Tinyhttpd源码分析与总结
一、概念
httpd是Apache(HTTP)服务器的主程序。被设计为一个独立运行的后台进程,它会建立一个处理请求的子进程或线程的池。
cgi模式(web server和CGI的交互模式):httpd接收到一个动态请求就fork一个cgi进程,cgi进程返回结果给httpd进程后自我销毁。简单说明CGI和动态请求是什么
二、Tinyhttpd源码分析
1、转自【源码剖析】tinyhttpd —— C 语言实现最简单的 HTTP 服务器:
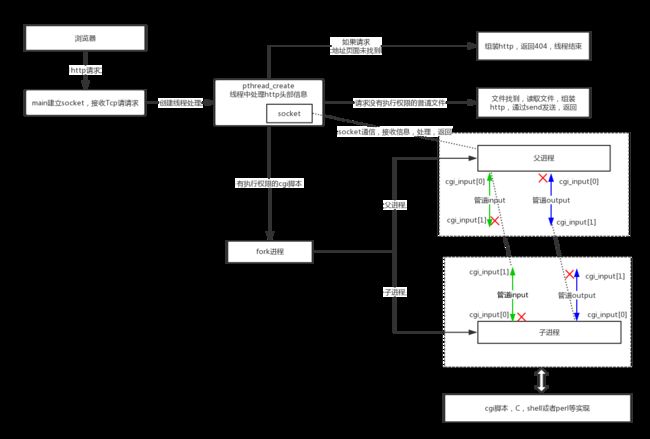
工作流程:
(1) 服务器启动,在指定端口或随机选取端口绑定 httpd 服务。
(2)收到一个 HTTP 请求时(其实就是 listen 的端口 accpet 的时候),派生一个线程运行 accept_request 函数。
(3)取出 HTTP 请求中的 method (GET 或 POST) 和 url。对于 GET 方法,如果有携带参数,则 query_string 指针指向 url 中 ? 后面的 GET 参数。
(4) 格式化 url 到 path 数组,表示浏览器请求的服务器文件路径,在 tinyhttpd 中服务器文件是在 htdocs 文件夹下。当 url 以 / 结尾,或 url 是个目录,则默认在 path 中加上 index.html,表示访问主页。
(5)如果文件路径合法,对于无参数的 GET 请求,直接输出服务器文件到浏览器,即用 HTTP 格式写到套接字上,然后跳到(10)。其他情况(带参数 GET,POST 方式,url 为可执行文件),则调用 excute_cgi 函数执行 cgi 脚本。
(6)读取整个 HTTP 请求并丢弃,如果是 POST 则找出 Content-Length. 把 HTTP 200 状态码写到套接字。
(7) 建立两个管道,cgi_input 和 cgi_output, 并 fork 一个进程。
(8) 在子进程中,把 STDOUT 重定向到 cgi_outputt 的写入端,把 STDIN 重定向到 cgi_input 的读取端,关闭 cgi_input 的写入端 和 cgi_output 的读取端,设置 request_method 的环境变量,GET 的话设置 query_string 的环境变量,POST 的话设置 content_length 的环境变量,这些环境变量都是为了给 cgi 脚本调用,接着用 execl 运行 cgi 程序。
(9) 在父进程中,关闭 cgi_input 的读取端 和 cgi_output 的写入端,如果 POST 的话,把 POST 数据写入 cgi_input,已被重定向到 STDIN,读取 cgi_output 的管道输出到客户端,该管道输入是 STDOUT。接着关闭所有管道,等待子进程结束。
(10) 关闭与浏览器的连接,完成了一次 HTTP 请求与回应,因为 HTTP 是无连接的。
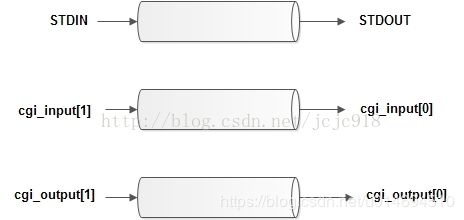


2、采用先MSG_PEEK的方式读缓冲进行预先读和分析
int get_line(int sock, char *buf, int size)
{
int i = 0;
char c = '\0';
int n;
while ((i < size - 1) && (c != '\n'))
{
n = recv(sock, &c, 1, 0);
/* DEBUG printf("%02X\n", c); */
if (n > 0)
{
if (c == '\r')
{
n = recv(sock, &c, 1, MSG_PEEK); //预先读和分析
/* DEBUG printf("%02X\n", c); */
if ((n > 0) && (c == '\n'))
recv(sock, &c, 1, 0);
else
c = '\n'; //只有'\r'时也当成回车换行逻辑"\r\n"
}
buf[i] = c;
i++;
}
else
c = '\n';
}
buf[i] = '\0';
return(i);
}recv的原型是ssize_t recv(int s, void *buf, size_t len, int flags); 通常flags都设置为0,此时recv函数读取tcp buffer中的数据到buf中,并从tcp buffer中移除已读取的数据。把flags设置为MSG_PEEK,仅把tcp buffer中的数据读取到buf中,并不把已读取的数据从tcp buffer中移除,再次调用recv仍然可以读到刚才读到的数据。
针对一次读取一个字符的场景,recv的MSG_PEEK参数就发挥作用。 查看到"\r"之后,n = recv(sock, &c, 1, MSG_PEEK); 查看下一个字符是否是"\n",是就读取(并移除)数据。
3、在多线程执行的情况下调用fork()函数
在多线程执行的情况下调用fork()函数,仅会将发起调用的线程复制到子进程中。(子进程中该线程的ID与父进程中发起fork()调用的线程ID是一样的,因此,线程ID相同的情况有时我们需要做特殊的处理。)也就是说不能同时创建出于父进程一样多线程的子进程。其他线程均在子进程中立即停止并消失,并且不会为这些线程调用清理函数以及针对线程局部存储变量的析构函数。
这将导致下列一些问题:fork()和多线程
由于这些问题,推荐在多线程程序中调用fork()的唯一情况是:其后立即调用exec()函数执行另一个程序,彻底隔断子进程与父进程的关系。由新的进程覆盖掉原有的内存,使得子进程中的所有pthreads对象消失。
fork()函数的调用会导致在子进程中除调用线程外的其它线程全都终止执行并消失,因此在多线程的情况下会导致死锁和内存泄露的情况。在进行多线程编程的时候尽量避免fork()的调用,同时在程序在进入main函数之前应避免创建线程,因为这会影响到全局对象的安全初始化。线程不应该被强行终止,因为这样它就没有机会调用清理函数来做相应的操作,同时也就没有机会来释放已被锁住的锁,如果另一线程对未被解锁的锁进行加锁,那么将会立即发生死锁,从而导致程序无法正常运行。
4、无名管道作为进程间通信IPC的原理
fork()+pipe() --> 父子进程间通过管道通信:
fork之后,操作系统会复制一个与父进程完全相同的子进程。这2个进程共享代码空间,但是数据空间是互相独立的,子进程数据空间中的内容是父进程的完整拷贝,指令指针也完全相同,子进程拥有父进程当前运行到的位置(两进程的程序计数器pc值相同。也就是说,子进程是从fork返回处开始执行的)。
两个进程通过一个管道只能实现单向通信,如果有时候也需要子进程写父进程读,就必须另开一个管道。管道的读写端通过打开的文件描述符来传递,因此要通信的两个进程必须从它们的公共祖先那里继承管道文件描述符。也就是需要通过fork传递文件描述符使两个进程都能访问同一管道,它们才能通信。
至于为什么父进程关闭管道的读文件描述符filedes[0]后子进程还能读取管道的数据,是因为系统维护的是一个文件的文件描述符表的计数,文件表中的每一项都会维护一个引用计数,标识该表项被多少个文件描述符(fd)引用,在引用计数为0的时候,表项才会被删除。所以调用close(fd)关闭子进程的文件描述符,只会减少引用计数,但是不会使文件表项被清除,所以父进程依旧可以访问。
5、HTTP报文
请求端(客户端)的HTTP报文叫做请求报文,响应端(服务器端)的叫做响应报文。HTTP报文本身是由多行(CR+LF作换行符'\r\n')数据构成的字符串文本。
请求报文和响应报文的结构:
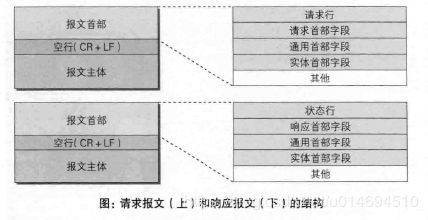

具体地:应用层(HTTP)
(1)请求报文
-
请求行(只有一行)
结构:method uri version
-
请求头(多行)
在HTTP/1.1中,请求头除了Host都是可选的。包含的头五花八门,这里只介绍部分。
-
空行(一行)
-
可选消息体(多行)
(2)响应报文
-
状态行(只有一行)
结构:version status_code status_message
-
响应头(多行)
-
空行(一行)
-
信息体(多行)
实际有效数据,通常是HTML格式的文件,该文件被浏览器获取到之后解析呈现在浏览器中。
6、CGI与环境变量
-
CGI程序
服务器为客户端提供动态服务首先需要解决的是得到用户提供的参数再根据参数信息返回。为了和客户端进行交互,服务器需要先创建子进程,之后子进程执行相应的程序去为客户服务。CGI正是帮助我们解决参数获取、输出结果的。
动态内容获取其实请求报文的头部和请求静态数据时完全相同,但请求的资源从静态的HTML文件变成了后台程序。服务器收到请求后fork()一个子进程,子进程执行请求的程序,这样的程序称为CGI程序(Python、Perl、C++等均可)。通常在服务器中我们会预留一个单独的目录(cgi-bin)用来存放所有的CGI程序,请求报文头部中请求资源的前缀都是/cgi-bin,之后加上所请求调用的CGI程序即可。
所以上述流程就是:客户端请求程序 -> 服务器fork()子进程 -> 执行被请求程序。接下来需要解决的问题就是如何获取客户端发送过来的参数和输出信息怎么传递回客户端。
-
环境变量
对CGI程序来说,CGI环境变量在创建时被初始化,结束时被销毁。当CGI程序被HTTP服务器调用时,因为是被服务器fork()出来的子进程,所以其继承了其父进程的环境变量,这些环境变量包含了很多基本信息,请求头中和响应头中列出的内容(比如用户Cookie、客户机主机名、客户机IP地址、浏览器信息等),CGI程序所需要的参数也在其中。
-
GET方法下参数获取
服务器把接收到的参数数据编码到环境变量QUERY_STRING中,在请求时只需要直接把参数写到URL最后即可,比如"http:127.0.0.1:80/cgi-bin/test?a=1&b=2&c=3",表示请求cgi-bin目录下test程序,'?'之后部分为参数,多个参数用'&'分割开。服务器接收到请求后环境变量QUERY_STRING的值即为a=1&b=2&c=3。
在CGI程序中获取环境变量值的方法是:getenv(),比如我们需要得到上述QUERY_STRING的值,只需要下面这行语句就可以了。
char *value = getenv("QUERY_STRING");之后对获得的字符串处理一下提取出每个参数信息即可。
-
POST方法下参数获取
POST方法下,CGI可以直接从服务器标准输入获取数据,不过要先从CONTENT_LENGTH这个环境变量中得到POST参数长度,再获取对应长度内容。随后从服务器标准输出传输结果数据。
-
参考资料
应用层(HTTP)
httpd服务
HTTP服务器的本质:tinyhttpd源码分析及拓展
Tinyhttpd精读解析