Deeplearning4j 实战 (17):基于SameDiff自动微分工具的CNN建模
Eclipse Deeplearning4j GitChat课程:https://gitbook.cn/gitchat/column/5bfb6741ae0e5f436e35cd9f
Eclipse Deeplearning4j 系列博客:https://blog.csdn.net/wangongxi
Eclipse Deeplearning4j Github:https://github.com/eclipse/deeplearning4j
在之前的文章中我们介绍了Deeplearning4j/ND4j中的自动微分工具SameDiff的基本使用和可视化方法,这篇文章我们介绍下如何使用SameDiff建模CNN网络,主要涉及卷积、池化等经典的CNN OP,使用的数据集也是之前我们介绍过的Mnist手写体数字数据集。我们尝试使用SameDiff提供的CNN相关算子搭建类似LeNet-5结构的卷积神经网络来对Mnist数据集进行分类。由于在之前的博客中我们并没有详细阐述过CNN的理论,因此我们先重新梳理下CNN的原理并且回顾下LeNet-5经典结构,在最后我们给出SameDiff建模的具体逻辑和训练评估结果。
1. 卷积神经网络的计算原理
卷积神经网络(CNN)最早成功应用于机器视觉领域,包括但不仅限于图像分类、主体检测、语义分割等场景。目前CNN结构也广泛用于自然语言处理领域和语音识别领域。我们这里重点讨论在图像领域的应用。对于计算机来说,图像信号和一个数字矩阵没有什么本质的不同,只不过灰度图和RGB图像的通道数不同使得这个数字矩阵的维度有所不同。数字矩阵本身没什么语义信息,但在成像之后人的肉眼具备提取其语义的能力。这里的语义可以是轮廓、颜色、纹理等特征,也可以是人、动物、植物这样具备物理意义的主体内容。早期的机器视觉的任务主要集中在特征提取的工作上,对于特征提取后采用的是SVM还是Tree-based模型其实效果的提升不是很显著,换言之,早期特征的质量决定了应用的上限。我们至今熟悉的SIFT、HOG特征依然是这些工作中的杰出成果。卷积神经网络其实是将特征提取这块的工作和后续的机器学习建模结合在一起,做成了一个end-to-end的应用。开发人员不用关心CNN到底提取了什么样的特征来做后续的工作,而只需要将原始信号作为输入喂到CNN中,输出则是我们所关心的结果。
但作为开发人员来说,仅仅是知道这些操作过程是不可能完成一个成功的应用的,因为当模型整体的效果不好的时候,评估指标不理想的时候,如何调优的问题其实就是对CNN原理进一步加深了解的问题。虽说深度学习的解释性很差,而且很多时候连凸优化理论都不满足,但是这并不是开发人员不去了解或者回避其计算原理的借口。至少,对于CNN中的OP都在做什么,为什么可能会work,需要有自己的理解和经验积累。我们回到CNN的原理上,先看下面的这张图。
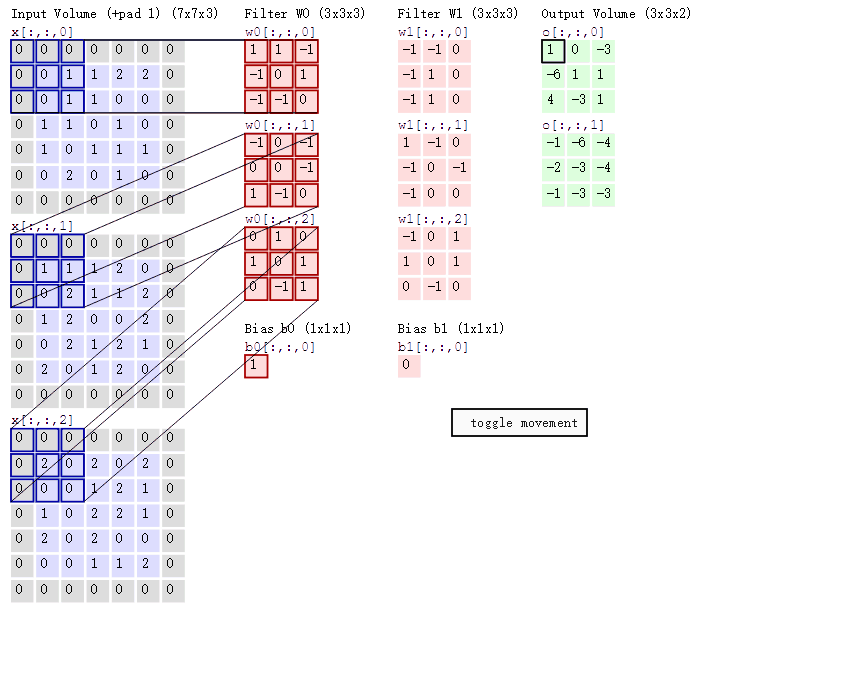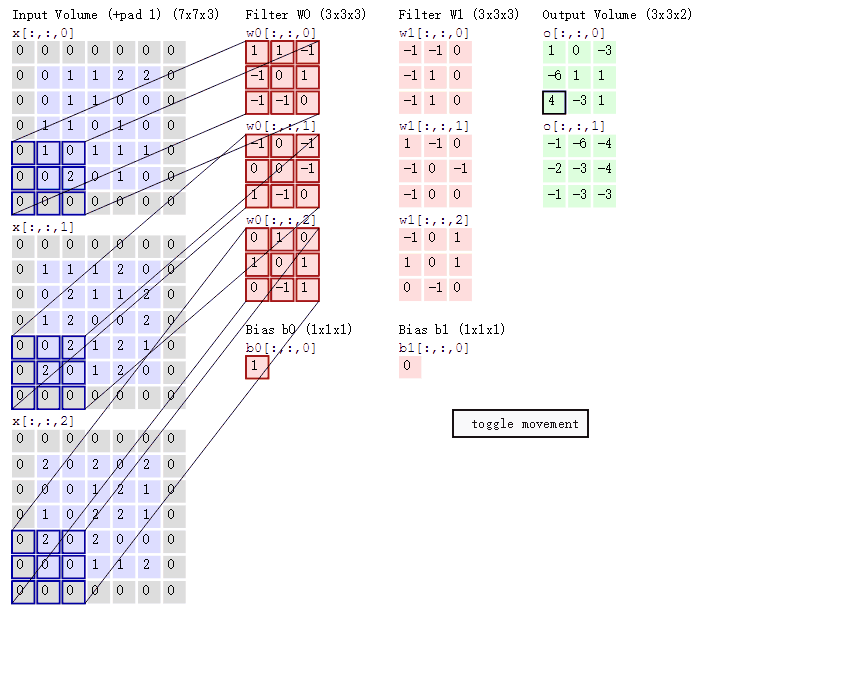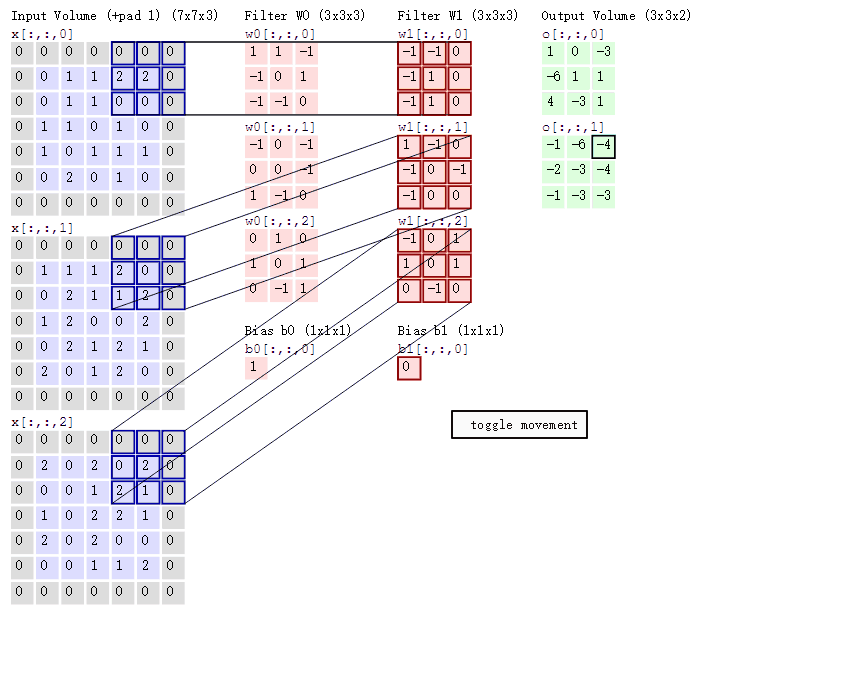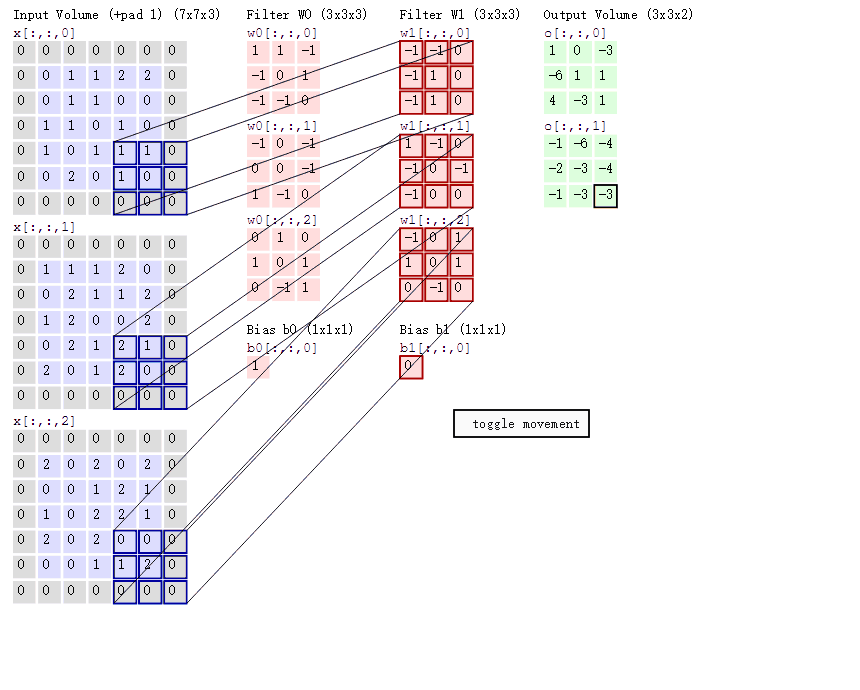
图中一共有4列,Input Volume/ Filter W0/ Filter W1/ Output Volume。Input Volume可以认为就是原始图像信号,这里Input Volume有三个数字矩阵,那就可以理解成RGB三个通道。Filter W0和Filter W1,它们可以被称为滤波器或者卷积核,本质上也是一个数值矩阵,只不过相对于输入的图像信号来说小很多。Filter矩阵中的数值可以是服从某种分布生成的,它的主要作用是和Input Volume的数值矩阵进行所谓的卷积运算。这里的卷积其实和深度学习本身没什么直接关系,它是一种存在已久的信号处理手段,详情可见郑君里老师的《信号与系统》一书中相关章节的描述。在CNN中,Filter和Input Volume的卷积运算,其实是Filter数值矩阵和Input Volume对应位置的子矩阵进行Hadamard乘积并加和。所谓Hadamard乘积就是两个size完全相同的数值矩阵,对应位置做乘法计算。这个操作其实并不复杂,那么它的作用是什么呢?其实就是提取图像中的特征。用Filter提取的特征你很难用颜色或者纹理这些带有具体物理含义的去描述,也就是其可解释性并不是那么好。但是在模型训练过程中,Filter数值矩阵中的值会不断调整,使得Filter提取的特征不断得为拟合最终的目标而服务。也就是说,特征提取的方式是在训练中不断优化的,提取的特征也是在不断调整的,这和原来静态的特征提取方式相比显然更加智能。
卷积神经网络有三个特点:局部感知、权值共享以及池化下采样。局部感知其实就是上述的Filter,这个size不大的数值矩阵和对应图片中的部分区域做特征提取的过程。由于Filter的size一般不是很大,因此其关注的区域肯定是图片的局部,因此称为局部感知。权值共享指的是Filter矩阵中的数值不会随着扫描原始图片局部区域的不同而不同,从某种意义上说,一个固定的Filter只能从图片中提取一类特征,如果觉得不够,那么可以设置多个Filter。像截图里,我们可以看到就是有两个Filter,它们的数值不尽相同,因为提取的特征也就不一样了,也许一个是形状一个是颜色。池化下采样我们来看下下面的截图。

截图是最大池化(max-pooling)。我们可以看到,每个不同颜色区域的四个数值内,我们选取的数值最大的那个数作为输出的结果。最大池化的物理含义可以认为是我们选择了局部区域内最具有代表性的特征作为输出。池化的另一个好处在于,输出的数值矩阵的size显著减小了,也就是维度降低了。除了最大池化外,另一个常用的是平均池化(average-pooling),也就是将局部区域中的数值加权平均作为输出。这两种最为常用。
卷积神经网络中的经常提到的几个术语,这里也顺便罗列下。
- 卷积核/滤波器(kernel/filter):通常为22,33,5*5大小的一个数值矩阵,用于提取图像局部特征
- 池化(pooling):亦称下采样,主要用于减小特征维度和选择特征的作用
- 步长(stride):卷积或者池化过程中每次移动的像素点的数量
- 特征图(feature map):卷积或者池化操作的输出,一般是几十个二维数值矩阵
- 填充(padding):在原图像外围填充数字(比如:0),用于多次提取图像的边缘特征
2. LeNet-5结构回顾
我们先来看张图。
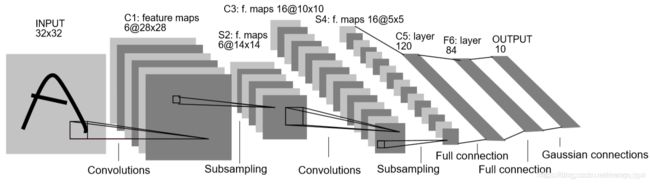
Lenet-5是一个具体里程碑意义的卷积神经网络结构,无论是后来的AlexNet还是GoogLenet、Resnet
等等都或多或少从中获取了灵感。从截图中可以明显的看出卷积+池化/下采样+卷积+池化/下采样+全连接+全连接的结构。Lenet-5每一层的输入输出的维度在截图里都有说明,网上的很多博客都有详细说明,这里我就不多重复了。需要注意的是,在Lenet-5的论文《Gradient-based learning applied to document recognition》中,和现代卷积神经网络有不同的是在于Lenet-5的激活函数还是以sigmoid为主,现代的cnn网络基本上都是relu系的激活函数。另外,对于多分类问题,现代网络多用softmax,而Lenet-5的输出是基于径向基函数(RBF)来计算全连接输出层的向量和标准输出之间的欧式距离。更多信息建议去看下Yann Lecun老爷子的论文。
3. SameDiff建模Mnist数据集
这个部分我们就介绍基于SameDiff工具如何建模卷积神经网络。我们主要是参考了Lenet-5的网络结构,只不过诸如filter、feature map的数量和论文中会有所不同。首先我们需要创建SameDiff建模的上下文以及部分配置项
//SameDiff上下文声明
SameDiff sd = SameDiff.create();
//Mnist数据集size声明
int nIn = 28 * 28;
int nOut = 10;
//卷积和池化操作的配置项
Conv2DConfig layer1ConvConfig = Conv2DConfig.builder()
.kH(5) //filter height
.kW(5) //filter width
.sH(1) //stride height
.sW(1) //stride height
.pH(0) //padding height
.pW(0) //padding width
//.isSameMode(true)
.build();
Conv2DConfig layer2ConvConfig = Conv2DConfig.builder()
.kH(5)
.kW(5)
.sH(1)
.sW(1)
.pH(0)
.pW(0)
//.isSameMode(true)
.build();
Pooling2DConfig layer1PoolConfig = Pooling2DConfig.builder()
.kH(2) //filter height
.kW(2) //filter width
.sH(2) //stride height
.sW(2) //stride width
.type(Pooling2DType.MAX)//max-pooling
.build();
Pooling2DConfig layer2PoolConfig = Pooling2DConfig.builder()
.kH(2) //filter height
.kW(2) //filter width
.sH(2) //stride height
.sW(2) //stride width
.type(Pooling2DType.MAX)//max-pooling
.build();
这部分声明主要分为三个部分。首先我们需要声明SameDiff的上下文环境,接着针对我们建模的数据集进行输入和输出size的声明。Mnist数据集是2828的灰度图,共0~9这10个类别,因此我们的输入和输出需要做个声明。第三部分就是卷积和池化的配置项。我们声明4个配置项,分别是CNN网络第一层和第二层的卷积与池化操作涉及的filter、stride和padding相关的size。这里第一层和第二层的设置其实是一样的,之所以声明成4个对象实例而不是2个,主要是方便开发人员后续修改它们的配置参数。我们各举一个实例的配置进行说明,首先是layer1ConvConfig。卷积核的大小这里我们设置成55,也就是kH和kW的大小。接着是步长stride的大小,这里我们设置成1*1,也就是filter每次移动一个像素点的位置。padding这里我们设置成0,也是默认设置,即不考虑外围的padding状况,如果需要尝试的开发人员可以自行设置。接着说明下layer1PoolConfig的参数。池化同样涉及filter和stride的size设置,这个和卷积操作的设置是类似的。另外,我们通过.type(Pooling2DType.MAX)开设置池化的方式,这里我们使用的是最大池化,开发人员也可以根据自己的需要设置成诸如平均池化等其他方式。下面我们声明下输入和输出的placeholder。
//Create input and label variables
SDVariable in = sd.placeHolder("input", DataType.FLOAT, -1, nIn); //Shape: [?, 784] - i.e., minibatch x 784 for MNIST
SDVariable label = sd.placeHolder("label", DataType.FLOAT, -1, nOut); //Shape: [?, 10] - i.e., minibatch x 10 for MNIST
SDVariable reshaped = in.reshape(-1, 1, 28, 28); //[numBatch, C, W, H]
这里我们声明了两个placeholder的实例,作用是用来接收训练数据的输入和输出。需要注意的是,我们采用的是mini-batch的SGD算法进行模型优化,因此在声明placeHolder的时候我们用-1来标识未知大小,类似于TF中的None设置:tf.placeholder(tf.float32, [None, 784])。同理,标注结果的placeholder也是类似的设置。由于从Mnist二进制数据集中读取的是784的向量,而CNN网络对二维数据进行处理,因此我们需要重构下数据的shape,这里和TF的OP也是一样的,调下reshape接口,就可以拿到[numBatch, C, W, H]维度的张量数据。这里C表示Channel,即通道数,W和H就是图片的宽和高。下面我们看下第一层卷积层的结构声明
// layer 1: Conv2D with a 5x5 kernel and 20 output channels
SDVariable w0 = sd.var("w0", new XavierInitScheme('c', 28 * 28 * 1, 24 * 24 * 20), DataType.FLOAT, 5, 5, 1, 20);
SDVariable b0 = sd.zero("b0", 20);
SDVariable conv1 = sd.cnn().conv2d(reshaped, w0, b0, layer1ConvConfig);
这里声明了两个Variable对象实例,w0和b0。这是CNN需要训练的两个参数。w0含有55120个数值的卷积核。从其shape来看,共有20个卷积核(也意味着经过第一层卷积后会有20个feature map的输出,输出的数值矩阵的shape是2424*20)。XavierInitScheme是用来做参数初始化的策略。b0是偏置项,这里我们直接用zero来把20个数值全部初始化为0。最后我们调用conv2d这个方法来进行第一层的卷积操作,这个和TF中的conv2d的接口也是类似的。下面我们来看下第二层的张量操作,也就是最大池化。
// layer 2: MaxPooling2D with a 2x2 kernel and stride, and ReLU activation
SDVariable pool1 = sd.cnn().maxPooling2d(conv1, layer1PoolConfig);
SDVariable relu1 = sd.nn().leakyRelu(pool1, 0.5);
我们将上面卷积操作得到的张量对象conv1作为入参输入到maxPooling2d的方法中,同时传入的是第一层的max-pooling的配置,这个OP得到的张量变量就是最大池化的结果。紧接着我们调用了非线性激活函数leakyRelu来提取非线性特征。那么到此,第一部分的卷积+池化就完成了。下面第二部分的张量操作也是类似的,我们直接给出第二部分的卷积+池化操作。
// layer 3: Conv2D with a 5x5 kernel and 50 output channels
SDVariable w1 = sd.var("w1", new XavierInitScheme('c', 12 * 12 * 20, 8 * 8 * 50), DataType.FLOAT, 5, 5, 20, 50);
SDVariable b1 = sd.zero("b1", 50);
SDVariable conv2 = sd.cnn().conv2d(relu1, w1, b1, layer2ConvConfig);
// layer 4: MaxPooling2D with a 2x2 kernel and stride, and ReLU activation
SDVariable pool2 = sd.cnn().maxPooling2d(conv2, layer2PoolConfig);
SDVariable relu2 = sd.nn().leakyRelu(pool2, 0.5);
这个和第一部分是类似的,我就不再多做解释了。下面我们参考Lenet-5最后两层的结构,将池化后的结果展开成全连阶层。
SDVariable flat = relu2.reshape(-1, 4 * 4 * 50);
// layer 5: MLP layer
SDVariable wOut = sd.var("wOut", new XavierInitScheme('c', 4 * 4 * 50, 400), DataType.FLOAT, 4 * 4 * 50, 400);
SDVariable bOut = sd.zero("bOut", 400);
SDVariable relu3 = sd.nn().leakyRelu(flat.mmul(wOut).add(bOut), 0.5);
// layer 6: Output layer
SDVariable wFinalOut = sd.var("wFinalOut",new XavierInitScheme('c', 400, 10), DataType.FLOAT, 400, 10);
SDVariable bFinalOut = sd.zero("bFinalOut", 10);
倒数第二层的全连阶层是一个800 * 400的全连阶层,而最后的一层全连阶层也就是输出层是一个400 * 10的前馈网络层。输出的10个神经元就对应label 0~9。最后我们定义下loss函数。
SDVariable feedforwardResult = sd.nn().linear("z", relu3, wFinalOut, bFinalOut);
// softmax crossentropy loss function
SDVariable loss = sd.loss().softmaxCrossEntropy("loss", label, feedforwardResult);
sd.setLossVariables(loss);
我们将最终得到的网络输出和标准的label作为入参喂到损失函数softmaxCrossEntropy中,并且在上下文中设置下这个loss变量。那么到此,CNN的建模工作就全部完成了。我们可以通过summary接口来看下网络涉及的哪些Variable和OP。
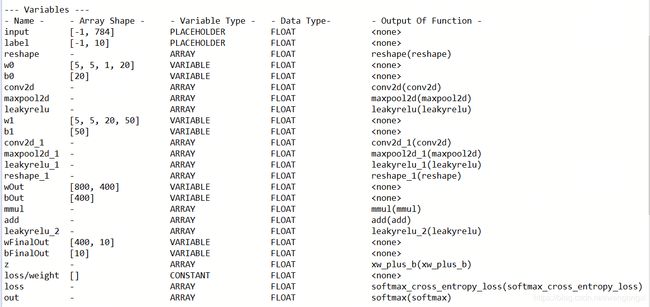
这张截图里我们可以看到在实现过程中所有涉及的placeholder、variable以及constant。

上图是所有涉及的张量变换操作。
最后我们给出读取数据和训练模型的相关逻辑。
Evaluation evaluation = new Evaluation();
double learningRate = 1e-2;
TrainingConfig config = new TrainingConfig.Builder()
.l2(1e-3) //L2正则化
.updater(new Adam(learningRate)) //Adam优化器
.dataSetFeatureMapping("input") //输入数据的变量名
.dataSetLabelMapping("label") //输出数据变量名
.trainEvaluation("out", 0, evaluation) //评估涉及的变量名
.build();
sd.setTrainingConfig(config);
sd.addListeners(new ScoreListener(1)); //loss监听器
int batchSize = 32;
//Mnist数据集读取
DataSetIterator trainData = new MnistDataSetIterator(batchSize, true, 12345);
int numEpochs = 10;
History hist = sd.fit()
.train(trainData, numEpochs)
.exec();
//评估模型
List acc = hist.trainingEval(Metric.ACCURACY);
System.out.println("Accuracy: " + acc);

从控制台打印的日志中可以看到在模型训练过程中loss值的下降情况,以及最后在训练集上的评估结果。如果开发人员需要进一步提升模型的准确率,那么可以从超参数层面以及模型结构层面进行调整,这里不多展开。以上就是基于SameDiff进行了完整的CNN建模逻辑,可以作为入门SameDiff使用的一个参考。
4. 小结
这篇文章我们主要介绍了基于SameDiff的类Lenet-5结构的CNN网络建模以及结合Mnist数据集进行测试。SameDiff的建模方式在之前的文章中我们已经有过介绍,大体的方式是一致的,需要先声明SameDiff上下文环境以及结合ND4j提供的OP构建整个CNN模型。在定义完网络结构以及相关的损失函数以后,我们就可以准备建模数据,设置训练的一些超参数。
SameDiff建模相比于Deeplearning4j原先提供的基于Layer提供的建模方式会比较繁琐,甚至更关注于张量的数据变换而没有整体的网络结构。但是,对于从事科研工作的人员来说,自定义OP并验证整体效果会非常方便,而对于工业界的开发来说,和Keras或者TF2.0接口更像的基于Layer的建模方式会有更高的工作效率,所以还是看各自的需要来使用。