爬淘宝
xjb写的 应付爬虫课作业,有误请指出,谢谢
项目描述
本项目的目的是爬取淘宝指定类目商品的价格、销量、评论数、评论等等。淘宝链接为www.taobao.com
#网页分析
1.
首先打开淘宝网页,在搜索栏输入任意字段,如:手机,会看到如下页面
用requests库get一下,看能得到什么结果
import requests
header={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36'}
r=requests.get('https://s.taobao.com/search?q=%E6%89%8B%E6%9C%BA&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306')
r.text
会发现get到的信息内容,是要让我们登陆,所以我们需要给header加上cookie信息
2. 制作请求头
cookie:一个 Web 站点可能会为每一个访问者产生一个唯一的ID, 然后以 Cookie 文件的形式保存在每个用户的机器上。如果使用浏览器访问 Web, 会看到所有保存在硬盘上的 Cookie。 详情参考百度百科
下面来说如何得到header信息
右击页面->检查->Network
随意点击一个文件
在这里会找到Request Headers,下面的信息就是可能需要的header请求头
我们先给header添加cookie和user-agent,试试看会返回什么结果
图中显示了一条商品信息
如
title、raw_title、pic_url、detail_url、view_price、view_fee等等信息
import requests
header={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36',
'cookie':此处应有cookie}
r=requests.get('https://s.taobao.com/search?q=%E6%89%8B%E6%9C%BA&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306',headers=header)
r.text
#爬取数据
##利用正则表达式获取数据
-
现在试着用正则表达式匹配一下这些信息
import re pt_raw_title=re.compile(r'"raw_title":"(.*?)"') print(len(pt_raw_title.findall(r.text))) pt_raw_title.findall(r.text)
结果显示我们匹配到了48条数据,和自己在淘宝页面显示的商品数目一致,所以现在大部分的数据在搜索结果页面就可以爬取到,接下来,我们需要做的就是多写几个正则表达式,把需要的内容匹配出来
2. 匹配数据
import re
result=[[],[],[],[],[],[],[],[],[]]
pt=[re.compile(r'"raw_title":"(.*?)"'),re.compile(r'"view_price":"(.*?)"'),
re.compile(r'"detail_url":"(.*?)"'),re.compile(r'"user_id":"(.*?)"'),
re.compile(r'"nid":"(.*?)"'),re.compile(r'"item_loc":"(.*?)"'),
re.compile(r'"view_sales":"(.*?)"'),re.compile(r'"comment_count":"(.*?)"'),
re.compile(r'"nick":"(.*?)"')]
for i in range(len(pt)):
result[i].extend(pt[i].findall(r.text))
-
查看结果
raw_title(店铺名)
view_price(价格)

detail_url(商品url)
这里可能有人想知道,为什么这个结果的前面的链接那么长,而后面的链接那么短,
是不是爬取的结果出错了,我们点开实际的淘宝页面看看即可
user_id(未知属性)
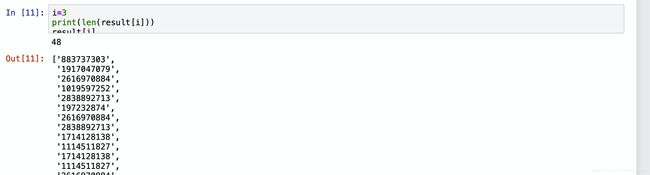
nid(商品对应的id)

item_loc(发货地)
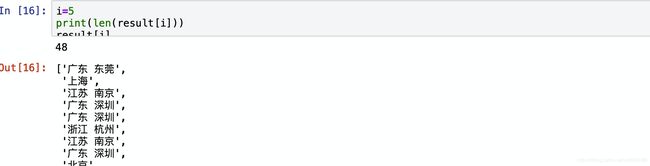
view_sales(价格)
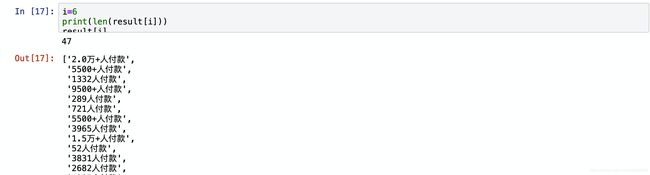
comment_count(评论数)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cn7eZv54-1573653831164)(media/15735547352737.jpg)]
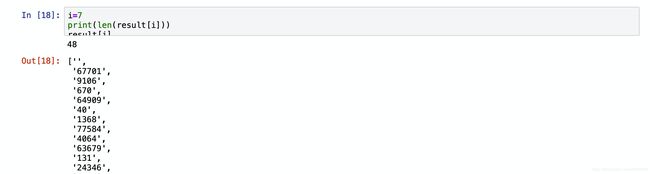
nick(店铺名)
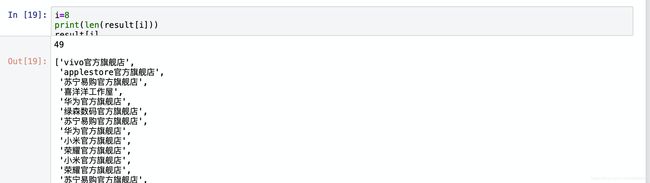
现在已经能获取商品的大部分信息,下一步就是保存商品信息,我们尝试使用pandas把数据存储到csv文件中
##保存数据import pandas as pd index=['raw_title','view_price','detail_url','user_id','nid','item_loc','view_sales','comment_count','nick'] df=pd.DataFrame(data=result,index=index) df=df.T df.to_csv('data.csv')

现在我们能保存爬去的数据,但是我们现在只爬取了一页数据,该怎样爬去多页数据呢,接下来就需要分析页面的url了
#实现多页爬取
-
分析url
第一页url
https://s.taobao.com/search?q=%E6%89%8B%E6%9C%BA&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306
第二页url
https://s.taobao.com/search?q=%E6%89%8B%E6%9C%BA&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s=44
第三页url
https://s.taobao.com/search?q=%E6%89%8B%E6%9C%BA&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s=88
经试验,发现只需要修改s=后面的数字即可实现翻页操作 -
实现翻页操作
import requests import re import pandas as pd import time pages=3 def get_response(pages): header={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36', 'cookie':此处应有cookie} response=[] for i in range(pages): url="https://s.taobao.com/search?q=%E6%89%8B%E6%9C%BA&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s="+str(i*44) r=requests.get(url,headers=header) response.append(r) time.sleep(1) return response def get_data(response): result=[[],[],[],[],[],[],[],[],[]] pt=[re.compile(r'"raw_title":"(.*?)"'),re.compile(r'"view_price":"(.*?)"'), re.compile(r'"detail_url":"(.*?)"'),re.compile(r'"user_id":"(.*?)"'), re.compile(r'"nid":"(.*?)"'),re.compile(r'"item_loc":"(.*?)"'), re.compile(r'"view_sales":"(.*?)"'),re.compile(r'"comment_count":"(.*?)"'), re.compile(r'"nick":"(.*?)"')] for i in range(len(pt)): for j in range(len(response)): result[i].extend(pt[i].findall(response[j].text)) return result def save_data(name,result): index=['raw_title','view_price','detail_url','user_id','nid','item_loc','view_sales','comment_count','nick'] df=pd.DataFrame(data=result,index=index) df=df.T print(df.head) df.to_csv(name+'.csv') response=get_response(pages) data=get_data(response) save_data("手机",data)结果如下
#爬取评论
##分析商品url
要获取评论,首先获得商品的链接
从上面的实验中detail_url中发现每个页面的前三个链接特别长,而后面的链接长度比较短,为简单起见,先分析后面短的链接
url1
https://detail.tmall.com/item.htm?spm=a230r.1.14.74.5c784d1fymGqjc&id=602669134298&ns=1&abbucket=2&sku_properties=10004:709990523;5919063:6536025
url2
https://detail.tmall.com/item.htm?spm=a230r.1.14.35.5c784d1fymGqjc&id=602210068322&ns=1&abbucket=2&sku_properties=10004:709990523;5919063:6536025
url3
https://item.taobao.com/item.htm?spm=a230r.1.14.20.5c784d1fymGqjc&id=601080313607&ns=1&abbucket=2#detail
第一条url和第二条url只有 id= 后面的数字不一样,而一个id对应一个商品,如果要访问其他商品,只需修改id后面的数字即可,商品的id我们已经在上面获取到了,即nid
第二条和第三条相比 第三条url没有第二条那么长,试试吧url2改成url3的样子,试试能不能访问链接
新url2 https://detail.tmall.com/item.htm?spm=a230r.1.14.35.5c784d1fymGqjc&id=602210068322&ns=1&abbucket=2#detail
结果无误
##抓包
通过ctrl+f搜索评论,发现在爬取到的结果中并没有评论数据,所以可能需要通过抓包的方式获取评论
-
检查
-
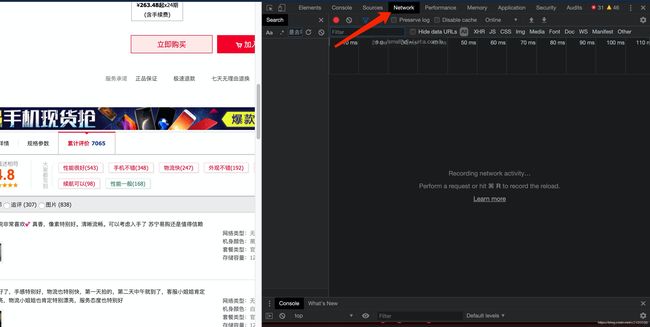
-
翻页 获取服务器返回的评论文件
-
搜索评论
-
拷贝链接
-
获取更多评论文件的链接
第二页评论
https://rate.tmall.com/list_detail_rate.htm?itemId=602210068322&spuId=1340548940&sellerId=2616970884&order=3¤tPage=2&append=0&content=1&tagId=&posi=&picture=&groupId=&ua=098%23E1hvh9vrvrwvUvCkvvvvvjiPRsMZ0jnbPFc9tjrCPmPZAjiPP2FW0jYURFdhzjDUCQhvCYMNzn1wVSJrvpvEvCmx9NclmncsCQhvCYMNzn1wK90rvpvBUCvDvyn2mHyL84%2F9bZbxKaVrvpvpjCBevSdTCEaDFfwznHVt6OhCvCWpvj7wkldNz%2FNK%2BYAYAZrqv6ru9phvh1vvnXAV7rMNt%2FffzbzEoz%2B2o0uCvpvWzMaA58D4zYM5sFjwdphvmpvW79WP2QBqhu6CvvyvmjU2ytWhRuptvpvhvvvvv2yCvvpvvvvvdphvmpvUEpW6nvp4SghCvCWpvHmwvHdNzYM5UnAYAZrqv6ru3QhvCvvhvvvtvpvhvvvvvvGCvvpvvPMMmphvLC23wvvjff0DK4vBh7DHD7z9aXTQVztrAjxlHdUf8cc63E7rjC61iNoxfBeKN6qwgWFIjE30pq2XS4ZAhjCbFOcnDBvwJ9kx6acEn1mtvpvIvvvvk6CvvvvvvvnUphvW8pvvv63vpCCIvvv2ohCv2ROvvvnUphvWtuyCvv9vvUvzUmE52gyCvvOUvvVCa6GCvpvVvvpvvhCviQhvCvvv9UUtvpvhvvvvvUhCvCWpvbVwCHdNzYMSWaAYAZrqv6ruRphvCvvvvvmCvpvLhvC15v14zYMNY6fwSwDbJQnb4FyCvvpvvvvvdphvhA9WR9W%2FP9L3YkeSI2BvALVDsLuCvpvxUvv25Rr4zYM5IAMwSwyqppRf4kuq9phv2nMS6cQx7rMNtYSNz86CvC9Gmnmm%2BqWhCkSE%2B2IDZO7aznmfdzDb1U7CvpvWz%2FMe5Wi4zYM5jCSwCQhvCYMNzn1ftKOjvpvjzYMwzHSelQwCvvNNzYsw7%2FFBRphvCvvvvvmCvpvLhv2L5Ux4zYM5tFqwSwDbJQnb49wCvvNNzYsw76oTdphvmpvpKg8bkQodHQwCvvNNzYsw76ZedphvmpvpfpnLZQ3tMvwCvvNNzYswcWrYCQhvCYMNzn1wqdOjvpvjzYMwzHsKl9%3D%3D&needFold=0&_ksTS=1573569220123_895&callback=jsonp896
第三页评论链接
https://rate.tmall.com/list_detail_rate.htm?itemId=602210068322&spuId=1340548940&sellerId=2616970884&order=3¤tPage=3&append=0&content=1&tagId=&posi=&picture=&groupId=&ua=098%23E1hvN9v4vX6vUvCkvvvvvjiPRsMZ0jEvPFshQjrCPmPWsjrnPLMptjE8nLMZ0j1HdphvmpvWkOFITv3mmUhCvvsNqQkGkxdNz%2FGh3rArvpvEvv9Y96YPmC8ZRphvCvvvvvvjvpvjzYMwzH1%2FA46Cvvyv22w2eE9UcVoCvpvWz%2F%2FMSvr4zYMSUbMw9phv2nMSgbQb7rMNq1vJz86CvvyvmCm2GNhU2UvtvpvhvvvvvUhCvvsNqGkwZxdNzYMMHYA5vpvhvvmv99yCvhQhK16vCAKxfwLhdigDN%2BLvafp4VjHaD7zhQ8TJh0NEifeaHsWAcfZnIOZtIoYbD4mxfXkOjLoQD7zOdigDNr3ldE7rejvr%2B8c6lEQOKphv8vvvvUrvpvvvvvmCRyCv2myvvvnUphvp4vvvv63vpvsevvv2ohCv2R4EvpvVmvvC9caPuphvmvvv92w982%2B%2BvphvC9vhvvCvpvGCvvpvvPMMRphvCvvvvvmjvpvhvvpvv86Cvvyvm2W2Kfyvhhvtvpvhvvvvv2yCvvpvvvvv9phv2nMSEbQa7rMNq0kSz86CvvyvmV8U2vQUUD4CvpvZzMN%2FM9E4zYMSchdGchS5AYMgzWv%3D&needFold=0&_ksTS=1573569388222_935&callback=jsonp936
第四页评论
https://rate.tmall.com/list_detail_rate.htm?itemId=602210068322&spuId=1340548940&sellerId=2616970884&order=3¤tPage=4&append=0&content=1&tagId=&posi=&picture=&groupId=&ua=098%23E1hva9vPvB9vUvCkvvvvvjiPRsMZ0jECn2LU1jYHPmPwAjEvn2zpAjlHPFzh6jYWRphvCvvvvvmrvpvEvvF9mEoZvmGsdphvhovUQQeRF92ArmeS8kiaAOcC3QhvCvvhvvm5vpvhvvmv9FyCvvpvvvvvmphvLvAtdvvj7uoQD70Od5lp1bmxfBkKNB3rzj7h5dUf857QiNoAdcvrMnF96CIaa6qyzb2XrqpyCW2%2BFO7t%2BeCo1RFEDLuTWDAvD7zvdiTtvpvIvvvvk6CvvvvvvUhTphvW8pvvv63vpCCIvvv2ohCv2ROvvvnUphvWtuyCvv9vvUvzUmrt0IyCvvOUvvVCa6GCvpvVvvpvvhCv2QhvCvvvMM%2FrvpvEvv9nCjt%2Fvn8TdphvmpvUMQkDipvMeUhCvCLNYqsJPldNzYY7KP1wo%2FwGzMFwQv%3D%3D&needFold=0&_ksTS=1573569441518_1001&callback=jsonp1002
分析链接 -
链接过长,去三个链接中前半段最相似的部分
分析得出只需这部分链接即可
https://rate.tmall.com/list_detail_rate.htm?itemId=602210068322&spuId=1340548940&sellerId=2616970884&order=3¤tPage=4&append=0&content=1&tagId=&posi=&picture=&groupId= -
评论翻页:实验发现修改*currentPage=*后面的数字,即可获得指定页码的评论
接下来使用requests.get()获取链接信息试试,结果如下
获取的结果对应淘宝的这个页面

通过分析,我们需要给header加上referer字段,而且referer字段对应的字符串正好是商品的链接,如下图所示
加上referer字段,重新爬取,如下图,有了我们所需要的评论信息
下一步:爬取多页页面的评论header={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36', 'cookie':此处应有cookie, 'referer':'https://detail.tmall.com/item.htm?spm=a230r.1.14.35.5c784d1fymGqjc&id=602210068322&ns=1&abbucket=2&sku_properties=10004:709990523;5919063:6536025'} pages=4 response_comment=[] for i in range(pages): url="https://rate.tmall.com/list_detail_rate.htm?itemId=602210068322&spuId=1340548940&sellerId=2616970884&order=3¤tPage=%d&append=0&content=1&tagId=&posi=&picture=&groupId="%i q=requests.get(url,headers=header) response_comment.append(q) time.sleep(1)
结果如下
匹配评论数据
pt=re.compile(r'"rateContent":"(.*?)"')
result_comment=[]
for i in response_comment:
result_comment.extend(pt.findall(i.text))
print(len(result_comment))
result_comment
结果如下
保存评论结果,文件名为商品ID
nid=602210068322
with open(str(nid)+'.txt','a+') as f:
for i in result_comment:
f.write(i)
f.write('\n')
结果如下
现在试着根据之前保存的nid来访问每个商品,获取评论,然后保存为txt文件
def save_comment(data):
for i in data[4]:
goods_url="https://item.taobao.com/item.htm?spm=a230r.1.14.20.5c784d1fymGqjc&id="+i+"&ns=1&abbucket=2#detail"
header={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36',
'cookie':此处应有cookie,
'referer':goods_url}
result_comment=[]
pt=re.compile(r'"rateContent":"(.*?)"')
for j in range(3):
comment_url=url="https://rate.tmall.com/list_detail_rate.htm?itemId=602210068322&spuId=1340548940&sellerId=2616970884&order=3¤tPage=%d&append=0&content=1&tagId=&posi=&picture=&groupId="%j
w=requests.get(comment_url,headers=header)
time.sleep(1)
for q in response_comment:
result_comment.extend(pt.findall(q.text))
with open(str(i)+'.txt','a+') as f:
for i in result_comment:
f.write(i)
f.write('\n')
save_comment(data)
为了防止被反爬
只爬取了4个商品的评论,每个商品爬取了三页评论
#总代码
import requests
import re
from fake_useragent import UserAgent
import pandas as pd
import time
import urllib
import random
pages=3
class taobao():
def __init__(self):
self.pages=int(input("请输入要爬取的页数"))
self.if_comment=int(input("请输入是否爬取评论:1爬,2不爬"))
if(self.if_comment==1):
self.nums=int(input("请输入要爬取评论的页数"))
self.response=None
self.result=None
self.name=None
self.cookie=此处应有cookie
def get_response(self):
header={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36',
'cookie':self.cookie}
response=[]
cat=input("输入要爬取的类目:")
self.name=cat
a=urllib.parse.quote(cat)
for i in range(self.pages):
url="https://s.taobao.com/search?q="+a+"&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s="+str(i*44)
header['user-agent']=UserAgent().random
r=requests.get(url,headers=header)
response.append(r)
time.sleep(1)
self.response=response
return response
def get_data(self):
result=[[],[],[],[],[],[],[],[],[]]
pt=[re.compile(r'"raw_title":"(.*?)"'),re.compile(r'"view_price":"(.*?)"'),
re.compile(r'"detail_url":"(.*?)"'),re.compile(r'"user_id":"(.*?)"'),
re.compile(r'"nid":"(.*?)"'),re.compile(r'"item_loc":"(.*?)"'),
re.compile(r'"view_sales":"(.*?)"'),re.compile(r'"comment_count":"(.*?)"'),
re.compile(r'"nick":"(.*?)"')]
for i in range(len(pt)):
for j in range(len(self.response)):
result[i].extend(pt[i].findall(self.response[j].text))
self.result=result
return result
def save_data(self):
index=['raw_title','view_price','detail_url','user_id','nid','item_loc','view_sales','comment_count','nick']
df=pd.DataFrame(data=self.result,index=index)
df=df.T
df.to_csv(self.name+'.csv')
def save_comment(self):
for i in self.data[4]:
goods_url = "https://item.taobao.com/item.htm?spm=a230r.1.14.20.5c784d1fymGqjc&id=" + i + "&ns=1&abbucket=2#detail"
header = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36',
'cookie': self.cookie,
'referer': 'https://detail.tmall.com/item.htm?spm=a230r.1.14.35.5c784d1fymGqjc&id=' + i + '&ns=1&abbucket=2&sku_properties=10004:709990523;5919063:6536025'}
header['user-agent'] = UserAgent().random
result_comment = []
pt = re.compile(r'"rateContent":"(.*?)"')
for j in range(self.nums):
comment_url = 'https://rate.tmall.com/list_detail_rate.htm?itemId=' + i + '&spuId=1340548940&sellerId=2616970884&order=2¤tPage=' + str(
j) + '&append=0&content=1&tagId=&posi=&picture=&groupId=&ua=098%23E1hvXQvPvBvvUpCkvvvvvjiPRsMO6j3CPFLUAjEUPmPhzji8P2qy1jtUPFqhAjrPR2yCvvBvpvvv9phvHnQGN7dKzYswznGA7MwIMPcw9HuCdphvmZCmB62dvhCLRsyCvvBvpvvvvphvCyCCvvvvvUyCvvXmp99We1AivpvUphvhKLU%2F9kotvpvIphvvcvvvphCvpvsBvvC2mZCvVhUvvhBJphvOp9vvpMivpC3mvvC2%2F9yCvh1mgcUvIqUf85WKYE7rejOdX9nr1EuKfvyf8rBl5FGDN5HmafmAdcHUjLPClfy64v6f8rBlDCODN5HhaNoXe7%2BRVAdhaB4AVAi1bPox2QhvCPMMvvm5vpvhphvhHUwCvvBvppvvdphvmZCmhy2kvhCBiT6CvvDvpQCvqQCvxekrvpvEphRUpjhvpHJ0&needFold=0&_ksTS=1573643934612_1200&callback=jsonp1201'
w = requests.get(comment_url, headers=header)
time.sleep(random.randint(3))
result_comment.extend(pt.findall(w.text))
time.sleep(random.randint(10))
with open(str(i) + '.txt', 'a+') as f:
for i in result_comment:
f.write(i)
f.write('\n')
def main():
tao=taobao()
data=tao.get_data()
data=tao.get_data()
tao.save_data()
if(tao.if_comment==1):
tao.save_comment()
if __name__=='main':
main()