prometheus搭建
一 简介
Prometheus是继Kubernetes后第2个正式加入CNCF基金会的项目,容器和云原生领域事实的监控标准解决方案。
Prometheus受启发于Google的Brogmon监控系统(相似的Kubernetes是从Google的Brog系统演变而来),从2012年开始由前Google工程师在Soundcloud以开源软件的形式进行研发,并且于2015年早期对外发布早期版本。2016年5月继Kubernetes之后成为第二个正式加入CNCF基金会的项目,同年6月正式发布1.0版本。2017年底发布了基于全新存储层的2.0版本,能更好地与容器平台、云平台配合
prometheus的架构图
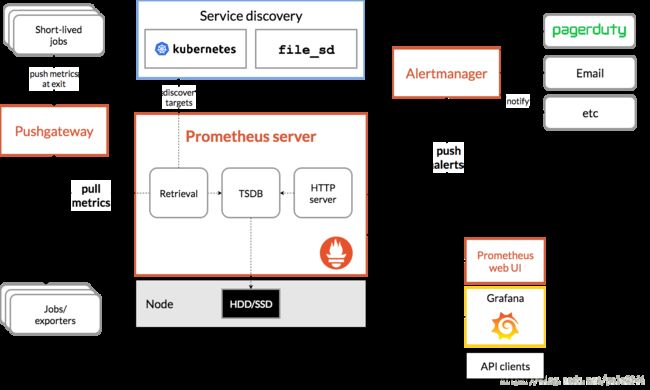
更多理论性描述可自行百度。
从监控数据的获取一直到报警的过程,采用监控mysql数据库为例用白话来说。
exporter:用于获取mysql的各项指标,包括资源指标,甚至表里数据。并格式化为prometheus指定的数据格式。exporter的来源有以下几种,1从Prometheus官网或社区找。2 从mysql官网或社区找。3 从万能的网上扒。 4 自己写。
理论上来说。只要提供exporter,我们能监控任何东西。包括计算机硬件,软件,我们自己的程序,传感器,汽车,飞机大炮等。
指标数据格式大体如下:

Prometheus : 请求mysql的exporter提供的接口,获取指标数据。 并判断本次拉取的指标数据是否符合我们设置的报警规则。
alertManger: 如果指标数据符合我们设置的报警规则,则采用alertManager设置的告警方式发出报警。比如发邮件,企业微信等等等等。
同时,我们可以用grafana添加Prometheus数据源。以图形方式直观查看监测情况

二 以docker方式安装Prometheus
1. 拉取镜像
docker pull prom/prometheus
2. 编写配置文件
/mnt/docker_volume/prometheus/conf/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
3. 运行
1. 执行命令 vim /etc/passwd
添加一行数据
nobody:x:65534:65534:nobody:/home:/bin/false
2. 执行命令 vim /etc/group
添加一行数据
nobody:x:65534:
3. 创建路径/mnt/docker_volume/prometheus/data
并将data目录设置用户和组为 65534
cd /mnt/docker_volume/prometheus/
chown 65534:65534 data/
这样做的原因是需要把prometheus 的数据路径映射出来,避免容器删除后历史监控数据丢失。
而更改文件所有者只是为了解决 open /prometheus/lock: permission denied 的报错。
之后运行如下命令启动容器。
docker run -p 9090:9090 -v /mnt/docker_volume/prometheus/conf/prometheus.yml:/etc/prometheus/prometheus.yml -v /mnt/docker_volume/prometheus/conf/:/etc/prometheus/rules -v /mnt/docker_volume/prometheus/data:/prometheus --privileged -d --name prometheus_container prom/prometheus
4. 确认安装成功
访问 ip:9090 进入如下页面
即为安装完成。
三 以docker方式安装 grafana
1. 拉取镜像
docker pull grafana/grafana
2. 运行
docker run -d --name grafana_container -p 3000:3000 grafana/grafana
3. 确认安装成功
访问 ip:3000 ,默认账号密码为admin,admin。添加Prometheus数据源,添加dashboard,输入指标prometheus grafana将自动提示指标全名,任意选择,并查询,查看结果。
四 以docker方式安装 alertmanager
1. 拉取镜像
docker pull prom/alertmanager
2. 编写配置文件
/mnt/docker_volume/prometheus/alertManager/alertmanager.yml
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'email'
receivers:
#- name: 'web.hook'
# webhook_configs:
# - url: 'http://127.0.0.1:5001/'
- name: 'email'
email_configs:
- to: 接收者的@qq.com
from: 发送者的@qq.com
smarthost: smtp.qq.com:587
auth_username: 发送人账号
auth_password: 发送人授权码
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
上面的配置文件中,我配置的是用qq邮箱发送告警信息。其他告警方式可自行调研。
3. 运行
docker run -d -p 9093:9093 -v /mnt/docker_volume/prometheus/alertManager:/etc/alertmanager --name alertmanager_container prom/alertmanager
五 结合exporter 入门使用
1. node-exporter监控服务器
从Prometheus官网
https://prometheus.io/docs/instrumenting/exporters/ 可以找到node-exporter
但是这里我们采用docker,
拉取镜像
docker pull prom/node-exporter
运行
docker run -d -p 9100:9100 --name node-exporter_container prom/node-exporter
访问ip:9100/metrics
返回很多指标数据。
2. 编写告警规则
我们在/mnt/docker_volume/prometheus/conf目录下新建一个文件node_rules.yml
配置告警规则
groups:
- name: node_memory_MemFree_bytes
rules:
- alert: node_memory_MemFree_bytes
expr: node_memory_MemFree_bytes/node_memory_MemTotal_bytes < 0.60
for: 1m
labels:
severity: page
annotations:
summary: "内存已经使用4成"
3. 修改prometheus 配置文件
添加一个job
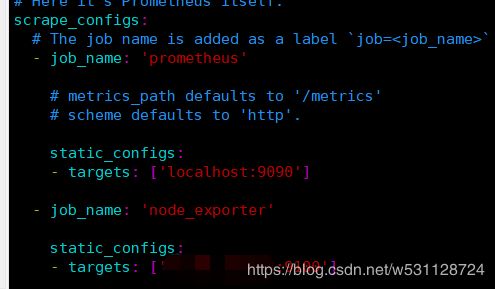
添加 alertManager
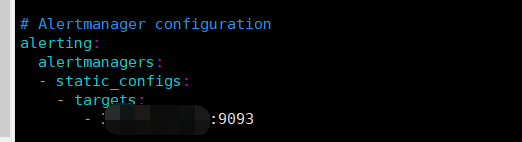
添加 rules 文件

4. 重启 Prometheus
docker restart prometheus_container
5. 查看grafana
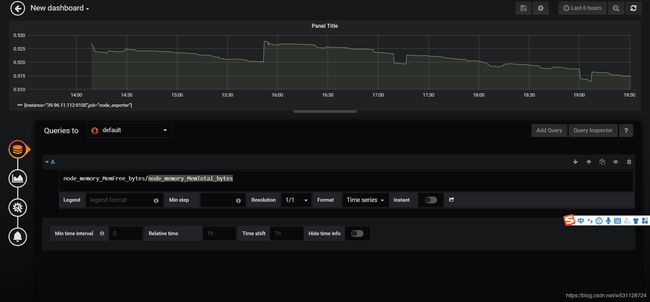
6. 等待邮件
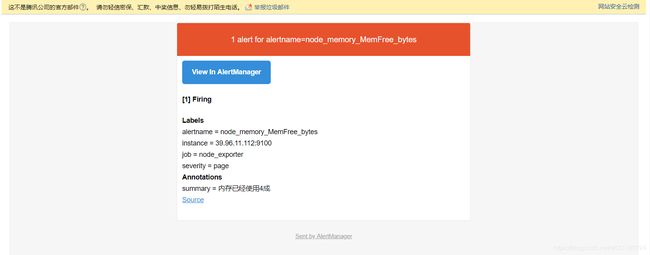
六 待续
1. Prometheus 目前不支持集群,因为一般来说监控只是一个观察措施。 但是如果对监控及告警要求较高,比如工业上,错过报警就容易发生事故等场景。可以考虑横向扩展,具体实现方案还未探索。
2. 目前每加一个监控项,报警规则。都需要重启Prometheus服务。配置文件热加载方案还没去了解。
3. 关于Prometheus如何监控我们的springboot工程或者数据库表里的数据,分为 资源监控(系统级参数)和自定义监控(我们自己写入我们想看的监控数据)。都已经有现成的集成方案了。后续将发到群里。