【Python+selenium】Page Object 设计模式
Page Object是selenium自动化测试项目开发实践的最佳设计模式之一,它主要体现在对界面交互细节的封装,这样可以使测试案例更关注与业务而非界面细节,从而提高测试案例的可读性。
一、认识Page Oject
Page Oject设计模式的优点如下:
- 减少代码的重复
- 提高测试用例的可读性
- 提高测试用例的可维护性,特别是针对UI频繁变化的项目。
当为Web页面编写测试时,需要操作该Web页面上的元素。然而,如果在测试代码中直接操作HTML元素,那么你的代码是及其脆弱的,因为UI经常变动。我们可以将一个page对象封装成一个HTML页面,然后通过提供的应用程序特定的API来操作页面元素,而不是在HTML中四处搜寻。Page Oject原理如下图。
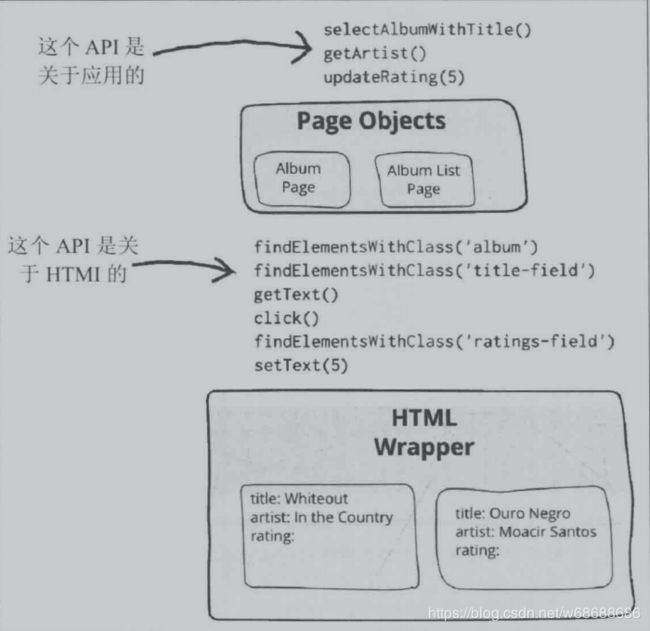
page对象的一个基本经验法则是:凡事人能做的事,page对象通过软件客户端都能够做到。因此,它也应当提供一个易于编程的接口并隐藏窗口中底层的部件。所以访问一个文本框应该通过一个访问方法(accessor method)来实现字符串的获取与返回,复选框应当使用布尔值,按钮应当被表示为行为导向的方法名。page对象应当将在GUI控件上所有查询和操作数据的行为封装为方法。一个好的经验法则是,即使改变具体的控件,page对象的接口也不应当发生变化。
尽管该术语是“页面”对象,但并不意味着需要针对每个页面建立一个这样的对象,例如,页面有重要意义的元素可以独立为一个page对象。经验法则的目的是通过给页面建模,使其对应用程序的使用者变得有意义。
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
class Page(object):
'''
基础类,用于页面对象类的继承
'''
login_url='https://mail.163.com/'
def __init__(self, selenium_driver, base_url=login_url):
self.base_url = base_url
self.driver = selenium_driver
self.timeout = 30
def on_page(self):
return self.driver.current_url == (self.base_url + self.url)
def _open(self, url):
url = self.base_url + url
self.driver.get(url)
assert self.on_page(), 'did not land on %s' % url
def open(self):
self._open(self.url)
def find_element(self, *loc):
return self.driver.find_element(*loc)
class LoginPage(Page):
'''
163邮箱登录页面模型
'''
url = '/'
# 定位器
username_loc = (By.NAME, 'email')
password_loc = (By.NAME, 'password')
submit_loc = (By.ID, 'dologin')
#Action
def type_username(self,username):
self.find_element(*self.username_loc).send_keys(username)
def type_password(self,password):
self.find_element(*self.password_loc).send_keys(password)
def submit(self):
self.find_element(*self.submit_loc).click()
def test_user_login(dirver,username,password):
'''
测试获取的用户名/密码是否可以登录
'''
driver = webdriver.Chrome()
login_page=LoginPage(driver)
login_page.open()
# 进入用户名输入页面
driver.find_element_by_xpath('//*[@id="switchAccountLogin"]').click()
# 定位元素的时候一直报无法定位,后面查了资料才发现,这里有一个iframe
iframe = driver.find_element_by_xpath('//div[@id="loginDiv"]/iframe')
driver.switch_to.frame(iframe)
login_page.type_username(username)
login_page.type_password(password)
login_page.submit()
def main():
driver = webdriver.Chrome()
username='****@163.com'
password='******'
test_user_login(driver,username,password)
sleep(10)
#text=driver.find_element_by_id('spnUid').text
#assert(user=='****@163.com'),"用户名称不匹配,登录失败!"
#关闭浏览器窗口
driver.close()
if __name__=='__main__':
main()
Page Object设计模式的实现方法显然使结构变得复杂了很多。下面我们对其进行逐段分析,来体会这样设计的好处。
1.创建page类
首先创建一个基础类Page,在初始化方法__init__()中定义驱动(driver)、基本的URL(base_url)和超时时间(timeout)等。
定义open()方法用于打开URL网站,但它本身并未做到这件事情,而是交由_open()方法来实现。关于URL地址的断言部分,则交由on_page()方法来实现,而find_element()方法用于元素的定位。
2.创建LoginPage类
Page类中定义的这些方法都是页面操作的基本方法。下面根据登录页的特点再创建LoginPage类并继承Page类,这也是Page Object设计模式中最重要的对象层。
LoginPage类中主要对登录页面上的元素进行封装,使其成为更具体的操作方法。例如,用户名、密码和登录按钮都被封装成了方法。
3.创建test_user_login()函数
test_user_login()函数将单个的元素操作组成一个完整的动作,而这个动作包含了打开浏览器、输入用户名/密码、点击登录等单步操作。在使用该函数时需要将driver、username、password等信息作为函数的入参,这样改函数具有很强的可重用性。
4、创建main()函数
main()函数更接近于用户的操作行为。对用户来说,要进行邮箱的登录,需要关心的就是通过哪个浏览器打开邮箱网址、登陆的用户名和密码是什么,至于输入框、按钮是如何定位的,则不需要关心。
这样分层的好处是,不同的层关心不同的问题。页面对象层只关心元素的定位问题,测试用例只关心测试的数据。
一个有分歧的地方是page对象是否应自身包含断言,或者仅仅提供数据给测试脚本来设置断言。在page对象中包含断言的提倡者认为,这有助于避免在测试脚本中出现重复的断言,可以更容易地提供更好的错误信息,并且提供更接近只做不问风格的API。不在page对象中包含断言的倡导者认为,包含断言会混合访问页面数据和实现断言逻辑的职责,并且导致page对象过于臃肿。
笔者赞成在page对象中不包含断言,虽然我们可以通过为常用的断言提供断言库的方式来消除重复,提供更好的诊断,但从用户的角度去自动化的观点来看,判断是否登录成功是用户需要做的事情,不应该交友页面对象层来完成。
使用Page Object模式之后的另一个好处就是有助于降低冗余。如果需要在10个用例中输入不同的用户名/密码登录,那么用main()方法写将会变得非常简洁。
因此,Page Oject模式的作用在一个测试人员自己写主场景测试案例时是不容易体会到的,因为你不需要和开发、业务交流案例,也不会写很多重复的动作。但是,当你真正开始尝试ADDD或BDD,当你开始写一些重要的异常分支流程时,当你开始为新需求频繁维护修改案例时,就会意识到Page Object的作用。
最后,Page Object不是万能药,也不是唯一方案,提高测试案例的可读性,避免案例步骤冗余才是最终目标。