GPU编程--CPU和GPU的设计区别
本篇结构
- 前言
- 概论
- CPU简介
- GPU简介
- 并行计算
- CPU/GPU对比
- 适于GPU计算的场景
- GPU开发环境
- 参考博文
一、前言
因为工作需要,需要从github上找一个CUDA的DBSCAN聚类实现,刚开始从github上获取到的代码只支持二维数据,为了适配多维数据,要对代码简单改造,这就需要了解CUDA编程模式。之前没有接触过GPU编程相关概念,甚至于没有学过c语言,加上脑袋笨重,费了好些功夫,才让CUDA DBSCAN运行起来。
为了方便自己后面回顾,所以将涉及到的知识点简单串联起来,并加以记录。
如果可以,也希望给其他朋友一些can参考(肯定是有很多不足,还望海涵)。
二、概论
由于其设计目标的不同,GPU和CPU分别针对了两种不同的应用场景。
CPU需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理。这些都使得CPU的内部结构异常复杂。
而GPU面对的则是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境。
于是CPU和GPU就呈现出非常不同的架构(图可以从CUDA官网找到https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#axzz4YFZTibzg):
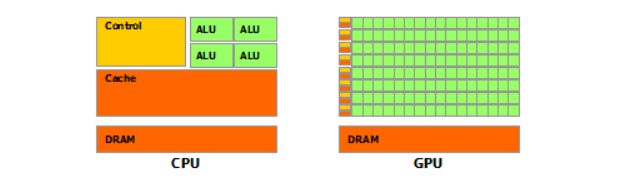
三、CPU简介
CPU (Central Processing Unit) 即中央处理器,是机器的“大脑”,也是布局谋略、发号施令、控制行动的“总司令官”。
CPU的结构主要包括运算器(ALU, Arithmetic and Logic Unit)、控制单元(CU, Control Unit)、寄存器(Register)、高速缓存器(Cache)和它们之间通讯的数据、控制及状态的总线。
CPU是基于低延时的设计,简单来说包括:计算单元、控制单元和存储单元,架构可参考下图:
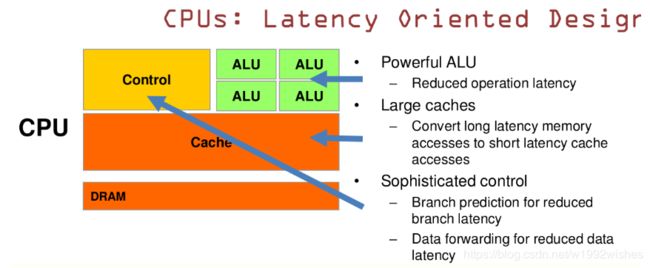
CPU的特点是:
(1)CPU有强大的ALU(算术运算单元),它可以在很少的时钟周期内完成算术计算
当今的CPU可以达到64bit 双精度。执行双精度浮点源算的加法和乘法只需要1~3个时钟周期(CPU的时钟周期的频率是非常高的,达到1.532~3gigahertz(千兆HZ, 10的9次方))。
(2)大的缓存可以降低延时
保存很多的数据放在缓存里面,当需要访问的这些数据,只要在之前访问过的,如今直接在缓存里面取即可。
(3)复杂的逻辑控制单元
当程序含有多个分支的时候,它通过提供分支预测的能力来降低延时。
数据转发。当一些指令依赖前面的指令结果时,数据转发的逻辑控制单元决定这些指令在pipeline中的位置并且尽可能快的转发一个指令的结果给后续的指令。这些动作需要很多的对比电路单元和转发电路单元。
四、GPU简介
GPU全称为Graphics Processing Unit,中文为图形处理器,就如它的名字一样,GPU最初是用在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上运行绘图运算工作的微处理器。
GPU是基于大的吞吐量设计,GPU简单架构参考下图:
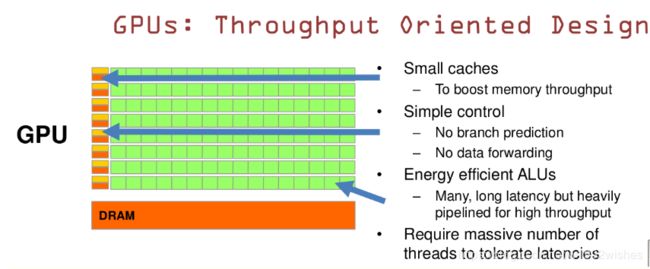
GPU的特点是:
(1)有很多的ALU和很少的cache
缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,而是为thread提高服务的。如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问dram(因为需要访问的数据保存在dram中而不是cache里面),获取数据后cache会转发这个数据给对应的线程,这个时候是数据转发的角色。但是由于需要访问dram,自然会带来延时的问题。
(2)GPU的控制单元(左边黄色区域块)可以把多个的访问合并成少的访问。
(3)GPU的虽然有dram延时,却有非常多的ALU和非常多的thread
为了平衡内存延时的问题,GPU可以充分利用多的ALU的特性达到一个非常大的吞吐量的效果。尽可能多的分配Threads。
五、并行计算
在对比CPU/GPU前,先了解下并行并行计算。
并行计算(Parallel Computing)是指同时使用多种计算资源解决计算问题的过程,是提高计算机系统计算速度和处理能力的一种有效手段。它的基本思想是用多个处理器来共同求解同一问题,即将被求解的问题分解成若干个部分,各部分均由一个独立的处理机来并行计算。
并行计算可分为时间上的并行和空间上的并行。
时间上的并行是指流水线技术,比如说工厂生产食品的时候分为四步:清洗-消毒-切割-包装。
如果不采用流水线,一个食品完成上述四个步骤后,下一个食品才进行处理,耗时且影响效率。但是采用流水线技术,就可以同时处理四个食品。这就是并行算法中的时间并行,在同一时间启动两个或两个以上的操作,大大提高计算性能。
空间上的并行是指多个处理机并发的执行计算,即通过网络将两个以上的处理机连接起来,达到同时计算同一个任务的不同部分,或者单个处理机无法解决的大型问题。
比如小李准备在植树节种三棵树,如果小李1个人需要6个小时才能完成任务,植树节当天他叫来了好朋友小红、小王,三个人同时开始挖坑植树,2个小时后每个人都完成了一颗植树任务,这就是并行算法中的空间并行,将一个大任务分割成多个相同的子任务,来加快问题解决速度。
六、CPU/GPU对比
CPU:
CPU的架构中需要大量的空间去放置存储单元(橙色部分)和控制单元(黄色部分),相比之下计算单元(绿色部分)只占据了很小的一部分,所以它在大规模并行计算能力上极受限制,而更擅长于逻辑控制。
CPU遵循的是冯诺依曼架构,其核心就是:存储程序,顺序执行。这使得CPU就像是个一板一眼的管家,人们吩咐的事情它总是一步一步来做。但是随着人们对更大规模与更快处理速度的需求的增加,这位管家渐渐变得有些力不从心。
GPU:
GPU的构成相对简单,有数量众多的计算单元和超长的流水线,特别适合处理大量的类型统一的数据。
GPU的工作大部分都计算量大,但没什么技术含量,而且要重复很多很多次。GPU就是用很多简单的计算单元去完成大量的计算任务,纯粹的人海战术。这种策略基于一个前提,就是并行计算的线程之间没有什么依赖性,是互相独立的。
GPU在处理能力和存储器带宽上相对于CPU有明显优势,在成本和功耗上也不需要付出太大代价。由于图形渲染的高度并行性,使得GPU可以通过增加并行处理单元和存储器控制单元的方式提高处理能力和存储器带宽。GPU设计者将更多的晶体管用作执行单元,而不是像CPU那样用作复杂的控制单元和缓存并以此来提高少量执行单元的执行效率。
但GPU无法单独工作,必须由CPU进行控制调用才能工作。CPU可单独作用,处理复杂的逻辑运算和不同的数据类型,但当需要大量的处理类型统一的数据时,则可调用GPU进行并行计算。
另外:CPU的整数计算、分支、逻辑判断和浮点运算分别由不同的运算单元执行,此外还有一个浮点加速器。因此,CPU面对不同类型的计算任务会有不同的性能表现。而GPU是由同一个运算单元执行整数和浮点计算,因此,GPU的整型计算能力与其浮点能力相似。
关于GPU和CPU,知乎上有个不是很雅观的例子:
就像有个工作需要算几亿次一百以内加减乘除一样,因为这些计算没有太大的难度,一个办法是雇上几十个小学生一起算,一人算一部分,算是个体力活。
GPU就是这样,用很多简单的计算单元去完成大量的计算任务,纯粹的人海战术。但是这种策略基于一个前提,就是小学生A和小学生B的工作没有什么依赖性,是互相独立的。很多涉及到大量计算的问题基本都有这种特性,比如你说的破解密码,挖矿和很多图形学的计算。这些计算可以分解为多个相同的简单小任务,每个任务就可以分给一个小学生去做。
CPU就像老教授,积分微分都会算,就是工资高,一个老教授资顶二十个小学生。有一些任务并不是简单的计算,二是涉及到“流”的问题。比如你去相亲,双方看着顺眼才能继续发展。总不能你这边还没见面呢,那边找人把证都给领了。这种比较复杂的问题都是CPU来做的。
总而言之,因为最初用来处理的任务就不同,所以CPU和GPU设计上有不小的区别。GPU的运算速度取决于雇了多少小学生,CPU的运算速度取决于请了多么厉害的教授。教授处理复杂任务的能力是碾压小学生的,但是对于没那么复杂的任务,还是顶不住人多。当然现在的GPU也能做一些稍微复杂的工作了,相当于升级成初中生高中生的水平。但还需要CPU来把数据喂到嘴边才能开始干活,究竟还是靠CPU来管的。
七、适于GPU计算的场景
尽管GPU计算已经开始崭露头角,但GPU并不能完全替代X86解决方案。很多操作系统、软件以及部分代码现在还不能运行在GPU上,所谓的GPU+CPU异构超级计算机也并不是完全基于GPU进行计算。一般而言适合GPU运算的应用有如下特征:
- 运算密集
- 高度并行
- 控制简单
- 分多个阶段执行
GPU计算的优势是大量内核的并行计算,瓶颈往往是I/O带宽,因此适用于计算密集型的计算任务。
PS:所谓计算密集型(Compute-intensive)的程序,就是其大部分运行时间花在了寄存器运算上,寄存器的速度和处理器的速度相当,从寄存器读写数据几乎没有延时。可以做一下对比,读内存的延迟大概是几百个时钟周期;读硬盘的速度就不说了,即便是SSD,也实在是太慢了。
八、GPU开发环境
**CG(C for Graphics)**是为GPU编程设计的高级绘制语言,由NVIDIA和微软联合开发,微软版本叫HLSL,CG是NVIDIA版本。Cg极力保留C语言的大部分语义,并让开发者从硬件细节中解脱出来,Cg同时也有一个高级语言的其他好处,如代码的易重用性,可读性得到提高,编译器代码优化。
**CUDA(ComputeUnified DeviceArchitecture,统一计算架构)**是由NVIDIA所推出的一种集成技术,是该公司对于GPGPU的正式名称。通过这个技术,用户可利用NVIDIA的GeForce8以后的GPU和较新的QuadroGPU进行计算。亦是首次可以利用GPU作为C-编译器的开发环境。NVIDIA营销的时候,往往将编译器与架构混合推广,造成混乱。实际上,CUDA架构可以兼容OpenCL或者自家的C-编译器。无论是CUDAC-语言或是OpenCL,指令最终都会被驱动程序转换成PTX代码,交由显示核心计算。
ATIStream是AMD针对旗下图形处理器(GPU)所推出的通用并行计算技术。利用这种技术可以充分发挥AMDGPU的并行运算能力,用于对软件进行加速或进行大型的科学运算,同时用以对抗竞争对手的NVIDIA CUDA技术。与CUDA技术是基于自身的私有标准不同,ATIStream技术基于开放性的OpenCL标准。
**OpenCL(Open Computing Language,开放计算语言)**是一个为异构平台编写程序的框架,此异构平台可由CPU,GPU或其他类型的处理器组成。OpenCL由一门用于编写kernels(在OpenCL设备上运行的函数)的语言(基于C99)和一组用于定义并控制平台的API组成。OpenCL提供了基于任务分区和数据分区的并行计算机制。
OpenCL类似于另外两个开放的工业标准OpenGL和OpenAL,这两个标准分别用于三维图形和计算机音频方面。OpenCL扩展了GPU用于图形生成之外的能力。OpenCL由非盈利性技术组织KhronosGroup掌管。
下面是对几种GPU开发环境的简单评价:
CG:优秀的图形学学开发环境,但不适于GPU通用计算开发。
ATIStream:硬件上已经有了基础,但只有低层次汇编才能使用所有的硬件资源。高层次的brook是基于上一代GPU的,缺乏良好的编程模型。
OpenCL:开放标准,抽象层次较低,较多对硬件的直接操作,代码需要根据不同硬件优化。
CUDA:仅能用于NVIDIA的产品,发展相对成熟,效率高,拥有丰富的文档资源。
九、参考博文
想更好理解CPU和GPU的区别,可以参考下面的博文:
通俗易懂告诉你CPU/GPU是什么?
CPU和GPU的设计区别
GPU及相关技术简介