# cnn 训练数据 测试数据-> 设计网络架构 -> 训练-> 预测-> 小结
# 对比简单神经网络拟合股价
# A 激励函数+ 矩阵乘加
# A CNN : pool(激励函数+ 矩阵卷积 加法)
# C 激励函数+ 矩阵乘加(A->B)
# C CNN:激励函数+ 矩阵乘加(A->B) + softmax(+ 矩阵乘加)
# loss: tf.reduce_mean(tf.square(y - layer2))
# loss: CNN:code
# 1) import
import random
import tensorflow as tf
# 解决mnist版本弃用警告问题
old_v = tf.logging.get_verbosity()
tf.logging.set_verbosity(tf.logging.ERROR)
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
# 2) load data
mnist = input_data.read_data_sets('MNIST_data', one_hot = True)
# 3) input
imageInput = tf.placeholder(tf.float32, [None, 784]) # 输入图片大小:28 * 28
labelInput = tf.placeholder(tf.float32, [None, 10]) # 参考knn
# 4) data reshape
# 2d -> 4d none * 784 -> M * 28(w) * 28(h) * 1(channel)
imageInputReshape = tf.reshape(imageInput, [-1, 28, 28, 1])
# 5) 卷积
# 权重矩阵 truncated_normal: 正态分布数据 卷积内核: 5 * 5, channel: 1 output: 32 方差:stddev
w0 = tf.Variable(tf.truncated_normal([5, 5, 1, 32], stddev = 0.1))
# 偏移矩阵 bo改变最后一维,因此和w0的最后一维保持一致 -> 32维,值:0.1
b0 = tf.Variable(tf.constant(0.1, shape = [32]))
# 6) layer1 : 激励函数+ 卷积
# imageInputReshape: M * 28 * 28 * 1 w0: 5 * 5 * 1 * 32
# 步长: 当前内核在每一维度上每次移动的步长 padding:same(卷积核可停留在图像边缘)
# -> output : M * 28 * 28 * 32
layer1 = tf.nn.relu(tf.nn.conv2d(imageInputReshape, w0, strides = [1, 1, 1, 1], padding = 'SAME') + b0)
# 数据太大-> pooling 下采样(数据量减少): M * 28 * 28 * 32通过ksize输出-> M * 7 * 7 * 32
# max_pool: [1, 2, 3, 4]-> 4
layer1_pool = tf.nn.max_pool(layer1, ksize = [1, 4, 4, 1], strides = [1, 4, 4, 1], padding = 'SAME')
# 7) 全连接层
# layer2 out: softmax(激励函数+ 乘加) 正态分布的二维数据: [7 * 7 * 32, 1024]
w1 = tf.Variable(tf.truncated_normal([7 * 7 * 32, 1024], stddev = 0.1))
b1 = tf.Variable(tf.constant(0.1, shape = [1024]))
h_reshape = tf.reshape(layer1_pool, [-1, 7 * 7 * 32]) # 4d-> 2d: N * 7 * 7 * 32-> N * N1
# [N , 7 * 7 * 32] matmul [7 * 7 * 32, 1024] -> N * 1024
h1 = tf.nn.relu(tf.matmul(h_reshape, w1) + b1)
# 7.1) softMax
w2 = tf.Variable(tf.truncated_normal([1024, 10], stddev = 0.1))
b2 = tf.Variable(tf.constant(0.1, shape = [10]))
# N * 1024 1024 * 10 -> N * 10
pred = tf.nn.softmax(tf.matmul(h1, w2) + b2)
# N * 10(概率) N1 [0.1 0.2 0.4 0.1 ...] 分别表示0~9出现的概率
# label: [0 0 0 1 0 0 0 0 0 0] 只有一个1
loss0 = labelInput * tf.log(pred) # 减少预测结果的范围
loss1 = 0
# 7.2)
# 累加10维,使均值最小
for m in range(0, 500): # test 500
for n in range(0, 10): # 10维
loss1 = loss1 - loss0[m, n]
loss = loss1 / 500
# 8) train 每次下降0.01
train = tf.train.GradientDescentOptimizer(0.01).minimize(loss)
# 9) run
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(100):
images, labels = mnist.train.next_batch(500) # 每次读取500图
sess.run(train, feed_dict = {imageInput : images, labelInput : labels})
pred_test = sess.run(pred, feed_dict = {imageInput : mnist.test.images, labelInput : labels})
# 比较pred_test与mnist.train.labels pred_test:500图
acc = tf.equal(tf.argmax(pred_test, 1), tf.argmax(mnist.test.labels, 1))
acc_float = tf.reduce_mean(tf.cast(acc, tf.float32))
acc_result = sess.run(acc_float, feed_dict = {imageInput : mnist.test.images, labelInput : mnist.test.labels})
print('acc_result = ', acc_result)
print('END')
准确度的部分值结果如下:
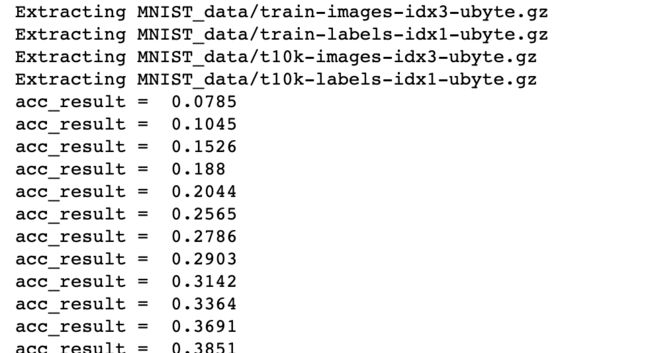
image.png
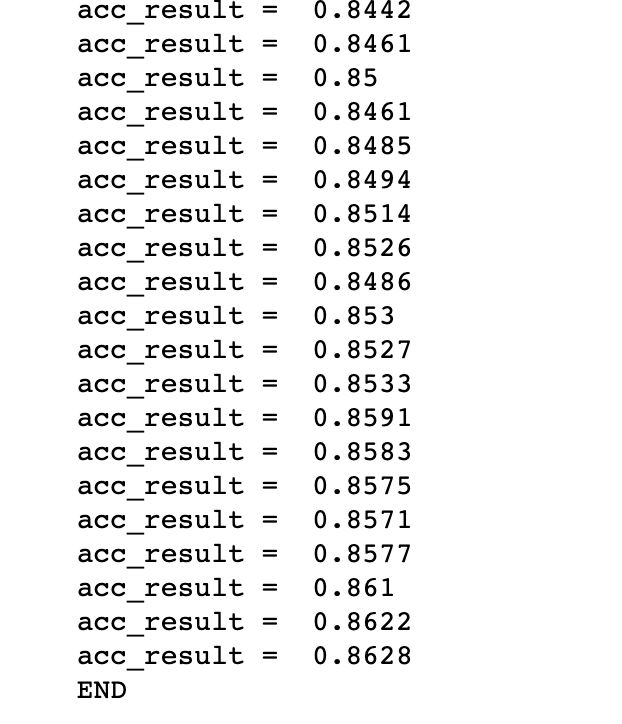
image.png