施加等式约束。与其他深度学习重建方法相比,所提出的方法使用先验的可能性作为训练损失和重建中的目标函数来改善图像质量。结果与GRAPPA,ell 1 ESPRiT和MODL(一种最先进的深度学习重建方法)相比,该方法在保留图像细节和减少混叠伪像方面表现出改进的性能。与其他方法相比,所提出的方法通常实现压缩感测和并行成像重建的峰值信噪比改善超过5dB。结论与压缩感知重建任务中的常规ell 1稀疏度先验相比,贝叶斯推断显着改善了重建性能。更重要的是,所提出的重建框架可以针对大多数MRI重建场景进行推广。 |
| Fast and Efficient Model for Real-Time Tiger Detection In The Wild Authors Orest Kupyn, Dmitry Pranchuk 迄今为止,最高精度的物体探测器基于两级方法,例如Fast R CNN或一级探测器,例如Retina Net或具有深且复杂骨干的SSD。在本文中,我们介绍了TigerNet简单而有效的基于FPN的网络架构,用于野外的Amur Tiger Detection。该模型具有600k参数,每个图像需要0.071 GFLOP,并且可以近乎实时地在边缘设备智能相机上运行。此外,我们通过伪标记学习方法引入两阶段半监督学习,以从大网络中提取知识。对于ATRW ICCV 2019老虎检测子挑战,基于公共排行榜得分,我们的方法与其他方法相比表现出优越的性能。 |
| ForkNet: Multi-branch Volumetric Semantic Completion from a Single Depth Image Authors Yida Wang, David Joseph Tan, Nassir Navab, Federico Tombari 我们基于单个编码器和用于重建原始和完成场景的不同几何和语义表示的三个独立生成器,从单个深度图像提出用于3D语义完成的新模型,所有这些都共享相同的潜在空间。为了在网络的几何和语义分支之间传递信息,我们在它们之间引入了在相应网络层连接特征的路径。受来自真实场景的有限数量的训练样本的启发,我们的架构的一个有趣属性是通过生成具有高质量,逼真场景甚至包括遮挡和真实噪声的新训练数据集来补充现有数据集的能力。我们通过直接从潜在空间中采样特征来构建新数据集,该潜在空间生成一对部分体积表面和完成的体积语义表面。此外,我们利用多个鉴别器来提高重建的准确性和真实性。我们展示了我们的方法在两个最常见的完成任务语义3D场景完成和3D对象完成的标准基准测试中的优势。 |
| Face-to-Parameter Translation for Game Character Auto-Creation Authors Tianyang Shi 1 , Yi Yuan 1 , Changjie Fan 1 , Zhengxia Zou 2 , Zhenwei Shi 3 , Yong Liu 4 1 NetEase Fuxi AI Lab, 2 University of Michigan, 3 Beihang University, 4 Zhejiang University 角色定制系统是角色扮演游戏角色扮演游戏中的重要组成部分,允许玩家使用自己的喜好编辑游戏角色的面部外观,而不是使用默认模板。本文提出了一种根据输入的面部照片自动创建玩家游戏角色的方法。我们通过解决大量物理上有意义的面部参数的优化问题,在面部相似性测量和参数搜索范例下制定上述艺术创作过程。为了有效地最小化所创建的面部与真实面部之间的距离,特别设计了两种损失函数,即辨别力损失和面部内容丢失。由于游戏引擎的渲染过程不可区分,因此进一步引入生成网络作为模仿游戏引擎物理行为的模仿者,使得所提出的方法可以在神经风格转移框架下实现,并且可以优化参数通过梯度下降。实验结果表明,我们的方法在全局外观和局部细节方面实现了输入面部照片与游戏角色创建之间的高度生成相似性。我们的方法已经在去年的新游戏中部署,现在已被玩家使用超过100万次。 |
| Knowledge Distillation for End-to-EndPerson Search Authors Bharti Munjal, Fabio Galasso, Sikandar Amin 介绍端到端人物搜索的知识蒸馏。端到端方法是用于人员搜索的现有技术,其共同解决检测和重新识别。这些用于联合优化的方法由于次优检测器而显示出其最大的性能下降。 |
| STaDA: Style Transfer as Data Augmentation Authors Xu Zheng, Tejo Chalasani, Koustav Ghosal, Sebastian Lutz, Aljosa Smolic 训练深度卷积神经网络CNN的成功在很大程度上取决于大量的标记数据。最近的研究发现,神经风格转移算法可以将一个图像的艺术风格应用于另一个图像而不改变后者的高级语义内容,这使得采用神经风格转移作为数据增加方法来增加更多变化是可行的。训练数据集。本文的贡献是对神经风格转移作为图像分类任务的数据增强方法的有效性的全面评估。我们探索了最先进的神经风格转移算法,并将其作为数据增强方法应用于Caltech 101和Caltech 256数据集,与传统的数据增强相比,我们发现VGG16的图像分类精度从83到85提高了约2到85。策略。我们还将这种新方法与传统的数据增强方法相结合,以进一步提高图像分类的性能。这项工作展示了神经风格转移在计算机视觉领域的潜力,例如帮助我们减少收集足够标记数据的难度,并提高基于通用图像的深度学习算法的性能。 |
| MANAS: Multi-Agent Neural Architecture Search Authors Fabio Maria Carlucci, Pedro Esperanca, Rasul Tutunov, Marco Singh, Victor Gabillon, Antoine Yang, Hang Xu, Zewei Chen, Jun Wang 神经架构搜索NAS问题通常被表述为图搜索问题,其目标是学习边缘上的最优操作,以便最大化图级全局目标。由于大的架构参数空间,效率是阻止NAS实际使用的关键瓶颈。在本文中,我们通过将NAS构建为多代理问题来解决该问题,其中代理控制网络的子集并协调以达到最佳架构。我们提供两种不同的轻量级实现,具有减少的存储器要求,是现有技术的第八,并且性能高于计算成本更高的方法。从理论上讲,我们证明了O sqrt T形式的消失遗憾,T是总轮数。最后,我们意识到随机搜索是一种经常被忽略的有效基线,我们对3个替代数据集和2个网络配置进行了额外的实验,并在比较中取得了有利的结果。 |
| A Geometry-Sensitive Approach for Photographic Style Classification Authors Koustav Ghosal, Mukta Prasad, Aljosa Smolic 照片的特征在于不同的构图属性,如三分法,景深,消失线等。这些属性中的一个或多个的存在或不存在有助于图像的整体艺术价值。在这项工作中,我们分析了基于深度学习的方法学习这种摄影风格属性的能力。我们观察到,尽管标准CNN相当好地学习了基于纹理和外观的特征,但是它对全局和几何特征的理解受到两个因素的限制。首先,数据增强策略裁剪,扭曲等会扭曲照片的构图并影响性能。其次,CNN特征原则上是平移不变和外观依赖的。但是一些对于美学很重要的几何特性,例如,三次规则RoT,取决于位置和外观不变。因此,我们提出了一种新颖的输入表示,即几何敏感,位置识别和外观不变。我们进一步介绍了一种双列CNN架构,其在摄影风格分类方面比现有技术SoA表现更好。从我们的结果中,我们观察到所提出的网络比SoA更好地学习基于几何和外观的属性。 |
| Unsupervised Video Depth Estimation Based on Ego-motion and Disparity Consensus Authors Lingtao Zhou, Jiaojiao Fang, Guizhong Liu 基于无监督学习的深度估计方法已经受到越来越多的关注,因为它们不需要大量用于训练的密集标记数据来获取。在本文中,我们利用Zhou等人的现有技术方法,在自然场景中提出了一种新的无监督单目视频深度估计方法。它共同估计深度和相机运动。我们的方法通过三个方面超越基线方法1我们通过基于估计的视差并入左右双目图像重建损失来添加附加信号作为基线方法的监督,因此左帧可以通过时间帧和右帧重建立体视觉2网络训练通过联合使用两种视图合成损失和左右视差一致性正则化来同时估计深度和姿势3我们使用边缘感知平滑L2正则化来平滑深度图同时保留目标的轮廓。对KITTI自动驾驶数据集和Make3D数据集的广泛实验表明了我们的算法在训练效率方面的优越性。我们可以通过仅3到5倍的训练数据在基线上获得有竞争力的结果。实验结果还表明,我们的方法甚至优于使用地面实况深度或给定姿势进行训练的经典监督方法。 |
| PSDNet and DPDNet: Efficient channel expansion, Depthwise-Pointwise-Depthwise Inverted Bottleneck Block Authors Guoqing Li, Meng Zhang, Qianru Zhang, Ziyang Chen, Wenzhao Liu, Jiaojie Li, Xuzhao Shen, Jianjun Li, Zhenyu Zhu, Chau Yuen 在许多实时应用中,深度神经网络的部署受到高计算成本的限制,并且高效的轻量级神经网络受到广泛关注。在本文中,我们提出深度卷积DWC用于扩展瓶颈块中的通道数,这比1 x 1卷积更有效。基于使用DWC的信道扩展,所提出的Pointwise标准Depthwise网络PSDNet具有比CIFAR数据集上的相应ResNet更少的参数数量,更少的计算成本和更高的准确度。为了设计更有效的轻量级卷积神经网络,提出了深度逐点倒置瓶颈块DPD块,并通过堆叠DPD块设计DPDNet。同时,对于具有相同层数的网络,DPDNet的参数数量仅为MobileNetV2的60左右,但可以达到近似精度。此外,DPDNet的两个超参数可以在准确性和计算成本之间进行权衡,这使得DPDNet适用于各种任务。此外,我们发现具有更多DWC层的网络优于具有更多1x1卷积层的网络,这表明提取空间信息比组合信道信息更重要。 |
| Object Viewpoint Classification Based 3D Bounding Box Estimation for Autonomous Vehicles Authors Zhou Lingtao, Fang Jiaojiao, Liu Guizhong 3D物体检测是自动驾驶车辆感知系统最重要的任务之一。随着2D物体检测领域的显着成功,基于先进的2D物体检测器和2D和3D边界框之间的几何约束,已经提出了几种基于单目图像的3D物体检测算法。在本文中,我们提出了一种新的方法,用于确定2D 3D几何约束的配置,该方法基于众所周知的2D 3D两阶段对象检测框架。首先,我们将摄像机拍摄对象的离散视点相对于摄像机和物体之间的观察关系分为16类。其次,我们通过将新的子分支集成到现有的多分支CNN中来设计视点分类器。然后,可以根据该分类器的输出确定2D和3D边界框之间的几何约束的配置。对KITTI数据集进行的大量实验表明,我们的方法不仅提高了计算效率,而且提高了模型的整体精度,尤其是方向角估计。 |
| Data Interpretation over Plots Authors Nitesh Methani, Pritha Ganguly, Mitesh M. Khapra, Pratyush Kumar 通过问题回答QA来推理情节是在视觉,语言处理和推理的交叉点上具有挑战性的机器学习任务。现有的合成数据集FigureQA,DVQA不模拟数据标签,实际值数据或复杂推理问题的可变性。因此,针对这些数据集提出的模型并未完全解决推理超过图的挑战。我们建议PlotQA拥有超过220,000个地块的810万个问答案对,其中包含来自真实世界的数据和基于众包问题模板的问题。 PlotQA中的26个问题的答案不在固定的词汇表中,需要推理能力。对PlotQA现有模型的分析表明,需要混合模型通过从固定词汇表中选择答案或从图中预测的边界框中提取答案,可以更好地回答具体问题,而其他问题则通过表格问题答案引擎得到解答通过视觉元素检测提取结构化表格。对于后者,我们提出VOES管道并将其与SAN VQA相结合,形成混合型SAN VOES。在DVQA数据集上,SAN VOES模型的准确度为58,显着提高了最高报告准确度46。在PlotQA数据集中,SAN VOES的准确度为54,这是我们训练的所有模型中最高的。对VOES管道中每个模块的分析表明,精度的进一步提高需要更准确的视觉元素检测。 |
| Image Inpainting with Learnable Bidirectional Attention Maps Authors Chaohao Xie, Shaohui Liu, Chao Li, Ming Ming Cheng, Wangmeng Zuo, Xiao Liu, Shilei Wen, Errui Ding 大多数基于卷积网络CNN的修复方法采用标准卷积来区分处理有效像素和空洞,使得它们在处理不规则空洞方面受到限制,更容易产生具有颜色差异和模糊性的修复结果。已建议使用部分卷积来解决此问题,但它采用手工制作的特征重新规范化,并且仅考虑正向掩码更新。在本文中,我们提出了一个可学习的注意力映射模块,用于以端到端的方式学习特征重整化和掩模更新,这对于适应卷积层的不规则孔和传播是有效的。此外,引入可学习的反向注意力图以允许U Net的解码器专注于填充不规则的孔而不是重建孔和已知区域,从而产生我们可学习的双向注意力图。定性和定量实验表明,我们的方法在产生更清晰,更连贯和视觉上合理的修复结果方面对现有技术有利。源代码和预先训练的模型将在 |
| HarDNet: A Low Memory Traffic Network Authors Ping Chao, Chao Yang Kao, Yu Shan Ruan, Chien Hsiang Huang, Youn Long Lin 最先进的神经网络架构,如ResNet,MobileNet和DenseNet,在低MAC和小型号的同类产品上实现了出色的精度。但是,这些指标可能无法准确预测推断时间。我们建议用于访问中间特征映射的内存流量可以是支配推理延迟的因素,尤其是在诸如实时对象检测和高分辨率视频的语义分段之类的任务中。我们提出了一种谐波密集连接网络,以实现低MAC和内存流量方面的高效率。与FC DenseNet 103,DenseNet 264,ResNet 50,ResNet 152和SSD VGG相比,新网络分别实现了35,36,30,32和45个推理时间缩短。我们使用包括Nvidia分析器和ARM Scale Sim在内的工具来测量内存流量,并验证推断延迟确实与内存流量消耗成正比,并且建议的网络消耗低内存流量。我们得出结论,在为边缘的高分辨率应用设计神经网络架构时,应考虑内存流量。 |
| Counterfactual Depth from a Single RGB Image Authors Theerasit Issaranon, Chuhang Zou, David Forsyth 我们描述了一种方法,该方法从单个RGB图像中预测一个深度图,该深度图描述了当被移除蒙版对象时的场景,我们称之为反事实深度,它将隐藏的场景几何与观察结果一起建模。我们的方法的工作原理与场景完成工作的原因相同,对象的空间结构很简单。但是我们提供比当前场景完成方法更高分辨率的空间表示,因为我们以像素级精度操作并且不依赖于体素表示。此外,我们不需要RGBD输入。我们的方法使用标准编码器解码器架构,并且修改解码器以接受对象掩码。我们描述了一个我们收集的小型评估数据集,它可以推断哪些因素对重建的影响最大。使用此数据集,我们显示我们对蒙版对象的深度预测优于其他基线。 |
| Domain Randomization and Pyramid Consistency: Simulation-to-Real Generalization without Accessing Target Domain Data Authors Xiangyu Yue, Yang Zhang, Sicheng Zhao, Alberto Sangiovanni Vincentelli, Kurt Keutzer, Boqing Gong 我们建议利用模拟的潜力,以领域概括方式对现实世界自驾车场景进行语义分割。在没有任何目标域数据的情况下训练分段网络,并在看不见的目标域上进行测试。为此,我们提出了一种领域随机化和金字塔一致性的新方法来学习具有高普遍性的模型。首先,我们建议使用辅助数据集在视觉外观方面使用真实图像的样式随机化合成图像,以便有效地学习域不变表示。其次,我们进一步在不同的程式化图像和图像内强制执行金字塔一致性,以分别学习域不变和尺度不变特征。对从GTA和SYNTHIA到Cityscapes,BDDS和Mapillary的推广进行了广泛的实验,我们的方法比现有技术获得了更好的结果。值得注意的是,我们的泛化结果与通过现有技术模拟到实际域自适应方法获得的结果相当甚至更好,后者在训练时访问目标域数据。 |
| FACSIMILE: Fast and Accurate Scans From an Image in Less Than a Second Authors David Smith, Matthew Loper, Xiaochen Hu, Paris Mavroidis, Javier Romero 目前用于体形估计的方法要么缺乏细节,要么需要许多图像。它们通常在架构上很复杂并且计算成本很高。我们提出了FACSIMILE FAX,这是一种从单张照片中估计细节体的方法,降低了创建人类虚拟表示的标准。我们的方法易于实施且执行速度快,易于部署。传真使用图像转换网络,以图像的原始分辨率恢复几何。与直觉相反,驱动传真的主要损失是基于每像素表面法线而不是每像素深度,使得可以在没有任何深度监督的情况下估计详细的车身几何形状。我们在质量和数量上评估我们的方法,并与现有技术方法进行比较。 |
| Performance comparison of 3D correspondence grouping algorithm for 3D plant point clouds Authors Shiva Azimi, Tapan K. Gandhi 植物表现组学可用于监测植物的健康和生长。诸如立体重建,图像检索,对象跟踪和对象识别的计算机视觉应用在基于成像的植物表型中起重要作用。本文对一些流行的3D通信分组算法进行了比较评估,其动机是它们在模型创建,植物识别和识别植物部分等任务中可以发挥的重要作用。本文的另一个贡献是将2D最大似然匹配扩展到3D最大似然估计样本共识MLEASAC。 MLESAC是有效的,并且在计算上不如3D随机样本共识RANSAC强烈。我们在植物的3D点云上测试这些算法,以及解决形状检索和点云注册方案的两个标准基准。在精度和召回方面评估性能。 |
| HiCoRe: Visual Hierarchical Context-Reasoning Authors Pedro H. Bugatti, Priscila T. M. Saito, Larry S. Davis 关于图像对象及其层次交互的推理是下一代计算机视觉方法的关键概念。在这里,我们提出了一个新的框架,通过基于可视化分层上下文的推理来处理它。当前的推理方法使用来自图像对象及其交互的细粒度标签来预测新对象的标签。我们的框架修改了当前的信息流。它超越并独立于对象的细粒度标签以定义图像上下文。它考虑了不同抽象级别之间的层次交互,即图像中信息的分类及其边界框。除了这些联系,它还考虑了它们的内在特征。为此,我们使用卷积神经网络构建并应用图形到图形卷积网络。我们对广泛使用的卷积神经网络表现出强大的效果,在众所周知的图像数据集上获得3倍的增益。我们在不同场景下评估框架的功能和行为,考虑不同的超类,子类和分层粒度级别。我们还通过图注意网络和预处理方法探索注意机制,考虑维度扩展和/或特征表示的减少。进行进一步分析,比较监督和半监督方法。 |
| HishabNet: Detection, Localization and Calculation of Handwritten Bengali Mathematical Expressions Authors Md Nafee Al Islam, Siamul Karim Khan 最近,手写的孟加拉语字母和数字的识别引起了AI社区研究人员的广泛关注。在这项工作中,我们提出了一种基于卷积神经网络CNN的物体检测模型,该模型可以识别和评估手写的孟加拉语数学表达式。该方法能够检测多个孟加拉数字和运算符,并在图像中定位它们的位置。利用该信息,它能够从一系列数字构造数字并对它们执行数学运算。对于对象检测任务,使用了现有技术的YOLOv3算法。为了训练和评估模型,我们设计了一个新的数据集Hishab,这是第一个用于物体检测的孟加拉手写数字数据集。该模型的总体验证平均精度mAP为98.6。此外,我们模型中使用的特征提取器主干CNN的分类准确性在两个公开可用的孟加拉手写数字数据集NumtaDB和CMATERdb上进行了测试。主干CNN在NumtaDB上实现了99.6252的测试集精度,在CMATERdb上实现了99.0833。 |
| White-Box Evaluation of Fingerprint Matchers Authors Steven A. Grosz, Joshua J. Engelsma, Nicholas G. Paulter Jr., Anil K. Jain 已经对指纹识别系统进行了现有的评估,作为指纹识别或验证准确性的端到端黑盒测试。然而,端到端系统的性能受到任何组成模块中出现的错误的影响,包括指纹读取器,预处理,特征提取和匹配。虽然一些研究已经对指纹识别系统的指纹识别器和特征提取模块进行了白盒测试,但是很少有人致力于指纹匹配子模块的白盒评估。我们报告了一个开放源和两个商业现货的受控白盒评估结果,它们对基于受控扰动随机噪声的鲁棒性以及引入输入细节特征集的非线性失真的基于细节的基于细节的匹配器进行了评估。 。对10,000个合成生成的指纹进行实验。我们的白盒评估显示了在存在各种扰动和非线性失真的情况下基于不同细节的匹配器之间的性能比较,这些先前未在黑盒测试中显示。此外,我们的白盒评估显示,指纹细节匹配器的性能比虚假细节和细节位置的小位置位移更容易受到非线性失真和缺失细节的影响。还开发了指纹匹配中的测量不确定度。 |
| Dynamic Approach for Lane Detection using Google Street View and CNN Authors Rama Sai Mamidala, Uday Uthkota, Mahamkali Bhavani Shankar, A. Joseph Antony, A. V. Narasimhadhan 车道检测算法一直是完全辅助和自主导航系统的关键推动因素。本文采用基于SegNet编码器解码器结构的卷积神经网络CNN模型,提出了一种新颖实用的车道检测方法。编码器块呈现输入的低分辨率特征图,并且解码器块提供来自特征图的像素分类。所提出的模型已经过2000多个图像数据集的训练,并根据评估数据集中提供的相应基础事实进行测试。为了实现实时导航,我们扩展了模型的预测,将其与现有的Google API连接,评估调整超参数的模型的指标。这种方法的新颖之处在于将现有的segNet架构与谷歌API集成在一起。该界面使其适用于辅助机器人系统。观察到的结果表明,由于涉及预处理,所提出的方法在具有挑战性的遮挡条件下是稳健的,并且与现有方法相比具有优越的性能。 |
| Geometry Normalization Networks for Accurate Scene Text Detection Authors Youjiang Xu, Jiaqi Duan, Zhanghui Kuang, Xiaoyu Yue, Hongbin Sun, Yue Guan, Wayne Zhang 大的几何形状,例如,方向变化是场景文本检测中的关键挑战。在这项工作中,我们首先进行实验以研究网络在检测场景文本时学习几何变化的能力,并发现网络只能处理有限的文本几何差异。然后,我们提出了一个新的几何规范化模块GNM,它具有多个分支,每个分支由一个规模归一化单元和一个方向归一化单元组成,通过至少一个分支将每个文本实例规范化为一个所需的规范几何范围。 GNM是通用的,并且很容易插入到现有的基于卷积神经网络的文本检测器中,以构建端到端的几何规范化网络GNNets。此外,我们提出了一种几何感知训练方案,通过从均匀几何方差分布中采样和扩充文本实例来有效地训练GNNets。最后,对ICDAR 2015和ICDAR 2017 MLT的流行基准的实验证实,我们的方法通过分别获得88.52和74.54的一个前向测试F分数,显着优于所有最先进的方法。 |
| Adversarial Learning and Self-Teaching Techniques for Domain Adaptation in Semantic Segmentation Authors Umberto Michieli, Matteo Biasetton, Gianluca Agresti, Pietro Zanuttigh 深度学习技术已广泛应用于自动驾驶系统中,用于对城市场景进行语义理解,但是他们需要大量的标记数据用于训练,这对于获取而言是困难且昂贵的。最近提出的解决方法是使用合成数据训练深度网络,但是现实世界和合成表示之间的域转换限制了性能。在这项工作中,引入了一种新的无监督域自适应策略来解决这个问题。所提出的学习策略由标记的合成数据的标准监督学习损失的三个组成部分驱动,对抗性学习模块利用标记的合成数据和未标记的真实数据,最后利用未标记的数据来利用自学教学策略。最后一个组件利用由分段置信度引导的区域增长框架。此外,我们根据类频率对此组件进行加权,以提高不常见类的性能。实验结果证明了该策略在将合成数据集(如GTA5和SYNTHIA)训练的分割网络适用于Cityscapes和Mapillary等真实世界数据集方面的有效性。 |
| Combining Deep Learning and Model-Based Methods for Robust Real-Time Semantic Landmark Detection Authors Benjamin Naujoks, Patrick Burger, Hans Joachim Wuensche 与抽象特征相比,重要对象(所谓的地标)是用于车辆定位和导航的更自然的手段,尤其是在挑战非结构化环境中。主要的挑战是识别各种照明条件下的地标和不断变化的植被环境,同时只提供很少的训练样本。我们提出了一种利用深度学习和基于模型的方法来克服大数据集需求的新方法。使用RGB图像和光检测以及测距LiDAR点云,我们的方法将卷积神经网络CNN的现有分类结果与基于鲁棒模型的方法结合起来,将先前知识考虑到先前时间步骤。以树木和灌木作为地标的具有挑战性的真实场景的评估显示出基于纯学习的最先进的3D探测器的有希望的结果,同时显着更快。 |
| Estimation of Absolute Scale in Monocular SLAM Using Synthetic Data Authors Danila Rukhovich, Daniel Mouritzen, Ralf Kaestner, Martin Rufli, Alexander Velizhev 本文通过估计连续图像帧的摄像机中心之间的绝对距离来解决单眼SLAM中的尺度估计问题。这些估计将改善经典的非深SLAM系统的整体性能,并允许从单个单目相机恢复度量特征位置。我们提出了几种网络架构,这些架构可以提高现有技术水平的尺度估计精度。此外,我们利用仅使用从计算机图形模拟器得到的合成数据来训练神经网络的可能性。我们的主要观点是,仅使用合成训练输入,我们可以实现与从实际数据获得的相似的比例估计精度。这一事实表明,完全注释的模拟数据是对基于实际未标记数据训练的现有基于深度学习的SLAM系统的可行替代方案。我们对无监督域自适应的实验也表明,模拟和实际数据之间视觉外观的差异不会影响尺度估计结果。我们的方法使用0.03MP的低分辨率图像进行操作,这使其适用于使用单目相机的实时SLAM应用。 |
| Learned Semantic Multi-Sensor Depth Map Fusion Authors Denys Rozumnyi, Ian Cherabier, Marc Pollefeys, Martin R. Oswald 基于截断有符号距离函数的体积深度图融合已成为一种标准方法,并用于许多三维重建管道。在本文中,我们以多种方式概括这种经典方法1语义语义信息丰富了场景表示,并融入了融合过程。 2多传感器深度信息可以来自不同的传感器或算法,具有非常不同的噪声和异常值统计数据,这些数据在数据融合期间被考虑。 3场景降噪和完成传感器无法恢复某些材料和光照条件的深度,或者由于遮挡而丢失数据。我们的方法对几何体进行去噪,关闭孔并为每个语义类计算一个防水表面。 4学习我们提出了一种神经网络重建方法,它在一个强大的框架内统一所有这些属性。我们的方法与语义深度融合和场景完成一起学习传感器或算法属性,并且还可以用作专家系统,例如,统一各种光度立体算法的优势。我们的方法是第一个统一所有这些属性的方法。对合成数据集和实际数据集的实验评估表明了明显的改进。 |
| Training-Time-Friendly Network for Real-Time Object Detection Authors Zili Liu, Tu Zheng, Guodong Xu, Zheng Yang, Haifeng Liu, Deng Cai 现代物体探测器很少能够同时实现短训练时间,快速推理速度和高精度。为了在它们之间取得平衡,我们提出了培训时间友好网络TTFNet。在这项工作中,我们从轻头,单级和无锚设计开始,实现快速推理速度。然后,我们专注于缩短培训时间。我们注意到,生产更高质量的样品与增加批量大小具有相似的作用,这有助于提高学习率并加快培训过程。为此,我们引入了一种使用高斯核生成训练样本的新方法。此外,我们设计了主动样本权重,以便更好地利用信息。 MS COCO的实验表明,我们的TTFNet在平衡训练时间,推理速度和准确性方面具有很大的优势。与先前的实时探测器相比,它将训练时间缩短了七倍以上,同时保持了最先进的性能。此外,我们的超快速版TTFNet 18和TTFNet 53的性能分别优于SSD300和YOLOv3不到其培训时间的十分之一。代码已在网址上提供 |
| Semantic filtering through deep source separation on microscopy images Authors Avelino Javer, Jens Rittscher 就其本质而言,细胞和组织的显微镜图像由有限数量的对象类型或组件组成。与大多数自然场景相比,该组合物是先验已知的。将生物图像分解为具有语义意义的物体和层次是本文的目的。基于最近的图像去噪方法,我们提出了一种框架,该框架可以实现最先进的分割结果,只需要很少或不需要手动注释。在这里,通过添加细胞作物产生的合成图像足以训练模型。对细胞图像,组织学数据集和小动物视频的广泛实验表明,我们的方法推广到广泛的实验环境。由于所提出的方法不需要密集标记的训练图像并且能够解析部分重叠的对象,因此它有望在许多不同的应用中使用。 |
| This is not what I imagined: Error Detection for Semantic Segmentation through Visual Dissimilarity Authors David Haldimann, Hermann Blum, Roland Siegwart, Cesar Cadena 由于深度学习的能力,语义分割的准确性取得了显着进步。不幸的是,这些方法不能比他们的训练数据的分布更加概括,并且不能适当地处理分发类。这限制了对自主或安全关键系统的适用性。我们提出了一种利用生成模型来检测错误分段或分布式实例的新方法。以预测的语义分割为条件,生成RGB图像。然后,我们学习一种不相似度量,将生成的图像与原始输入进行比较,并检测语义分段引入的不一致性。我们提出了异常值和错误分类检测的测试用例,并在多个数据集上定性和定量地评估我们的方法。 |
| Relationship-Aware Spatial Perception Fusion for Realistic Scene Layout Generation Authors Hongdong Zheng, Yalong Bai, Wei Zhang, Tao Mei 生成对抗网络GAN的重大进展使得基于自然语言描述为单个对象生成令人惊讶的逼真图像成为可能。然而,由于场景布局生成严重受到分集对象缩放和空间位置的影响,因此仍然难以实现具有显式交互的多个实体的图像的受控生成。在本文中,我们提出了一个新的框架,用于从文本场景图生成逼真的图像布局。在我们的框架中,空间约束模块被设计为适合对象的合理缩放和空间布局,同时考虑它们之间的关系。此外,引入了上下文融合模块,用于在场景图中的对象依赖性方面融合成对的空间信息。通过使用这两个模块,我们提出的框架倾向于生成更常见的布局,这有助于逼真的图像生成。实验结果包括定量结果,定性结果和两个不同场景图数据集的用户研究,证明了我们提出的框架能够从场景图生成具有多个对象的复杂和逻辑布局。 |
| Towards Flops-constrained Face Recognition Authors Yu Liu, Guanglu Song, Manyuan Zhang, Jihao Liu, Yucong Zhou, Junjie Yan 特别是在计算预算有限的情况下,大规模人脸识别具有挑战性。给定textit flops上限,关键是找到最优的神经网络架构和优化方法。在本文中,我们简要介绍了针对ICCV19轻量级人脸识别挑战的团队木马的解决方案。挑战要求每次提交都是单一模型,计算预算不超过30 GFlops。我们介绍了基于Flops约束的搜索网络架构Efficient PolyFace,一种新颖的丢失函数ArcNegFace,一种新颖的帧聚合方法QAN,以及我们实现扩充,常规面,标签平滑,锚点微调等方面的一些有用技巧。 。我们的基本型号Efficient PolyFace,基于biggace大图像的轨道需要28.25 Gflops,而PolyFace QAN解决方案需要24.12 Gflops用于iQiyi大型视频轨道。这两个解决方案分别在两个轨道中达到94.198 1e 8和72.981 1e 4,这是现有技术的结果。 |
| Self-Training and Adversarial Background Regularization for Unsupervised Domain Adaptive One-Stage Object Detection Authors Seunghyeon Kim, Jaehoon Choi, Taekyung Kim, Changick Kim 基于深度学习的物体探测器已经显示出显然而,当列车数据和测试数据具有不同的分布时,基于监督学习的方法表现不佳。为了解决该问题,域适应将知识从标签足够的域源域转移到标签稀缺域目标域。自我训练是实现领域适应的有力方法之一,因为它有助于类智能领域适应。不幸的是,一种利用伪标签作为基础事实的天真方法由于不正确的伪标签而退化了性能。在本文中,我们介绍了弱自我训练WST方法和对抗背景分数正则化BSR用于域自适应一阶段目标检测。 WST减少了不准确的伪标签对稳定学习过程的不利影响。 BSR帮助网络提取目标背景的判别特征,以减少域移位。两个组成部分相互补充,因为BSR增强了前景和背景之间的区别,而WST加强了阶级明智的歧视。实验结果表明,该方法有效地提高了无监督域自适应设置中一级目标检测的性能。 |
| Self-Ensembling with GAN-based Data Augmentation for Domain Adaptation in Semantic Segmentation Authors Jaehoon Choi, Taekyung Kim, Changick Kim 基于深度学习的语义分割方法具有固有的局限性,即训练模型需要具有像素级注释的大量数据。为了解决这个具有挑战性的问题,许多研究人员关注语义分割的无监督域自适应。无监督域自适应寻求使在源域上训练的模型适应目标域。在本文中,我们介绍了一种自组合技术,这是一种成功的分类领域适应方法。然而,将自我集成应用于语义分割是非常困难的,因为在自组合中使用的大量调整的手动数据增量对于减少语义分段中的大域间隙是无用的。为了克服这种限制,我们提出了一种由两个组成部分组成的新框架,它们彼此互补。首先,我们提出了一种基于生成对抗网络GAN的数据增强方法,该方法计算效率高,有效促进域对齐。给定这些增强图像,我们应用自组合来增强目标域上的分段网络的性能。所提出的方法在无监督域自适应基准上优于现有技术的语义分割方法。 |
| Semantic Segmentation of Panoramic Images Using a Synthetic Dataset Authors Yuanyou Xu, Kaiwei Wang, Kailun Yang, Dongming Sun, Jia Fu 全景图像由于其大视场FoV而在信息容量和场景稳定性方面具有优势。在本文中,我们提出了一种合成全景图像新数据集的方法。我们设法将从不同方向拍摄的图像拼接成全景图像以及它们的标记图像,以产生称为SYNTHIA PANO的全景语义分割数据集。为了找出使用全景图像作为训练数据集的效果,我们设计并执行了一整套实验。实验结果表明,使用全景图像作为训练数据有利于分割结果。此外,已经表明,通过使用具有180度FoV的全景图像作为训练数据,该模型具有更好的性能。此外,用全景图像训练的模型也具有更好的抵抗图像失真的能力。 |
| Flexible Auto-weighted Local-coordinate Concept Factorization: A Robust Framework for Unsupervised Clustering Authors Zhao Zhang, Yan Zhang, Sheng Li, Guangcan Liu, Dan Zeng, Shuicheng Yan, Meng Wang 由于对噪声的敏感性,对重建误差的严格约束以及预先获得的近似相似性,概念因子分解CF及其变体可能产生不准确的表示和聚类结果。为了提高表示能力,提出了一种新的无监督鲁棒柔性自动加权局部坐标概念因子分解RFA LCF框架,用于聚类高维数据。具体而言,RFA LCF通过干净的数据空间恢复,强大的稀疏局部坐标编码和自适应加权将强大的灵活CF集成到统一模型中。 RFA LCF通过增强CF对噪声和误差的鲁棒性来改善表示,提供对重建误差的灵活约束并联合优化局部性。为了实现稳健的学习,RFA LCF清楚地学习稀疏投影以恢复底层干净的数据空间,然后在投影的特征空间中执行灵活的CF. RFA LCF还使用基于L2,1范数的灵活残差来编码恢复的数据与其重建之间的不匹配,并使用鲁棒的稀疏局部坐标编码来使用一些附近的基本概念来表示数据。对于自动加权,RFA LCF通过最小化干净数据,锚点和坐标上的重建误差,以自适应方式联合保留基础概念空间和新坐标空间中的流形结构。通过交替更新局部坐标保持数据,基础概念和新坐标,可以潜在地改进表示能力。公共数据库的广泛结果表明,与其他相关方法相比,RFA LCF提供了最先进的聚类结果。 |
| Visual Deprojection: Probabilistic Recovery of Collapsed Dimensions Authors Guha Balakrishnan, Adrian V. Dalca, Amy Zhao, John V. Guttag, Fredo Durand, William T. Freeman 我们引入了视觉去除功能,即恢复沿着维度折叠的图像或视频。投影出现在各种情况下,例如长时间曝光摄影,其中动态场景及时折叠以产生运动模糊图像,以及角落相机,其中来自场景的反射光沿着空间维度折叠,因为边缘遮挡物屈服一维视频。对于给定的输入,通常存在许多合理的解决方案。我们首先提出一个概率模型来捕捉任务的模糊性。然后,我们使用卷积神经网络作为函数逼近器提出变分推理策略。在测试时从推理网络进行的采样从原始信号的分布产生似乎合理的候选者,其与给定的输入投影一致。我们在几个数据集上评估空间和时间deprojection任务的方法。我们首先证明该方法可以从空间投影中恢复人类步态视频和面部图像,然后表明它可以从通过时间投影获得的显着运动模糊图像中恢复移动数字的视频。 |
| Towards Robust Learning-Based Pose Estimation of Noncooperative Spacecraft Authors Tae Ha Park, Sumant Sharma, Simone D Amico 这项工作提出了一种新颖的卷积神经网络CNN架构和训练程序,以实现非合作航天器的稳健和准确的姿态估计。首先,引入了新的CNN架构,在斯坦福太空集合实验室SLAB和欧洲航天局ESA高级概念团队ACT主办的近期姿态评估挑战赛中获得第四名。所提出的架构首先通过回归2D边界框来检测对象,然后单独的网络从在检测到的感兴趣区域RoI周围裁剪的目标图像中回归已知表面关键点的2D位置。在单个图像姿势估计问题中,提取的2D关键点可以与对应的3D模型坐标结合使用,以通过Perspective n Point PnP问题计算相对姿势。这些关键点位置已知与3D模型中的关键点位置的对应关系,因为CNN被训练为以预定义的顺序预测角落,允许绕过计算上昂贵的特征匹配过程。这项工作还介绍和探索了纹理随机化,以训练CNN用于星载应用。具体而言,应用神经样式转移NST来使合成渲染图像中的航天器纹理随机化。结果表明,使用航天器的纹理随机图像进行训练可以提高网络在星载图像上的性能,而不会在训练过程中暴露于星载图像。研究还表明,在训练过程中使用纹理随机化航天器图像时,回归三维边界框角可以获得更好的星载图像表现,而不是回归表面关键点,因为NST不可避免地扭曲了表面关键点与之关系更近的航天器几何特征。 |
| Improved Image Augmentation for Convolutional Neural Networks by Copyout and CopyPairing Authors Philip May 图像增强是一种广泛使用的技术,用于改善卷积神经网络CNN的性能。在常见的图像移位中,裁剪,翻转,剪切和旋转用于增强。但是还有更多高级技术,如Cutout和SamplePairing。在这项工作中,我们提出了最先进的Cutout和SamplePairing技术的两项改进。我们称为Copyout的新方法采用另一个随机训练图像的方形补丁,并将其复制到用于训练的每个图像的随机位置。我们发现的第二种技术称为CopyPairing。它结合了Copyout和SamplePairing进一步增强,甚至更好的性能。我们在CIFAR 10数据集上应用这些增强技术的不同实验,以在不同配置下评估和比较它们。在我们的实验中,我们表明,与Cutout相比,Copyout将测试错误率降低了8.18,与SamplePairing相比降低了4.27。与Cutout相比,CopyPairing将测试错误率降低了11.97,与SamplePairing相比降低了8.21。 |
| Learning Visual Features Under Motion Invariance Authors Alessandro Betti, Marco Gori, Stefano Melacci 人类不断暴露于具有自然时间结构的视觉数据流中。然而,大多数成功的计算机视觉算法在图像级别工作,完全丢弃运动携带的宝贵信息。在本文中,我们声称处理视觉流自然导致制定运动不变原理,这使得能够构建源于变分原理的新学习理论,就像在物理学中一样。这种有原则的方法非常适合于对视觉中出现的许多有趣问题进行讨论,并且它为在视网膜上发现卷积滤波器提供了良好的计算方案。与需要大规模监督的传统卷积网络不同,所提出的理论为视频信号的无监督处理提供了真正的新场景,其中特征是在具有运动不变性的多层架构中提取的。虽然该理论能够实现新颖的计算机视觉系统,但它也揭示了基于信息的原则在推动可能的生物解决方案中的作用。 |
| Deep Mesh Reconstruction from Single RGB Images via Topology Modification Networks Authors Junyi Pan, Xiaoguang Han, Weikai Chen, Jiapeng Tang, Kui Jia 由于深度学习技术的最新进展,现在可以从单个图像重建一般对象的3D网格。然而,由于产生可行的网状结构的非常困难,现有技术的方法通常通过学习使其变形到目标表面的模板网格的位移来简化问题。虽然通过使多个网格补片变形可以实现重建具有复杂拓扑的3D形状,但是仍然难以缝合结果以确保高网格质量。在本文中,我们提出了一个端到端的单视图网格重建框架,它能够从单个0模板网格生成具有复杂拓扑的高质量网格。我们的方法的关键是一个新颖的渐进式整形框架,它在网格变形和拓扑修改之间交替。虽然变形网络预测每个顶点平移可以减少重建网格与地面实况之间的差距,但是采用新颖的拓扑修改网络来修剪容易出错的面,从而实现拓扑的演化。通过迭代这两个过程,可以逐步修改网格拓扑,同时实现更高的重建精度。此外,边界细化网络被设计用于细化边界条件以进一步改善重建网格的视觉质量。大量实验表明,我们的方法在质量和数量上都优于现有技术方法,特别是对于具有复杂拓扑结构的形状。 |
| Flow Guided Short-term Trackers with Cascade Detection for Long-term Tracking Authors Han Wu, Xueyuan Yang, Yong Yang, Guizhong Liu 对象跟踪已经研究了几十年,但大多数现有的工作都集中在短期跟踪上。对于长序列,对象经常被完全遮挡或长时间不在视野中,并且现有的短期对象跟踪算法经常失去目标,并且即使再次出现目标也难以重新捕获目标。本文提出了一种新的长期目标跟踪算法流MDNet RPN,在短期目标跟踪算法中增加了跟踪结果判断模块和检测模块。实验表明,所提出的长期跟踪算法对目标消失问题是有效的。 |
| Multiple Object Tracking with Motion and Appearance Cues Authors Weiqiang Li, Jiatong Mu, Guizhong Liu 由于更好的视频质量和更高的帧速率,近年来多目标跟踪问题的性能得到了极大的提高。然而,在实际应用场景中,相机运动和每帧噪声检测结果显着降低了跟踪器的性能。高速和高质量的多物体跟踪器仍然迫切需要。在本文中,我们提出了一种新的多目标跟踪器,遵循流行的跟踪检测方案。我们使用光流网络解决相机运动问题,并利用辅助跟踪器来处理丢失的检测问题。此外,我们同时使用外观和运动信息来提高匹配质量。 VisDrone MOT数据集的实验结果表明,我们的方法可以显着提高多目标跟踪的性能,同时实现高效率。 |
| READ: Recursive Autoencoders for Document Layout Generation Authors Akshay Gadi Patil, Omri Ben Eliezer, Or Perel, Hadar Averbuch Elor 布局是任何图形设计的基本组成部分。创建大量合理的文档布局可能是一项繁琐的任务,需要满足许多约束,包括涉及不同语义元素的局部约束和对一般外观和间距的全局约束。在本文中,我们提出了一个新的框架,创建了READ,用于文档布局生成的递归自动编码器,以生成大量和多种文档的合理2D布局。首先,我们设计一种探索性递归方法来提取单个文档的结构分解。利用带有标记边界框注释的文档数据集,我们的递归神经网络学习将以简单层次结构形式给出的结构表示映射到紧凑代码,其空间用高斯分布近似。可以从该空间采样新的层次结构,从而获得新的文档布局。此外,我们引入了一个组合度量来衡量文档布局之间的结构相似性。我们将其部署以显示我们的方法能够生成高度可变和逼真的布局。我们进一步演示了生成的布局在文档上的标准检测任务的上下文中的实用性,表明当使用READ生成布局的生成文档扩充训练数据时,检测性能会提高。 |
| Second-order Non-local Attention Networks for Person Re-identification Authors Bryan Ning Xia, Yuan Gong, Yizhe Zhang, Christian Poellabauer 最近的努力已经通过设计基于部件的架构以允许神经网络从语义上连贯的部分学习判别性表示而显示出用于人员识别的有希望的结果。一些努力使用软注意力将远距离异常值重新分配给它们最相似的部分,而另一些努力调整部分粒度以结合更远的位置来学习关系。其他人试图通过在特征图的连续区域上引入丢失机制来概括基于部分的方法,以增强远距离区域关系。然而,只有少数先前的努力直接为人员重新ID任务建模特征地图的远程或非本地位置。在本文中,我们提出了一种新的注意机制,通过二阶特征统计直接模拟远程关系。当与广义DropBlock模块结合使用时,我们的方法与主流人员识别数据集(包括Market1501,CUHK03和DukeMTMC reID)的现有技术结果相同或更好。 |
| SSSDET: Simple Short and Shallow Network for Resource Efficient Vehicle Detection in Aerial Scenes Authors Murari Mandal, Manal Shah, Prashant Meena, Santosh Kumar Vipparthi 在许多基于航空视觉的应用中,小尺寸目标的检测至关重要。用于空中场景分析的普遍部署的低成本无人驾驶飞行器UAV在性质上受到高度资源限制。在本文中,我们提出了一个简单的短而浅的网络SSSDet,可以在空中场景中对小型车辆进行鲁棒检测和分类。与现有技术的探测器相比,建议的SSSDet速度提高了4倍,所需FLOP减少了4.4倍,参数减少了30倍,所需内存空间减少了31倍,并提供了更高的精度。因此,它更适合于实时应用中的硬件实现。我们还通过在79个航拍图像中为我们的实验注释了1396个新对象,创建了一个新的机载图像数据集ABD。该方法的有效性在现有的VEDAI,DLR 3K,DOTA和Combined数据集上得到验证。 SSSDet在精度,速度,计算和内存效率方面优于最先进的探测器。 |
| WSLLN: Weakly Supervised Natural Language Localization Networks Authors Mingfei Gao, Larry S. Davis, Richard Socher, Caiming Xiong 我们提出弱监督语言本地化网络WSLLN,以在给定语言查询的情况下检测长的未修剪视频中的事件。为了学习视觉片段和文本之间的对应关系,大多数先前的方法需要时间坐标训练事件的开始和结束时间,这导致注释的高成本。 WSLLN通过仅使用视频句子对进行训练而不访问事件的时间位置来减轻注释负担。通过简单的端到端结构,WSLLN可以测量段文本的一致性,并同时根据文本进行段选择。两者的结果被合并并优化为视频句子匹配问题。 ActivityNet Captions和DiDeMo上的实验证明WSLLN实现了最先进的性能。 |
| UPI-Net: Semantic Contour Detection in Placental Ultrasound Authors Huan Qi, Sally Collins, J. Alison Noble 语义轮廓检测是在医学成像中经常遇到的挑战性问题,其中胎盘图像分析是特定示例。在本文中,我们通过将其作为语义轮廓检测问题进行研究,在2D胎盘超声图像中研究子宫胎盘界面UPI检测。与自然图像相反,胎盘超声图像包含特定的解剖结构,因此具有独特的几何形状。我们认为UPI检测器结合全局上下文建模以减少不必要的误报UPI预测将是有益的。我们的方法,即UPI Net,旨在通过轻量级全局上下文建模和有效的多尺度特征聚合来捕捉胎盘几何中的长程依赖性。我们对胎盘超声数据库进行了主题水平10倍的嵌套交叉验证,其中48个图像具有来自49次扫描的标记的UPI。实验结果表明,与其他竞争基准相比,UPI Net在不引入可观的计算开销的情况下,在标准轮廓检测指标方面具有最高性能。 |
| Push for Quantization: Deep Fisher Hashing Authors Yunqiang Li, Wenjie Pei, Yufei zha, Jan van Gemert 当前大量数据集需要轻量级访问以进行分析。因此,离散散列方法是有益的,因为它们将高维数据映射到有效存储和处理的紧凑二进制代码,同时保留语义相似性。为了优化用于图像散列的强大的深度学习方法,需要基于梯度的方法。然而,二进制码是离散的,因此没有连续的导数。通过在连续空间中解决问题来解决问题然后量化解决方案并不能保证产生可分离的二进制代码。量化需要包含在优化中。在本文中,我们推动量化我们优化二进制空间中的最大类可分性。我们在二进制空间中测量不同图像对之间的距离。除了成对距离之外,我们从Fisher的线性判别分析Fisher LDA中汲取灵感,以最大化类之间的二进制距离,同时最小化同一类中图像的二进制距离。在CIFAR 10,NUS WIDE和ImageNet100上的实验证明了紧凑的代码,与现有技术相比是有利的。 |
| Towards Improving Generalization of Deep Networks via Consistent Normalization Authors Aojun Zhou, Yukun Ma, Yudian Li, Xiaohan Zhang, Ping Luo 批量标准化BN被证明可以加速训练并改进卷积神经网络结构的泛化,这通常使用Conv BN对作为构建块。然而,这项工作显示了一个普遍现象,即Conv BN模块不一定优于不使用BN训练的网络,特别是在训练中提供数据增强时。我们发现这种现象的发生是因为增强数据的分布与规范化表示的分布之间存在不一致。为了解决这个问题,我们提出了一致归一化CN,它不仅保留了现有归一化方法的优点,而且在各种任务上实现了最先进的性能,包括图像分类,分割和机器翻译。代码将被释放以便于再现性。 |
| Boundary-Aware Feature Propagation for Scene Segmentation Authors Henghui Ding, Xudong Jiang, Ai Qun Liu, Nadia Magnenat Thalmann, Gang Wang 在这项工作中,我们解决了场景分割的挑战性问题。为了在保持不同对象的特征辨别的同时增加同一对象的特征相似性,我们探索在对象边界的控制下在整个图像中传播信息。为此,我们首先建议将边界作为一个额外的语义类来学习,以使网络能够意识到边界布局。然后,我们提出单向非循环图UAG来模拟无向循环图UCG的功能,其通过逐像素连接建立图形来结构化图像,以高效且有效的方式。此外,我们提出了边界感知特征传播BFP模块,以收集和传播由UAG结构化图像中的学习边界隔离的区域内的局部特征。所提出的BFP能够通过在相同的片段区域之间建立强连接但在不同片段区域之间建立弱连接来将特征传播分成一组语义组。在没有花里胡哨的情况下,我们的方法在三个具有挑战性的语义分割数据集上实现了新的最先进的分割性能,即PASCAL Context,CamVid和Cityscapes。 |
| Imbalance Problems in Object Detection: A Review Authors Kemal Oksuz, Baris Can Cam, Sinan Kalkan, Emre Akbas 在本文中,我们对目标检测中的不平衡问题进行了全面的回顾。为了系统地分析问题,我们引入了两个分类法,一个用于解决问题,另一个用于提出的解决方案。根据问题的分类,我们深入讨论每个问题,并对文献中的解决方案提出统一而批判的观点。此外,我们还确定了有关现有不平衡问题以及之前未讨论的不平衡问题的主要公开问题。此外,为了使我们的审查保持最新,我们提供了一个随附的网页,根据我们基于问题的分类法对解决不平衡问题的论文进行分类。研究人员可以在这个网页上跟踪更新的研究 |
| Scraping Social Media Photos Posted in Kenya and Elsewhere to Detect and Analyze Food Types Authors Kaihong Wang, Mona Jalal, Sankara Jefferson, Yi Zheng, Elaine O. Nsoesie, Margrit Betke 监测饮食中的人口水平变化可能对教育和实施改善健康的干预措施有用。研究表明,来自社交媒体来源的数据可用于监测饮食行为。我们建议使用位置方法来从Instagram帖子创建食物图像数据集。我们用它在2019年3月的20天内收集了356万张图像。我们还提出了一种关键词方法,并用它来刮掉30种图像及其38种肯尼亚食物类型的标题。我们分别发布了两个104,000和8,174个图像标题对的数据集。利用肯尼亚104K的第一个数据集,我们培训肯尼亚食品分类器KenyanFC,以区分肯尼亚食品和肯尼亚发布的非食品图像。我们使用第二个数据集KenyanFood13来训练肯尼亚食品类型识别器的缩写KenyanFTR,以识别肯尼亚的13种流行食品类型。 KenyanFTR是一种多模态深度神经网络,可以使用图像及其相应的标题识别13种类型的肯尼亚食物。实验表明,KenyanFC的平均前1精度在10,400个测试Instagram图像中为99,而KenyanFTR在8,174个测试数据点上为81。消融研究表明,13种食物类型中的3种特别难以基于图像内容进行分类,并且在图像分析中添加字幕分析产生的分类器比仅依赖于图像的分类器准确度高9%。我们的食物趋势分析显示,蛋糕和烤肉是2019年3月在肯尼亚Instagram上拍摄的最受欢迎的食物。 |
| Object Detection in Optical Remote Sensing Images: A Survey and A New Benchmark Authors Ke Li, Gang Wan, Gong Cheng, Liqiu Meng, Junwei Han 最近致力于提出用于光学遥感图像中的物体检测的各种方法的大量努力。然而,目前关于光学遥感图像中的物体检测的数据集和基于深度学习的方法的调查是不充分的。此外,大多数现有数据集都有一些缺点,例如,图像和对象类别的数量是小规模的,并且图像的多样性和变化是不充分的。这些限制极大地影响了基于深度学习的对象检测方法的发展。在本文中,我们全面回顾了最近在计算机视觉和地球观测社区中基于深度学习的物体检测进展。然后,我们提出了一个大规模,公开可用的光学遥感图像中的物体检测基准,我们称之为DIOR。该数据集包含23463个图像和190288个实例,涵盖20个对象类。建议的DIOR数据集1在对象类别,对象实例编号上是大规模的,并且在总图像编号2上具有大范围的对象尺寸变化,不仅在空间分辨率方面,而且在对象方面由于在不同的成像条件,天气,季节和图像质量下获得图像,并且具有高的类间相似性和类内多样性,因此跨物体3的类内尺寸可变性具有很大的变化。建议的基准可以帮助研究人员开发和验证他们的数据驱动方法。最后,我们评估了DIOR数据集中的几种最先进的方法,以便为将来的研究建立基线。 |
| Detecting floodwater on roadways from image data with handcrafted features and deep transfer learning Authors Cem Sazara, Mecit Cetin, Khan M. Iftekharuddin 检测由于洪水而被淹没的道路段对于车辆路线和交通管理决策具有重要的应用。本文提出了一套算法来自动检测可能存在于手机或其他类型光学相机捕获的图像中的洪水。为此,开发了图像分类和泛滥区域分割方法。对于分类任务,我们使用局部二值模式LBP,Oriented Gradients HOG直方图和预训练深度神经网络VGG 16作为特征提取器,并在提取的特征上训练逻辑回归,k最近邻和决策树分类器。具有逻辑回归分类器的预先训练的VGG 16网络优于所有其他方法。对于洪水区域分割任务,我们研究了基于超像素的方法和完全卷积神经网络FCN。与分类任务类似,我们在超像素区域上训练逻辑回归和k个最近邻分类器,并将其与端到端训练的FCN进行比较。条件随机场CRF方法应用于两种分割方法后后处理粗分割结果。 FCN在所有指标中提供了最高分,其次是基于超像素的逻辑回归,然后是基于超像素的KNN。 |
| A Semantics-Assisted Video Captioning Model Trained with Scheduled Sampling Authors Haoran Chen, Ke Lin, Alexander Maye, Jianming Li, Xiaolin Hu 鉴于视频的特征,可以使用循环神经网络自动生成视频的标题。用于视频字幕的现有方法具有至少三个限制。首先,语义信息已被广泛应用于提高视频字幕模型的性能,但现有网络往往无法提供有意义的语义特征。其次,教师强制算法通常用于优化视频字幕模型,但在训练和推理过程中,应用不同的策略来指导字生成,从而导致性能不佳。第三,当前的视频字幕模型易于产生相对短的字幕,其不恰当地表达视频内容。为了解决这三个问题,我们相应地进行了三项改进。首先,我们利用静态空间特征和动态时空特征作为语义检测网络SDN的输入,以便为视频生成有意义的语义特征。然后,我们提出了一个预定的抽样策略,逐步将培训阶段从教师指导方式转向更自我教学的方式。最后,通过句子长度来利用普通对数概率损失函数,从而减轻短句倾向。我们的模型在Youtube2Text数据集上实现了最先进的结果,并且与MSR VTT数据集上的最新模型竞争。 |
| Towards Learning Affine-Invariant Representations via Data-Efficient CNNs Authors Xenju Xu, Guanghui Wang, Alan Sullivan, Ziming Zhang 在本文中,我们建议将先验知识集成到卷积神经网络CNN的设计和训练中,以学习对仿射变换(即平移,缩放,旋转)不变的对象表示。因此,我们提出了一种新颖的多尺度maxout CNN,并用新颖的旋转不变正则化器端对端地训练它。该正则化器旨在强制每个2D空间滤波器中的权重以近似圆形图案。通过这种方式,我们设法使用卷积,多尺度最大值和圆形滤波器来处理训练中的仿射变换。根据经验,我们证明这些知识可以显着提高数据效率以及学习模型的泛化和稳健性。例如,在交通标志数据集上并且每班只有10个图像训练,我们的方法可以达到84.15,在测试精度方面优于现有技术的29.80。 |
| Energy Clustering for Unsupervised Person Re-identification Authors Kaiwei Zeng 由于人工重新识别Re ID方法的监督学习中数据注释的高成本,无监督学习在现实世界中变得更具吸引力。基于层次聚类的自下而上聚类BUC方法是一种有前途的无监督聚类方法。 BUC的一个关键因素是距离测量策略。理想情况下,距离测量应考虑所有样本的簇间和簇内距离。然而,BUC使用最小距离,仅考虑两个簇之间的一对最近样本并忽略簇中其他样本的多样性。为了解决这个问题,我们建议使用能量距离来评估层次聚类E簇中的簇间距和簇内距离,并使用偏差平方和SSD作为正则项来进一步平衡能量的多样性和相似性。距离评估。我们在大规模重新ID数据集上评估我们的方法,包括Market 1501,DukeMTMC reID和MARS。大量实验表明,我们的方法比现有技术的无监督方法获得了显着的改进,甚至比一些转移学习方法更好。 |
| Deep Plug-and-Play Prior for Parallel MRI Reconstruction Authors Ali Pour Yazdanpanah, Onur Afacan, Simon K. Warfield 磁共振成像MRI中的快速数据采集非常需要,扫描时间直接取决于采集的k空间样本的数量。用于快速MRI采集的常规MRI重建方法主要依赖于代表稀疏度的分析模型的不同正则化器。然而,最近基于深度学习的数据驱动方法已经导致图像重建算法的有希望的改进。在本文中,我们提出了一种深度即插即用的并行MRI重建问题框架,该问题利用深度神经网络DNN作为迭代方法中的高级降噪器。这反过来又能够以改善的图像质量快速获取MR图像。将所提出的方法与使用临床金标准GRAPPA方法的重建进行比较。我们使用欠采样数据的结果表明,与用于MRI重建的临床金标准方法相比,我们的方法可以在高加速因子下提供更高质量的图像。我们提出的重建使得能够增加加速因子,并且在保持高图像质量的同时减少采集时间。 |
| Robust Online Video Super-Resolution Using an Efficient Alternating Projections Scheme Authors Ricardo Augusto Borsoi 视频超分辨率重建SRR算法尝试从低分辨率LR观察重建高分辨率HR视频序列。尽管视频SRR的最近进展已经显着改善了重建的HR序列的质量,但是设计SRR算法仍然具有挑战性,SRR算法在小的计算复杂度下实现了良好的质量和鲁棒性,因此适合于在线应用。在本文中,我们提出了一种新的自适应视频SRR算法,该算法以非常小的计算成本实现了最先进的性能。利用考虑自然图像序列中典型创新异常值特征构造的非线性代价函数和边缘保持正则化策略,实现了最新的重建图像质量和鲁棒性。使用在非凸集上的特定交替投影策略来优化该成本函数,其能够在非常少的迭代中收敛。使用来自多维多速率信号处理的工具也可以获得对投影操作的准确且非常有效的近似。这解决了基于随机梯度的方法的慢收敛问题,同时保持较小的计算复杂度。合成图像和真实图像序列的仿真结果表明,所提算法的性能与现有技术的SRR算法相似或更好,但只需要一小部分计算成本。 |
| Combining Multi-Sequence and Synthetic Images for Improved Segmentation of Late Gadolinium Enhancement Cardiac MRI Authors V ctor M. Campello, Carlos Mart n Isla, Cristian Izquierdo, Steffen E. Petersen, Miguel A. Gonz lez Ballester, Karim Lekadir 在晚期钆增强磁共振图像中准确分割心脏边界LGE MRI是准确量化瘢痕组织的基本步骤。然而,尽管存在许多用于电影图像的自动心脏分割的解决方案,但是瘢痕组织的存在可以使LGE MRI中的心肌的正确描绘具有挑战性,即使对于人类专家也是如此。作为多序列心脏MR分割挑战的一部分,我们提出了基于两个组件的LGE MRI分割解决方案。首先,训练生成对抗网络,用于在电影和LGE MRI序列之间进行模态转换的任务,以获得两种模态的额外合成图像。其次,训练深度学习模型用于使用原始序列,增强序列和合成序列的不同组合进行分割。我们基于来自45名不同患者的三个磁共振序列LGE,bSSFP和T2的结果表明,结合合成图像和数据增强的多序列模型训练在使用真实数据集的传统训练的分割中得到改善。总之,通过使用由非对比MRI序列提供的补充信息,可以提高LGE MRI图像的分割的准确性。 |
| Semantically-Regularized Logic Graph Embeddings Authors Yaqi Xie, Ziwei Xu, Kuldeep Meel, Mohan S Kankanhalli, Harold Soh 在这项工作中,我们的目标是利用编码为逻辑规则的先验知识来提高深度模型的性能。我们提出了一个逻辑图嵌入网络,它通过增强的图形卷积网络GCN将d DNNF公式和赋值投影到流形上。为了生成语义上忠实的嵌入,我们提出了识别节点异质性的技术,以及将结构约束结合到嵌入中的语义正则化。实验表明,我们的方法提高了训练模型执行模型检查和视觉关系预测的模型的性能。 |
| A Tool for Super-Resolving Multimodal Clinical MRI Authors Mikael Brudfors, Yael Balbastre, Parashkev Nachev, John Ashburner 我们提出了一种用于多模式临床磁共振成像MRI中的分辨率恢复的工具。这些图像表现出很大的可变性,包括生物学和仪器学。这种可变性使得利用神经成像分析软件进行自动化处理非常具有挑战性。这使得智能仅可从未开发的临床数据的大规模分析中提取,并且阻碍在临床护理中引入自动化预测系统。本文介绍的工具通过厚切片,多对比度MR扫描的生成模型中的推断实现了这种处理。所有模型参数均根据观察数据估算,无需手动调整。该方法的模型驱动性质意味着不需要任何类型的训练来适用于临床环境中存在的MR对比的多样性。我们在模拟数据上显示,所提出的方法优于传统的基于模型的技术,并且在多模式MRI的大型医院数据集上,该工具可以成功地超分辨出非常厚的切片图像。实施可从 |
| 3DSiameseNet to Analyze Brain MRI Authors Cecilia Ostertag, Marie Beurton Aimar, Thierry Urruty 预测易患发生神经退行性疾病的人的认知进化对于尽快提供适当的治疗至关重要。在本文中,我们提出了一个3D暹罗网络,旨在从全脑3D MRI图像中提取特征。我们表明,使用卷积层可以提取有意义的特征,减少了经典图像处理操作的需要,例如分割或预先计算特征,如皮质厚度。为了领导这项研究,我们使用了阿尔茨海默氏病神经影像学倡议ADNI,这是一个3D MRI脑图像的公共数据库。提取了一组247个受试者,所有受试者在12个月的范围内具有2个图像。为了测量患者状态的演变,我们比较了这两个图像。我们的工作在一开始受到了Bhagwat等人的一篇文章的启发。在2018年,他们提出了一个暹罗网络,以预测病人的状态,但没有任何卷积层,并将MRI图像缩小为从预定义的ROI中提取的特征向量。我们表明,我们的网络在认知能力下降的VS稳定患者的分类中达到了90的准确度。该结果是在没有认知评分的帮助下获得的,并且与在深度学习领域中声称的当前数据集大小相比具有少量患者。 |
| CGC-Net: Cell Graph Convolutional Network for Grading of Colorectal Cancer Histology Images Authors Yanning Zhou, Simon Graham, Navid Alemi Koohbanani, Muhammad Shaban, Pheng Ann Heng, Nasir Rajpoot 结肠直肠癌CRC分级通常通过评估组织学图像内的腺体形成程度来进行。要做到这一点,重要的是通过评估细胞水平信息以及腺体的形态来考虑整个组织微环境。然而,当前用于CRC分级的自动化方法通常利用小图像块,因此不能将整个组织微架构结合用于分级目的。为了克服CRC分级的挑战,我们提出了一种新的细胞图卷积神经网络CGC Net,它将每个大的组织学图像转换成图形,其中每个节点由原始图像中的核表示,细胞相互作用表示为这些之间的边缘。节点根据节点相似性。除了节点的空间位置之外,CGC网还利用核外观特征来进一步提高算法的性能。为了使节点融合多尺度信息,我们引入了自适应GraphSage,这是一种图形卷积技术,它以数据驱动的方式组合多级特征。此外,为了处理图中的冗余,我们提出了一种采样技术,可以去除密集核活动区域中的节点。我们表明,将图像建模为图形使我们能够有效地考虑比传统的基于补丁的方法大16倍的大图像,并模拟组织微环境的复杂结构。我们在大型CRC组织学图像数据集上构建平均超过3,000个节点的细胞图,并报告与最近基于补丁和基于上下文补丁的技术相比的现有技术结果,证明了我们的方法的有效性。 |
| Hyper-Pairing Network for Multi-Phase Pancreatic Ductal Adenocarcinoma Segmentation Authors Yuyin Zhou, Yingwei Li, Zhishuai Zhang, Yan Wang, Angtian Wang, Elliot Fishman, Alan Yuille, Seyoun Park 胰腺导管腺癌PDAC是最致命的癌症之一,总体五年存活率为8。由于PDAC的细微纹理变化,推荐胰腺双相成像以更好地诊断胰腺疾病。在本研究中,我们的目标是通过整合多相信息(即动脉期和静脉期)来增强PDAC自动分割。为此,我们提出了Hyper Pairing Network HPN,这是一个3D完全卷积神经网络,可以有效地整合来自不同阶段的信息。所提出的方法包括双路径网络,其中两个并行流与超连接互连以进行密集的信息交换。另外,添加配对损失以鼓励不同阶段的高级特征表示之间的共性。与使用单相数据的现有技术相比,就DSC而言,HPN报告了从56.21到63.94的显着改进,高达7.73。 |
| miniSAM: A Flexible Factor Graph Non-linear Least Squares Optimization Framework Authors Jing Dong, Zhaoyang Lv 计算机视觉和机器人中的许多问题可以被表述为由因子图表示的非线性最小二乘优化问题,例如,同时定位和映射SLAM,来自运动SfM的结构,运动规划和控制。我们开发了一个开源的C Python框架miniSAM,用于解决基于因子图的最小二乘问题。与大多数现有的最小二乘求解器框架相比,miniSAM有1个完整的Python NumPy API,可以实现更灵活的开发,并且可以轻松地与现有的Python项目绑定,以及2个稀疏线性求解器列表,包括支持CUDA的稀疏线性求解器。我们的基准测试结果显示,miniSAM在各种类型的问题上提供了可比较的性能,具有更灵活和更流畅的开发体验。 |
| Metric Learning for Adversarial Robustness Authors Chengzhi Mao, Ziyuan Zhong, Junfeng Yang, Carl Vondrick, Baishakhi Ray 众所周知,深层网络对敌对攻击很脆弱。使用几个标准图像数据集和已建立的攻击机制,我们对攻击下的深度表示进行了实证分析,发现攻击导致内部表示更接近假类。受此观察的启发,我们建议通过度量学习来规范受攻击的表示空间,以便产生更强大的分类器。通过仔细采样度量学习的示例,我们的学习表示不仅可以提高稳健性,还可以检测以前看不见的对抗性样本。根据基线曲线下面积AUC得分,定量实验表明稳健性准确度提高了4倍,检测效率提高了6倍。 |
| VISIR: Visual and Semantic Image Label Refinement Authors Sreyasi Nag Chowdhury, Niket Tandon, Hakan Ferhatosmanoglu, Gerhard Weikum 社交媒体爆炸在互联网上填充了大量图像。存在两种用于图像检索的范例1基于内容的图像检索CBIR,其传统上使用视觉特征用于相似性搜索,例如SIFT特征,以及2基于标记的图像检索TBIR,其依赖于用户标记,例如Flickr标记。 CBIR现在通过基于深度学习的视觉标签检测的进步获得语义表达。 TBIR受益于查询和点击日志,以自动推断更多信息标签。但是,基于学习的标记仍会产生噪声标签,并且仅限于具体对象,忽略了泛化和抽象。基于点击的标记仅限于出现在图像的文本上下文中或导致单击的查询中的术语。本文通过语义上提炼和扩展基于学习的对象检测所建议的标签来解决上述限制。我们考虑不同对象的标签之间的语义一致性,利用词汇和常识知识,并将标签分配转换为由整数线性程序解决的约束优化问题。实验表明,我们的方法,称为VISIR,提高了LSDA和YOLO等艺术品视觉标签工具的质量。 |
| Kidney tumor segmentation using an ensembling multi-stage deep learning approach. A contribution to the KiTS19 challenge Authors Gianmarco Santini, No mi Moreau, Mathieu Rubeaux 在肾癌治疗的背景下,肾和肾肿瘤特征的精确表征是最重要的,特别是对于需要精确定位待移除组织的肾单位保留手术。对准确和自动划分工具的需求是KiTS19挑战的起源。它旨在通过提供300个CT扫描的特征数据集来加速该领域的研究和开发,以帮助预测和治疗计划。为了应对这一挑战,我们提出了一种基于残余UNet框架的自动,多阶段,2.5D深度学习分割方法。最后添加了一个集合操作,以组合前一阶段的预测结果,减少单个模型之间的差异。我们的神经网络分割算法在90个看不见的测试病例中分别达到肾脏和肾脏肿瘤的平均Dice评分0.96和0.74。获得的结果是有希望的,并且可以通过结合关于定期降低肿瘤分割结果的良性囊肿的先前知识来改进。 |
| Reinforcement Learning-based Automatic Diagnosis of Acute Appendicitis in Abdominal CT Authors Walid Abdullah Al, Il Dong Yun, Kyong Joon Lee 以蠕虫状阑尾疼痛性炎症为特征的急性阑尾炎是最常见的外科急症之一。由于在常规CT视图中观察到的复杂结肠结构中的不清楚的解剖结构,使阑尾局部化是具有挑战性的,导致诊断耗时。卷积神经网络的端到端学习CNN也不太可能有用,因为与腹部CT体积相比,阑尾的尺寸可以忽略不计。由于没有先前的计算方法,我们提出了第一个用于急性阑尾炎诊断的计算机化自动化。在我们的方法中,我们利用部署在下腹部区域的强化学习剂来首先获得阑尾位置以减少用于诊断的搜索空间。然后,我们使用仅在每个体积的小阑尾贴片上训练的CNN获得分类分数,即局部位置周围的局部邻域的急性阑尾炎的可能性。从得到的得分的空间表示,我们最终定义了一个低熵RLE区域来选择最佳诊断得分,这有助于提高即使在高阑尾定位误差情况下也能显示鲁棒性的分类准确性。在我们的319腹部CT体积的实验中,基于RLE的先前定位决策显示出比基于CNN的标准诊断方法显着改善。 |
| Resource Optimized Neural Architecture Search for 3D Medical Image Segmentation Authors Woong Bae, Seungho Lee, Yeha Lee, Beomhee Park, Minki Chung, Kyu Hwan Jung 神经架构搜索NAS是一个自动完成神经网络设计任务的框架,最近在深度学习领域得到了积极的研究。然而,只有少数NAS方法适用于3D医学图像分割。医学3D图像通常非常大,因此由于其GPU计算负担和长训练时间而难以应用先前的NAS方法。我们提出了资源优化的神经网络搜索方法,该方法可以在1GB数据集的短时间训练时间内应用于3D医学分割任务,使用少量计算能力一个RTX 2080Ti,10.8GB GPU内存。如果不重新训练微调,也可以实现优异的性能,这在大多数NAS方法中是必不可少的。这些优点可以通过使用基于强化学习的控制器和参数共享来实现,并且关注于宏搜索而不是微搜索的最佳搜索空间配置。我们的实验表明,所提出的NAS方法在3D医学图像分割中具有最先进的性能,优于手动设计的网络。 |
| A Semi-Automated Usability Evaluation Framework for Interactive Image Segmentation Systems Authors Mario Amrehn, Stefan Steidl, Reinier Kortekaas, Maddalena Strumia, Markus Weingarten, Markus Kowarschik, Andreas Maier 对于复杂的分段任务,全自动系统的可实现精度本身就是有限的。具体地,当需要针对少量给定数据集的精确分割结果时,半自动方法对用户表现出明显的益处。人机交互的优化HCI是交互式图像分割的重要组成部分。然而,引入新型交互式分割系统ISS的出版物往往缺乏对人机交互方面的客观比较。已经证明,即使在整个交互式原型中基础分割算法相同时,它们的用户体验也可能发生很大变化。因此,用户更喜欢简单的界面以及相当程度的自由度来控制分段的每个迭代步骤。在本文中,基于广泛的用户研究,提出了一种比较ISS的客观方法。通过抽象参与者给出的视觉和语言反馈来进行总结性定性内容分析。用户通过系统可用性量表SUS和AttrakDiff 2问卷执行对分段系统的直接评估。此外,引入了关于这些研究中可用性方面的发现的近似,仅在系统可测量的用户动作中使用交互式分割原型。所有问卷调查结果的预测平均相对误差为8.9,接近问卷调查结果本身的预期精确度。该自动评估方案可以显着减少调查原型用户界面UI特征和分割方法的每个变化所需的资源。 |
| DeepHealth: Deep Learning for Health Informatics Authors Gloria Hyun Jung Kwak, Pan Hui 机器学习和深度学习为我们提供了一个全新研究时代的探索。随着更多数据和更好的计算能力的出现,它们已经在各个领域得到实施。健康信息学领域对人工智能的需求也在增加,我们可以期待看到人工智能应用在医疗保健领域的潜在好处。深度学习可以帮助临床医生诊断疾病,识别癌症部位,确定每位患者的药物效应,了解基因型和表型之间的关系,探索新的表型,并高精度地预测传染病爆发。与传统模型相比,它的方法不需要特定领域的数据预处理,并且预计它将在未来最终改变人类生活。尽管具有显着优势,但在数据高维度,异构性,时间依赖性,稀疏性,不规则性,缺乏标签和模型可靠性,可解释性,可行性,安全性,实际使用的可扩展性方面存在一些挑战。本文综述了应用深度学习在健康信息学中的研究,重点关注过去五年在医学成像,电子健康记录,基因组学,传感和在线通信健康领域的研究,以及挑战和有希望的方向。未来的研究。我们强调正在进行的流行方法研究,并确定构建深度学习模型的若干挑战 |
| Deep Learning Algorithms to Isolate and Quantify the Structures of the Anterior Segment in Optical Coherence Tomography Images Authors Tan Hung Pham, Sripad Krishna Devalla, Aloysius Ang, Soh Zhi Da, Alexandre H. Thiery, Craig Boote, Ching Yu Cheng, Victor Koh, Michael J. A. Girard 使用光学相干断层扫描OCT图像精确分离和量化眼前段AS中的眼内尺寸对于许多眼病,尤其是闭角型青光眼的诊断和治疗是重要的。在这项研究中,我们开发了深度卷积神经网络DCNN用于巩膜骨刺的定位,以及前段结构虹膜,角膜巩膜壳,前房的分割。在训练数据有限的情况下,DCNN能够像有经验的眼科医生一样准确地检测到看不见的ASOCT图像上的巩膜刺,并同时隔离前段结构,骰子系数为95.7。然后,我们自动提取了八个临床相关的ASOCT参数,并提出了一个自动质量检查流程,该流程可以确定这些参数的可靠性。当与能够成像多个径向截面的OCT机器组合时,算法可以提供更完整的客观评估。这是为ASOCT扫描的可靠量化提供强大的自动化框架的必要步骤,用于角闭合性青光眼的诊断和管理。 |
| WhiteNet: Phishing Website Detection by Visual Whitelists Authors Sahar Abdelnabi, Katharina Krombholz, Mario Fritz 旨在通过声称虚假身份和冒充属于可信赖网站的视觉资料窃取用户信息的网络钓鱼网站仍然是当今互联网线程的主要威胁。因此,在网络钓鱼检测文献中经常使用检测与一组列入白名单的合法网站的视觉相似性。尽管以前做了很多努力,但这些方法要么在具有严重限制的数据集上进行评估,要么假设目标合法网页的密切副本,这使得它们很容易被绕过。本文提供了一种新的基于相似性的网络钓鱼检测框架WhiteNet,即具有三个共享卷积神经网络CNN的三元组网络。我们还提供了WhitePhish,一个改进的数据集,以生态有效的方式评估WhiteNet和其他框架。 WhiteNet学习网站的配置文件,以便检测零日钓鱼网站,并在合法与网络钓鱼二进制分类的ROC曲线下达到0.9879的面积,该曲线优于重新实施的现有技术方法。 WhitePhish是基于白名单源和数据集特征的深入分析的扩展数据集。 |
| Automatic Detection of Bowel Disease with Residual Networks Authors Robert Holland, Uday Patel, Phillip Lung, Elisa Chotzoglou, Bernhard Kainz 克罗恩病是IBD的两种炎症性肠病之一,仅在英国就影响了20万人,或大约每500人中就有一人。我们探讨了深度学习算法在磁共振成像中识别终末回肠克罗恩病的可行性。小数据集。我们证明它们提供了与当前临床标准MaRIA评分相当的性能,同时只需要准备和推理时间的一小部分。此外,由于复杂且自由移动的解剖结构,肠在个体之间受到高度变化。因此,我们还探讨了手头分类难度对性能的影响。最后,我们采用软注意机制来放大显着的局部特征并增加可解释性。 |
| Fetal Ultrasound Image Segmentation for Measuring Biometric Parameters Using Multi-Task Deep Learning Authors Zahra Sobhaninia, Shima Rafiei, Ali Emami, Nader Karimi, Kayvan Najarian, Shadrokh Samavi, S.M.Reza Soroushmehr 超声成像是妊娠期间的标准检查,可用于测量产前诊断和估计孕龄的特定生物特征参数。胎儿头围HC是决定胎儿生长和健康的重要因素之一。本文提出了一种多任务深度卷积神经网络,通过最小化由分割骰子得分和椭圆参数MSE组成的复合成本函数,对HC椭圆进行自动分割和估计。妊娠不同孕期胎儿超声数据集的实验结果表明,分割结果和提取的HC与放射科医师注释吻合良好。所获得的胎儿头部分割的骰子得分和HC评估的准确性与现有技术相当。 |
| Gland Segmentation in Histopathology Images Using Deep Networks and Handcrafted Features Authors Safiyeh Rezaei, Ali Emami, Hamidreza Zarrabi, Shima Rafiei, Kayvan Najarian, Nader Karimi, Shadrokh Samavi, S.M.Reza Soroushmehr 组织病理学图像包含癌症疾病的医学诊断和预后的基本信息。组织病理学图像中腺体的分割是分析和诊断不健康患者的主要步骤。由于深度神经网络在智能医学诊断和组织病理学中的广泛应用和巨大成功,我们提出了用于腺体分割和恶性病例识别的LinkNet的修改版本。我们展示了使用特定的手工制作功能,如不变的本地二进制模式,大大提高了系统性能。实验结果证明了所提出的系统对现有技术方法的能力。我们在测试Warwick QU数据集的B部分图像时获得了最佳结果,并在A部分图像上获得了可比较的结果。 |
| Integrating Data and Image Domain Deep Learning for Limited Angle Tomography using Consensus Equilibrium Authors Muhammad Usman Ghani, W. Clem Karl 计算机断层扫描CT是一种非侵入性成像模式,应用范围从医疗保健到安全。它使用以不同角度收集的投影数据的集合来重建对象的横截面图像。诸如FBP的传统方法要求在整个角度范围内均匀地获取投影数据。在某些应用中,无法获取此类数据。安全性是一种这样的领域,其中正在开发违反完整数据假设的非旋转扫描配置。传统方法从填充有伪像的数据产生图像。最近深度学习DL方法的成功激发了研究人员使用深度神经网络DNN对这些载有神器的图像进行后期处理。这种方法在真正的CT问题上取得了有限的成功。另一种方法是使用DNN预处理不完整的数据,目的是避免完全产生伪像。由于学习过程中的不完善,这种方法仍然可以留下可察觉的残留伪像。在这项工作中,我们的目标是通过基于共识均衡CE框架的两步过程,在数据和图像领域中结合深度学习的力量。具体而言,我们在数据和图像域中使用条件生成对抗网络cGAN来提高性能和有效计算,并通过共识过程将它们组合在一起。我们证明了我们的方法在真实安全CT数据集上的有效性,以应对具有挑战性的90度有限角度问题。相同的框架可以应用于电子显微镜,非破坏性评估和医学成像等应用中出现的其他有限数据问题。 |
| Robust BGA Void Detection Using Multi Directional Scan Algorithms Authors Vikas Ahuja, Vijay Kumar Neeluru 电子电路板的使用寿命受到焊球中存在的空隙的影响。通过检测和测量空隙来对焊球进行质量检查对于改善电子电路中的电路板良率问题是很重要的。通常,基于2D或3D X射线图像手动执行检查。对于高质量检查,难以通过手动检查以高重复性精确地检测和测量空隙,并且这是耗时的过程。需要高质量和快速检查,提出了各种用于空洞检测的方法。但是,在处理各种挑战时缺乏稳健性,例如过孔,电镀或过孔反射,光线不一致,噪声,人工制品等空隙,各种空隙形状,低分辨率图像以及各种设备的可扩展性。强大的BGA空洞检测成为非常困难的问题,特别是如果图像尺寸非常小,例如大约40x40,并且空隙和BGA背景之间的低对比度表示大约7个强度等级,等级为255。在这项工作中,我们提出了基于多方向扫描的空洞检测的新方法。所提出的方法能够分割用于低分辨率图像的空隙,并且可以容易地缩放到各种电子制造产品。 |
| Joint Segmentation and Landmark Localization of Fetal Femur in Ultrasound Volumes Authors Xu Wang, Xin Yang, Haoran Dou, Shengli Li, Pheng Ann Heng, Dong Ni 体积超声在促进产前检查方面具有很大的潜力。非常需要自动化解决方案来高效且有效地分析大量卷。分割和标志性定位是在临床上对产前超声量进行定量评估的两种关键技术。然而,当考虑到较差的图像质量,边界模糊度和体积超声的解剖变化时,这两项任务都是微不足道的。在本文中,我们提出了一个有效的框架,用于产前超声波卷中的同步分割和标志性定位。所提出的框架具有两个分支,其中分段和地标定位的信息提示可以双向传播以使两个任务受益。由于地标定位倾向于遭受误报,我们提出基于距离的损失来抑制噪声,从而增强定位图,进而增强分割。最后,我们进一步利用对抗模块来强调分割与地标定位之间的对应关系。在胎儿股骨的体积超声数据集上进行了广泛验证,我们提出的框架被证明是一种有前途的解决方案,可以促进产前超声波体积的解释。 |
| Bi-Directional ConvLSTM U-Net with Densley Connected Convolutions Authors Reza Azad, Maryam Asadi Aghbolaghi, Mahmood Fathy, Sergio Escalera 近年来,基于深度学习的网络已经实现了医学图像分割中的最新技术性能。在现有网络中,U Net已成功应用于医学图像分割。在本文中,我们提出了U Net,Bi Direction ConvLSTM U Net与密集连接卷积BCDU Net的扩展,用于医学图像分割,其中我们充分利用U Net,双向ConvLSTM BConvLSTM和密集卷积机制。我们使用BConvLSTM以非线性方式组合从相应编码路径和先前解码卷积层提取的特征映射,而不是U Net的跳过连接中的简单串联。为了加强特征传播并鼓励特征重用,我们在编码路径的最后一个卷积层中使用密集连接的卷积。最后,我们可以通过采用批量归一化BN来加速所提出的网络的收敛速度。所提出的模型在视网膜血管分割,皮肤病变分割和肺结节分割的三个数据集上进行评估,从而实现最先进的性能。 |
| HM-NAS: Efficient Neural Architecture Search via Hierarchical Masking Authors Shen Yan, Biyi Fang, Faen Zhang, Yu Zheng, Xiao Zeng, Hui Xu, Mi Zhang 在设计神经网络架构时,自动方法(通常称为神经架构搜索NAS)的使用最近引起了相当多的关注。在这项工作中,我们提出了一种有效的NAS方法,名为HM NAS,它推广了现有的基于权重共享的NAS方法。现有的基于权重共享的NAS方法仍然采用手工设计的启发式方法来生成架构候选者。因此,架构候选者的空间被约束在所有可能架构的子集中,使得架构搜索结果次优。 HM NAS通过两项创新解决了这一局限。首先,HM NAS采用多级架构编码方案,以便搜索更灵活的网络架构。其次,它丢弃了手工设计的启发式算法,并采用了分层掩蔽方案,可自动学习并确定最佳架构。与基于现有技术的基于权重分享的方法相比,HM NAS能够实现更好的架构搜索性能和竞争性模型评估准确性。如果没有手工设计的启发式约束,我们搜索到的网络包含更灵活,更有意义的架构,现有的基于权重分享的NAS方法无法发现 |
| From perception to control: an autonomous driving system for a formula student driverless car Authors Tairan Chen, Zirui Li, Yiting He, Zewen Xu, Zhe Yan, Huiqian Li 本文介绍了Smart Shark II的自主系统,该系统于2018年赢得了中国学生自主FSAC比赛。在本次比赛中,自主赛车需要自主完成两圈未知赛道。在本文中,作者介绍了该赛车的自动驾驶软件结构,确保了高车速和安全性。关键部件确保赛车的稳定驾驶,基于LiDAR和基于视觉的锥体检测提供冗余感知,基于EKF的定位提供高精度和高频状态估计感知结果通过占用网格图在时间和空间中累积。在获得轨迹之后,使用模型预测控制算法来优化赛车的纵向和横向控制。最后,显示了基于真实世界数据的实验性能。 |
| Animated Stickies: Fast Video Projection Mapping onto a Markerless Plane through a Direct Closed-Loop Alignment Authors Shingo Kagami, Koichi Hashimoto 本文介绍了一种快速投影映射方法,用于使用低延迟数字微镜器件DMD投影仪将投影到无标记平面上的运动图像内容。通过采用闭环对准方法,其中不仅表面纹理而且通过相机跟踪投影图像,所提出的方法没有相机和投影仪之间的校准或位置调整。我们设计了基准图案,以插入DMD投影仪的二进制帧的快速拍打序列中,这允许同时跟踪表面纹理和与相机捕获的单个图像分开的基准几何图形。在CPU上实现的建议方法以400 fps运行,并且可以将任意视频内容粘贴到各种纹理表面上。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com