Redis简介,部署与Redis 主从复制
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都 支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排 序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文 件,并且在此基础上实现了master-slave(主从)同步。
Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部 分场合可以对关系数据库起到很好的补充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。
Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复 制。存盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布 记录。同步对读取操作的可扩展性和数据冗余很有帮助。
数据模型
编辑
Redis的外围由一个键、值映射的字典构成。与其他非关系型数据库主要不同在于:Redis中值的类型 [1] 不仅限于字符串,还支持如下抽象数据类型:
-
字符串列表
-
无序不重复的字符串集合
-
有序不重复的字符串集合
-
键、值都为字符串的哈希表 [1]
值的类型决定了值本身支持的操作。Redis支持不同无序、有序的列表,无序、有序的集合间的交集、并集等高级服务器端原子操作。
数据结构
编辑
redis提供五种数据类型:string,hash,list,set及zset(sorted set)。
string(字符串)
string是最简单的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value,其上支持的操作与Memcached的操作类似。但它的功能更丰富。
redis采用结构sdshdr和sds封装了字符串,字符串相关的操作实现在源文件sds.h/sds.c中。
数据结构定义如下:
| 1 2 3 4 5 6 |
|
list(双向链表)
list是一个链表结构,主要功能是push、pop、获取一个范围的所有值等等。操作中key理解为链表的名字。
对list的定义和实现在源文件adlist.h/adlist.c,相关的数据结构定义如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
dict(hash表)
set是集合,和我们数学中的集合概念相似,对集合的操作有添加删除元素,有对多个集合求交并差等操作。操作中key理解为集合的名字。
在源文件dict.h/dict.c中实现了hashtable的操作,数据结构的定义如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
dict中table为dictEntry指针的数组,数组中每个成员为hash值相同元素的单向链表。set是在dict的基础上实现的,指定了key的比较函数为dictEncObjKeyCompare,若key相等则不再插入。
zset(排序set)
zset是set的一个升级版本,他在set的基础上增加了一个顺序属性,这一属性在添加修改元素的时候可以指定,每次指定后,zset会自动重新按新的值调整顺序。可以理解了有两列的mysql表,一列存value,一列存顺序。操作中key理解为zset的名字。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
zset利用dict维护key -> value的映射关系,用zsl(zskiplist)保存value的有序关系。zsl实际是叉数
不稳定的多叉树,每条链上的元素从根节点到叶子节点保持升序排序。
存储
编辑
redis使用了两种文件格式:全量数据和增量请求。
全量数据格式是把内存中的数据写入磁盘,便于下次读取文件进行加载;
增量请求文件则是把内存中的数据序列化为操作请求,用于读取文件进行replay得到数据,序列化的操作包括SET、RPUSH、SADD、ZADD。
redis的存储分为内存存储、磁盘存储和log文件三部分,配置文件中有三个参数对其进行配置。
save seconds updates,save配置,指出在多长时间内,有多少次更新操作,就将数据同步到数据文件。这个可以多个条件配合,比如默认配置文件中的设置,就设置了三个条件。
appendonly yes/no ,appendonly配置,指出是否在每次更新操作后进行日志记录,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为redis本身同步数据 文件是按上面的save条件来同步的,所以有的数据会在一段时间内只存在于内存中。
appendfsync no/always/everysec ,appendfsync配置,no表示等操作系统进行数据缓存同步到磁盘,always表示每次更新操作后手动调用fsync()将数据写到磁盘,everysec表示每秒同步一次。
安装
编辑
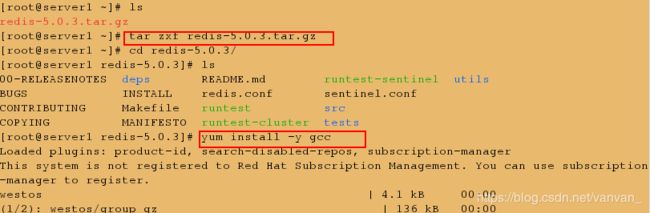
获取源码、解压、进入源码目录
server1,2,3 操作相同:
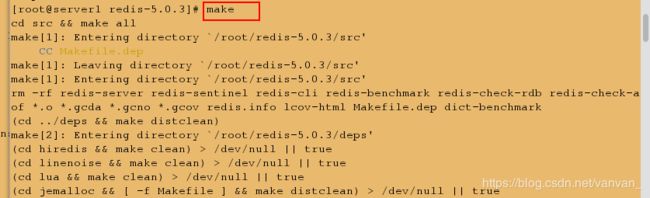
编译生成可执行文件
由于makefile文件已经写好,我们只需要直接在源码目录执行make命令进行编译即可:

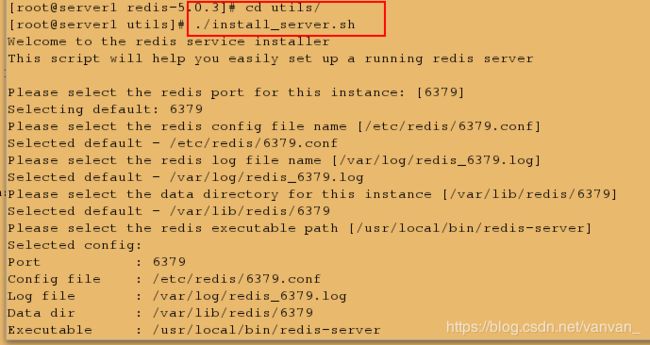
make命令执行完成后,会在当前目录下生成本个可执行文件,分别是redis-server、redis-cli、redis-benchmark、redis-stat,它们的作用如下:
redis-server:Redis服务器的daemon启动程序
redis-cli:Redis命令行操作工具。当然,你也可以用telnet根据其纯文本协议来操作
redis-benchmark:Redis性能测试工具,测试Redis在你的系统及你的配置下的读写性能
redis-stat:Redis状态检测工具,可以检测Redis当前状态参数及延迟状况。
配置参数
在我们成功安装Redis后,我们直接执行redis-server即可运行Redis,此时它是按照默认配置来运行的(默认配置甚至不是后台运 行)。我们希望Redis按我们的要求运行,则我们需要修改配置文件,Redis的配置文件就是我们上面第二个cp操作的redis.conf文件,它被 我们拷贝到了/usr/local/redis/etc/目录下。修改它就可以配置我们的server了。如何修改?下面是redis.conf的主要配 置参数的意义:
daemonize:是否以后台daemon方式运行
pidfile:pid文件位置
port:监听的端口号
timeout:请求超时时间
loglevel:log信息级别
logfile:log文件位置
databases:开启数据库的数量
save * *:保存快照的频率,第一个*表示多长时间,第二个*表示执行多少次写操作。在一定时间内执行一定数量的写操作时,自动保存快照。可设置多个条件。
rdbcompression:是否使用压缩
dbfilename:数据快照文件名(只是文件名,不包括目录)
dir:数据快照的保存目录(这个是目录)
appendonly:是否开启appendonlylog,开启的话每次写操作会记一条log,这会提高数据抗风险能力,但影响效率。
appendfsync:appendonlylog如何同步到磁盘(三个选项,分别是每次写都强制调用fsync、每秒启用一次fsync、不调用fsync等待系统自己同步)
Redis常用内存优化手段与参数
通过我们上面的一些实现上的分析可以看出redis实际上的内存管理成本非常高,即占用了过多的内存,作者对这点也非常清楚,所以提供了一系列的参数和手段来控制和节省内存,我们分别来讨论下。
首先最重要的一点是不要开启Redis的VM选项,即虚拟内存功能,这个本来是作为Redis存储超出物理内存数据的一种数据在内存与磁盘换入换出的一 个持久化策略,但是其内存管理成本也非常的高,并且我们后续会分析此种持久化策略并不成熟,所以要关闭VM功能,请检查你的redis.conf文件中 vm-enabled 为 no。
其次最好设置下redis.conf中的maxmemory选项,该选项是告诉Redis当使用了多少物理内存后就开始拒绝后续的写入请求,该参数能很好的保护好你的Redis不会因为使用了过多的物理内存而导致swap,最终严重影响性能甚至崩溃。
另外Redis为不同数据类型分别提供了一组参数来控制内存使用,我们在前面详细分析过Redis Hash是value内部为一个HashMap,如果该Map的成员数比较少,则会采用类似一维线性的紧凑格式来存储该Map, 即省去了大量指针的内存开销,这个参数控制对应在redis.conf配置文件中下面2项:
-
hash-max-zipmap-entries 64
-
hash-max-zipmap-value 512
-
hash-max-zipmap-entries
含义是当value这个Map内部不超过多少个成员时会采用线性紧凑格式存储,默认是64,即value内部有64个以下的成员就是使用线性紧凑存储,超过该值自动转成真正的HashMap。
hash-max-zipmap-value 含义是当 value这个Map内部的每个成员值长度不超过多少字节就会采用线性紧凑存储来节省空间。
以上2个条件任意一个条件超过设置值都会转换成真正的HashMap,也就不会再节省内存了,那么这个值是不是设置的越大越好呢,答案当然是否定 的,HashMap的优势就是查找和操作的时间复杂度都是O(1)的,而放弃Hash采用一维存储则是O(n)的时间复杂度,如果
成员数量很少,则影响不大,否则会严重影响性能,所以要权衡好这个值的设置,总体上还是最根本的时间成本和空间成本上的权衡。
同样类似的参数
list-max-ziplist-entries 512
说明:list数据类型多少节点以下会采用去指针的紧凑存储格式。
list-max-ziplist-value 64
说明:list数据类型节点值大小小于多少字节会采用紧凑存储格式。
set-max-intset-entries 512
说明:set数据类型内部数据如果全部是数值型,且包含多少节点以下会采用紧凑格式存储。
最后想说的是Redis内部实现没有对内存分配方面做过多的优化,在一定程度上会存在内存碎片,不过大多数情况下这个不会成为Redis的性能瓶颈,不 过如果在Redis内部存储的大部分数据是数值型的话,Redis内部采用了一个shared integer的方式来省去分配内存的开销,即在系统启动时先分配一个从1~n 那么多个数值对象放在一个池子中,如果存储的数据恰好是这个数值范围内的数据,则直接从池子里取出该对象,并且通过引用计数的方式来共享,这样在系统存储 了大量数值下,也能一定程度上节省内存并且提高性能,这个参数值n的设置需要修改源代码中的一行宏定义REDIS_SHARED_INTEGERS,该值 默认是10000,可以根据自己的需要进行修改,修改后重新编译就可以了。
另外redis 的6种过期策略redis 中的默认的过期策略是volatile-lru 。设置方式
config set maxmemory-policy volatile-lru
maxmemory-policy 六种方式
volatile-lru:只对设置了过期时间的key进行LRU(默认值)
allkeys-lru : 是从所有key里 删除 不经常使用的key
volatile-random:随机删除即将过期key
allkeys-random:随机删除
volatile-ttl : 删除即将过期的
noeviction : 永不过期,返回错误
maxmemory-samples 3 是说每次进行淘汰的时候 会随机抽取3个key 从里面淘汰最不经常使用的(默认选项)
主从复制
redis的复制功能是支持多个数据库之间的数据同步。一类是主数据库(master)一类是从数据库(slave),
主数据库可以进行读写操作,当发生写操作的时候自动将数据同步到从数据库,而从数据库一般是只读的,
并接收主数据库同步过来的数据,一个主数据库可以有多个从数据库,而一个从数据库只能有一个主数据库。
部署主从复制
环境准备:
server1: 172.25.60.1 (主)
server2: 172.25.60.2 (从)1.server1/2修改redis可访问IP本机->0.0.0.0
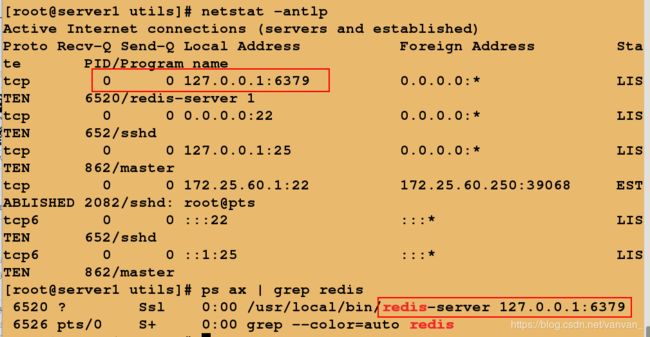


2.server2

配置复制源ip 与端口
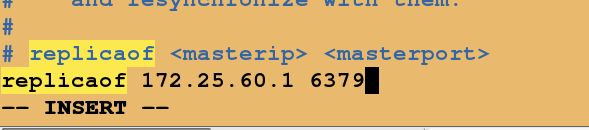
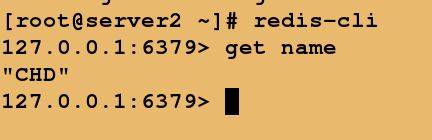
测试:
server1 写入name的k-v数据
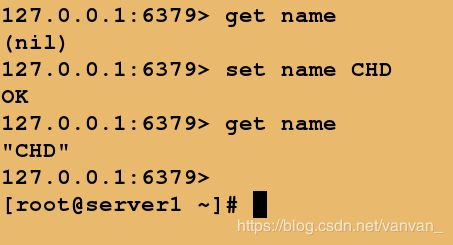
server2 实时获取server1同步的数据