MySQL数据库字符集utf8如何转utf8mb4
这几天开发的项目需要把Emoji 表情保存到数据库,原来的Mysql数据库的编码是utf8的,这就导致保存的时候报如下错误:
java.sql.SQLException: Incorrect string value: '\xF0\x9F\x92\x95\xF0\x9F...' for column…………
mysql的utf8并不是真正意义上的utf8,mysql的utf8只支持最长三个字节,所以Emoji 表情和有些生僻字以及任何新增的 Unicode 字符等如果超过三个字节用utf8字符集保存是会报错的。mysql在5.5.3之后增加了utf8mb4这个字符集,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。好在utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需要做其他转换。
为了获取更好的兼容性,应该总是使用 utf8mb4 而非 utf8. 对于 CHAR 类型数据,utf8mb4 会多消耗一些空间,根据 Mysql 官方建议,使用 VARCHAR 替代 CHAR。
因为mysql的char列类型在utf8mb4下, 为了保证所有的数据都存的下, char将会占用字符数*4的字节数 (mysql的char列类型utf8将占用字符数*3的字节数), 以保证空间分配足够. 所以建议用可变长度varchar, 以节省空间. 可变长度消耗的存储空间为: 实际存储需要的字节数+1或2个字节表达的长度。
使用utf8mb4要求:
1.MySQL版本要求:不低于5.5.3(mysql是在5.5.3之后增加了utf8mb4这个字符集)
2.JDBC驱动版本要求:mysql connector版本高于5.1.13可以使用如下sql查看数据库及服务器的字符集/编码集情况:
show variables like '%character%';
show variables like 'collation%';
将数据库和已经建好的表也转换成utf8mb4
更改数据库编码(字符集):ALTER DATABASE DATABASE_NAME DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
更改表编码(字符集)(注意:这里修改的是表的字符集,表里面字段的字符集并没有被修改):ALTER TABLE TABLE_NAME DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
更改表编码(字符集)和表中所有字段的编码(字符集):
ALTER TABLE TABLE_NAME CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
批量修改表和表字段编码的方法:
MySQL批量修改数据表的字符集:https://blog.csdn.net/vfsdfdsf/article/details/90287305
MySQL批量修改数据表和数据表中所有字段的字符集:https://blog.csdn.net/vfsdfdsf/article/details/90484891
修改字符集为utf8mb4的sql语句如下(下面的语句只对当前session有效,是临时性的,永久性的请修改MySQL配置文件):
/*来自客户端的语句的字符集*/
set character_set_client = utf8mb4;
/*建立连接使用的字符集*/
set character_set_connection = utf8mb4;
/*默认数据库使用的字符集。当默认数据库更改时,服务器则设置该变量。如果没有默认数据库,变量的值同character_set_server*/
set character_set_database = utf8mb4;
/*用于向客户端返回查询结果的字符集*/
set character_set_results = utf8mb4;
/*服务器的默认字符集*/
set character_set_server=utf8mb4;
修改MySQL配置文件
(修改MySQL配置文件是后面操作另外一个库的时候补充上来的,所以这里的utf8mb4_unicode_ci和下面截图中的utf8mb4_general_ci,有不一致的地方,朋友们根据自己的需求设置就是了。utf8mb4_unicode_ci和utf8mb4_general_ci的区别只是排序规则的不同,字符集都是utf8mb4,排序规则根据自身需求选择即可)
修改mysql配置文件my.cnf(windows为my.ini,我的windows下my.ini文件在C:\ProgramData\MySQL\MySQL Server 5.7目录)
我的my.cnf放在/etc/my.cnf位置。找到后请在以下三部分里添加如下内容:
[client]
default-character-set = utf8mb4
[mysql]
default-character-set = utf8mb4
[mysqld]
character-set-client-handshake = FALSE
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
init_connect='SET NAMES utf8mb4'
截图如下(最后一句是忽略表名大小写的,有需要的可以配置上):
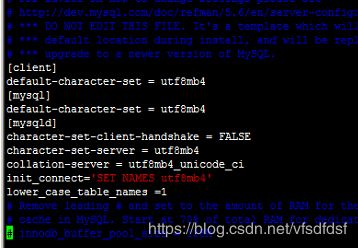
修改完成后记得重启mysql:
Linux:
service mysql restart
或者
service mysqld restartWindows:
net stop mysql
net start mysql停止命令:net stop mysql
启动命令:net start mysql
不同的操作系统重启数据库方式不同,如果以上命令不管用,请根据操作系统在网上搜索命令
修改前的数据库和服务器字符集我没有截图保存,下面贴上修改后的截图
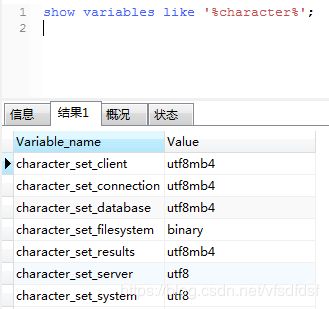
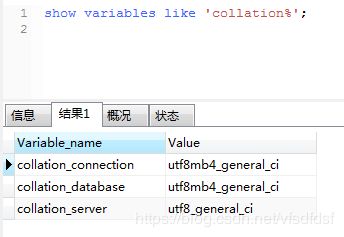
下面贴上上面各个参数的解释:
character_set_client
来自客户端的语句的字符集。
character_set_connection
建立连接使用的字符集。
character_set_database
默认数据库使用的字符集。当默认数据库更改时,服务器则设置该变量。如果没有默认数据库,变量的值同character_set_server
character_set_results
用于向客户端返回查询结果的字符集。
character_set_ server
服务器的默认字符集。
character_set_system
服务器用来保存识别符的字符集。该值一定是utf8。
character_sets_dir
字符集安装目录。
collation_connection
连接字符集的校对规则。
collation_database
默认数据库使用的校对规则。当默认数据库改变时服务器则设置该变量。如果没有默认数据库,变量的值同collation_server。
collation_server
服务器的默认校对规则。
程序重新连接数据库,应该是可以保存成功了。
如果修改完成后,代码中保存还是报错的话那就要修改连接数据库的配置了。
本人使用的是阿里巴巴的druid数据库连接池:
我在DruidDataSource配置中新增了如下配置:
jdbc数据库连接参数设置:
删除了如下参数:useUnicode\=true&characterEncoding\=utf-8
characterEncoding=utf8其实是会自动识别为utf8mb4,也可以不加这个参数,会自动检测。
而autoReconnect=true是必须加上的。
如果本文有什么错误的地方烦请指出!
如果有问题可以留言,希望本文可以帮助有需要的人。
记得点赞哟!