全面深入了解python(一)
全面深入了解python(一)
写在开始前,此教程不是基础教程,在看之前你需要有一定的python基础,不然你可能无法理解教程到底教了哪些东西。
环境:python版本是3.6.5(>=3.4即可)
1. Python数据模型
数据模型其实是对Python框架的描述,它规范了这门语言自身构建模块的接口,这些模块包括但不限于序列、迭代器、函数、类和上下文管理器。
Python解释器碰到特殊的句法时,会使用特殊方法去激活一些基本的对象操作,这些特殊方法的名字以两个下划线开头,以两个下划线结尾(例如__getitem__)。比如obj[key]的背后就是__getitem__方法,为了能求得my_collection[key]的值,解释器实际上会调用my_collection.__getitem__(key)。
上面说的特殊方法其实有个昵称,可能你以前就听过,叫做魔术方法。这些魔术方法能让你自己的对象实现和支持以下的语言结构,并与之交互:
- 迭代
- 集合类
- 属性访问
- 运算符重载
- 函数和方法的调用
- 对象的创建和销毁
- 字符串表示形式和格式化
- 管理上下文(即with块)
1.1 一叠Python风格的纸牌
接下来用一个非常简单的例子来展示如何实现__getitem__和__len__这两个特殊方法,通过这个例子我们也能见识到特殊方法的强大。
import collections
Card = collections.namedtuple('Card',['rank','suit'])
class OrderCard:
ranks = [str(n) for n in range(2,11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Card(rank,suit) for suit in self.suits for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]
首先,我们用collections.namedtuple构建了一个简单的类来表示一张纸牌。自Python 2.6开始,namedtuple就加入到Python里,用以构建只有少数属性但是没有方法的对象,比如数据库条目。使用终端进行样例的输入,利用namedtuple,我们可以很轻松地得到一个纸牌对象:
>>> beer_card = Card('7','diamonds')
>>> beer_card
Card(rank='7', suit='diamonds')
当然,我们这个例子主要还是关注OrderCard这个类,很短小精悍。首先,它跟任何标准Python集合类型一样,可以用len()函数来查看一叠牌有多少张:
>>> order_card = OrderCard()
>>> len(order_card)
52
从一叠牌中抽取特定的一张纸牌,比如说第一张或者最后一张,是很容易的:order_card[0]或order_card[-1]。这都是由__getitem__方法提供的:
>>> order_card[0]
Card(rank='2', suit='spades')
>>> order_card[-1]
Card(rank='A', suit='hearts️')
我们需要单独写一个方法用来随机抽取一张纸牌吗?没必要,Python已经内置了从一个序列中随机选出一个元素的函数random.choice,我们直接把它用在这一叠纸牌实例上就好:
>>> from random import choice
>>> choice(order_card)
Card(rank='8', suit='spades')
>>> choice(order_card)
Card(rank='3', suit='hearts️')
>>> choice(order_card)
Card(rank='Q', suit='hearts️')
现在已经可以体会到通过实现魔术方法来利用Python数据模型的两个好处。
- 作为你的类的用户,他们不必去记住标准操作的各种名称(“怎么得到元素的总数?是.size()还是.length()还是别的什么?”)
- 可以更加方便地利用Python的标准库,比如random.choice函数,从而不用重新发明轮子。
因为__getitem__方法把[]操作交给了self._cards列表,所以我们的deck类自动支持切片(slicing)操作。下面列出了查看一叠牌最上面3张和只看排面是K的牌的操作。其中第二种操作的具体方法是,先抽出索引是11的那张牌,然后每隔13张牌拿1张:
>>> order_card[:3]
[Card(rank='2', suit='spades'), Card(rank='3', suit='spades'), Card(rank='4', suit='spades')]
>>> order_card[11::13]#前面是索引,后面是步长
[Card(rank='K', suit='spades'), Card(rank='K', suit='diamonds️'), Card(rank='K', suit='clubs️'), Card(rank='K', suit='hearts️')]
另外,仅仅实现了__getitem__方法,这一叠牌就变成可迭代的了:
>>> for card in order_card:
... print(card)
Card(rank='2', suit='spades')
Card(rank='3', suit='spades')
Card(rank='4', suit='spades')
...
反向迭代也没关系:
>>> for card in reversed(order_card):
... print(card)
Card(rank='A', suit='hearts️')
Card(rank='K', suit='hearts️')
Card(rank='Q', suit='hearts️')
...
迭代通常是隐式的,比如说一个集合类型没有实现__contains__方法,那么in运算符就会按顺序做一次迭代搜索。于是,in运算符可以用在我们的OrderCard类上,因为它是可迭代的:
>>> Card('3','spades') in order_card
True
>>> Card('K','test') in order_card
False
那么排序呢?我们用点数来判定扑克牌的大小,2最小、A最大;同时还要加上对花色的判定,黑桃最大、红桃次之、方块再次、梅花最小。下面就是按照这个规则来给扑克牌排序的函数,梅花2的大小是0,黑桃A是51:
suit_values = dict(spades=3,hearts=2,diamonds=1,clubs=0)
def spades_high(card):
rank_value = OrderCard.ranks.index(card.rank)
return rank_value * len(suit_values) + suit_values[card.suit]
有了spades_high函数,就能对这叠牌进行升序排序了:
>>> for card in sorted(order_card,key=spades_high):
... print(card)
Card(rank='2', suit='clubs')
Card(rank='2', suit='diamonds')
Card(rank='2', suit='hearts')
...
Card(rank='A', suit='diamonds')
Card(rank='A', suit='hearts')
Card(rank='A', suit='spades')
虽然OrderCard隐式地继承了object类,但功能却不是继承而来的。我们通过数据模型和一些合成来实现这些功能。通过实现__len__和__getitem__这两个特殊方法,OrderCard就跟一个Python自由的序列数据类型一样,可以体现出Python的核心语言特性(例如迭代和切片)。同时这个类还可以用于标准库中如:random.choice、reversed和sorded这些函数。另外,对合成的运用使__len__和__getitem__的具体实现可以代理给self._cards
这个python列表(即list对象)。
1.2 如何使用特殊方法(魔术方法)
首先明确一点,魔术方法的存在是为了被python解释器调用的,你自己并不需要调用它们。也就是说没有my_object.__len__()这种写法,而应该使用len(my_object)。在执行len(my_object)的时候,如果my_object是一个自定义类的对象,那么python会自己去调用其中由你实现的__len__方法。
通常代码中无需直接使用魔术方法,除非有大量的元编程存在,唯一的例外是经常使用__init__方法,目的是在代码的子类的__init__方法中调用超类的构造器。通过内置函数(len、iter、str等等)来使用魔术方法是最好的选择,这些内置函数不仅会调用魔术方法,对于内置类来说,运行它们速度更快。
还有一点,不要自己想当然的随意添加魔术方法,比如__foo__之类的,因为现在没有被Python内部使用,不代表以后不被用。
来实现一个二维向量(vector)类,这里的向量就是欧几里得几何中常用的概念,常在数学和物理中使用。
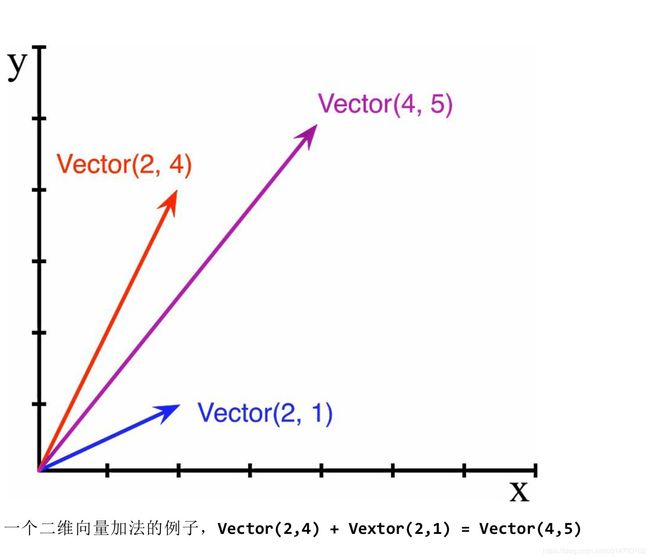
python内置的complex类可以用来表示向量,但是我们自定义的类可以扩展到n维向量。
自定义Vector类:
from math import hypot
class Vector:
def __init__(self,x=0,y=0):
self.x = x
self.y = y
def __repr__(self):
return f'Vector({self.x},{self.y})' # 3.6新功能,新的格式化方式
def __abs__(self):
return hypot(self.x,self.y)
def __bool__(self):
return bool(abs(self))
def __add__(self, other):
x = self.x + other.x
y = self.y + other.y
return Vector(x,y)
def __mul__(self, scalar):
return Vector(self.x * scalar, self.y * scalar)
把上图的样例实现出来:
>>> v1 = Vector(2,4)
>>> v2 = Vector(2,1)
>>> v1 + v2
Vector(4,5)
通过+运算符所得到的结果也是一个向量,而且结果会被控制台友善的打印出来。
abs是一个内置函数,如果输入是整数或者浮点数,返回值是输入值的绝对值,输入值是复数,返回值应该是该复数的模,因此定义该函数时,也应该返回该向量的模:
>>> v = Vector(3,4)
>>> abs(v)
5.0
我们还可以利用*运算符来实现向量的标量乘法:
>>> v * 3
Vector(9,12)
>>> abs(v * 3)
15.0
实现的Vector类中是由:__repr__、__abs__、__add__、__mul__这些特殊方法实现。但是在上述使用中发现除了__init__会被使用之外,其他的魔术方法是被python解释器直接调用,而不是自己使用代码调用。(上文已经提过)
1.3 为什么len不是普通方法
如果x是一个内置类型的实例,那么len(x)的速度会非常快,背后的原因是CPython会直接从一个C结构体里读取对象的长度,完全不会调用任何方法。获取一个集合中元素的数量是一个很常见的操作,在str、list、memoryview等类型上,这个操作必须高效。
c语言中的结构体里可以存储这个对象的相关数据信息,是其属性,可以直接读取。例:
struct Articles
{
char title[50]; //文章标题
char author[50]; //文章作者
char subject[100]; //文章主题
int article_length; //文章长度
int article_id; //文章编号
} article;