JVM成神之路-Java对象模型
首先我们要知道:
在jvm的内存结构中,对象保存在堆中,而我们在对对象进行操作时,其实操作的是对象的引用。
Java对象包含三个部分
一个Java对象可以分为三部分存储在内存中,分别是:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
- 对象头(包含锁状态标志,线程持有的锁等标志)
- 实例数据
- 对齐填充
oop-klass model(hotspot jvm中的对象模型)
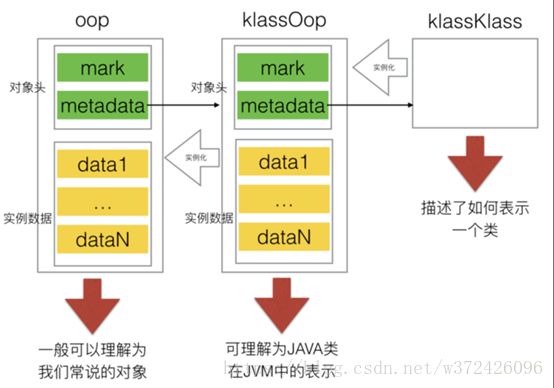
Java虚拟机的底层是使用c++实现,而jvm并没有根据一个Java的实例对象去创建对应的c++对象,而是设计了一个oop-klass model ;
- OOP(Ordinary Object Pointer):普通对象指针; 表示一个实例信息
- Klass:描述对象实例的具体类型, 含了元数据和方法信息
- 创建目的:不想让每个对象中都含有一个vtable(虚函数表)
类就是一类事物的抽象概括。
OOP体系:
- OOPs模块中包含了多个子模块,每个子模块对应一个类型,每一个类型的OOP都代表一个在JVM内部使用的特定对象的类型。
- 在Java程序运行过程中,每创建一个新的对象,在JVM内部就会相应的创建一个对应类型的OOP对象。
代码:
- typedef class oopDesc* oop;
// 定义了oop共同的基类,其他的类型都是它的子类
- typedef class instanceOopDesc* instanceOop;
/* 表示一个Java类型实例,每当我们new一个对象时,
JVM都会创建一个instanceOopDesc */
- typedef class methodOopDesc* methodOop;
// 表示一个Java方法
- typedef class constMethodOopDesc* constMethodOop;
// 表示一个Java方法中的不变信息
- typedef class MethodDataOopDesc* methodDataOop;
// 记录性能信息的数据结构
- typedef class arrayOopDesc* arrayOop;
/* 定义了数组oops的抽象基类,下面两个类相当于此类的子类,
new一个数组时会建立此对象*/
- typedef class objArrayOopDesc* objArrayOop;
// 表示持有一个oops数组,对应存储对象的数组
- typedef class typeArrayOopDesc* typeArrayOop;
// 表示容纳基本类型的数组,对应存储基本类型的数组
- typedef class constantPoolOopDesc* constantPoolOop;
// 表示在class文件中描述的常量池
- typedef class constantPoolCacheOopDesc* constantPoolCacheOop;
// 常量池缓存
- typedef class klassOopDesc* klassOop;
// 描述一个与Java类对等的C++类
- typedef class markOopDesc* markOop;
// 表示对象头
OopDesc结构:
class oopDesc {
friend class VMStructs;
private:
/*
* 实际上也是代表了instanceOopDesc、arrayOopDesc和OopDesc
* 包含了markOop _mark和union_matadata两部分
*/
volatile markOop _mark; // 保存锁标记、gc分代等信息
union _metadata { wideKlassOop _klass; // 普通指针,
// 压缩类指针,和普通指针都指向instanceKlass 对象
narrowOop _compressed_klass; } _metadata;
private:
// 实例数据保存的位置
void* field_base(int offset) const;
jbyte* byte_field_addr(int offset) const;
jchar* char_field_addr(int offset) const;
jboolean* bool_field_addr(int offset) const;
jint* int_field_addr(int offset) const;
jshort* short_field_addr(int offset) const;
jlong* long_field_addr(int offset) const;
jfloat* float_field_addr(int offset) const;
jdouble* double_field_addr(int offset) const;
address* address_field_addr(int offset) const; }
/* instanceOopDesc和arrayOopDesc都直接继承了oopDesc,
都没有增加其他的数据结构 */
class instanceOopDesc : public oopDesc {
}
class arrayOopDesc : public oopDesc { }
- 职能:表示对象的实例数据,不含任何虚函数
- 对象在内存中的基本形式就是oop
- 对象所属的类也是一种oop,即klassOop,对应的klass是klassKlass
Klass体系:
结构:
- class Klass;
// klassOop的一部分,用来描述语言层的类型,其他所有类的父类
- class instanceKlass;
// 在虚拟机层面描述一个Java类,每一个已加载的Java类都会创建一个此对象,
// 在JVM层表示Java类
- class instanceMirrorKlass;
// 专有instantKlass,表示java.lang.Class的Klass
- class instanceRefKlass;
// 专有instantKlass,表示java.lang.ref.Reference的子类的Klass
- class methodKlass; // 表示methodOop的Klass
- class constMethodKlass; // 表示constMethodOop的Klass
- class methodDataKlass; // 表示methodDataOop的Klass
- class klassKlass; // 最为klass链的端点,klassKlass的Klass就是它自身
- class instanceKlassKlass; // 表示instanceKlass的Klass
- class arrayKlassKlass;
// 表示arrayKlass的Klass
- class objArrayKlassKlass; // 表示objArrayKlass的Klass
- class typeArrayKlassKlass; // 表示typeArrayKlass的Klass
- class arrayKlass; // 表示array类型的抽象基类
- class objArrayKlass; // 表示objArrayOop的Klass
- class typeArrayKlass; // 表示typeArrayOop的Klass
- class constantPoolKlass; // 表示constantPoolOop的Klass
- class constantPoolCacheKlass;
// 表示constantPoolCacheOop的Klass
功能:
-
-
- 实现语言层面的Java类(在Klass基类中已经实现)
- 实现Java对象的分发功能(由Klass子类提供虚函数实现)
-
目的:为了实现虚函数多态,提供了虚函数表。
- instanceKlass的内部结构:
- objArrayOop _methods;
// 类拥有的方法
- typeArrayOop _method_ordering;
//描述方法顺序
- objArrayOop _local_interfaces;
//实现的接口
- objArrayOop _transitive_interfaces;
//继承的接口
- typeArrayOop _fields;
//域
- constantPoolOop _constants;
//常量
- oop _class_loader;
//类加载器
- oop _protection_domain;
//protected域
....
HotSpotJVM的设计这把对象一拆为二,分为Klass和oop,其中oop的只能主要在于表示对象的实例数据,所以其中不含有任何虚函数,而klass为了实现虚函数多态,所以提供了虚函数表。所以,关于java的多态,其实也有虚函数的影子在。
instanceKlass
JVM在运行时,需要一种用来标识Java内部类型的机制。在HotSpot中的解决方案是:为每一个已加载的Java类创建一个instanceKlass对象,用来在JVM层表示Java类。
结构:
//类拥有的方法列表
objArrayOop _methods;
//描述方法顺序
typeArrayOop _method_ordering;
//实现的接口
objArrayOop _local_interfaces;
//继承的接口
objArrayOop _transitive_interfaces;
//域
typeArrayOop _fields;
//常量
constantPoolOop _constants;
//类加载器
oop _class_loader;
//protected域
oop _protection_domain;
....
在JVM中,对象在内存中的基本存在形式就是oop。那么,对象所属的类,在JVM中也是一种对象,因此它们实际上也会被组织成一种oop,即klassOop。同样的,对于klassOop,也有对应的一个klass来描述,它就是klassKlass,也是klass的一个子类。
klassKlass作为oop的klass链的端点。关于对象和数组的klass链大致如下图:
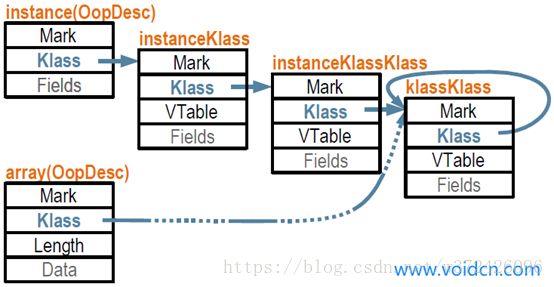
oop-klass-klassKlass关系图:
符号引用
符号引用就是用一组符号来描述所引用的目标,我们都知道在Java中,通常情况下我们写的一个Java类被编译以后都是一个class文件,在编译的时候,Java类并不知道所引用的类的实际地址,因此只能使用符号引用来代替。
一般一个对象的创建就是从new开始的,而操作这些创建指令的就是jvm了,首先当你开始new的时候,jvm会先去查找一个符号引用,如果找不到这个符号引用就说明这个类还没有被加载,因此jvm就会进行类加载,然后符号引用被解析完成,紧接着jvm会为对象在堆内存中分配内存,也就是说我们这个user对象就在堆内存中有一块内存空间了。
HotSpot虚拟机实现的Java对象包括三个部分:对象头,实例字段和对齐填充。
为对象分配完堆内存之后,jvm会将该内存进行零值初始化。

内存存储:
关于一个Java对象,他的存储是怎样的,一般很多人会回答:对象存储在堆上。稍微好一点的人会回答:对象存储在堆上,对象的引用存储在栈上。今天,再给你一个更加显得牛逼的回答:
对象的实例(instantOopDesc)保存在堆上,对象的元数据(instantKlass)保存在方法区,对象的引用保存在栈上。
其实如果细追究的话,上面这句话有点故意卖弄的意思。因为我们都知道。方法区用于存储虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。 所谓加载的类信息,其实不就是给每一个被加载的类都创建了一个 instantKlass对象么。
示例
class Model{
public static int a = 1;
private final int NUMBER = 2;
public int b;
public int c = 3;
public Model(int b){
this.b = b;
}
public static void main(String[] args){
int d = 10;
Model modelA = new Model(2);
Model modelB = new Model(3);
}
}
存储结构:

总结:
在Java中,JVM中的对象模型包含两部分:Oop和Klass,在类被加载的时候,JVM会给类创建一个instanceKlass,其中包含了类信息、常量、静态变量、即时编译器编译后的代码等,存储在方法区,用来在JVM层表示该Java类。而使用new一个对象后,JVM就会创建一个instanceOopDesc对象,该对象包含对象头和实例数据,对象头中保存的是锁的状态标志等信息,元数据则实际上是一个指针,指向instanceKlass。
Java对象模型---对象头(Mark Word)
对象自身的运行时数据
这部分存储包括哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等。这部分数据被官方称为Mark Word,在32位和64位的虚拟机中的大小分别为32bit和64bit。
由于对象头信息是与对象自身定义的数据无关的额外存储成本,考虑到虚拟机的空间效率,Mark Word被设计成一个非固定的数据结构以提高存储空间的利用率。即这部分数据会根据对象的状态来分配存储空间。
对象的类型指针
即指向对象的类元数据的指针。虚拟机可以通过该指针判定对象实例属于哪个类。
在Java对象中比较特殊的是Java数组,一个数组实例的对象头中必须记录数组的长度。JVM可以通过对象头中的数组长度数据来判定数组的大小,这是访问数组类型的元数据无法得到的。
对象的实例数据
前面提到对象头是对象的额外开销,只有实例数据才是一个对象实例存储的有效信息,也是在程序代码中所定义的各种类型的字段内容。这部分内容同时记录了子类从父类继承所得的各类型数据。
填充
对齐填充在对象数据中并不是必然的,只是起着占位符的作用,没有特别含义。HotSpot要求对象起始地址必须是8字节的整数倍。对象头的大小刚好符合要求,因此当实例数据没有对齐时,就需要通过填充来对齐数据。
获取类的元数据
虚拟机在加载类的时候会将类的信息、常量、静态变量和即时编译器编译后的代码等数据存储在方法区(Method Area)。类的元数据,即类的数据描述,也被存在方法区。我们知道对象头中会存有对象的类型指针,通过类型指针可以获取类的元数据。因此,对象的类型指针其实指向的是方法区的某个存有类信息的地址。
但是,并不是每个对象实例都存有对象的类型指针。根据对象访问定位方法的不同,对象的类型指针被存放在不同的区域。
- 通过句柄访问对象
- 对象的类型指针被存放在句柄池中;
- 通过Reference指针直接访问对象
- 对象的类型指针被存放在对象本身的数据中。
比较来说:
- 使用句柄访问的最大好处就是reference中存储的是稳定的句柄地址,当对象被移动(垃圾收集时会经常移动对象)时智慧改变句柄中实例数据执政,而reference本身不需要修改。
- 使用直接指针访问方式的最大好处就是速度快,节省了一次指针定位的时间开销(对象的访问在java中也非常频繁)
因此,Java的对象数据存储可以理解为:
- 引用类型(指向对象的Reference)
- 存储在栈中
- 对象的类的元数据 (Class MetaData)
- 存储在方法区中
- 对象的实例数据
- 存储在堆中
对象内存布局
- 存储的是与对象本身定义的数据无关的额外存储成本,其数据结构不固定。
- 32位JVM中,对象不同装填的mark word各个比特位区间图示如下:

对象五种状态:无锁态、轻量级锁、重量级锁、GC标记和偏向锁。
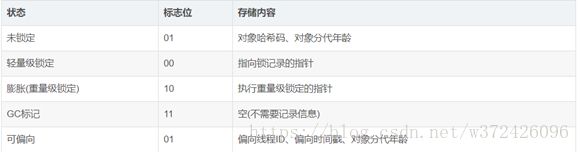
HotSpot中对象头主要包含两部分
第一:
用于存储对象自身的运行时数据,如上表中的对象哈希码,对象分代年龄,偏向线程id,偏向时间戳等。
第二:
类型指针了,我们看表中也有指针字样,那么这部分主要就是杜希昂指向它的类元数据的指针了,虚拟机就是通过这个指针来确定这个对象时那个实例。
偏向锁和重量级锁
- 偏向锁:主要解决无竞争下的锁性能问题
- 按照HotSpot设计,每次加锁/解锁都会涉及到一些CAS操作,CAS操作会延迟本地调用
- 偏向锁会偏向第一个访问锁的程序,如果接下来的运行过程中,该锁没有被其他线程访问,则持有偏向锁的线程将永远不需要触发同步。
- 但是如果在运行过程中,遇到了其他线程抢占锁,则持有偏向锁的线程会被挂起,JVM会尝试消除它身上的偏向锁,将锁恢复到标准的轻量级锁
- 只能在单线程中起作用
- 轻量级锁:为了在无多线程竞争的环境中使用CAS来替代synchronized。减少传统的重量级锁使用操作系统互斥量产生的性能消耗,是为了减少多线程进入互斥的几率。并非替代互斥。
参考资料:
《深入理解Java虚拟机》
http://www.cnblogs.com/chenyangyao/p/5245669.html
深入理解多线程(二)—— Java的对象模型-HollisChuang's Blog
深入理解多线程(三)—— Java的对象头-HollisChuang's Blog