Rocksdb源码剖析一----Rocksdb概述与基本组件
如需转载,请注明链接及作者,谢谢合作~~
因为本人对一些经典的开源项目很有兴趣,也想从大牛设计的开源系统中学习架构设计经验,所以喜欢分析一些开源代码,这次因为项目中需要使用rocksdb,故在使用的时候仔细分析了rocksdb的实现细节,从2015年11月11日下决心整理出这一系列的blog,也算是对工作的总结吧。分享出来希望能帮到有需要的朋友。因为之前已经读完LevelDB的源码,读的过程中也参考了网上的相关文章,此小节的介绍会与LevelDB有些类似,毕竟rocksdb是基于LevelDB设计实现的,只在一些地方做了优化而已,有些代码甚至都是一样的。源码分析的后面章节会具体分析rocksdb的实现。
Rocksdb是facebook开源的NOSQL存储系统,其设计是基于Google开源的Leveldb,优化了LevelDB中存在的一些问题,其性能号称要比LevelDB强,rocksdb的设计跟Leveldb的极其类似,读过LevelDB源码的再读rocksdb的源码基本毫无压力,rocksdb也包括了内存memtable,LRUcache,磁盘上的sstable,operation log等等。本系列就是从rocksdb的源码级别来分析其设计实现与性能
既然rocksdb是基于leveldb设计实现并优化了一些细节,那我们先看一下leveldb的基本框架,
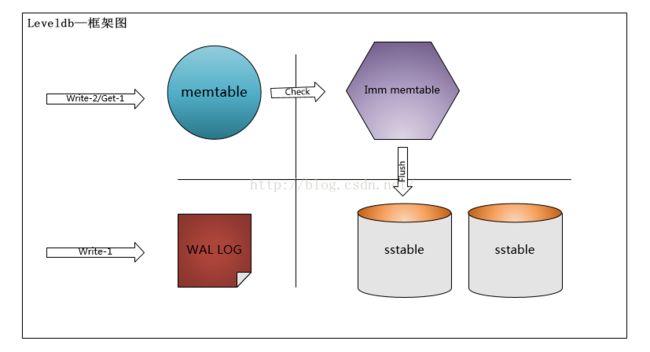
图1-1
由该架构图可以看到,Leveldb是由memtable, immute memtable,wal log,sstable组成内存中的memtalbe与imm memtable各为一个,imm memtable是由memtable达到阈值后转化而成的,其数据结构是一样的。这里对于Leveldb的具体实现细节这里不详细论述,有兴趣的可以参考下其它Leveldb的源码分析,或者继续看后续分析章节,对理解Leveldb也很有帮助。
rocksdb对leveldb的优化有:
- 增加了column family,有了列簇的概念,可把一些相关的key存储在一起,column famiy的设计挺有意思的,后面会单独分析
- 内存中有多个immute memtalbe,可防止Leveldb中的 write stall
- 可支持多线程同时compation,理论上多线程同时comaption会比一个线程compation要快
- 增加了merge operator,也就是原地更新,优化了modify的效率
- 支持DB级的TTL
- flush与compation分开不同的线程池来调度,并具有不同的优先级,flush要优于compation,这样可以加快flush,防止stall
- 对SSD存储做了优化,可以以in-memory方式运行
- 增加了对 write ahead log(WAL)的管理机制,更方便管理WAL,WAL是binlog文件
-
上面只要简单的总结,更多的细节还需要进一步分析,rocksdb的基本框架如下图,
 图1-2从图1-1与图1-2可以看出,Leveldb的框架与Rocksdb的框架十分类似,rocksdb从3.0开始支持ColumnFamily的概念,所以我们从ColumnFamily的角度来看rocksdb的框架,
图1-2从图1-1与图1-2可以看出,Leveldb的框架与Rocksdb的框架十分类似,rocksdb从3.0开始支持ColumnFamily的概念,所以我们从ColumnFamily的角度来看rocksdb的框架,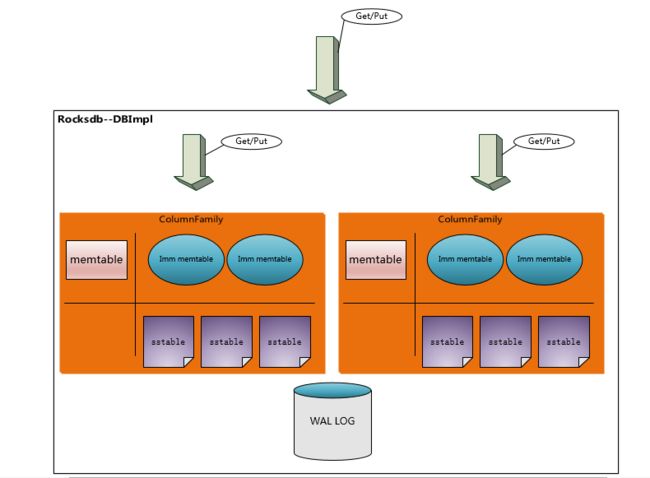
每个columnfamilyl的meltable与sstable都是分开的,所以每一个column family都可以单独配置,所有column family共用同一个WAL log文件,可以保证跨column family写入时的原子性Rocksdb同样是一种基于operation log的文件系统,由于采用了op log,将对磁盘的随机写转换成了对op log的顺序写,最新的数据是存储在内存的memrory中,可以提高IO效率。每一个的column family分别有一个memtable与sstablle.当某一coloumn family内存中的memory table超过阈值时, 转换成immute memtable并创建新的op log,immute memtable由一系列的memtable组成,它们是只读的,可供查询,不能更新数据。当immute memtable的数目超过设置的数值时,会触发flush,DB会调度后台线程将多个memtable合并后再dump到磁盘生成Level0中一个新的sstable文件,Level0中的sstable文件不断累积,会触发compaction,DB会调度后台compaction线程将Level0中的sstable文件根据key与Level1中的sstable合并并生成新的sstable,依次类推,根据key的空间从低层往上compact,最终形成了一层层的结构,层级数目是由用户设置的。
二.
在阅读rocksdb源码前,需要提前储备下一些基本知识,要是对LevelDB的架构已经比较熟悉的话,基本可以略过此处,开始关注后面的章节。
必备知识点
1. 字节序
rocksdb中与leveldb类似,数字的存储是little-endian的,也就是说在把int32与int64转换成char*的函数中,是按照先低位再高位的顺序存放的。
2. Varint
在把int32或int64转换到字符串中时,为减小存储空间,采用变长存储,也就是VarInt。变长存储的实现与PB中的基本一样,即每byte的有效存储是7bit的,最高的8bit位表示是否结束, 最高bit位为1时,表示后面还有一个byte的数字,为0时,表示已经结束,具体实现可参考Encodexxx和Decodexxx系列函数
3. 基本数据结构
3.1 Slice
rocksdb的基本数据结构,成员包括length与一个指向外部存储空间的指针,是二进制安全的,可以包含‘\0',提供了一些可与string/char*相互转换的接口,
3.2 Status
rocksdb的状态类,将错误号与错误信息封装,同样是为了节省空间,Status类将返回码,错误信息与长度打包存储在一个字符数组中。
格式如下:
state_[0..3] == 消息长度
state_[4] == 消息code
state_[5..] ==消息
3.3 Arena
rocksdb的简单内存池,
申请内存时,将申请到的内存块放入std::vector blocks_中,在Arena的生命周期结束后,统一释放掉所有申请到的内存,内部结构如图1-3所示。
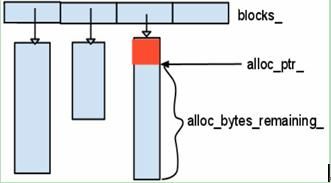
图1-3
另外,rocksdb同样可以使用tcmalloc与jemalloc,在性能方面还是会有不小的提升.
3.4memtable
leveldb中,memtable在内存中核心s的数据结构为skiplist,而在rocksdb中,memtable在内存中的形式有三种:skiplist、hash-skiplist、hash-linklist,从字面中就可以看出数据结构的大体形式,hash-skiplist就是每个hash bucket中是一个skiplist,hash-linklist中,每个hash bucket中是一个link-list,启用何用数据结构可在配置中选择,下面是skiplist的数据结构:

图1-4
下面是hash-skiplist的结构,

图1-5
下面是hash-linklist的框架图,
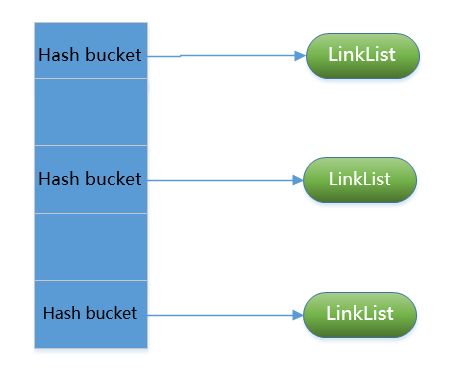
图1-6
3.5 Cache
rocksdb内部根据双向链表实现了一个标准的LRUCache,由于LRUCache的设计实现比较通用经典,这里详细分析一下LRUCache的实现过程,根据LRUCache的从小到大的顺序来看基本组件,
A. LRUHandle结构体,Cache中最小粒度的元素,代表了一个k/v存储对,下面是LRUHandle的所有信息,
struct LRUHandle {
void* value; // value信息
void (*deleter)(const Slice&, void* value); //删除元素时,可调用的回调函数
LRUHandle* next_hash; //解决hash冲突时,使用链表法
LRUHandle* next;//next/prev构成了双链,由LRU算法使用
LRUHandle* prev;
size_t charge; // TODO(opt): Only allow uint32_t?
size_t key_length; //key的长度
uint32_t refs; // a number of refs to this entry
// cache itself is counted as 1
bool in_cache; // true, if this entry is referenced by the hash table
uint32_t hash; // Hash of key(); used for fast sharding and comparisons
char key_data[1]; // Beginning of key
Slice key() const {
// For cheaper lookups, we allow a temporary Handle object
// to store a pointer to a key in "value".
if (next == this) {
return *(reinterpret_cast(value));
} else {
return Slice(key_data, key_length);
}
}
void Free() {
assert((refs == 1 && in_cache) || (refs == 0 && !in_cache));
(*deleter)(key(), value);
free(this);
}
};
B. 实现了rocksdb自己的HandleTable,其实就是实现了自己的hash table, 速度号称比g++4.4.3版本自带的hash table的速度要快不少
class HandleTable {
public:
HandleTable() : length_(0), elems_(0), list_(nullptr) { Resize(); }
template
void ApplyToAllCacheEntries(T func) {
for (uint32_t i = 0; i < length_; i++) {
LRUHandle* h = list_[i];
while (h != nullptr) {
auto n = h->next_hash;
assert(h->in_cache);
func(h);
h = n;
}
}
}
~HandleTable() {
ApplyToAllCacheEntries([](LRUHandle* h) {
if (h->refs == 1) {
h->Free();
}
});
delete[] list_;
}
LRUHandle* Lookup(const Slice& key, uint32_t hash) {
return *FindPointer(key, hash);
}
LRUHandle* Insert(LRUHandle* h) {
LRUHandle** ptr = FindPointer(h->key(), h->hash);
LRUHandle* old = *ptr;
h->next_hash = (old == nullptr ? nullptr : old->next_hash);
*ptr = h;
if (old == nullptr) {
++elems_;
if (elems_ > length_) {
// Since each cache entry is fairly large, we aim for a small
// average linked list length (<= 1).
Resize();
}
}
return old;
}
LRUHandle* Remove(const Slice& key, uint32_t hash) {
LRUHandle** ptr = FindPointer(key, hash);
LRUHandle* result = *ptr;
if (result != nullptr) {
*ptr = result->next_hash;
--elems_;
}
return result;
}
private:
// The table consists of an array of buckets where each bucket is
// a linked list of cache entries that hash into the bucket.
uint32_t length_;
uint32_t elems_;
LRUHandle** list_;
// Return a pointer to slot that points to a cache entry that
// matches key/hash. If there is no such cache entry, return a
// pointer to the trailing slot in the corresponding linked list.
LRUHandle** FindPointer(const Slice& key, uint32_t hash) {
LRUHandle** ptr = &list_[hash & (length_ - 1)];
while (*ptr != nullptr &&
((*ptr)->hash != hash || key != (*ptr)->key())) {
ptr = &(*ptr)->next_hash;
}
return ptr;
}
void Resize() {
uint32_t new_length = 16;
while (new_length < elems_ * 1.5) {
new_length *= 2;
}
LRUHandle** new_list = new LRUHandle*[new_length];
memset(new_list, 0, sizeof(new_list[0]) * new_length);
uint32_t count = 0;
for (uint32_t i = 0; i < length_; i++) {
LRUHandle* h = list_[i];
while (h != nullptr) {
LRUHandle* next = h->next_hash;
uint32_t hash = h->hash;
LRUHandle** ptr = &new_list[hash & (new_length - 1)];
h->next_hash = *ptr;
*ptr = h;
h = next;
count++;
}
}
assert(elems_ == count);
delete[] list_;
list_ = new_list;
length_ = new_length;
}
};
HandleTable的结构也是很简单,就是连续一些hash slot,然后用链表法解决hash 冲突,

图1-7
C. LRUCahe
LRUCache是由LRUHandle与HandleTable组成,并且LRUCache内部是有锁的,所以外部多线程可以安全使用。
HandleTable很好理解,就是把Cache中的数据hash散列存储,可以加快查找速度;
LRUHandle lru_是个dummy pointer,也就是双链表的头,也就是LRU是由双链表保存的,队头是最早进入Cache的,队尾是最后进入Cache的,所以,在Cache满了需要释放空间的时候是从队头开始的,队尾是刚进入Cache的元素
class LRUCache {
public:
LRUCache();
~LRUCache();
// Separate from constructor so caller can easily make an array of LRUCache
// if current usage is more than new capacity, the function will attempt to
// free the needed space
void SetCapacity(size_t capacity);
// Like Cache methods, but with an extra "hash" parameter.
Cache::Handle* Insert(const Slice& key, uint32_t hash,
void* value, size_t charge,
void (*deleter)(const Slice& key, void* value));
Cache::Handle* Lookup(const Slice& key, uint32_t hash);
void Release(Cache::Handle* handle);
void Erase(const Slice& key, uint32_t hash);
// Although in some platforms the update of size_t is atomic, to make sure
// GetUsage() and GetPinnedUsage() work correctly under any platform, we'll
// protect them with mutex_.
size_t GetUsage() const {
MutexLock l(&mutex_);
return usage_;
}
size_t GetPinnedUsage() const {
MutexLock l(&mutex_);
assert(usage_ >= lru_usage_);
return usage_ - lru_usage_;
}
void ApplyToAllCacheEntries(void (*callback)(void*, size_t),
bool thread_safe);
private:
void LRU_Remove(LRUHandle* e);
void LRU_Append(LRUHandle* e);
// Just reduce the reference count by 1.
// Return true if last reference
bool Unref(LRUHandle* e);
// Free some space following strict LRU policy until enough space
// to hold (usage_ + charge) is freed or the lru list is empty
// This function is not thread safe - it needs to be executed while
// holding the mutex_
void EvictFromLRU(size_t charge,
autovector* deleted);
// Initialized before use.
size_t capacity_;
// Memory size for entries residing in the cache
size_t usage_;
// Memory size for entries residing only in the LRU list
size_t lru_usage_;
// mutex_ protects the following state.
// We don't count mutex_ as the cache's internal state so semantically we
// don't mind mutex_ invoking the non-const actions.
mutable port::Mutex mutex_;
// Dummy head of LRU list.
// lru.prev is newest entry, lru.next is oldest entry.
// LRU contains items which can be evicted, ie reference only by cache
LRUHandle lru_;
HandleTable table_;
};
到这,我们从设计现实就能看出一个标准的LRUCache已经成形了,接下来更有意思的是rocksdb又实现了一个ShardedLRUCache,它就是一个封装类,实现了分片LRUCache,在多线程使用的时候,根据key散列到不同的分片LRUCache中,以降低锁的竞争,尽量提高性能。下面一行的代码是一目了然,
LRUCache shard_[kNumShards]
D. 另一个很有用的就是ENV,基于不同的平台继承实现了不同的ENV,提供了系统级的各种实现,功能很是强大,对于想做跨平台软件的同学很有借鉴意义。ENV的具体实现就不贴了,主要就是太多。对于其它的工具类,具体可参考src下的相关实现。
PS : csdn的编辑器真心难用,后面准备该系列的blog转到github上,~另外,仓促写了第一篇,就是敦促自己赶紧把后面的一系列抓紧写完,不再拖拉~~