第二讲 cs224n系列之word2vec & 词向量
文章目录
- 系列目录(系列更新中)
- 1.语言模型
- 2.word2vec
- 2.1.CBOW与Skip-Gram模式关系
- 3 Skip-gram基本模型
- 3.1 相关公式
- 3.2 Skipgram框架结构
- 3.4 相关推导
- 4 训练优化
- 参考文献
本系列是一个基于深度学习的NLP教程,2016年之前叫做CS224d: Deep Learning for Natural Language Processing,之后改名为CS224n: Natural Language Processing with Deep Learning。新版主讲人是泰斗Chris Manning和Richard Socher(这是旧版的讲师),两人分别负责不同的章节。博主在学习的同时,对重点内容做成系列教程,与大家分享!
系列目录(系列更新中)
-
第一讲 初识深度模型 Neural Networks Tutorial – A Pathway to Deep Learning
(这里引用一篇我觉得特别棒的深度学习入门教程,超级详细,墙裂推荐) -
第二讲 cs224n系列之word2vec & 词向量
-
word2vec进阶之skim-gram和CBOW模型(Hierarchical Softmax、Negative Sampling)
-
第三讲 cs224n系列之skip-pram优化 & Global Vector by Manning & 词向量评价
1.语言模型
神经概率语言模型(Neural Probabilistic Language Model)中词的表示是向量形式、面向语义的。两个语义相似的词对应的向量也是相似的,具体反映在夹角或距离上。甚至一些语义相似的二元词组中的词语对应的向量做线性减法之后得到的向量依然是相似的。词的向量表示可以显著提高传统NLP任务的性能,例如《基于神经网络的高性能依存句法分析器》中介绍的词、词性、依存关系的向量化对正确率的提升等。
2.word2vec
word2vec是一个计算word vector的开源工具。当我们在说word2vec算法或模型的时候,其实指的是其背后用于计算word vector的CBoW模型和Skip-gram模型。很多人以为word2vec指的是一个算法或模型,这也是一种谬误。
词向量的早期编码方式我们一般叫做1-of-N representation或者one hot representation. 比如我们有下面的5个词组成的词汇表,词"Queen"的序号为2, 那么它的词向量就是(0,1,0,0,0)(0,1,0,0,0)。同样的道理,词"Woman"的词向量就是(0,0,0,1,0) (0,0,0,1,0). One hot representation用来表示词向量非常简单,但是却有很多问题。最大的问题是我们的词汇表一般都非常大,比如达到百万级别,这样每个词都用百万维的向量来表示简直是内存的灾难。这样的向量其实除了一个位置是1,其余的位置全部都是0,表达的效率不高.
Dristributed representation可以解决One hot representation的问题,它的思路是通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。当然在实际情况中,我们并不能对词向量的每个维度做一个很好的解释。具体词向量的样子在后面Skip-grams框架中有讲解。
word2vec作为神经概率语言模型的输入,其本身其实是神经概率模型的副产品,是为了通过神经网络学习某个语言模型而产生的中间结果。具体来说,“某个语言模型”指的是“CBOW”和“Skip-gram”。具体学习过程会用到两个降低复杂度的近似方法——Hierarchical Softmax或Negative Sampling。两个模型乘以两种方法,一共有四种实现。
根据上面说的整理如下:
- Skip-grams (SG):预测上下文
- Continuous Bag of Words (CBOW):预测目标单词
两种稍微高效一些的训练方法:
- Hierarchical softmax
- Negative sampling
下文介绍算法中的 Skip-grams (SG),也就是说通过一个word预测context(上下文)
2.1.CBOW与Skip-Gram模式关系
word2vec主要分为CBOW(Continuous Bag of Words)和Skip-Gram两种模式。CBOW是从原始语句推测目标字词;而Skip-Gram正好相反,是从目标字词推测出原始语句。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。
对同样一个句子:Hangzhou is a nice city。我们要构造一个语境与目标词汇的映射关系,其实就是input与label的关系。
这里假设滑窗尺寸为1(滑窗尺寸……这个……不懂自己google吧-_-|||)
CBOW可以制造的映射关系为:[Hangzhou,a]—>is,[is,nice]—>a,[a,city]—>nice
Skip-Gram可以制造的映射关系为(is,Hangzhou),(is,a),(a,is), (a,nice),(nice,a),(nice,city)
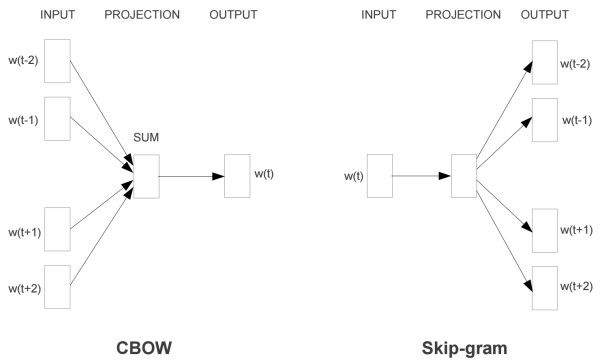
3 Skip-gram基本模型
原理图:

注意这里虽然有四条线,但模型中只有一个条件分布(因为这只是个词袋模型而已,与位置无关)。学习就是要最大化这些概率。
3.1 相关公式
J ( θ ) = ∏ t = 1 T ∏ − m ≤ j ≤ m 且 j ≠ 0 p ( w t + j ∣ w t ; θ ) J(\theta) = \prod_{t=1}^{T} \prod_{-m\leq j \leq m 且 j \neq 0 } p(w_{t+j}|w_t;\theta) J(θ)=t=1∏T−m≤j≤m且j̸=0∏p(wt+j∣wt;θ)
要最大化目标函数。对其取个负对数,得到损失函数——对数似然的相反数:
Negative log likelihood:
J ( θ ) = − 1 T ∑ t = 1 T ∑ − m ≤ j ≤ m 且 j ≠ 0 l o g { p ( w t + j ∣ w t ) } J(\theta) = - \frac{1}{T} \sum_{t=1}^{T} \sum_{-m\leq j \leq m 且 j \neq 0 } log \{ p(w_{t+j}|w_t)\} J(θ)=−T1t=1∑T−m≤j≤m且j̸=0∑log{p(wt+j∣wt)}
这些术语都是一样的:Loss function = cost function = objective function,不用担心用错了。对于softmax来讲,常用的损失函数为交叉熵。
其中:
某个上下文条件概率 p ( w t + j ∣ w t ; θ ) p(w_{t+j}|w_t;\theta) p(wt+j∣wt;θ)可由softmax得到:

这里的o是outside(或者output)单词索引(下标),c是中心词的索引(下标), v c v_c vc和 u c u_c uc是中心词c和outside(或者output)词o对应的词向量 (这里的outside或者output其实就是上下文中的单词)
点积也有点像衡量两个向量相似度的方法,两个向量越相似,其点积越大。
softmax之所叫softmax,是因为指数函数会导致较大的数变得更大,小数变得微不足道;这种选择作用类似于max函数。
3.2 Skipgram框架结构
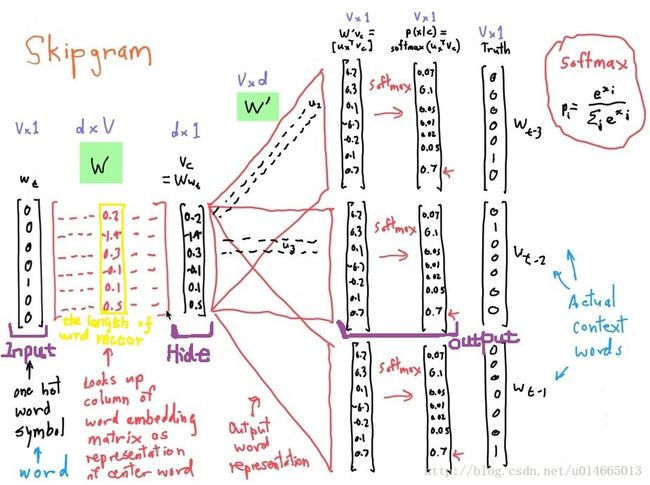
从左到右是one-hot向量,乘以center word的W于是找到词向量,乘以另一个context word的矩阵W’得到对每个词语的“相似度”,对相似度取softmax得到概率,与答案对比计算损失。
这两个矩阵都含有V个词向量,也就是说同一个词有两个词向量,哪个作为最终的、提供给其他应用使用的embeddings呢?有两种策略,要么加起来,要么拼接起来。在CS224n的编程练习中,采取的是拼接起来的策略
最终我们就是要求两个矩阵W和W’,一般是把这些参数写进 θ \theta θ,有

由于上述两个矩阵的原因,所以θθ的维度中有个2。
####3.3 Skipgram框架相关细节
我们如何来表示这些单词呢?首先,我们都知道神经网络只能接受数值输入,我们不可能把一个单词字符串作为输入,因此我们得想个办法来表示这些单词。最常用的办法就是基于训练文档来构建我们自己的词汇表(vocabulary)再对单词进行one-hot编码。
假设从我们的训练文档中抽取出10000个唯一不重复的单词组成词汇表。我们对这10000个单词进行one-hot编码,得到的每个单词都是一个10000维的向量,向量每个维度的值只有0或者1,假如单词ants在词汇表中的出现位置为第3个,那么ants的向量就是一个第三维度取值为1,其他维都为0的10000维的向量(ants=[0, 0, 1, 0, …, 0])。
还是上面的例子,“The dog barked at the mailman”,那么我们基于这个句子,可以构建一个大小为5的词汇表(忽略大小写和标点符号):(“the”, “dog”, “barked”, “at”, “mailman”),我们对这个词汇表的单词进行编号0-4。那么”dog“就可以被表示为一个5维向量[0, 1, 0, 0, 0]。
模型的输入如果为一个10000维的向量,那么输出也是一个10000维度(词汇表的大小)的向量,它包含了10000个概率,每一个概率代表着当前词是输入样本中output word的概率大小。
下图是我们神经网络的结构:

隐层没有使用任何激活函数,但是输出层使用了sotfmax。
我们基于成对的单词来对神经网络进行训练,训练样本是 ( input word, output word ) 这样的单词对,input word和output word都是one-hot编码的向量。最终模型的输出是一个概率分布。
隐层
说完单词的编码和训练样本的选取,我们来看下我们的隐层。如果我们现在想用300个特征来表示一个单词(即每个词可以被表示为300维的向量)。那么隐层的权重矩阵应该为10000行,300列(隐层有300个结点)。
Google在最新发布的基于Google news数据集训练的模型中使用的就是300个特征的词向量。词向量的维度是一个可以调节的超参数(在Python的gensim包中封装的Word2Vec接口默认的词向量大小为100, window_size为5)。
看下面的图片,左右两张图分别从不同角度代表了输入层-隐层的权重矩阵。左图中每一列代表一个10000维的词向量和隐层单个神经元连接的权重向量。从右边的图来看,每一行实际上代表了每个单词的词向量。
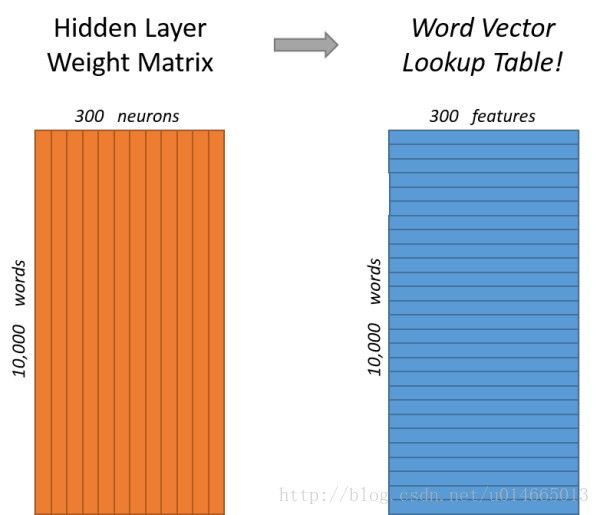
所以我们最终的目标就是学习这个隐层的权重矩阵。
我们现在回来接着通过模型的定义来训练我们的这个模型。
上面我们提到,input word和output word都会被我们进行one-hot编码。仔细想一下,我们的输入被one-hot编码以后大多数维度上都是0(实际上仅有一个位置为1),所以这个向量相当稀疏,那么会造成什么结果呢。如果我们将一个1 x 10000的向量和10000 x 300的矩阵相乘,它会消耗相当大的计算资源,为了高效计算,它仅仅会选择矩阵中对应的向量中维度值为1的索引行(这句话很绕),看图就明白。

我们来看一下上图中的矩阵运算,左边分别是1 x 5和5 x 3的矩阵,结果应该是1 x 3的矩阵,按照矩阵乘法的规则,结果的第一行第一列元素为0 x 17 + 0 x 23 + 0 x 4 + 1 x 10 + 0 x 11 = 10,同理可得其余两个元素为12,19。如果10000个维度的矩阵采用这样的计算方式是十分低效的。
为了有效地进行计算,这种稀疏状态下不会进行矩阵乘法计算,可以看到矩阵的计算的结果实际上是矩阵对应的向量中值为1的索引,上面的例子中,左边向量中取值为1的对应维度为3(下标从0开始),那么计算结果就是矩阵的第3行(下标从0开始)—— [10, 12, 19],这样模型中的隐层权重矩阵便成了一个”查找表“(lookup table),进行矩阵计算时,直接去查输入向量中取值为1的维度下对应的那些权重值。隐层的输出就是每个输入单词的“嵌入词向量”。
输出层
经过神经网络隐层的计算,ants这个词会从一个1 x 10000的向量变成1 x 300的向量,再被输入到输出层。输出层是一个softmax回归分类器,它的每个结点将会输出一个0-1之间的值(概率),这些所有输出层神经元结点的概率之和为1。
下面是一个例子,训练样本为 (input word: “ants”, output word: “car”) 的计算示意图。

3.4 相关推导




上面蓝色字体说还需要output求偏导,这个确实是,但是我感觉上面的对中心词求的时候应该前面还需要求和的,以为公式里还有一个 ∑ \sum ∑,有待验证!!!
这样最后就剩下递归下降求了,小白自行百度!
4 训练优化
了解了上面的原理,你可能会注意到,这个训练过程的参数规模非常巨大。假设语料库中有30000个不同的单词,hidden layer取128,word2vec两个权值矩阵维度都是[30000,128],在使用SGD对庞大的神经网络进行学习时,将是十分缓慢的。而且,你需要大量的训练数据来调整许多权重,避免过度拟合。数以百万计的重量数十亿倍的训练样本意味着训练这个模型将是一个野兽。
一般来说,有Hierarchical Softmax、Negative Sampling等方式来解决。这就是在开始的时候列出来的方法,现在知道为什么了吧!
在下一篇文章中我将对skip-pram中的negative sampling进行详细说明
参考文献
- Word2Vec-语言模型的前世今生
- 一文详解 Word2vec 之 Skip-Gram 模型
这篇文章超级通俗易懂,很经典 - word2vec原理推导与代码分析
本贴详细描述了SG、CBOW、Hierarchical Softmax、Negative Sampling四种方法 - CS224n笔记2 词的向量表示:word2vec
- word2vec原理(一) CBOW与Skip-Gram模型基础