1. 距离的量度
1) 距离
距离的定义是一个宽泛的概念:只要满足非负、自反、三角不等式就可以称之为距离。其中非负是指任意两个相异点的距离为正;自反是Dis(y,x)=Dis(x,y);三角不等式是Dis(x,z)<=Dis(x,y)+Dis(y,z)
2) 马氏距离(闵可夫斯基距离)
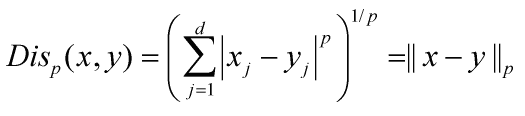
其中d是维数,p是阶数,也称为p范数。
当p=1时,是曼哈顿距离
当p=2时,是欧氏距离
当p→∞时,是切比雪夫距离
当p=0时,是海明距离
3) 欧氏距离
两点间的直线距离(一般用两条竖线||w||代表w的2范数)代入公式:
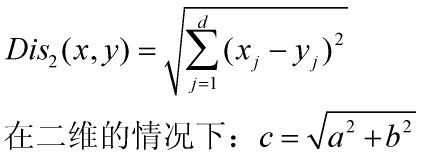
4) 曼哈顿距离(城市街区距离)
各坐标数值差的和,就像汽车只能行驶在横平竖直的街道上,代入公式:
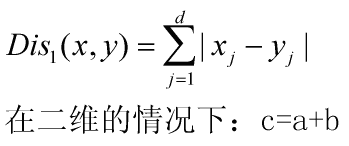
5) 切比雪夫距离
各坐标数值差的最大值,当马氏距离的p→∞时,最终的结果取决于距离最大的维度上的距离:
Dis∞=maxj|xj-yj|
在二维的情况下:c=max(a,b)
6) 海明距离
L0范数并不是一个真正的范数,它主要被用来度量向量中非零元素的个数。
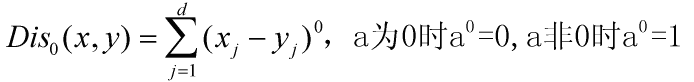
7) 总结
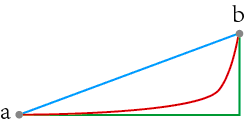
图片从上到下依次显示a与b点的三种距离:欧氏距离(蓝色),切比雪夫距离(红色),曼哈顿距离(绿色)
2. 范数
范数是一种强化了的距离概念,根据马氏距离的公式,把x,y两点间的距离看作一个向量z

||z||p是向量z的p范数,也记作Lp范数。
范数包括向量范数和矩阵范数,向量范数表征向量空间中向量的大小,矩阵范数表征矩阵引起变化的大小。上面我们看到的就是L0, L1, L2, L∞范数的计算方法。
机器学习中常使用范数防止过拟合,它可以计量模型的大小(复杂度),作为惩罚项加入公式,通过迭代计算,在误差和复杂度之间制衡,如公式:
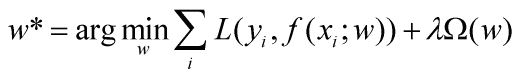
其中x是自变量,y是结果,w是参数,通过f(x;w)预测y’,L(y,y’)求真实值与预测值的误差,Ω是惩罚项,λ是惩罚项的系数。目标是求误差最小时参数w的取值。
和上一次SVM篇中讲到的一样,这也是在条件Ω下求误差L极小值的问题,还是拉格朗日乘子法,用系数λ把两式连在一起,变为简单的求极值问题。
3. KNN(K近邻)算法
1) K近邻
存在一个样本数据集合(训练集),并且样本集中每个数据都存在标签,输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征相比较,然后提取样本集中特征最相似的前K个数据的分类标签。
算法参考K个距离最近的训练样例,并整合多个目标值,对于分类问题,最简单的方法是投票法,也可以预测各个类别的概率分布,对于回归问题,可取均值,或按距离加权等。
简言之,K近邻就是根据距离实例最近的范例来判定新实例的类别或估值。
K近邻可处理分类和回归问题。它需要记忆全部训练样本,空间复杂度高,计算复杂度高,优点是对异常值不敏感,精度高,但当样本少噪声大时也会过拟合。
对于K值的选择,一般情况下,起初随着K增加,分类器的性能会快速提升,但K大到某一点时,性能又会下降,因此需要谨慎选择的K值,也有一些自动计算K值的方法,后面说。
2) 步骤
i. 计算欧氏距离
ii. 按距离排序
iii. 选取距离最小的k个点
iv. 确定k点中各分类的出现概率
v. 返回出现概率最高的分类
3) 例程
i. 功能
根据训练集中的四个实例,对新数据[1.2, 1.3]分类
ii. 代码
# -*- coding: utf-8 -*-
from numpy import *
import operator
def classify(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize, 1)) - dataSet #求inX与训练集各个实例的差
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5 # 求欧式距离
sortedDistIndicies = distances.argsort() # 取排序的索引,用于排label
classCount={}
for i in range(k):
voteILabel = labels[sortedDistIndicies[i]]
classCount[voteILabel]=classCount.get(voteILabel,0)+1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0] # 取最多的分类
group = array([[1,1.1],[1,1],[0,0],[0,0.1]]) # 训练集
labels = ['A','A','B','B'] # 训练集分类
print classify([1.2,1.3], group, labels, 3) # 对数据点[0,0]分类
iii. 分析
例程中没有调库,直接用python实现了KNN,主要为了解原理,实际操作中一般使用sklearn库中的sklearn.neighbors.NearestNeighbors类。
4. K-means聚类算法
1) K-means:
K-means(K均值)聚类,其中k是用户指定的要创建的簇的数目,算法以k个随机质心开始,计算每个点到质心的距离,每个点会被分配到距其最近的簇质心,然后基于新分配到的簇的点更新质心,以上过程重复数次,直到质心不再改变。
该算法能保证收敛到一个驻点,但不能保证能得到全局最优解,受初始质心影响大。可采用一些优化方法,比如先将所有点作为一个簇,然后使用k-均值(k=2)进行划分,下一次迭代时,选择有最大误差的簇进行划分,重复到划分为k个簇为止。
该算法在数据多的时候,计算量大,需要采取一些优化方法,比如一开始计算时只取部分数据。
聚类方法常用于无监督学习,给无标签的数据分类;根据质心的原理也可实现有监督学习中的分类和回归。
2) 评价聚类
聚类常用于无监督学习,那么如何评价聚类的好坏呢?这里使用了散度。
散度(divergence)可用于表征空间各点矢量场发散的强弱程度,给定数据矩阵X,散度矩阵定义为:
其中μ是均值,散度可以理解为各点相对于均值的发散程度。
当数据集D被划分为多个簇D1,D2…Dk时,μj为簇Dj的均值,Sj为簇Dj的散度矩阵,B为将D中各点替换为相应簇均值uj后的散度矩阵。
无论是否划分,整体的散度S不变,它由各个簇内部的散度Sj和各均值相对于整体的散度B组成的。
我们聚簇的目标是增大B,减少各个Sj,就是让簇内部的点离均值更近,各簇间的距离更远。该公式(求散度矩阵的迹)可以作为评价聚类质量的量度。
3) 例程:
i. 功能
用sklearn提供的KMeans类实现聚类功能,并画图
ii. 代码
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
plt.figure()
random_state = 170
X,y = make_blobs(n_samples=200,random_state=random_state) # 使用sklearn提供的数据
y_pred = KMeans(n_clusters=3,random_state=random_state).fit_predict(X)
plt.scatter(X[:,0],X[:,1],c=y_pred)
plt.show()
5. 使用注意事项
基于距离的算法实际应用中,需要做一些预处理,以便达到更好的效果:
属性多时,最好先降维,以免无意义数据淹没有意义数据。
使用之前最好做直方图分析,查看样本的密集区域。
使用之前需要对各个属性做标准化,以免值大的属性有更大权重。
使用之前最好根据经验对各属性分配不同的权重。
对于无法直接分开的数据,可以考虑使用核函数转换后再计算距离。
6. 算法之间的关系
线性回归,logistic回归,支持向量机,KNN,K-Means都属于基于距离的模型。下面以分类问题为例,看看它们之间的关系。
假设我们有一个训练数据集(xi,yi),需要预测数据a属于哪个分类,在对数据毫无先验知识的情况下:
我们可能会找一个和a最相近的x,然后把a预测成x对应的分类y,这就是最近邻;
如果觉得一个x不保险(万一它是噪声数据呢),找离它最近的k个点x,看看它们对应的y属性大多数属于哪个分类y,这就是k近邻;
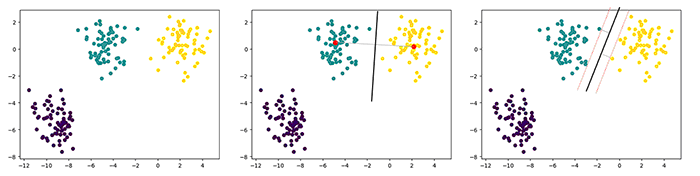
如果我们估计这些数据可以被分成一簇一簇(左图),而不是混在一起的,那我们可以用K-Means先把它分成几簇,看a属性哪一簇,然后按簇预测,这样只保存簇心点及该簇对应的分类即可,可以简化数据存储和计算量;
如果不同的簇刚好对应不同的分类,也就是说不同分类在空间上是分离的,那么计算两个簇的质心(中图),连接两个质心(灰线),在连线中间做垂线(黑色),把两类分开,就是logistic回归/线性回归,这样就不需要保存实例,而保存直线参数即可分类;
如果计算直线的时候,考虑到直线到两类的边界(右图),就是SVM支持向量机,它保存边界上的实例和直线的参数,以提供更多的信息。
簇还可以和决策树结合,按照距离把相近的簇合二为一;如果考虑到数据在欧氏空间中的概率分布,还可以在概率模型和几何模型之建立联系……