【今日CV 计算机视觉论文速览 91期】Mon, 1 Apr 2019
今日CS.CV 计算机视觉论文速览
Mon, 1 Apr 2019 , ? No.91期
Totally 35 papers
?上期速览 ✈更多精彩请移步主页

Interesting:
?CoSegNet,一套用于点云联合分割的网络架构,通过矩阵秩估计加入了连续性损失,优化了预处理的分割外形,得到了高效的分割结果。 (from Simon Fraser University)
流程图:

精炼网络和特征抽取网络:

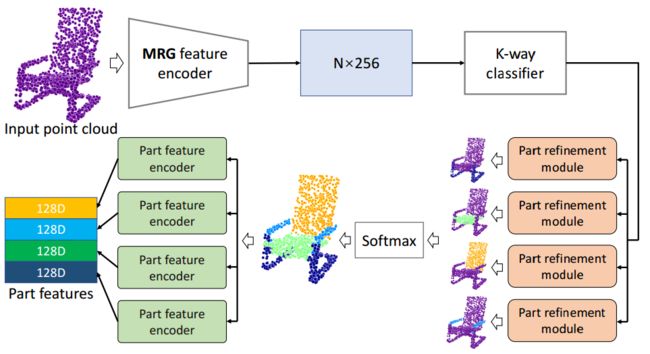
不同外形中得到的形状相似矩阵:

?对于任意模糊核的可插入超分辨模块研究, 拓展了基于双三次退化过程的超分辨,并建立起了处理任意模糊核的理论框架。设计的新的SISR退化过程模型充分利用盲去噪方法的优势来估计模糊核,并利用即插即用算法来分离变量,优化能量函数。便于插入任何形式的求解器先验以替代去噪先验。(from HIT)
三种不同形式的模糊核:

最后的效果:
code:https://github.com/cszn/DPSR
?CroP,色彩恒常基准数据集生成器,(from University of Zagreb)

datasset Cube+: https://ipg.fer.hr/ipg/resources/color_constancy?
?IMAGENET-P,常见扰动数据集,包括了15种常见扰动(from University of California, Berkeley)

dataset:https://github.com/hendrycks/robustness
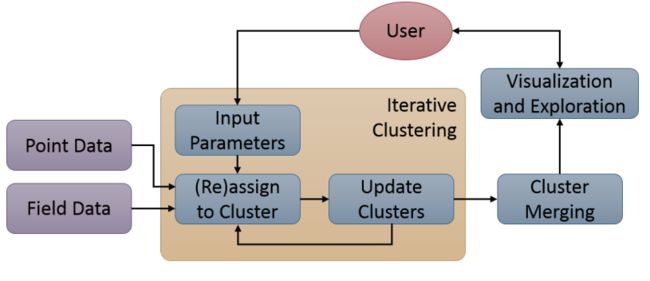
?点或场中4D特征抽取方法,欧几里得表示的场和拉格朗日形式的点/轨迹,(from University of California, Davis)
流程图和具体方法:

Daily Computer Vision Papers
| Incremental Learning with Unlabeled Data in the Wild Authors Kibok Lee, Kimin Lee, Jinwoo Shin, Honglak Lee 已知深度神经网络在类增量学习中遭受灾难性遗忘,其中在学习新任务时先前任务的性能急剧下降。为了减轻这种影响,我们建议在野外利用连续和大量的未标记数据。特别是,为了有效地利用这些瞬态外部数据,我们设计了一种新的类增量学习方案,其具有新的蒸馏损失,称为全局蒸馏,ba学习策略以避免过度拟合到最近的任务,以及ca采样策略用于所需的外部数据。我们对各种数据集(包括CIFAR和ImageNet)的实验结果证明了所提方法优于现有方法的优越性,特别是当可以访问未标记数据流时,与现有技术方法相比,我们实现了高达9.3的相对性能提升。 |
| CroP: Color Constancy Benchmark Dataset Generator Authors Nikola Bani , Karlo Ko evi , Marko Suba i , Sven Lon ari 在当代数码相机中实现颜色恒定性作为预处理步骤是非常重要的,因为它消除了场景照明对物体颜色的影响。为了开发和测试新的颜色恒常性方法,已经创建了几个基准颜色恒定数据集。然而,它们都有许多缺点,包括少量图像,错误提取的地面实况照明,长期误用历史,违反其规定的假设等。为了克服这些和类似的问题,本文中的颜色恒定基准数据集生成器是建议。对于给定的相机传感器,它能够生成在现实世界的子集中拍摄的任何数量的真实原始图像,即打印照片的图像。具有此类图像的数据集与其他现有的真实世界数据集共享许多正面特征,而一些消极特征被完全消除。生成的图像可以成功地用于训练后来在现实世界数据集上实现高精度的方法。这为为高级深度学习技术创建足够大的数据集开辟了道路。提出并讨论了实验结果。源代码可在以下位置获得 |
| CNN-based Prostate Zonal Segmentation on T2-weighted MR Images: A Cross-dataset Study Authors Leonardo Rundo, Changhee Han, Jin Zhang, Ryuichiro Hataya, Yudai Nagano, Carmelo Militello, Claudio Ferretti, Marco S. Nobile, Andrea Tangherloni, Maria Carla Gilardi, Salvatore Vitabile, Hideki Nakayama, Giancarlo Mauri 前列腺癌是美国男性中最常见的癌症。然而,尽管多参数磁共振成像MRI的进步提供了与病理区域相关的形态学和功能信息,但前列腺成像仍然具有挑战性。随着整个前列腺腺体分割,区分中央腺体CG和外周区域PZ可以指导鉴别诊断,因为肿瘤的频率和严重程度在这些区域中不同,但是它们的边界通常是弱的和模糊的。这项工作提出了深度学习的初步研究,以自动描绘CG和PZ,旨在评估卷积神经网络CNNs在两个多中心MRI前列腺数据集上的泛化能力。特别是,我们比较了三种基于CNN的体系结构SegNet,U Net和pix2pix。在这样的背景下,在没有预训练的情况下实现的分割性能在4倍交叉验证中进行比较。通常,U Net优于其他方法,尤其是在对多个数据集执行训练和测试时。 |
| Infinite Brain MR Images: PGGAN-based Data Augmentation for Tumor Detection Authors Changhee Han, Leonardo Rundo, Ryosuke Araki, Yujiro Furukawa, Giancarlo Mauri, Hideki Nakayama, Hideaki Hayashi 由于缺乏可用的注释医学图像,精确的计算机辅助诊断需要密集的数据增强DA技术,例如原始图像的几何强度变换,然而,这些变换图像本质上具有与原始图像类似的分布,导致有限的性能改进。为了填补真实图像分布中缺乏的数据,我们合成了脑对比增强磁共振MR图像,这些图像与使用生成对抗网络GAN的原始图像完全不同。本研究利用GANs PGGANs的渐进式生长,这是一种多阶段生成训练方法,用于生成基于卷积神经网络的脑肿瘤检测的原始大小的256×256 MR图像,这是由于传统的GAN难以通过高分辨率的GAN训练不稳定而产生的。和各种肿瘤的大小,位置,形状和对比度。我们的初步结果表明,这种新颖的基于PGGAN的DA方法与经典DA相结合,在肿瘤检测和其他医学成像任务中可以实现有希望的性能改善。 |
| Second Rethinking of Network Pruning in the Adversarial Setting Authors Shaokai Ye, Kaidi Xu, Sijia Liu, Hao Cheng, Jan Henrik Lambrechts, Huan Zhang, Aojun Zhou, Kaisheng Ma, Yanzhi Wang, Xue Lin 众所周知,深度神经网络DNN容易受到对抗性攻击,这是通过在良性示例上添加精心设计的扰动来实现的。基于Min max强健优化的对抗性训练可以提供抵御对抗性攻击的安全性概念。然而,对抗性强健性要求网络的容量明显大于自然训练的能力,只有良性的例子。本文提出了一个并行对抗训练和权重修剪的框架,它可以实现模型压缩,同时仍然保持对抗性的稳健性,并基本上解决了对抗性训练的两难问题。此外,这项工作研究了传统网络修剪设置中关于重量修剪的两个假设,并发现权重修剪对于减少对抗设置中的网络模型大小是必不可少的,即,即使从大模型继承初始化,也从头开始训练小模型无法实现对抗稳健性和模型压缩。 |
| Photo-realistic Monocular Gaze Redirection using Generative Adversarial Networks Authors Zhe He, Adrian Spurr, Xucong Zhang, Otmar Hilliges 凝视重定向是将凝视改变为给定单眼眼贴图像的期望方向的任务。诸如视频会议,电影和游戏之类的许多应用以及用于凝视估计的训练数据的生成需要重定向凝视,而不会扭曲眼睛周围区域的外观并且同时产生照片逼真图像。现有方法缺乏产生感知似乎合理的图像的能力。在这项工作中,我们提出了一种新方法,通过利用生成性对抗训练来合成以目标凝视方向为条件的眼睛图像来缓解这一问题。我们的方法确保了合成图像与真实图像的感知相似性和一致性。此外,凝视估计损失用于准确地控制凝视方向。为了获得高质量的图像,我们将感知和周期一致性损失纳入我们的架构中。在广泛的评估中,我们表明所提出的方法在图像质量和重定向精度方面都优于现有技术方法。最后,我们展示如果用于增加真实训练数据,生成的图像可以为凝视估计任务带来显着改善。 |
| Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels Authors Kai Zhang, Wangmeng Zuo, Lei Zhang 虽然深度神经网络基于DNN的单图像超分辨率SISR方法正在迅速普及,但它们主要是为广泛使用的双三次降解而设计的,并且仍然存在对于它们用任意模糊核超分辨率低分辨率LR图像的基本挑战。同时,由于其模块化结构易于插入降噪器先验,因此即插即用图像恢复具有高度灵活性。在本文中,我们通过在即插即用框架的帮助下扩展基于深度SISR的双三次降级来处理具有任意模糊内核的LR图像,从而提出了一种原则性的公式和框架。具体来说,我们设计了一个新的SISR退化模型,以便利用现有的盲目去模糊方法进行模糊核估计。为了优化新的降解诱导能量函数,我们通过可变分裂技术推导出即插即用算法,这允许我们先将任何超级旋转变压器插入而不是作为模块化部件之前的降噪器。对合成和真实LR图像的定量和定性评估表明,所提出的深度即插即用超分辨率框架对于处理模糊的LR图像是灵活且有效的。 |
| Multimodal Emotion Classification Authors Anurag Illendula, Amit Sheth 大多数NLP和计算机视觉任务仅限于标记数据的稀缺性。在社交媒体情感分类和其他相关任务中,主题标签已被用作标记数据的指示符。随着社交媒体表情符号使用的快速增长,表情符号被用作主要社交NLP任务的附加功能。然而,如果社交媒体上的多媒体帖子中的帖子由图像和文本组成,则对此进行的研究较少。与此同时,我们已经看到了将领域知识纳入其中以提高机器对文本理解的兴趣。在本文中,我们研究表情符号的领域知识是否可以提高情绪分类任务的准确性。我们利用最先进的深度学习架构,利用社交媒体帖子中不同形式对情感分类任务的重要性。我们的实验表明,三种形式的文本,表情符号和图像编码不同的信息来表达情感,因此可以相互补充。我们的结果还表明,表情符号意义取决于文本背景,表情符号与文本结合编码比单独考虑更好的信息。通过550,000个岗位的培训数据实现了71.98的最高准确度。 |
| Asymmetric Deep Semantic Quantization for Image Retrieval Authors Zhan Yang, Osolo Ian Raymond, WuQing Sun, Jun Long 由于其快速检索和存储效率能力,散列已被广泛用于最近邻检索任务。通过使用基于深度学习的技术,散列在许多应用程序中可以胜过基于非学习的散列。然而,对先前基于学习的散列方法存在一些限制,例如,由于散列方法不能发现丰富的语义信息而学习的散列码不具有辨别力,并且训练策略难以优化离散二进制码。在本文中,我们提出了一种新的基于学习的散列方法,命名为textbf下划线A对称textbf下划线D eep textbf下划线S emantic textbf下划线Q uantization textbf ADSQ。 textbf ADSQ使用三个流框架实现,其中包含一个emph LabelNet和两个emph ImgNets。 emph LabelNet利用三个完全连接的层,用于捕获图像对之间丰富的语义信息。对于两个emph ImgNets,它们各自采用相同的卷积神经网络结构,但具有不同的权重,即不对称卷积神经网络。两个emph ImgNets用于生成有区别的紧凑哈希码。具体来说,emph LabelNet的功能是捕获丰富的语义信息,用于指导两个emph ImgNets最小化真实连续特征和离散二进制代码之间的差距。通过这样做,textbf ADSQ可以充分利用最关键的语义信息来指导特征学习过程,并考虑公共语义空间和汉明空间的一致性。我们的实验结果表明,textbf ADSQ可以生成高判别性的紧凑哈希码,并且它在三个基准数据集CIFAR 10,NUS WIDE和ImageNet上优于当前最先进的方法。 |
| DNA: Deeply-supervised Nonlinear Aggregation for Salient Object Detection Authors Yun Liu, Deng Ping Fan, Guang Yu Nie, Xinyu Zhang, Vahan Petrosyan, Ming Ming Cheng 显着目标检测的最新进展主要是为了开发如何在卷积神经网络CNN中有效地整合多尺度卷积特征。许多现有技术方法强制执行深度监督以执行侧向输出预测,其被线性地聚合以用于最终显着性预测。在本文中,我们在理论上和实验上证明了侧输出预测的线性聚合是次优的,并且它仅限制了对深度监督所获得的侧输出信息的使用。为了解决这个问题,我们提出了深度监督的非线性聚合DNA,以更好地利用各种侧输出的补充信息。与现有方法相比,它聚合了侧输出特征而不是预测,并且ii采用非线性而非线性变换。实验表明,DNA可以成功突破当前线性方法的瓶颈。具体而言,所提出的显着性检测器,一种带有DNA的改进的U Net架构,在各种数据集和评估指标上都有利于最先进的方法,而不需要花哨。代码和数据将在纸张验收后发布。 |
| Shape Robust Text Detection with Progressive Scale Expansion Network Authors Wenhai Wang, Enze Xie, Xiang Li, Wenbo Hou, Tong Lu, Gang Yu, Shuai Shao 场景文本检测已经取得了快速进展,特别是随着最近卷积神经网络的发展。但是,仍存在两个阻碍算法进入工业应用的挑战。一方面,大多数现有技术算法都需要四边形边界框,这样可以准确地定位任意形状的文本。另一方面,彼此接近的两个文本实例可能导致错误检测,其涵盖两个实例。传统上,基于分割的方法可以缓解第一个问题,但通常无法解决第二个挑战。为了解决这两个挑战,在本文中,我们提出了一种新颖的渐进式扩展网络PSENet,它可以精确地检测任意形状的文本实例。更具体地说,PSENet为每个文本实例生成不同比例的内核,并逐渐将最小比例内核扩展为具有完整形状的文本实例。由于最小尺度内核之间存在大的几何边距,因此我们的方法可以有效地分割紧密文本实例,从而更容易使用基于分割的方法来检测任意形状的文本实例。 CTW1500,Total Text,ICDAR 2015和ICDAR 2017 MLT的大量实验验证了PSENet的有效性。值得注意的是,在CTW1500上,一个充满长曲线文本的数据集,PSENet在27 FPS下实现了74.3的F测量,而我们最好的F测量82.2优于6.6的现有算法。该代码将在未来发布。 |
| Few-Shot Deep Adversarial Learning for Video-based Person Re-identification Authors Lin Wu, Yang Wang, Hongzhi Yin, Meng Wang, Ling Shao, B. C. Lovell 基于视频的人物识别ID是指从任意未对齐的视频片段中跨越相机视图匹配人。现有方法依赖于监督信号来优化投影空间,在该投影空间下,帧间视频之间的距离最小化最小化。然而,这需要在摄像机视图中对人进行详尽的标记,使其无法在大型网络摄像机中进行缩放。此外,注意到,没有明确地解决具有视图不变性的学习有效视频表示,否则哪些特征表现出不同的分布。因此,匹配人物ID的视频需要灵活的模型来捕捉时间序列观察中的动态,并学习视图不变表示以及对有限标记的训练样本的访问。在本文中,我们提出了一种新的基于视频的人物ID的镜头深度学习方法,以学习具有辨别力和视图不变性的可比表示。所提出的方法是在变分递归神经网络VRNNs上开发的,并且经过逆向训练以产生具有时间依赖性的潜在变量,所述时间依赖性具有高度辨别力但在匹配人员中看不变。通过对三个基准数据集进行的大量实验,我们凭经验展示了我们的方法在创建视图不变时间特征和通过我们的方法实现的最新技术性能方面的能力。 |
| DenseAttentionSeg: Segment Hands from Interacted Objects Using Depth Input Authors Zihao Bo, Hang Zhang, Junhai Yong, Feng Xu 我们提出了一种基于DNN的实时技术,用于根据深度输入来分割交互运动的手和对象。我们的模型称为DenseAttentionSeg,它包含一个密集的注意机制,用于融合不同尺度的信息,并通过跳过连接提高结果质量。此外,我们在模型训练中引入轮廓损失,这有助于生成准确的手和物体边界。最后,我们提出并将发布我们的InterSegHands数据集,这是一个包含大约52k手对象交互深度图的精细手部分割数据集。我们的实验评估了我们的技术和数据集的有效性,并表明我们的方法在交互分割方面优于当前最先进的深度分割方法。 |
| Synthesizing a 4D Spatio-Angular Consistent Light Field from a Single Image Authors Andre Ivan, Williem, In Kyu Park 从单个图像合成密集采样的光场对于许多应用是非常有益的。传统方法重建深度图并依赖于基于物理的渲染和辅助网络来改进合成的新颖视图。简单的基于像素的丢失还通过使其依赖于像素强度提示而不是几何推理来限制网络。在这项研究中,我们表明,可以使用不同的几何表示,即外观流,来稳健和直接地合成来自单个图像的光场。提出了一种不需要基于物理的方法或后处理子网的单端到端深度神经网络。提出了两种基于已知光场领域知识的新型损失函数,使网络能够有效地保持子孔径图像之间的空间角度一致性。实验结果表明,该模型成功地合成了密集光场,定性和定量优于以前的模型。该方法可以推广到任意场景,而不是关注特定类别的对象。合成光场可用于各种应用,例如深度估计和重新聚焦。 |
| CUTIE: Learning to Understand Documents with Convolutional Universal Text Information Extractor Authors Xiaohui Zhao, Zhuo Wu, Xiaoguang Wang 从文件(例如收据或发票)中提取关键信息,并将感兴趣的文本保存到结构化数据,对于包括但不限于会计,财务和税收领域的办公自动化的文档密集流程过程至关重要。为了避免为每种特定类型的文档设计专家规则,一些已发表的作品试图通过学习模型来基于NLP字段中的命名实体识别NER方法来探索文本序列中的语义上下文来解决该问题。在本文中,我们建议利用文档中文本的语义和空间分布的有效信息。具体而言,我们提出的模型,卷积通用文本信息提取器CUTIE,在网格文本上应用卷积神经网络,其中文本作为具有语义内涵的特征嵌入。我们进一步探讨了采用不同结构的卷积神经网络的效果,并提出了一种快速便携的结构。我们证明了所提方法在数据集上的有效性,该数据集具有多达6,980个标记收据,无需任何预训练或后期处理,实现了比BERT高得多但只有1 10个参数且不需要3,300M的最先进性能用于预训练的单词数据集。实验结果还表明,CUTIE能够以更少量的训练数据实现最先进的性能。 |
| Local Aggregation for Unsupervised Learning of Visual Embeddings Authors Chengxu Zhuang, Alex Lin Zhai, Daniel Yamins 神经网络中无监督的学习方法对于进一步提高人工智能具有重要意义,因为它们可以在不需要大量昂贵注释的情况下实现网络训练,并且因为它们将是部署的通用学习的更好模型由人类。然而,无监督网络长期落后于其监督对手的表现,特别是在大规模视觉识别领域。最近在训练深度卷积嵌入以最大化非参数实例分离和聚类目标方面的发展已经显示出弥合这一差距的希望。在这里,我们描述了一种方法,该方法训练嵌入函数以最大化局部聚合的度量,使得类似的数据实例在嵌入空间中一起移动,同时允许不同的实例分离。该聚合度量是动态的,允许出现不同尺度的软聚类。我们在几个大规模视觉识别数据集上评估我们的程序,在ImageNet中实现对象识别的无监督转移学习性能,在Places 205中进行场景识别,在PASCAL VOC中进行对象检测。 |
| Lending Orientation to Neural Networks for Cross-view Geo-localization Authors Liu Liu, Hongdong Li 本文研究了基于图像的地理定位IBL问题,利用地面到航空的交叉视图匹配。目标是通过将地面级查询图像与大的地理标记的航空图像数据库(例如,卫星图像)匹配来预测地面级查询图像的空间位置。由于他们的观点和视觉外观的巨大差异,这是一项具有挑战性的任务。针对该问题的现有深度学习方法已经集中于最大化空间上靠近图像对之间的特征相似性,同时最小化远离的其他图像对。他们通过在地面和航拍图像中基于视觉外观的深度特征嵌入来实现这一点。然而,在日常生活中,人们通常使用em方向信息作为空间定位任务的重要线索。受这种见解的启发,本文提出了一种新的方法,它赋予深度神经网络定向的常识。给定地面球形全景图像作为查询输入和大地理参考卫星图像数据库,我们设计了一种连体网络,其明确地编码方向,即图像的每个像素的球面方向。我们的方法显着提高了学习的深层特征的判别力,导致更高的回忆率和精度优于以前的所有方法。与以前性能最佳的网络相比,我们的网络使用的第五个参数数量也更紧凑。为了评估我们方法的推广,我们还创建了一个大规模的跨视图定位基准测试,其中包含覆盖城市的100K地理标记地面空中对。我们的代码和数据集可在网址上找到 |
| ESFNet: Efficient Network for Building Extraction from High-Resolution Aerial Images Authors Jingbo Lin, Houbing Song, Weipeng Jing 从高分辨率航拍图像中提取建筑物足迹始终是城市动态监测,规划和管理的重要组成部分。由于高分辨率航拍图像中的复杂环境和土地覆盖物体,它在遥感研究中也是一项具有挑战性的任务。近年来,深度神经网络在提高遥感图像建筑物提取精度方面取得了很大成就。然而,大多数现有方法通常需要大量参数和浮点运算以获得高精度,这导致高内存消耗和低推理速度,这对研究是有害的。在本文中,我们提出了一种新的深度结构ESFNet,它采用可分离的分解残差块并利用扩张的卷积,旨在保持轻微的精度损失,同时具有较低的计算成本和内存消耗。这是第一次在遥感领域引入深度神经网络的效率视图。我们的ESFNet能够在单个Tesla V100上以超过100 FPS的速度运行,比现有的实时架构ERFNet需要少6倍的FLOP并且参数减少18倍,同时保留相似的精度,无需任何额外的上下文模块,后期处理和预先训练的方案。我们在WHU Building Dataset上评估了我们的网络,并将其与其他最先进的架构进行了比较。结果和综合分析表明,我们的网络有利于高效的遥感研究和应用,并可以进一步扩展到其他领域。该代码是公开的 |
| A Deep Dive into Understanding Tumor Foci Classification using Multiparametric MRI Based on Convolutional Neural Network Authors Weiwei Zong, Joon Lee, Chang Liu, Eric Carver, Aharon Feldman, Branislava Janic, Mohamed Elshaikh, Milan Pantellic, David Hearshen, Indrin Chetty, Benjamin Movsas, Ning Wen 数据稀缺已经抑制了深度学习模型在使用多参数MRI的前列腺图像分析方面取得更大进展。本文开发了一种有效的卷积神经网络CNN,用于对前列腺癌患者的病变恶性肿瘤进行分类,在此基础上系统地分析了模型解释,以弥合自然图像与MR图像之间的差距,这是该类型中的第一个。文献。通过将中间特征馈送到称为加权极端学习机的传统分类算法中来解决并且成功地解决了小样本量的问题,其中考虑了输出类别之间的不平衡分布。在公共数据集上训练的模型能够推广到来自独立机构的数据以进行准确预测。发现生成的显着图与病变良好匹配,可以使临床医生有益于诊断目的。 |
| Relation-aware Graph Attention Network for Visual Question Answering Authors Linjie Li, Zhe Gan, Yu Cheng, Jingjing Liu 为了回答关于图像的语义复杂问题,视觉问题回答VQA模型需要完全理解图像中的视觉场景,尤其是不同对象之间的交互动态。我们提出了一种关系感知图注意网络ReGAT,它将每个图像编码成图形,并通过图形注意机制模拟多类型的对象间关系,以学习问题自适应关系表示。两种类型的视觉对象关系被探索i显式关系,其表示对象之间的几何位置和语义交互,以及ii捕获图像区域之间的隐藏动态的隐式关系。实验表明,ReGAT在VQA 2.0和VQA CP v2数据集上均优于先前的现有技术方法。我们进一步表明ReGAT与现有的VQA架构兼容,并且可以用作通用关系编码器来提升VQA的模型性能。 |
| FrameNet: Learning Local Canonical Frames of 3D Surfaces from a Single RGB Image Authors Jingwei Huang, Yichao Zhou, Thomas Funkhouser, Leonidas Guibas 在这项工作中,我们介绍了从单个RGB图像识别密集规范3D坐标系的新问题。我们观察到图像中的每个像素对应于下面的3D几何中的表面,其中规范框架可以被识别为由三个正交轴表示,一个沿着其法线方向,一个沿着其切线平面。我们提出了一种从RGB预测这些轴的算法。我们的第一个见解是,使用最近引入的方向场合成方法自动计算的规范帧可以为任务提供训练数据。我们的第二个见解是,设计用于表面法线预测的网络在联合训练以预测规范帧时提供更好的结果,并且在训练时甚至更好地预测规范帧的2D投影。我们猜想这是因为规范切线方向的投影经常与图像中的局部梯度对齐,并且因为这些方向通过投影几何和正交性约束与3D规范帧紧密相关。在我们的实验中,我们发现我们的方法可以预测3D规范帧,这些帧可以用于表面法线估计,特征匹配和增强现实等应用。 |
| Attention-Guided Generative Adversarial Networks for Unsupervised Image-to-Image Translation Authors Hao Tang, Dan Xu, Nicu Sebe, Yan Yan 生成性对抗网络中的现有技术方法GAN能够利用不成对的图像数据来学习从一个图像域到另一个图像域的映射函数。但是,这些方法通常会产生伪像,并且只能转换低级信息,但无法传输图像的高级语义部分。原因主要是发生器不具有检测图像的最具辨别力的语义部分的能力,因此使得生成的图像具有低质量。为了处理这种限制,在本文中,我们提出了一种新的注意引导生成对抗网络AGGAN,它可以检测最具辨别力的语义对象,并最大限度地减少语义操作问题中不需要部分的变化,而无需使用额外的数据和模型。 AGGAN中的注意力引导发生器能够通过内置注意机制产生注意力掩模,然后将输入图像与注意力掩模融合以获得高质量的目标图像。此外,我们提出了一种新颖的注意引导鉴别器,它只考虑有人居住的区域提议的AGGAN通过端到端时尚进行训练,具有对抗性损失,周期一致性损失,像素丢失和注意力损失。定性和定量结果都表明,我们的方法可以比现有模型更有效地生成更清晰,更准确的图像。 |
| Multifaceted 4D Feature Segmentation and Extraction in Point and Field-based Datasets Authors Franz Sauer, Kwan Liu Ma 大规模多方面数据的使用在各种科学应用中很常见。在许多情况下,这种多方面的数据采用基于场的欧拉和基于点轨迹的拉格朗日表示的形式,因为每个数据在表征研究系统方面具有一组独特的优势。此外,研究这些多方面数据集的规模和复杂性的增加受到感知能力和可用计算资源的限制,需要复杂的数据缩减和特征提取技术。在这项工作中,我们提出了一种新的4D特征分割提取方案,可以同时对场和点轨迹数据类型进行操作。生成的特征是具有基于字段和基于点的组件的时变数据子集,并且基于来自两种数据类型的底层模式来提取。这使研究人员能够更好地探索两种数据表示之间的空间和时间相互作用,并从新的角度研究潜在的现象。我们使用GPU加速并行化我们的方法,并将其应用于现实世界的多方面数据集,以说明可以提取和探索的功能类型。 |
| Revisiting Local Descriptor based Image-to-Class Measure for Few-shot Learning Authors Wenbin Li, Lei Wang, Jinglin Xu, Jing Huo, Yang Gao, Jiebo Luo 在图像分类中很少有镜头学习旨在学习分类器,以便在每个类只有少数训练样例时对图像进行分类。最近的工作已经取得了很好的分类性能,其中通常使用基于图像级特征的度量。在本文中,我们认为,鉴于少数镜头学习中的例子稀缺,在这样的水平上的度量可能不够有效。相反,我们认为应该采用基于局部描述符的图像到类测量,这是因为它在局部不变特征的鼎盛时期取得了令人惊讶的成功。具体来说,在最近的情节训练机制的基础上,我们提出了一个简短的深度最近邻神经网络DN4,并以端到端的方式训练它。它与文献的主要区别在于通过基于局部描述符的图像到类测量来替换最终层中基于图像级特征的测量。该度量是通过卷积特征映射的深度局部描述符上的k最近邻搜索在线进行的。所提出的DN4不仅学习了图像到类测量的最佳深度局部描述符,而且在示例稀缺的情况下也利用了这种测量的更高效率,这要归功于同一类中的图像之间的视觉模式的可交换性。我们的工作为少数镜头学习提供了一个简单,有效且计算有效的框架。基准数据集的实验研究始终显示出其优于相关技术水平的优势,最大的绝对改进为17。源代码可以从UrlFont获得 |
| Bit-Flip Attack: Crushing Neural Network withProgressive Bit Search Authors Adnan Siraj Rakin, Zhezhi He, Deliang Fan 最近提出了与不同应用和组件相关的深度神经网络DNN的几个重要安全问题。 DNN最广泛调查的安全问题来自其恶意输入,a.k.a对抗性示例。然而,DNN参数的安全性挑战尚未得到很好的探索。在这项工作中,我们首先提出了一种名为Bit Flip Attack BFA的新型DNN重量攻击方法,它可以通过在其重量存储存储器系统(即DRAM)中恶意翻转极少量的位来破坏神经网络。位翻转操作可以通过众所周知的Row Hammer攻击进行,而我们的主要贡献是开发一种算法,将存储在存储器中的最脆弱的DNN权重参数位识别为二进制位,这可以最大限度地降低精度降级翻转。我们提出的BFA利用逐行比特搜索PBS方法,该方法结合梯度排序和逐行搜索来识别要翻转的最脆弱的比特。在PBS的帮助下,我们可以成功地攻击ResNet 18完全故障,即前1个精度仅从93.8到0.1中通过13位翻转从69.8降低到0.1,而随机翻转100位只会使精度降低不到1。 |
| Improving Object Detection with Inverted Attention Authors Zeyi Huang, Wei Ke, Dong Huang 改善物体探测器以防止遮挡,模糊和噪声是在实际应用中部署探测器的关键步骤。由于不可能通过数据收集来消除所有图像缺陷,因此许多研究人员试图在训练中生成硬样本。生成的硬样本是图像或特征映射,其中在空间维度中丢弃了粗糙的补丁。在训练额外的硬样本和/或使用额外的网络分支估计丢失补丁时需要大量的开销。在本文中,我们使用称为Inverted Attention IA的高效细粒机制改进了物体探测器。与仅关注物体主导部分的原始探测器网络不同,具有IA的探测器网络迭代地反转对特征图的关注,并且更多地关注互补对象部分,特征通道甚至上下文。我们的方法1沿着特征图2的空间和通道维度操作,不需要对硬样本的额外训练,没有额外的网络参数用于注意力估计,并且没有测试开销。实验表明,我们的方法在基准数据库上不断改进了两级和单级检测器。 |
| SpaceNet MVOI: a Multi-View Overhead Imagery Dataset Authors Nicholas Weir, David Lindenbaum, Alexei Bastidas, Adam Van Etten, Sean McPherson, Jacob Shermeyer, Varun Kumar, Hanlin Tang 在听到的图像中检测和分割对象是一项具有挑战性的任务。顶部图像中的对象的可变密度,随机取向,小尺寸和实例异构性要求不同于为自然场景数据集设计的现有模型的方法。虽然正在开发新的高架图像数据集,但它们几乎普遍包含从最低点直接开销的单个视图,未能解决一个关键变量视角。相比之下,现实世界的头顶图像中的视图各不相同,特别是在动态场景中,例如自然灾害,其中第一次看起来往往超过最低点40度。这代表了对计算机视觉方法的重要挑战,因为改变视角会增加失真,改变分辨率和改变照明。目前,这些扰动对算法检测和对象分割的影响尚未得到证实。为了解决这个问题,我们引入了SpaceNet多视图架空图像MVOI数据集,这是SpaceNet开源遥感数据集的扩展。 MVOI包括27种独特的外观,从32到54度的广泛视角。这些图像中的每一个都覆盖相同的地理位置,并使用126,747个建筑物足迹标签进行注释,从而可以直接评估视点扰动对模型性能的影响。我们对1个建筑物检测,2个概括到不可见的视角和分辨率,以及建筑物足迹提取对分辨率变化的敏感性进行基准测试。我们发现分割和对象检测模型很难识别出最低点图像中的建筑物,并且很难概括为看不见的视图,这是探索在视觉动态环境中检测小型异构目标对象的广泛相关挑战的重要基准。 |
| Learning to Transfer Examples for Partial Domain Adaptation Authors Zhangjie Cao, Kaichao You, Mingsheng Long, Jianmin Wang, Qiang Yang 域适应对于在新的和看不见的环境中学习至关重要。通过域对抗性训练,深度网络可以学习解缠结和可转移的特征,从而有效地减少源域和目标域之间的数据集转换,从而进行知识转移。在大数据时代,大规模标记数据集的现成可用性激发了对部分域适应PDA的广泛兴趣,PDA将识别器从标记的大域转移到未标记的小域。它将标准域适应扩展到目标标签仅是源标签子集的场景。在目标标签未知的情况下,PDA的关键挑战是如何在共享类中转移相关示例以促进正向转移,并忽略特定类中的不相关示例以减轻负转移。在这项工作中,我们提出了一种统一的方法,即PDA,示例传输网络ETN,它共同学习源域和目标域的域不变表示,以及渐进式加权方案,量化源示例的可转移性,同时控制它们对学习任务的重要性在目标域中。对几个基准数据集的全面评估表明,我们的方法实现了部分域适应任务的最新结果。 |
| The Algorithmic Automation Problem: Prediction, Triage, and Human Effort Authors Maithra Raghu, Katy Blumer, Greg Corrado, Jon Kleinberg, Ziad Obermeyer, Sendhil Mullainathan 在广泛的领域中,算法匹配并超越人类专家的表现,从而考虑人类判断和算法预测在这些领域中的作用。然而,围绕这些发展的讨论隐含地将预测的具体任务与自动化的一般任务等同起来。我们在此论证,自动化不仅仅是对人工与算法性能的比较,还涉及决定首先给予算法的任务实例。我们开发了一个通用框架,将后一个决策作为一个优化问题,我们展示了这个优化问题的基本启发式方法如何能够在医学中大量研究AI的应用中获得性能提升。我们的框架还强调了有效的自动化如何关键地依赖于逐个实例地估算算法和人为错误,我们的结果表明这些错误估计问题的改进如何能够为自动化带来显着的收益。 |
| All about Structure: Adapting Structural Information across Domains for Boosting Semantic Segmentation Authors Wei Lun Chang, Hui Po Wang, Wen Hsiao Peng, Wei Chen Chiu 在本文中,我们针对语义分割任务解决了无监督域自适应的问题,其中我们尝试将在具有地面实况标签的合成数据集上学习的知识转移到没有任何注释的真实世界图像。假设图像的结构内容是语义分割中最具信息性和决定性的因素,并且可以跨域轻松共享,我们提出了一种域不变结构提取DISE框架,将图像分解为域不变结构和域特定纹理表示,可以进一步实现跨域的图像转换,并启用标签转移以提高分割性能。大量实验验证了我们提出的DISE模型的有效性,并证明了其优于几种最先进的方法。 |
| Counting with Focus for Free Authors Zenglin Shi, Pascal Mettes, Cees G. M. Snoek 本文旨在计算图像中的任意对象。领先的计数方法从每个对象的点注释开始,从中构造密度图。然后,他们的训练目标通过深度卷积网络将输入图像转换为密度图。我们认为点注释比仅仅构建密度图更有助于监督目的。我们介绍了免费重新利用积分的方法。首先,我们提出了来自分割的监督焦点,其中点被转换为二进制映射。二进制映射与网络分支和伴随的丢失函数组合以关注感兴趣的区域。其次,我们提出了来自全局密度的监督焦点,其中点注释与图像像素的比率用于另一个分支以规范整体密度估计。为了协助密度估计和分割焦点,我们还为点注释引入了改进的内核大小估计器。对四个数据集的实验表明,无论基础网络如何,我们所有的贡献都会减少计数误差,从而导致仅使用单个网络的现有技术精度。最后,我们是第一个依靠WIDER FACE,让我们展示我们的方法在处理不同对象比例和拥挤程度方面的好处。 |
| On the Anatomy of MCMC-based Maximum Likelihood Learning of Energy-Based Models Authors Erik Nijkamp, Mitch Hill, Tian Han, Song Chun Zhu, Ying Nian Wu 本研究调查了无监督最大似然ML学习中马尔可夫链蒙特卡罗MCMC采样的影响。我们的注意力仅限于家庭非标准化概率密度,其负对数密度或能量函数是ConvNet。总的来说,我们发现用于稳定先前研究中的训练的大多数技术可能产生相反的效果。只需少量超参数且无正则化,即可实现具有ConvNet潜力的稳定ML学习。通过这个最小的框架,我们根据MCMC抽样的实施确定了各种ML学习成果。 |
| Amortized Object and Scene Perception for Long-term Robot Manipulation Authors Ferenc Balint Benczedi, Michael Beetz 移动机器人在人类环境中执行长期操纵活动,必须感知具有非常不同视觉特性的各种物体,并且需要在整个任务执行期间可靠地跟踪这些物体。为了提高效率,机器人感知能力需要超出当前可感知的能力,并且应该能够回答关于当前和过去场景的查询。在本文中,我们研究了一种用于长期机器人操纵的感知系统,该系统可以跟踪不断变化的环境并构建感知世界的表示。具体来说,我们引入了一个摊销组件,在整个执行周期中传播感知任务。由此产生的查询驱动感知系统异步地将记录图像的结果整合成符号和数字,我们称之为子符号表示,形成机器人的感知信念状态。 |
| Generative Adversarial Networks: recent developments Authors Maciej Zamorski, Adrian Zdobylak, Maciej Zi ba, Jerzy wi tek 在传统的生成建模中,良好的数据表示通常是良好的机器学习模型的基础。它可以链接到编码隐藏在原始数据中的更多解释因素的良好表示。随着生成对抗网络GAN的发明,生成对抗网络GAN是能够以无监督和半监督方式学习表示的生成模型的子类,我们现在能够对比地学习从简单的先前分布到目标数据分布的良好映射。本文概述了GAN的最新发展,重点是学习潜在空间表示。 |
| Benchmarking Neural Network Robustness to Common Corruptions and Perturbations Authors Dan Hendrycks, Thomas Dietterich 在本文中,我们建立了严格的图像分类器稳健性基准。我们的第一个基准ImageNet C标准化并扩展了损坏稳健性主题,同时展示了哪些分类器在安全关键应用中更受欢迎。然后我们提出了一个名为ImageNet P的新数据集,它使研究人员能够对分类器对常见扰动的鲁棒性进行基准测试。与最近的稳健性研究不同,该基准评估了常见腐败和扰动的表现,而不是最坏情况下的对抗性扰动。我们发现从AlexNet分类器到ResNet分类器的相对损坏稳健性的变化可以忽略不计。之后,我们发现了增强腐败和扰动稳健性的方法。我们甚至发现绕过的对抗性防御提供了实质性的共同扰动稳健性。我们的基准可以共同帮助未来的工作向强大推广的网络发展。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pixabay.com