【AI视野·今日CV 计算机视觉论文速览 第170期】Mon, 25 Nov 2019
AI视野·今日CS.CV 计算机视觉论文速览
Mon, 25 Nov 2019
Totally 46 papers
上期速览✈更多精彩请移步主页

Interesting:
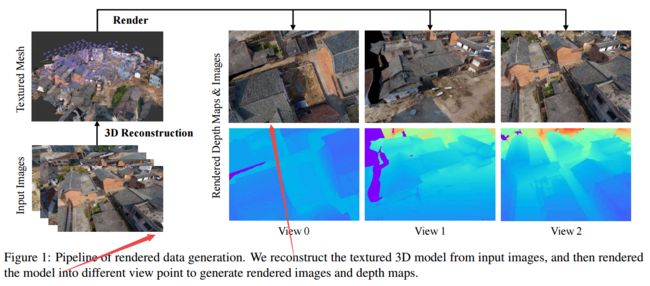
*****BlendedMVS大规模多视角三维重建的基准数据集和通用方法, 规范化了三维重建流程,从图像到mesh的过程,包括深度图与rgb的渲染,与输入图的结合。数据集中包含了17k的高分辨率场景图(from 港中文 珠科创新Altizure 浙大)
与类似数据集的比较结果:
code:https://github.com/YoYo000/BlendedMVS
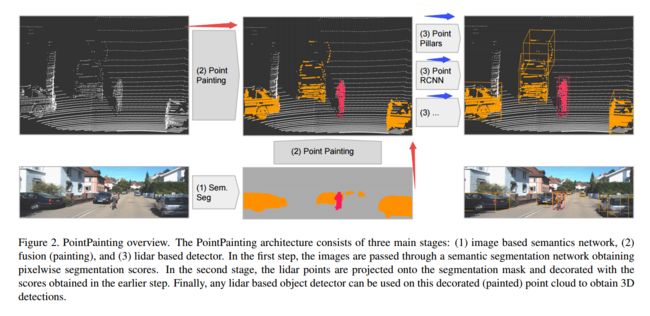
****PointPainting将图像分割结果painting到点云上增加信息, 提出了一种将RGB的实例分割与激光雷达点云想融合进行三维检测的方法,通过将激光雷达点投影在图像分割结果上,为每个点附加分类分数。被append分数的点云随后被送入点云处理方法来进行检测,大幅提高了性能。(from nuTonomy)
company ref:https://www.aptiv.com/autonomous-mobility
****合成与真实,在可控噪声下的深度学习研究, 系统充分地研究了深度神经网络在真实和合成噪声上的性能,发现深度网络在真实噪声下具有更好的泛化性、在真实数据上不会一开始就学习模式;如果进行调优ImageNet架构可以很好地泛化到噪声数据上;真实世界的数据噪声危害很小、鲁棒模型改进空间小,如果在合成数据上表现好并不意味着在真实数据上表现好。(from 谷歌)
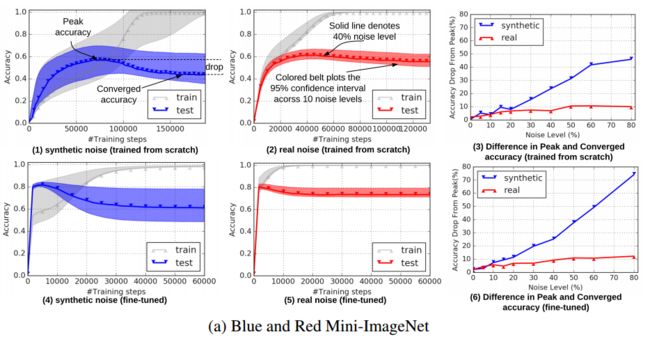
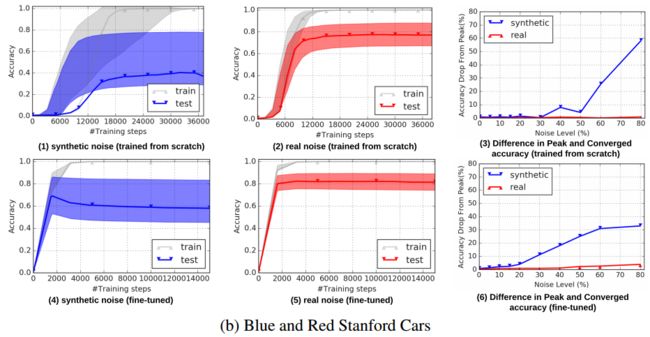
注作图值得借鉴:fig2-4
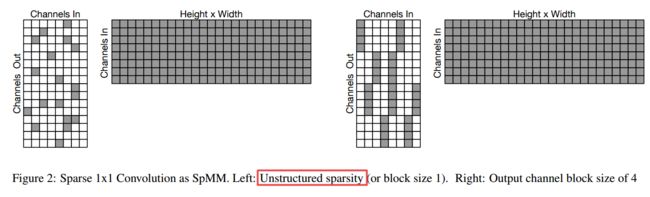
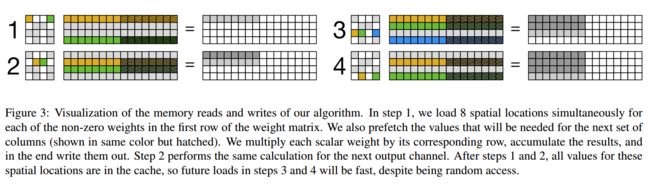
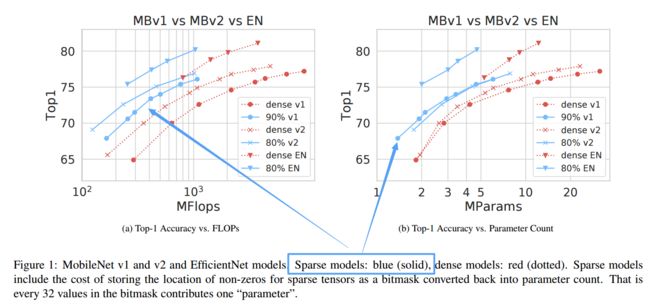
****Fast Sparse ConvNets快速稀疏卷积网络, 近年来为了提高网络的推理速度,人么提出了包括压缩激活模块16,深度可分离方法4和mobilenet中的逆模块。为了进一步拓展,研究人员通过稀疏的卷积操作替代原有稠密操作方法,引入了一系列高效的稀疏卷积核提高了精度和速度。(from 谷歌 deepmind)
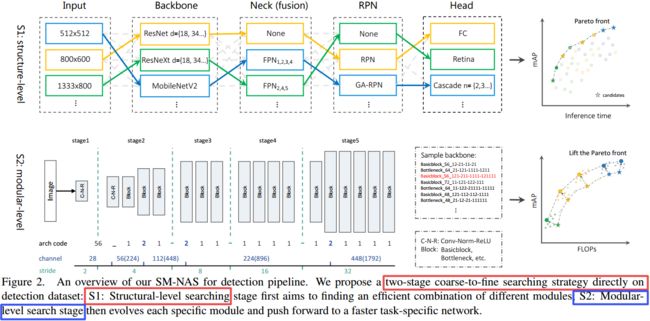
***SM-NAS从结构到模块的分级神经架构搜索用于目标检测, (from 华为诺亚实验室 中山大学)
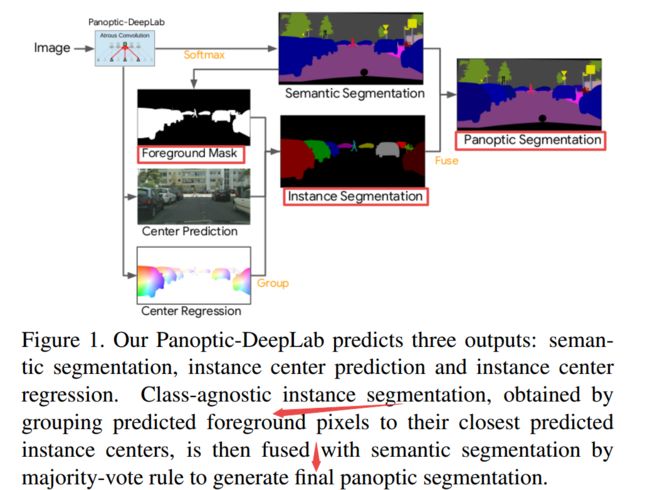
****Panoptic-DeepLab自底向上的全景分割方法, 通过Panoptic-DeepLab预测三个输出,包括语义分割、实例中心预测和实例中心回归。通过用的前景实例分分割与语义分割融合得到最终的全景分割结果。(from google,UIUC)
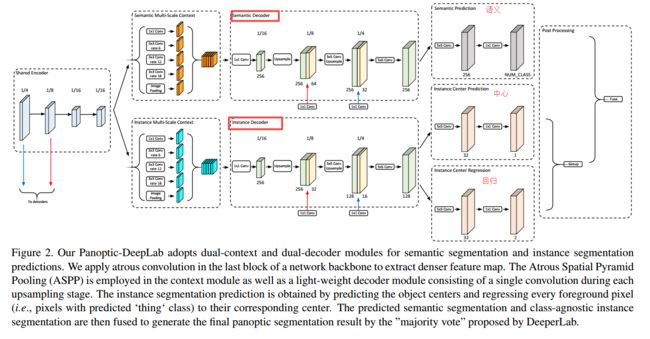
模型架构如下图所示,分为语义编码和实例结构编码两部分,输出三个结果,并进行融合:
三种不同的HRNet架构模型:


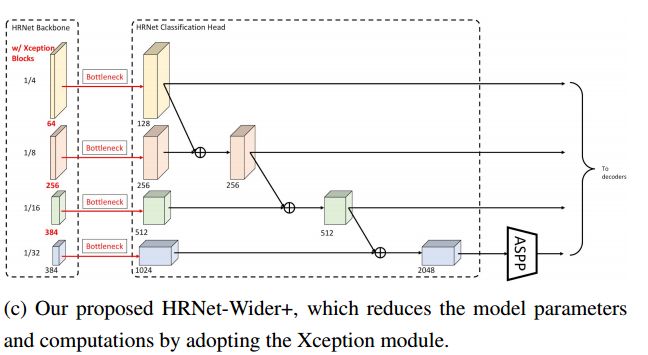
ref: AUNet
SelfVIO视觉惯导里程计和深度估计方法, (from 牛津)

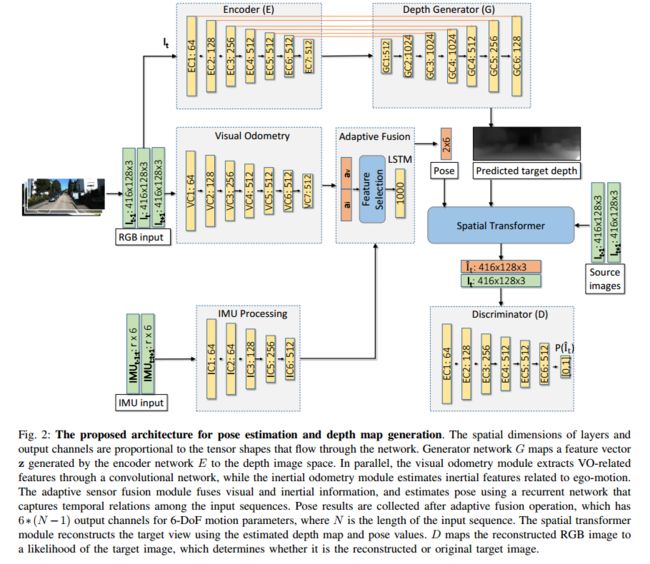
DLGAN解耦图像标签表示的细粒度特征用于图像操作, (from 北大)

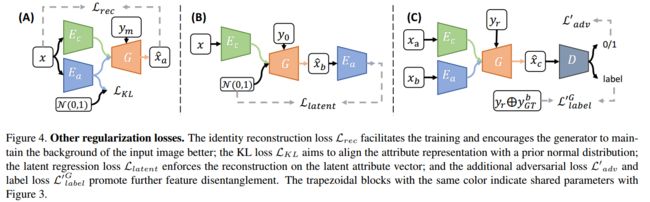
无监督方法进行表面反射和阴影分解的Intrinsic image decomposition

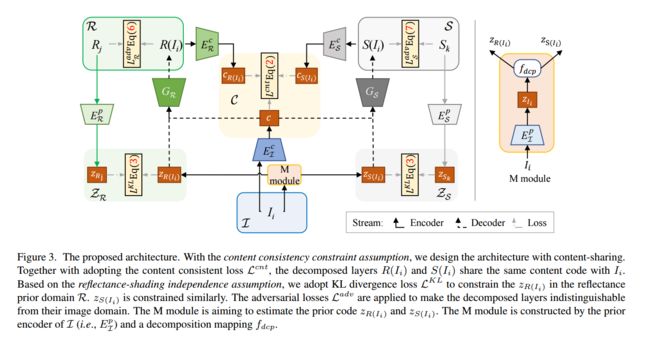

稠密立体视觉匹配方法SGM
星系参数估计
深度学习进行艺术鉴赏
作图值得借鉴fig14-17:
计算机视觉辅助的交通事故检测
Daily Computer Vision Papers
| Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation Authors Bowen Cheng, Maxwell D. Collins, Yukun Zhu, Ting Liu, Thomas S. Huang, Hartwig Adam, Liang Chieh Chen 在这项工作中,我们介绍了Panoptic DeepLab,这是一个简单,强大且快速的全景分割系统,旨在为自下而上方法建立坚实的基线,该方法可以实现两阶段方法的可比性能,同时又能产生快速的推理速度。特别地,PanopticDeepLab分别采用特定于语义和实例分段的双重ASPP和双重解码器结构。语义分割分支与任何语义分割模型(例如DeepLab)的典型设计相同,而实例分割分支与类无关,涉及简单的实例中心回归。结果,我们的单个Panoptic DeepLab同时在所有三个Cityscapes基准测试中排名第一,在测试集上设定了84.2 mIoU,39.0 AP和65.5 PQ的新技术水平。此外,配备了MobileNetV3的Panoptic DeepLab几乎可以实时运行,以每秒1025 x 2049的图像每秒15.8帧的速度运行,同时在测试集的Cityscapes 54.1 PQ上具有竞争优势。在Mapillary Vistas测试台上,我们的六个模型合计达到42.7 PQ,在2018年的挑战者中以1.5的健康利润领先于挑战者。最后,我们的Panoptic DeepLab还可以与具有挑战性的COCO数据集上的几种自上而下的方法媲美。我们首次展示了一种自下而上的方法可以在全景分割方面提供最先进的结果。 |
| PointPainting: Sequential Fusion for 3D Object Detection Authors Sourabh Vora, Alex H. Lang, Bassam Helou, Oscar Beijbom 相机和激光雷达是一般机器人,尤其是自动驾驶汽车中重要的传感器形式。传感器提供补充信息,为紧密的传感器融合提供了机会。出人意料的是,仅激光雷达方法在主要基准数据集上的性能优于融合方法,这表明文献中存在空白。在这项工作中,我们提出了PointPainting顺序融合方法来填补这一空白。 PointPainting的工作原理是将激光雷达点投影到仅图像语义分割网络的输出中,并将类分数附加到每个点。然后可以将附加的绘制的点云馈送到任何仅激光雷达的方法。实验显示,在KITTI和nuScenes数据集上,对三种不同的现有方法(点RCNN,VoxelNet和PointPillars)进行了重大改进。 PointRCNN的彩绘版本代表了KITTI排行榜上的最新技术水平,可鸟瞰鸟瞰任务。在消融中,我们研究绘画的效果如何取决于语义分段输出的质量和格式,并演示如何通过流水线将等待时间最小化。 |
| Learnable Pooling in Graph Convolution Networks for Brain Surface Analysis Authors Karthik Gopinath, Christian Desrosiers, Herve Lombaert 脑表面分析对于神经科学至关重要,但是,大脑皮层的复杂几何形状阻碍了该任务的计算方法。困难来自于以欧几里得空间表示的3D成像数据与高度回旋的大脑表面的非欧几里得几何形状之间的差异。机器学习的最新进展已使神经网络可用于非欧几里得空间。这些促进了表面数据的学习,但是合并策略通常仍然局限于单个固定图形。本文提出了一种新的可学习图池化方法,用于处理多个表面值数据以输出基于主题的信息。该方法是通过学习基于图谱嵌入的图节点的固有聚合而进行创新的。我们通过在两个大型基准数据集上进行的深入实验来说明我们的方法的优势。合并策略的灵活性在四个不同的预测任务上进行了评估,即受试者性别分类,皮层区域大小的回归,阿尔茨海默氏病阶段的分类以及脑年龄的回归。我们的实验证明,与其他用于图卷积网络的合并技术相比,我们可学习的合并方法具有优越性,其结果改善了脑表面分析技术的发展水平。 |
| BlendedMVS: A Large-scale Dataset for Generalized Multi-view Stereo Networks Authors Yao Yao, Zixin Luo, Shiwei Li, Jingyang Zhang, Yufan Ren, Lei Zhou, Tian Fang, Long Quan 尽管深度学习最近在多视图立体MVS上取得了巨大的成功,但有限的训练数据使训练后的模型很难推广到看不见的场景。与其他计算机视觉任务相比,要收集大规模的MVS数据集相当困难,因为它需要昂贵的主动扫描仪和劳动密集型过程才能获得地面真实3D结构。在本文中,我们介绍了BlendedMVS,这是一个新颖的大规模数据集,可为基于学习的MVS提供足够的训练基础。为了创建数据集,我们应用了3D重建管线以从精选场景的图像中恢复高质量的纹理网格。然后,我们将这些网格模型渲染为彩色图像和深度图。将渲染的彩色图像进一步与输入图像融合,以生成照片逼真的融合图像作为训练输入。我们的数据集包含超过17k的高分辨率图像,涵盖各种场景,包括城市,建筑,雕塑和小物体。大量实验表明,与其他MVS数据集相比,BlendedMVS使训练后的模型具有明显更好的泛化能力。带有预训练模型的整个数据集将在以下位置公开提供 |
| Learning End-To-End Scene Flow by Distilling Single Tasks Knowledge Authors Filippo Aleotti, Matteo Poggi, Fabio Tosi, Stefano Mattoccia 场景流是一项具有挑战性的任务,旨在共同估计感测环境的3D结构和运动。尽管深度学习解决方案在准确性方面取得了出色的性能,但是这些方法将整个问题分为独立的任务立体声和光流,并通过独立的网络解决。这种策略极大地增加了训练过程的复杂性,并且需要耗电的GPU才能以1 FPS的速度推断场景流。相反,我们提出了DWARF,这是一种新颖的轻量级体系结构,能够共同推断整个场景流,从而轻松轻松地从头到尾地推理深度和光流。此外,由于缺乏用于整个场景流的地面真相图像,因此我们建议利用专门用于立体声或流的网络学到的知识来提取代理注解,这些知识可用于更多的数据。详尽的实验表明,i DWARF在单个高端GPU上以大约10 FPS的速度运行,在以KITTI分辨率嵌入的NVIDIA Jetson TX2上以1 FPS的速度运行,与深度10倍的模型相比,准确性有所下降,ii从许多蒸馏样本中学习更为有效而不是少数可用的带注释的。可用的代码 |
| Computer Vision-based Accident Detection in Traffic Surveillance Authors Earnest Paul Ijjina, Dhananjai Chand, Savyasachi Gupta, Goutham K 通过视频监视进行基于计算机视觉的事故检测已经成为一项有益而艰巨的任务。本文提出了一种新型的道路交通事故检测框架。所提出的框架利用Mask R CNN进行精确的目标检测,然后是基于有效质心的监控镜头目标跟踪算法。根据与其他车辆重叠后车辆中的速度和轨迹异常来确定发生事故的可能性。所提出的框架提供了一种鲁棒的方法,可以在一般道路交通CCTV监控录像上实现高检测率和低误报率。使用提议的数据集,在各种条件下(例如,日光充足,能见度低,下雨,冰雹和下雪)对该框架进行了评估。发现该框架有效,为实时开发通用车辆事故检测算法铺平了道路。 |
| Domain Adaptation for Object Detection via Style Consistency Authors Adrian Lopez Rodriguez, Krystian Mikolajczyk 我们提出了一种用于对象检测的领域自适应方法。我们介绍了一种两步法,第一步使检测器对低电平差具有鲁棒性,而第二步使分类器适应高级特征的变化。第一步,我们使用样式转换方法将源图像像素调整到目标域。我们发现,在样式转换的图像和源图像之间的对象检测器的高级功能中强制执行较小的距离可以改善目标域中的性能。对于第二步,我们提出了一种鲁棒的伪标记方法,以减少正采样和负采样中的噪声。使用PASCAL VOC上的检测器SSD300进行了实验评估,扩展了在 |
| Spotting insects from satellites: modeling the presence of Culicoides imicola through Deep CNNs Authors Stefano Vincenzi, Angelo Porrello, Pietro Buzzega, Annamaria Conte, Carla Ippoliti, Luca Candeloro, Alessio Di Lorenzo, Andrea Capobianco Dondona, Simone Calderara 如今,媒介传染病VBD对公共健康构成了严重威胁,造成了相当数量的人类疾病。最近,已经制定了一些监视计划来限制此类疾病的传播,通常涉及现场测量。由于实施该计划需要付出高昂的成本和精力,因此仍然缺少这种系统有效的计划。理想地,在该领域中的任何尝试都应考虑三角形载体携带病原体,该病原体与环境和气候条件紧密相关。在本文中,我们利用Sentinel 2任务中的卫星图像,因为我们相信它们会编码造成矢量传播的环境因素。我们以数据驱动程序的方式进行的分析将光谱图像与地面真相信息结合在一起,得出关于库里科米斯·伊米科拉的大量信息。在这方面,我们将我们的任务构造为二进制分类问题,从而支持卷积神经网络CNN能够从多波段图像中学习有用的表示形式。此外,我们提供了一个多实例变体,旨在从短频谱图像序列中提取时间模式。实验显示出令人鼓舞的结果,为新颖的支持工具奠定了基础,这些工具可以说明可以优先考虑监视和预防措施的地方。 |
| Locality Constraint Dictionary Learning with Support Vector for Pattern Classification Authors He Feng Yin, Xiao Jun Wu, Su Gen Chen 区分词典学习DDL由于其在各种模式分类任务中的出色表现而受到了广泛的关注。但是,在传统的DDL方法中,原子的位置没有得到充分的探索,这妨碍了它们的分类性能。在本文中,我们提出了一种带有支持向量判别式LCDL SV的局部性约束字典学习方法,其中利用所学字典的图拉普拉斯矩阵来保留局部性信息。为了在训练阶段共同学习分类器,将支持向量区分项合并到建议的目标函数中。此外,在分类阶段,测试数据的身份由正则残差和学习的多类支持向量机共同确定。最后,利用替代策略解决了由此产生的优化问题。在基准数据库上的实验结果证明了我们提出的方法在手工和深度功能上均优于以前的词典学习方法。我们提议的LCDL SV的源代码可在以下位置访问: |
| Orderless Recurrent Models for Multi-label Classification Authors Vacit Oguz Yazici, Abel Gonzalez Garcia, Arnau Ramisa, Bartlomiej Twardowski, Joost van de Weijer 递归神经网络RNN在许多计算机视觉任务(包括多标签分类)中很流行。由于RNN产生顺序输出,因此需要为多标签分类任务订购标签。当前方法根据标签的频率对标签进行排序,通常以稀有优先或频繁优先的顺序对其进行排序。这些强加的排序没有考虑到生成标签的自然顺序可以针对每个图像而改变,例如,首先是主要对象,然后对图像中的较小对象求和。因此,在本文中,我们提出了利用预测的标签序列动态排序地面真相标签的方法。这样可以更快地训练更多最佳LSTM模型以进行多标签分类。分析表明,我们的方法不会产生重复生成,这在其他模型中很常见。此外,它的表现优于其他CNN RNN模型,并且我们证明了采用我们建议的损失进行训练的图像编码器和语言解码器的标准体系结构在具有挑战性的MS COCO,WIDER属性和PA 100K方面获得了最新的技术成果,并且在NUS WIDE。 |
| Characterizing the impact of using features extracted from pre-trained models on the quality of video captioning sequence-to-sequence models Authors Menatallh Hammad, May Hammad, Mohamed Elshenawy 视频字幕的任务,即自动生成描述视频中一系列动作的句子,最近引起了越来越多的关注。视频数据的复杂和高维表示使得典型的编码器解码器体系结构难以识别相关特征并以适当格式对其进行编码。视频数据包含可以使用混合图像,场景,动作和音频功能识别的不同模式。在本文中,我们描述了影响视频描述的不同功能,并探讨了这些功能之间的相互作用以及它们如何影响视频表示的最终质量。在现有的利用有限视频信息范围的编码器-解码器模型的基础上,我们的比较表明,包含多模式视频功能如何对提高所生成语句的质量产生重大影响。这项工作对正在使用序列到序列模型来生成视频字幕的科学家和从业者特别感兴趣。 |
| SelfVIO: Self-Supervised Deep Monocular Visual-Inertial Odometry and Depth Estimation Authors Yasin Almalioglu, Mehmet Turan, Alp Eren Sari, Muhamad Risqi U. Saputra, Pedro P. B. de Gusm o, Andrew Markham, Niki Trigoni 在过去的十年中,已经提出了许多需要大量标记数据的监督式深度学习方法,用于视觉惯性里程法VIO和深度图估计。为了克服数据限制,自我监督学习已成为一种有前途的替代方法,它利用了场景中的几何和光度一致性等约束条件。在这项研究中,我们介绍了一种基于对抗性训练和自适应视觉惯性传感器融合的新型基于自我监督的深度学习VIO和深度图恢复方法SelfVIO。 SelfVIO学会根据未标记的单眼RGB图像序列和惯性测量单位IMU读数共同估算6自由度6 DoF自我运动和场景深度图。所提出的方法能够执行VIO,而无需IMU内部参数和/或IMU与摄像机之间的外部校准。估计和单视图深度恢复网络。我们对拟议框架进行了全面的定量和定性评估,将其性能与最先进的VIO,VO和可视化同时定位以及在KITTI,EuRoC和Cityscapes数据集上绘制VSLAM方法进行了比较。详细的比较证明,在姿态估计和深度恢复方面,SelfVIO优于最新的VIO方法,使其成为文献中现有方法中有希望的方法。 |
| Background Suppression Network for Weakly-supervised Temporal Action Localization Authors Pilhyeon Lee, Youngjung Uh, Hyeran Byun 监督不足的时间动作定位是一个非常具有挑战性的问题,因为在训练阶段未提供逐帧标签,而唯一的提示是视频级标签,每个视频是否包含感兴趣的动作帧。先前的方法汇总帧级别类分数以产生视频级别预测并从视频级别操作标签中学习。此公式不能完全模拟问题,因为背景帧被迫错误地分类为动作类,以准确预测视频级别标签。在本文中,我们设计了背景抑制网络BaS Net,它引入了背景的辅助类,并具有带有非对称训练策略的两个分支权重共享体系。这使BaS Net能够抑制背景帧的激活,从而提高定位性能。广泛的实验证明了BaS Net的有效性及其在最流行的基准THUMOS 14和ActivityNet上优于现有方法的优越性。我们的代码和训练有素的模型可在以下位置获得 |
| Computational Ceramicology Authors Barak Itkin, Lior Wolf, Nachum Dershowitz 要求野外考古学家确定陶器,为此目的,他们要依靠自己的经验和参考作品。我们已经开发了两个互补的机器学习工具,可以根据现场捕获的图像提出识别建议。一种方法依赖于板的断裂轮廓的形状,另一种方法基于装饰特征。对于轮廓识别工具,采用了一种新颖的深度学习架构,该架构整合了沿内表面和外表面的点的形状信息。装饰分类器基于图像识别中使用的相对标准的体系结构。在这两种情况下,训练分类器都需要应对在处理现实世界考古数据时所遇到的挑战,因为标记数据的匮乏导致不同类别实例之间的极端失衡,并且需要避免忽略稀有类别并注意某些类别的微小区别特征。训练数据的稀缺性通过使用合成生产的虚拟potsherds和采用多种数据增强技术得以克服。一种新颖的训练损失形式使我们能够克服人口不足的人群和判别特征的非均匀分布所引起的问题。 |
| Class-specific residual constraint non-negative representation for pattern classification Authors He Feng Yin, Xiao Jun Wu 基于表示的分类方法RBCM仍然是模式识别领域中最热门的主题之一,最近提出的基于非负表示的分类NRC在模式分类中取得了令人印象深刻的识别结果。但是,在NRC的公式中,除重建误差项外没有其他正则化项,这可能会导致求解不稳定并导致分类错误。为了克服NRC的这一缺点,在本文中,我们提出了一种针对类别的残差约束非负表示CRNR用于模式分类。 CRNR在NRC的公式中引入了特定于类别的残差约束,它鼓励更多同质的训练样本参与测试样本的表示。基于提出的CRNR,我们开发了基于CRNR的分类器CRNRC用于模式分类。在几个基准数据集上的实验结果证明了CRNRC优于常规RBCM以及最近提出的NRC。此外,在各种具有挑战性的模式分类任务中,CRNRC可以更好地工作或与某些先进的深度方法相媲美。我们建议的CRNRC的源代码可在以下位置访问: |
| DLGAN: Disentangling Label-Specific Fine-Grained Features for Image Manipulation Authors Guanqi Zhan, Yihao Zhao, Bingchan Zhao, Haoqi Yuan, Baoquan Chen, Hao Dong 最近的一些研究表明,将图像分解为内容和特征空间可以如何提供可控的图像转换操作。在本文中,我们提出了一个框架,该框架可以利用离散的多标签来控制要解散的特征,即解散标签特定的细颗粒特征以进行称为DLGAN的图像处理。通过将离散标签的特定属性特征映射到连续的先验分布中,我们可以利用离散标签和参考图像的优点来以混合方式实现图像处理。例如,给定一个具有多个离散细粒度标签的人脸图像数据集,例如CelebA,我们可以学习通过参考图像在黑发和金发之间平滑地插入人脸图像,同时通过离散的输入标签立即控制性别和年龄。据我们所知,这是在单个模型中实现这种混合操作的第一项工作。定性和定量实验证明了该方法的有效性 |
| Unsupervised Learning for Intrinsic Image Decomposition from a Single Image Authors Yunfei Liu, Yu Li, Shaodi You, Feng Lu 内在图像分解是计算机视觉中的基本任务,旨在推断场景的反射率和阴影。由于需要将一个图像分为两个部分,因此具有挑战性。为了解决这个问题,常规方法引入了各种先验来约束解决方案,但是性能有限。同时,通常通过有监督的学习方法来解决该问题,这实际上不是理想的解决方案,因为获得大规模真实自然场景的地面真相反射率和阴影具有挑战性,甚至是不可能的。在本文中,我们提出了一种新颖的无监督内在图像分解框架,该框架既不依赖标记的训练数据也不依赖手工制作的先验。取而代之的是,它直接从无监督和不相关的数据中了解反射率和阴影的潜在特征。为此,我们探讨了反射率与阴影,域不变内容约束和物理约束之间的独立性。在合成和真实图像数据集上的大量实验证明了所提出方法的始终如一的优越性能。 |
| SM-NAS: Structural-to-Modular Neural Architecture Search for Object Detection Authors Lewei Yao, Hang Xu, Wei Zhang, Xiaodan Liang, Zhenguo Li 现有技术的对象检测方法由于诸如骨架,特征融合颈部,RPN和RCNN头之类的各种模块而变得复杂,其中每个模块可能具有不同的设计和结构。如何利用计算成本和准确性来权衡结构组合以及多个模块的模块化选择神经架构搜索NAS在寻找最佳解决方案方面显示出巨大潜力。现有的用于对象检测的NAS仅专注于搜索单个模块(例如主干或特征融合颈)的更好设计,而忽略了整个系统的平衡。在本文中,我们提出了一种称为结构化到模块化NAS SM的两阶段粗略到精细搜索策略,用于搜索GPU友好的设计,既有效地组合了模块,又提供了更好的模块级体系结构来进行对象检测。具体来说,结构级搜索阶段首先旨在找到不同模块的有效组合。模块级搜索阶段然后扩展每个特定模块,并将Pareto推向更快的任务特定网络。我们考虑一种多目标搜索,其中搜索空间涵盖了许多流行的检测方法设计。通过探索从头开始的快速培训策略,我们可以直接搜索检测主干,而无需预先训练的模型或任何代理任务。所得的体系结构在推理时间和准确性上都支配了最先进的物体检测系统,并证明了在多个检测数据集上的有效性。与FPN相比,推理时间减少了一半,而且改善了1 mAP,而MaskRCNN的推理时间也达到了46 mAP。 |
| Visual Relationship Detection with Low Rank Non-Negative Tensor Decomposition Authors Mohammed Haroon Dupty, Zhen Zhang, Wee Sun Lee 我们解决了视觉关系检测VRD问题,该问题旨在以对象,谓语,对象的三元组形式描述对象对之间的关系。我们观察到,给定一对边界框建议,对象经常参与多个关系,这意味着三元组的分布是多峰的。我们利用三胞胎内的强相关性来学习以图像和边界框建议为条件的三重态变量的联合分布,从而消除了迄今为止使用的三胞胎独立分布。为了使学习三重态联合分布可行,我们引入了一种学习条件三重态分布的新技术,其形式为标准化的低秩非负张量分解。标准化张量分解采取离散变量混合分布的形式,因此能够捕获多模态。这使我们能够有效地学习高阶离散多峰分布,同时使参数大小易于管理。我们进一步对选择对象提议对的概率进行建模,并在模型中包括先验关系三元组。我们证明了该模型的每个部分都提高了性能,并且组合的性能优于Visual Genome VG和Visual Relationship Detection VRD数据集的最新水平。 |
| PAG-Net: Progressive Attention Guided Depth Super-resolution Network Authors Arpit Bansal, Sankaraganesh Jonna, Rajiv R.Sahay 在本文中,我们针对制导深度图超分辨率的挑战性问题提出了一种新方法,称为PAGNet。它基于残留的密集网络,并涉及注意机制,以抑制由于RGB图像的不正确引导而导致的纹理复制问题。注意模块主要涉及基于深度特征对指导图像进行空间关注。我们在测试数据集上评估提出的训练模型,并与最新的深度超分辨率方法进行比较。 |
| Real-time Ultrasound-enhanced Multimodal Imaging of Tongue using 3D Printable Stabilizer System: A Deep Learning Approach Authors M. Hamed Mozaffari, Won Sook Lee 尽管人们重新意识到了发音的重要性,但对于教员来说,如何应对语言学习者的发音需求仍然是一个挑战。对于语音教学,有相对稀缺的教学工具。与效率低下的传统发音指令(如收听和重复)不同,在新方法中采用了电子视觉反馈EVF系统(如超声技术)。近来,已经开发了超声增强的多峰方法,用于可视化覆盖在说话者头部的面部上的语言学习者的舌头运动。在大学一级,通过混合学习范式对该系统的几种语言课程进行了评估。结果表明,将发音器的系统可视化为对语言学习者的生物反馈将大大提高发音学习的效率。尽管成功地将多模式技术用于语音训练,但仍然需要人工和人工操作。在本文中,我们旨在通过利用强大的人工智能技术,提出一种新型的,全面的,自动的,实时的多模式发音训练系统,以解决先前方法的难题,从而为这一不断发展的研究做出贡献。这项研究的主要目的是结合超声技术,三维打印和深度学习算法的优势,以增强先前系统的性能。我们对所提议系统的初步教学评估显示,灵活性,控制力,鲁棒性和自治性得到了显着改善。 |
| Identify the cells' nuclei based on the deep learning neural network Authors Tianyang Zhang, Rui Ma 鉴定细胞核是大多数医学分析的重点。在临床实践中,非常需要帮助医生自动找到准确的细胞核位置。近来,全卷积神经网络FCN在许多图像分割中起着背骨的作用,例如医学领域的肝和肿瘤分割,技术领域的人体阻挡。细胞核识别任务也是一种图像分割。为此,我们更喜欢使用深度学习算法。我们构建了三个通用框架,一个是基于蒙版区域的卷积神经网络蒙版RCNN,它在许多图像分割中具有高性能,一个是U net,在小型数据集上具有很高的泛化性能,另一个是DenseUNet,是混合的具有密集网和U网的网络体系结构。我们比较了这三个框架的性能。我们在2018年数据科学挑战赛的数据集上评估了我们的方法。对于没有任何合奏的单个模型,它们都具有良好的性能。 |
| Graph Pruning for Model Compression Authors Mingyang Zhang, Xinyi Yu, Jingtao Rong, Linlin Ou, Weidong Zhang 以前的AutoML修剪工作使用单个图层功能来自动修剪过滤器。我们分析了具有捷径结构的不同块中两层的相关性。已经发现,在一个块中,较深的层具有许多冗余的过滤器,这些冗余的过滤器可以由前一层的过滤器表示,因此在修剪时必须考虑来自其他层的信息。在本文中,提出了一种图修剪方法,该方法将任何深度模型都视为拓扑图。基于图卷积网络的图PruningNet旨在自动提取每个节点的邻近信息。为了从各种拓扑中提取特征,Graph PruningNet通过针对每个节点的单独的完全连接层与Pruned Network连接,并从头开始在训练数据集上进行联合训练。因此,我们可以为任何大小的子网获得合理的权重。然后,我们通过强化学习来搜索修剪网络的最佳配置。与以前的工作不同,我们采用训练有素的Graph PruningNet中的节点特征代替手工特征,作为强化学习中的状态。与其他AutoML修剪作品相比,我们的方法在ImageNet 2012上的相同条件下达到了最先进的水平。该代码将在GitHub上发布。 |
| Crowd Density Forecasting by Modeling Patch-based Dynamics Authors Hiroaki Minoura, Ryo Yonetani, Mai Nishimura, Yoshitaka Ushiku 预测视频中观察到的人类活动是计算机视觉领域的长期挑战,这导致了各种现实世界的应用,例如移动机器人,自动驾驶和辅助系统。在这项工作中,我们提出了一种新的视觉预测任务,称为人群密度预测。给定一个由监视摄像机捕获的人群的视频,我们的目标是预测该人群在未来的帧中将如何运动。为了解决此任务,我们开发了基于补丁的密度预测网络PDFN,该网络可对一系列人群密度图进行预测,这些人群密度图描述了每个视频帧中每个位置的拥挤程度。 PDFN表示基于空间重叠斑块的人群密度图,并在紧凑的潜在空间中逐块学习密度动力学。这使我们能够高效地对各种复杂的人群密度动态进行建模,即使输入视频涉及可变数量的人群(每个人群独立移动)也是如此。与几个公开数据集的实验结果表明,与最新的预测方法相比,我们的方法是有效的。 |
| A Comparative Evaluation of SGM Variants (including a New Variant, tMGM) for Dense Stereo Matching Authors Sonali Patil, Tanmay Prakash, Bharath Comandur, Avinash Kak 我们的目标是三个方面。1要提出一种新的密集立体声匹配算法tMGM,该算法通过将tSGM的分层逻辑与MGM的支持结构相结合,相对于基线SGM实现了6 8的性能改进,这些性能数字已发布在tMGM 16下。 Middlebury Benchmark V3和2通过详尽的定量和定性比较研究,比较了SGM方法用于密集立体匹配的主要变体(包括新的tMGM)在存在光照变化和阴影,b无纹理或弱纹理的情况下的性能。区域,在存在大的立体校正误差的情况下,场景中的c个重复模式。 3提出一种新颖的DEM雕刻方法,用于估计多日期卫星立体声对的初始视差搜索范围。根据我们的研究,我们发现tMGM通常在所有这些数据条件下表现最佳。 tSGM和MGM均可提高立体视差图的密度,并且在tMGM中将两者结合起来可以准确估计大量像素的视差,否则这些像素会被SGM宣布无效。我们在比较评估中使用的数据集包括Middlebury2014,KITTI2015和ETH3D数据集,以及来自MVS Challenge数据集的San Fernando地区的卫星图像。 |
| MIMAMO Net: Integrating Micro- and Macro-motion for Video Emotion Recognition Authors Didan Deng, Zhaokang Chen, Yuqian Zhou, Bertram Shi 时空特征学习对于视频情感识别至关重要。先前的深层网络结构通常关注于宏运动,该宏运动在很长的时间尺度上扩展,例如,在几秒的数量级。我们认为,集成捕获微观和宏观运动信息的结构将有利于情绪预测,因为人类会同时感知微观和宏观表达。在本文中,我们建议将微观和宏观运动特征相结合,以通过两流递归网络MIMAMO微观宏观运动网改善视频情感识别。具体来说,较小和较短的微动作可以通过两流网络进行分析,而较大和更持久的宏动作可以通过后续的递归网络很好地捕获。为网络的不同部分的角色分配特定的解释,使我们能够根据原来的知识选择来选择参数,而事实证明这些选择是最优的。我们模型的重要创新之一是使用帧间相位差,而不是使用光流作为时间流的输入。与光流相比,相位差需要的计算量更少,并且对照明变化的鲁棒性更高。我们提出的网络在两个视频情感数据集(OMG情感数据集和Aff Wild数据集)上实现了最先进的性能。最重要的收获是唤醒预测,对于该预测,运动信息在直观上更具信息性。源代码位于 |
| Reinforcing an Image Caption Generator Using Off-Line Human Feedback Authors Paul Hongsuck Seo, Piyush Sharma, Tomer Levinboim, Bohyung Han, Radu Soricut 人工评级目前是评估图像字幕模型质量的最准确方法,但是昂贵的人工评级评估最经常使用的唯一结果是评估数据集中的一些总体统计数据。在本文中,我们表明,即使字幕分级的数量比字幕训练数据少几个数量级,也可以利用来自实例级人工字幕分级的信号来改善字幕模型。我们采用策略梯度方法来最大化非评级强化学习设置中的人类评级,作为奖励,其中策略梯度是根据来自字幕评级数据集中字幕的分布样本估算的。我们的经验证据表明,所提出的方法可以学习将人类评分者的判断概括为以前看不见的图像集,这是由一组不同的人类判断者判断出来的,此外还需要在不同的多维并行人类评估程序中进行判断。 |
| Rethinking Normalization and Elimination Singularity in Neural Networks Authors Siyuan Qiao, Huiyu Wang, Chenxi Liu, Wei Shen, Alan Yuille 在本文中,我们从消除奇异性的角度研究了神经网络的归一化方法。消除奇点对应于训练轨迹上神经元持续失活的点。它们在损耗环境中导致退化的歧管,这会减慢训练速度并损害模型性能。我们展示了基于通道的规范化层归一化和组归一化无法保证与消除奇异点相距甚远,而批处理归一化可以通过设计避免模型过于接近它们。为了解决这个问题,我们提出了BatchChannel Normalization BCN,它使用批处理知识来避免训练信道标准化模型时消除奇异点。与批处理规范化不同,BCN可以在大批量和微型批次训练设置中运行。 BCN的有效性在许多任务上得到了验证,包括图像分类,对象检测,实例分割和语义分割。代码在这里 |
| Fast Sparse ConvNets Authors Erich Elsen, Marat Dukhan, Trevor Gale, Karen Simonyan 从历史上看,对高效推理的追求一直是对新型深度学习架构和构建块进行研究的推动力之一。最近的一些示例包括挤压和激励模块,Xception中的深度可分离卷积以及MobileNet v2中的倒置瓶颈。值得注意的是,在所有这些情况下,最终的构建模块不仅可以实现更高的效率,而且还可以实现更高的准确性,并在该领域得到了广泛的采用。在这项工作中,我们进一步扩展了用于神经网络体系结构的有效构建模块的库,但是我们并未将卷积之类的标准原语替换为稀疏的对应内容,而是提倡将这些密集原语替换。尽管使用稀疏性减少参数数量的想法并不新鲜,但传统观点认为,理论FLOP的减少不会转化为实际效率的提高。我们旨在通过引入一系列针对ARM和WebAssembly的高效稀疏内核来纠正这种误解,我们将其作为XNNPACK库的一部分开放给社区使用,以使社区受益。借助我们对稀疏基元的有效实现,我们表明,在效率准确度曲线上,稀疏版本的MobileNet v1,MobileNet v2和EfficientNet体系结构明显优于强密度基准。在Snapdragon 835上,我们的稀疏网络性能比其密集的等效性能高1.3到2.4倍,相当于整个MobileNet系列产品的改进。我们希望我们的发现将促进稀疏性被更广泛地用作创建高效且准确的深度学习架构的工具。 |
| RefinedMPL: Refined Monocular PseudoLiDAR for 3D Object Detection in Autonomous Driving Authors Jean Marie Uwabeza Vianney, Shubhra Aich, Bingbing Liu 在本文中,我们努力解决由惊人的高密度原始PseudoLiDAR用于自动驾驶的单眼3D对象检测引起的歧义。在没有太多计算开销的情况下,我们提出了在3D检测之前对PseudoLiDAR进行监督的和未经监督的稀疏化方案。两种策略都仅使用KITTI对象检测基准上的5个点,就可以使标准3D检测器在原始PseudoLiDAR基线上获得更好的性能,从而使我们的单目框架和基于LiDAR的对应物在计算上等效(图1)。此外,我们的体系结构不可知的改进为汽车和行人类别提供了KITTI3D测试集上的最新技术成果,为行人提供了54个相对改进。最后,对单眼和基于LiDAR的3D检测框架之间的差异进行探索性分析,以指导未来的工作。 |
| Adversarial Learning of Privacy-Preserving and Task-Oriented Representations Authors Taihong Xiao, Yi Hsuan Tsai, Kihyuk Sohn, Manmohan Chandraker, Ming Hsuan Yang 由于数据驱动的深度学习已成为现代机器学习系统的重要组成部分,因此数据隐私已成为一个重要问题。例如,通过模型反转攻击可能会存在机器学习系统的潜在隐私风险,其目标是从深层网络的潜在表示中重建输入数据。我们的工作旨在学习保护隐私和面向任务的表示形式,以防御此类模型反转攻击。具体来说,我们提出了一种对抗重建学习框架,该框架可防止将潜在表示解码为原始输入数据。通过模拟对手的预期行为,可以通过最小化负像素重建损失或负特征重建(即感知距离损失)来实现我们的框架。我们验证了该方法在面部属性预测上的效果,表明我们的方法可以在实用性能略有下降的情况下保护视觉隐私。此外,我们还展示了公用程序隐私权在权衡训练时会因负感知距离损失而选择不同的超参数进行折衷,从而使服务提供商可以确定具有特定实用程序性能的正确隐私保护级别。此外,我们对功能,任务和数据的不同选择进行了广泛的研究,以进一步分析其对隐私保护的影响。 |
| Spectral Graph Transformer Networks for Brain Surface Parcellation Authors Ran He, Karthik Gopinath, Christian Desrosiers, Herve Lombaert 建模为图形网格的大脑表面分析是一项艰巨的任务。传统的深度学习方法通常依赖于欧几里得空间中的数据。作为对不规则图的扩展,在傅立叶或频谱域中定义了卷积运算。通过分解图拉普拉斯算子获得该光谱域,该图拉普拉斯算子捕获了相关的形状信息。但是,跨不同脑图的频谱分解会导致各个频谱域的特征向量之间出现不一致,从而导致图学习算法失败。当前的频谱图卷积方法通过在缓慢的迭代步骤中分别将特征向量与参考大脑对齐来处理此差异。本文提出了一种新颖的方法,用于学习使用直接数据驱动的方法对齐大脑网格所需的变换矩阵。我们的对齐和图形处理方法可以快速分析大脑表面。本文提出的新型光谱图变压器SGT网络在光谱域中使用很少的随机子采样节点来学习多个脑表面的对齐矩阵。我们验证了此SGT网络与图卷积网络的使用,以执行皮质细胞分裂。我们在101个手动标记的大脑表面上的方法显示了比无对齐策略更好的碎片处理性能,比传统的迭代对齐方法快了1400倍。 |
| HAL: Improved Text-Image Matching by Mitigating Visual Semantic Hubs Authors Fangyu Liu, Rongtian Ye, Xun Wang, Shuaipeng Li 中心度问题广泛存在于高维嵌入空间中,并且是交叉模式匹配任务的基本错误来源。在这项工作中,我们研究了视觉语义嵌入VSE中集线器的出现及其在文本图像匹配中的应用。我们分析了训练VSE的两个广泛采用的优化目标的利弊,并提出了一种新颖的中枢感知损失函数HAL,用于解决以前方法的缺陷。与Faghri等人(2018)只是在小批量中仅提取最困难的样本不同,HAL会使用本地和全局统计数据来考虑集线器的权重,从而考虑所有样本。我们对模型架构和数据集的各种配置进行了实验。该方法表现出了非常好的鲁棒性,并且在所有设置下对文本图像匹配的任务带来了持续的改进。具体来说,在与Faghri等人相同的模型架构下。 2018和李等人2018年,仅切换学习目标,我们报告MS COCO最高R 1提升7.4,Flickr30k最大8.3提升。 |
| Machine: The New Art Connoisseur Authors Yucheng Zhu, Yanrong Ji, Yueying Zhang, Linxin Xu, Aven Le Zhou, Ellick Chan 识别和理解艺术风格以发现艺术影响力的过程对于研究艺术史至关重要。传统上,受过训练的专家会仔细审查作品的详细信息,并将其与其他已知作品进行比较。为了自动化和扩展此任务,我们使用了几种最先进的CNN架构来探索机器如何帮助感知和量化艺术风格。这项研究探讨了1机器如何准确地对艺术风格进行分类2不同风格和艺术家之间的潜在关系是什么为了帮助回答第一个问题,我们使用Inception V3的最佳性能模型达到了88.35的9类分类精度,优于Elgammal等人的模型。的研究超过了20%。使用Grad CAM热图进行的可视化确认模型正确地聚焦于绘画的特征部分。为了帮助解决第二个问题,我们通过从效果最好的分类模型中提取512个特征,对风格和艺术家之间的影响进行网络分析。通过2D和3D T SNE可视化,我们观察到清晰的按时间顺序排列的艺术风格发展和分离模式。网络分析还似乎从艺术历史的角度显示了预期的艺术家级别的联系。这项技术似乎有助于识别一些以前未知的联系,这些联系可能会为艺术史学家进一步探索的新方向提供启示。我们希望人类和机器协同工作可以为该领域带来新的机会。 |
| Learning to Caption Images with Two-Stream Attention and Sentence Auto-Encoder Authors Arushi Goel, Basura Fernando, Thanh Son Nguyen, Hakan Bilen 从图像自动生成自然语言描述是人工智能中一个具有挑战性的问题,需要对视觉和文本提示之间的相关性有一个很好的了解。为了桥接这两种方式,现有技术中的方法通常使用图像和文本之间的动态界面(称为注意),该界面学会识别相关的图像部分,以估计以先前步骤为条件的下一个单词。尽管此机制很有效,但当嘈杂的视觉提示和文本提示之间找不到正确的关联时,就无法找到正确的关联。在本文中,我们提出了两种新颖的方法来解决此问题,即两种流注意力机制可以自动发现潜在类别,并根据先前生成的单词将它们与图像区域相关联; ii。一种规范化技术,封装了字幕的句法和语义结构,改进了图像字幕模型的优化。我们的定性和定量结果证明了MSCOCO数据集设置方面的显着改进,并为图像字幕提供了最新的性能。 |
| Deriving star cluster parameters with convolutional neural networks. II. Extinction and cluster/background classification Authors J. Bialopetravi ius, D. Narbutis, V. Vansevi ius 上下文。卷积神经网络CNN已被建立为在自然图像上进行快速目标检测和分类的首选方法。这为天体测量数据呈指数增长的天体参数推断打开了大门。到目前为止,星团分析是基于积分或分辨的恒星光度法,它限制了可从团簇图像各个像素中提取的信息量。 |
| Direct Classification of Type 2 Diabetes From Retinal Fundus Images in a Population-based Sample From The Maastricht Study Authors Friso G. Heslinga, Josien P.W. Pluim, A.J.H.M. Houben, Miranda T. Schram, Ronald M.A. Henry, Coen D.A. Stehouwer, Marleen J. van Greevenbroek, Tos T.J.M. Berendschot, Mitko Veta 2型糖尿病T2D是一种慢性代谢性疾病,可能导致失明和心血管疾病。关于早期T2D的信息可能存在于视网膜眼底图像中,但是这些图像可用于多大程度的筛查仍是未知的。在这项研究中,采用深度神经网络来区分有和没有T2D的个体的眼底图像。我们研究了三种实现高分类性能的方法,这些方法通过接收器工作曲线ROC AUC下的面积来衡量。同时输出视网膜生物标志物和T2D的多目标学习方法的最佳AUC为0.746 pm 0.001。此外,当将具有高预测不确定性的图像推荐给专家时,可以提高分类性能。我们还显示,使用简单的平均方法,每个人的左眼和右眼图像的组合可以进一步提高分类性能AUC 0.758 pm 0.003。结果是有希望的,表明从视网膜眼底图像筛查T2D的可行性。 |
| HybridNetSeg: A Compact Hybrid Network for Retinal Vessel Segmentation Authors Ling Luo, Dingyu Xue, Xinglong Feng 近年来,出现了许多基于图像分割的视网膜血管分析方法。但是,现有方法依赖于繁琐的主干,例如VGG16和ResNet 50,这得益于其强大的特征提取功能,但计算成本却很高。在本文中,我们提出了一种新颖的神经网络HybridNetSeg,致力于解决这一缺点,同时进一步提高整体性能。考虑到可变形卷积可以提取复杂和可变的结构信息,并且在混合深度卷积中较大的核有助于更高的精度。我们已经整合了这两个模块,并使用启发式学习的思想提出了一种混合卷积块HCB。受U Net的启发,我们使用HCB代替了U Net编码器的常见卷积的一部分,在加速推理过程的同时,将参数数量大大减少到0.71M。不仅如此,我们还提出了一种多尺度混合损失机制。在三个主要基准数据集上进行的大量实验证明了我们提出的方法的有效性 |
| Instance Cross Entropy for Deep Metric Learning Authors Xinshao Wang, Elyor Kodirov, Yang Hua, Neil Robertson 损失函数在深度度量学习中起着至关重要的作用,因此已经提出了各种函数。一些通过成对或三重相似性约束监督学习过程,而其他一些则利用多个数据点之间的结构化相似性信息。在这项工作中,我们从新颖的角度着手进行深度度量学习。我们提出了实例交叉熵ICE,它测量了估计的实例级别匹配分布与其基本事实之间的差异。 ICE具有三个主要吸引力。首先,类似于分类交叉熵CCE,ICE具有清晰的概率解释,并利用结构化的语义相似性信息进行学习监督。其次,ICE可以迭代地从小批量学习,因此可扩展到无限的训练数据,并且与训练集的大小无关。第三,受我们的相对权重分析影响,引入了无缝的样品重加权。它重新缩放样本梯度以控制训练样本的差异程度,而不是通过样本挖掘将其截断。除了其简单性和直观性之外,在三个真实世界的基准上进行的大量实验证明了ICE的优越性。 |
| Retinal Vessel Segmentation based on Fully Convolutional Networks Authors Zhengyuan Liu 视网膜血管的形态特征,例如长度,宽度,弯曲度,分支模式和角度,在各种心血管疾病和眼科疾病(例如糖尿病,高血压和动脉硬化)的诊断,筛查,治疗和评估中起着重要作用。从视网膜眼底图像提取视网膜血管的这些形态特征之前,关键步骤是血管分割。在这项工作中,我们提出了一种基于完全卷积网络的视网膜血管分割方法。从每个视网膜图像中提取数千个补丁,然后将其输入网络,并通过旋转提取的补丁来应用数据论证。全卷积网络的两种体系结构U Net和LadderNet被用于血管分割。我们在三个公共数据集DRIVE,STARE和CHASE DB1中评估了我们方法的性能。与最新技术水平相比,我们的方法的实验结果显示出优异的性能。 |
| Shape Detection In 2D Ultrasound Images Authors Ruturaj Gole, Haixia Wu, Subho Ghose 超声图像是在临床环境中用于分析和检测不同器官以进行疾病研究或诊断的最广泛使用的技术之一。依靠放射线专家等专家的主观意见,需要一种能够提供客观分析的自动识别和检测系统。以前在此主题上所做的工作是有限的,可以按感兴趣的器官分类。混合神经网络,线性和逻辑回归模型,3D重建模型以及各种机器学习技术已用于解决复杂的问题,例如病变和癌症的检测。我们的项目旨在使用双路径网络DPN来分割和检测从3D打印的肝脏模型获取的超声图像中的形状。此外,可以将DPN深度架构与完全卷积网络FCN结合使用以完善结果。用各种过滤器进行去噪的数据将用于评估它们之间的相对距离并提供最佳结果。少量数据集可与DPN配合使用,因此,这应适合我们,因为我们的数据集的大小将受到限制。此外,超声扫描应从扫描仪相对于器官的不同方向进行,以使训练数据集可以准确地执行分割和形状检测。 |
| Graph Convolution Networks for Probabilistic Modeling of Driving Acceleration Authors Jianyu Su, Peter A. Beling, Rui Guo, Kyungtae Han 对自主车辆周围交通进行建模和预测的能力对于自主飞行员和智能驾驶员辅助系统至关重要。加速度预测作为交通预测的主要组成部分之一很重要。本文提出了解决加速度预测问题的新方法。通过用图形模型表示车辆之间的空间关系,我们建立了一个广义的加速度预测框架。本文研究了提出的图卷积网络的有效性,该图卷积网络在预测公路上车辆行驶加速度分布的图形上运行。我们将通过整合递归神经网络来进一步研究预测改进,以解决交通数据中固有的时间复杂性。使用综合性能指标进行仿真研究的结果支持以下结论:我们提出的网络在预测范围内生成逼真的轨迹方面要优于最新方法。 |
| 2SDR: Applying Kronecker Envelope PCA to denoise Cryo-EM Images Authors Szu Chi Chung, Po Yao Niu, Su Yun Huang, Wei Hau Chang, I Ping Tu 主成分分析PCA可以说是向量类型数据使用最广泛的降维方法。当应用于图像数据时,PCA要求将图像描绘为矢量。由于由于矢量化步骤,它将解决巨大协方差矩阵的特征值问题,因此所得的计算量很大。为了减轻计算负担,引入了使用列向量和行向量以及Kronecker乘积生成每个基本向量的多线性PCA MPCA,并在面部图像集上证明了其成功。但是,当我们将MPCA应用于低温电子显微镜低温EM粒子图像时,与PCA相比,结果并不令人满意。另一方面,为了比较减少的空间以及MPCA和PCA的参数数量,提出了Kronecker信封PCA KEPCA,以提供MPCA类似的PCA基础。在这里,我们应用KEPCA通过两级降维2SDR算法对冷冻机EM图像进行降噪。 2SDR首先应用MPCA提取投影分数,然后对这些分数应用PCA以进一步减小尺寸。 2SDR具有两个优点,即它继承了MPCA的计算优势,并且其投影得分与PCA的得分无关。使用三个低温EM基准测试实验数据集进行的测试表明,就计算效率和降噪质量而言,2SDR的性能优于单独的MPCA和PCA。值得注意的是,从2SDR去噪显微照片中选出的去噪粒子允许后续的结构分析,以达到高质量的3D密度图。这表明通过这种2SDR去噪策略可以很好地保存高分辨率信息。 |
| ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring Authors David Berthelot, Nicholas Carlini, Ekin D. Cubuk, Alex Kurakin, Kihyuk Sohn, Han Zhang, Colin Raffel 通过引入两种新技术分布对齐和增强锚定,我们改进了最近提出的MixMatch半监督学习算法。分布对齐鼓励对未标记数据的预测的边际分布接近于地面事实标签的边际分布。增强锚定将输入的多个高度增强版本输入到模型中,并鼓励每个输出都与相同输入的弱增强版本的预测接近。为了产生强大的增强效果,我们提出了一种AutoAugment变体,可以在训练模型时学习增强策略。我们的新算法称为ReMixMatch,与以前的工作相比,其数据效率明显提高,达到相同精度所需的数据量要少5到16倍。例如,在具有250个带标签的示例的CIFAR 10上,我们达到93.73的准确度,而MixMatch的4个,000个示例的93.58的准确度和每个类别仅四个标签的中位准确度为84.92。我们将代码和数据开源 |
| Synthetic vs Real: Deep Learning on Controlled Noise Authors Lu Jiang, Di Huang, Weilong Yang 在嘈杂的数据上进行受控实验对于全面了解各种噪声水平的深度学习至关重要。由于缺乏合适的数据集,以前的研究仅研究了关于受控合成噪声的深度学习,而从未在受控环境中系统地研究过现实世界中的噪声。为此,本文建立了在10个受控噪声水平下的真实噪声标签基准。由于现实世界中的噪声具有独特的属性,因此,为了了解它们之间的区别,我们针对各种噪声级别和类型,体系结构,方法和培训设置进行了大规模研究。我们的研究表明1深度神经网络DNN可以更好地推广现实世界的噪声。 2个DNN可能不会首先在现实世界的噪声数据上学习模式。 3对网络进行微调后,ImageNet架构可以在嘈杂的数据上很好地概括。 4现实世界中的噪声似乎危害较小,但要改进健壮的DNN方法则要困难得多。 5在合成噪声上有效的稳健学习方法在现实世界的噪声上可能效果不佳,反之亦然。我们希望我们的基准以及我们的发现将有助于对噪声数据进行深度学习研究。 |
| Filter Response Normalization Layer: Eliminating Batch Dependence in the Training of Deep Neural Networks Authors Saurabh Singh, Shankar Krishnan 批次标准化BN是一种非常成功且广泛使用的批次相关训练方法。它使用小型批处理统计数据对激活进行归一化会引入样本之间的依赖性,如果小型批处理的大小太小或样本相互关联,则可能会损害训练。为了解决这些问题,已经提出了一些替代方法,例如“批量重新归一化”和“组归一化GN”。但是,它们要么与大批量的BN的性能不匹配,要么对于小批量的BN仍表现出性能下降,或者对模型体系结构引入了人为的约束。在本文中,我们提出了滤波器响应归一化FRN层,它是归一化和激活函数的新颖组合,可以用作替代其他归一化和激活的方法。我们的方法独立地对每个批次样品的每个激活图进行操作,从而消除了对其他批次样品或同一样品通道的依赖性。对于所有批次大小,我们的方法在各种设置中都优于BN和所有替代方法。在InceptionV3和ResnetV2 50架构的Imagenet分类中,具有最小批量大小的BN上,FRN层在前1个验证精度上的性能比BN好约0.7 1.0。此外,在小型批处理规模较小的情况下,它在相同问题上的性能比GN好1。对于COCO数据集上的对象检测问题,在所有批次大小方案中,FRN层的性能均优于所有其他方法至少0.3 0.5。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pexels.com