Java实现算法推荐:Mahout实践
推荐系统概述
推荐系统概述
推荐算法分类:
按数据使用划分:
- 协同过滤算法:UserCF, ItemCF, ModelCF
- 基于内容的推荐: 用户内容属性和物品内容属性
- 社会化过滤:基于用户的社会网络关系
按模型划分:
- 最近邻模型:基于距离的协同过滤算法
- Latent Factor Mode(SVD):基于矩阵分解的模型
- Graph:图模型,社会网络图模型
基于用户的协同过滤算法UserCF
基于用户的协同过滤,通过不同用户对物品的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐。简单来讲就是:给用户推荐和他兴趣相似的其他用户喜欢的物品。
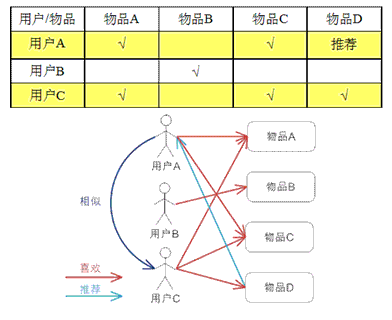
基于用户的 CF 的基本思想相当简单,基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。计算上,就是将一个用户对所有物品的偏好作为一个向量 来计算用户之间的相似度,找到 K 邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。图 2 给出了一个例子,对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居 – 用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。
基于物品的协同过滤算法ItemCF
于item的协同过滤,通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐。简单来讲就是:给用户推荐和他之前喜欢的物品相似的物品。
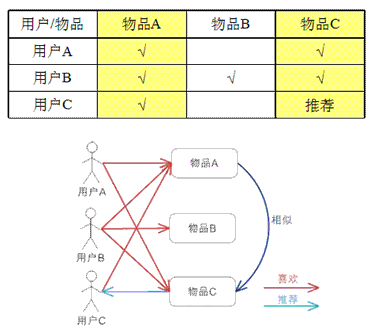
基于物品的 CF 的原理和基于用户的 CF 类似,只是在计算邻居时采用物品本身,而不是从用户的角度,即基于用户对物品的偏好找到相似的物品,然后根据用户的历史偏好,推荐相似的物品给他。从计算 的角度看,就是将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的 物品,计算得到一个排序的物品列表作为推荐。图 3 给出了一个例子,对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户 C 可能也喜欢物品 C。
注:基于物品的协同过滤算法,是目前商用最广泛的推荐算法。
协同过滤算法实现,分为2个步骤
- 计算物品之间的相似度
- 根据物品的相似度和用户的历史行为给用户生成推荐列表
Mathout:
东西太多……还是自己看博客吧
- 从源代码剖析Mahout推荐引擎
- Mahout推荐算法API详解
实战
数据源
取数据库t_recent_listen_00数据,总数据5323626条,导出sql文件导入本地数据库
导入时间大约15个小时后中断,删除user_id为0的数据等数据清理操作,共导入了2019-02-16及之前的收听记录,总条数4866861条
- 节目收听记录538805条
- 书籍收听记录3842982条
- 阅读记录484644条

生成csv格式文件
- book_csv_file.csv
- album_csv_file.csv
- read_csv_file.csv
python生成csv
import pymysql
import csv
import sys
import os
class ToCsv:
def __init__(self):
self.db = pymysql.connect(host='', user='', passwd='', port=3306, db='hi')
self.cursor = self.db.cursor()
self.last_id = 0
self.count = 0
self.book_count = 0
self.album_count = 0
self.read_count = 0
def _release_db(self):
self.db.close()
self.cursor.close()
def _do(self):
while 1:
ret = self._search_data()
if ret == 0:
break
def _search_data(self):
self.cursor.size = 50
sql = 'select * from t_recent_listen_00 where id>%s limit 50'
self.cursor.execute(sql, self.last_id)
lines = self.cursor.fetchall()
if (len(lines) > 0):
self.last_id = lines[len(lines)-1][0]
self.count = len(lines) + self.count;
self._write_cvs(lines)
if (self.count % 1000 == 0):
print(self.count)
return len(lines)
# print(self.last_id)
def _write_cvs(self, lines):
for item in lines:
if (item[10] == 4):
book_cvs_file = open('book_csv_file.csv', 'a', newline='')
book_writers = csv.writer(book_cvs_file)
# book_writers.writerow(['user_id', 'book_id'])
user_id = item[1]
book_id = item[2]
self.book_count += 1
if (self.book_count % 1000 == 0):
print("book count", self.book_count)
book_writers.writerow([str(user_id), str(book_id)])
if (item[10] == 2):
album_cvs_file = open('album_csv_file.csv', 'a', newline='')
album_writers = csv.writer(album_cvs_file)
# album_writers.writerow(['user_id', 'book_id'])
user_id = item[1]
book_id = item[2]
self.album_count += 1
if (self.album_count % 1000 == 0):
print("album count", self.album_count)
album_writers.writerow([str(user_id), str(book_id)])
if (item[10] == 10):
read_cvs_file = open('read_csv_file.csv', 'a', newline='')
read_writers = csv.writer(read_cvs_file)
# album_writers.writerow(['user_id', 'book_id'])
user_id = item[1]
book_id = item[2]
self.read_count += 1
if (self.read_count % 1000 == 0):
print("read count", self.read_count)
read_writers.writerow([str(user_id), str(book_id)])
def main(self):
pass
if __name__ == '__main__':
c = ToCsv()
c._do()
c._release_db()
简单讲解一下,就是读数据库,每次查询50条并写在csv文件最后,自己写的demo写注释太累了
book_csv_file.csv文件大小60M
java实现推荐系统
pom.xml
0.9
...
org.apache.mahout
mahout-core
${mahout.version}
org.apache.mahout
mahout-integration
${mahout.version}
org.mortbay.jetty
jetty
org.apache.cassandra
cassandra-all
me.prettyprint
hector-core
MahoutController
@RestController
@Slf4j
@RequestMapping("/")
public class MahoutController {
@GetMapping
public List mahout(@RequestParam String userId,@RequestParam int type){
//数据模型
DataModel model = null;
List list = Lists.newArrayList();
File cvsFile = null;
try {
long startTime = System.currentTimeMillis();
// File bookCsvFile = ResourceUtils.getFile("classpath:csv/book_cvs_file.csv");
if (type == 1) {
cvsFile = new File("E:\\code\\python\\to_csv\\book_csv_file.csv");
}else if(type == 2){
cvsFile = new File("E:\\code\\python\\to_csv\\read_csv_file.csv");
}else if(type == 3){
cvsFile = new File("E:\\code\\python\\to_csv\\album_csv_file.csv");
}
model = new GenericBooleanPrefDataModel(
GenericBooleanPrefDataModel
.toDataMap(new FileDataModel(cvsFile)));
ItemSimilarity item=new LogLikelihoodSimilarity(model);
//物品推荐算法
Recommender r=new GenericItemBasedRecommender(model,item);
list = r.recommend(Long.parseLong(userId), 10);
list.forEach(System.out::println);
long endTime = System.currentTimeMillis();
log.info((endTime-startTime) +"");
} catch (IOException e) {
e.printStackTrace();
} catch (TasteException e) {
e.printStackTrace();
}
return list;
}
@GetMapping("/user")
public List mahoutUser(@RequestParam String userId,@RequestParam int type){
//数据模型
DataModel model = null;
List list = Lists.newArrayList();
File cvsFile = null;
try {
long startTime = System.currentTimeMillis();
// File bookCsvFile = ResourceUtils.getFile("classpath:csv/book_cvs_file.csv");
if (type == 1) {
cvsFile = new File("E:\\code\\python\\to_csv\\book_csv_file.csv");
}else if(type == 2){
cvsFile = new File("E:\\code\\python\\to_csv\\read_csv_file.csv");
}else if(type == 3){
cvsFile = new File("E:\\code\\python\\to_csv\\album_csv_file.csv");
}
model = new FileDataModel(cvsFile);
//用户相识度算法
UserSimilarity userSimilarity=new LogLikelihoodSimilarity(model);
UserNeighborhood neighborhood = new NearestNUserNeighborhood(20,userSimilarity, model);
Recommender r=new GenericUserBasedRecommender(model, neighborhood, userSimilarity);
list = r.recommend(Long.parseLong(userId), 10);
list.forEach(System.out::println);
long endTime = System.currentTimeMillis();
log.info((endTime-startTime) +"");
} catch (IOException e) {
e.printStackTrace();
} catch (TasteException e) {
e.printStackTrace();
}
return list;
}
}
根据传入user_id来计算出推荐的物品id
结果
测试基于用户协同过滤和基于物品协同过滤输出结果
380万的数据计算一次需要4-6秒,如果实时解析文件生成推荐内容明显会拖累接口相应速度
测试结果还有一点,因为数据的问题csv只生成了用户id与物品id的对应关系,并没有生成用户对物品的打分数据,在实际过程中可以通过最近收听的数据库记录,计算用户听了改资源多长时间来判断用户对物品的喜好程度。
基于用户协同过滤和基于物品协同过滤输出的结果迥异,代码中物品协同过滤算法在不同用户id下返回的数据重复性很高,不大使用,而相比之下,代码中用户协同过滤算法在不同用户id下返回数据看起来比较可靠。实际开发过程中也需要对实际的数据进行判断,否则无法进行很好的推荐,反而会变成一个用户体验很差的功能。
小结
单机版的mahout在实际开发过程中无法胜任实时推荐,特别是在大数量的情况下。
可以考虑后台启动定时任务,每天/每周生成csv文件(python代码中生成csv的代码查数据库很慢……生成了N个小时,java应该会好一些),再通过定时任务计算用户并保存不同用户的不同推荐内容(需要根据实际情况进行判断,毕竟这个量也不小)