SpringBoot整合Redis集群
1、前提
需要搭建好redis集群,并且远程可访问。此博文基于Linux环境搭建的redis集群,端口从7001到7006,一共6个redis实例。启动集群后,可以使用RedisDeskTopManager连接上。我踩的坑:
Linux环境下,可以进入每个redis实例并进行操作。然后springboot整合好redis集群后,进行set和get操作时,一直显示:redis.clients.jedis.exceptions.JedisNoReachableClusterNodeException: No reachable node in cluster错误。以为是代码错误,以为是整合有问题,以为是集群没有搭建好,以为是防火墙没有关闭。。。反复查看了代码和整各过程,重新搭建了集群,关闭了防火墙,还是报这个错。结果到最后发现是Linux网路配置问题,之前是NAT模式,后来改成了仅主机模式,最终改成了仅主机模式后解决了这个问题。这个时候,可以用RedisDeskTopManager连接上redis集群中的单个redis实例,代码也不报错了。所以,整合的时候,可以使用RedisDeskTopManager提前连接一下,确定是否可以访问连接。
2、redis集群需要额外引入的pom依赖
org.springframework.boot
spring-boot-starter-data-redis
redis.clients
jedis
4、主类
@SpringBootApplication
@EnableCaching
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}5、配置文件:application.properties
#redis集群
# Redis服务器地址spring.redis.host=10.100.50.23
# Redis服务器连接端口
#spring.redis.port=6379
# Redis服务器连接密码(默认为空)
spring.redis.password=
# 连接池最大连接数(使用负值表示没有限制)
spring.redis.jedis.pool.max-active=8
# 连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.jedis.pool.max-wait=-1
# 连接池中的最大空闲连接
spring.redis.jedis.pool.max-idle=8
# 连接池中的最小空闲连接
spring.redis.jedis.pool.min-idle=1
# 连接超时时间(毫秒)
spring.redis.timeout=1
spring.redis.commandTimeout=5000
# redis.cluster
spring.redis.cluster.nodes=192.168.213.129:7001,192.168.213.129:7002,192.168.213.129:7003,192.168.213.129:7004,192.168.213.129:7005,192.168.213.129:7006
6、RedisClusterConfig,此类返回一个JedisCluster对象。
@Configuration
@ConditionalOnClass({JedisCluster.class})
public class RedisClusterConfig {
@Value("${spring.redis.cluster.nodes}")
private String clusterNodes;
@Value("${spring.redis.timeout}")
private int timeout;
@Value("${spring.redis.jedis.pool.max-idle}")
private int maxIdle;
@Value("${spring.redis.jedis.pool.max-wait}")
private long maxWaitMillis;
@Value("${spring.redis.commandTimeout}")
private int commandTimeout;
@Bean
public JedisCluster getJedisCluster() {
String[] cNodes = clusterNodes.split(",");
for(String fac :cNodes){
System.out.println(fac);
}
Set nodes =new HashSet();
//分割出集群节点
for(String node : cNodes) {
String[] hp = node.split(":");
nodes.add(new HostAndPort(hp[0],Integer.parseInt(hp[1])));
}
JedisPoolConfig jedisPoolConfig =new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(maxIdle);
jedisPoolConfig.setMaxWaitMillis(maxWaitMillis);
//创建集群对象
return new JedisCluster(nodes,commandTimeout,jedisPoolConfig);
}
}
7、接口方法定义
public interface RedisClusterService {
public Object get(String key);
public String set(String key, String value);
}8、接口方法实现类,实现的过程调用了集群中的方法
@Service
public class RedisClusterServiceImpl implements RedisClusterService {
//注入JedisCluster
@Autowired
JedisCluster jedisCluster;
@Override
public Object get(String key) {
return jedisCluster.get(key);
}
@Override
public String set(String key, String value) {
String set = jedisCluster.set(key, value);
return set;
}
}9、controller类
@Controller
@RequestMapping("redisCluster")
public class RedisClusterController {
// 注入的是接口类
@Autowired
RedisClusterService redisClusterService;
/**
* 根据键获取redis中对应的值
*/
@ResponseBody
@RequestMapping("/get")
public Object getValue(String key){
Object value = redisClusterService.get(key);
return value;
}
/**
* 向redis集群中存入值
*/
@ResponseBody
@RequestMapping("/set")
public String setInfo(String key,String value){
try {
String set = redisClusterService.set(key,value);
return "已存入缓存。。。"+set;
} catch (Exception e) {
e.printStackTrace();
return "缓存存入失败。。。";
}
}
}10、使用postman进行测试
(1)添加数据

(2)获取数据

(3)集群说明
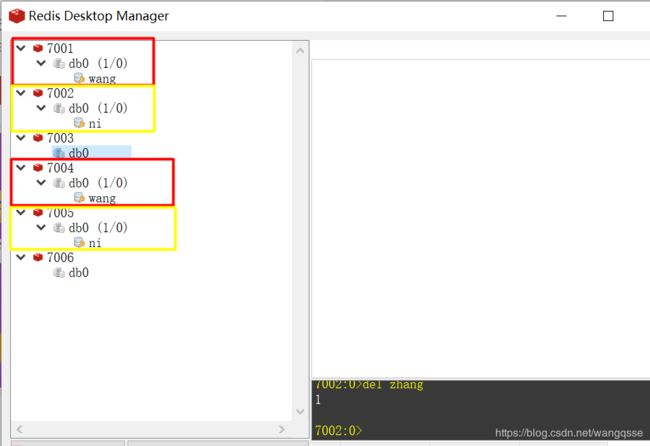
通过使用RedisDeskTopManager连接redis集群可以发现,6个redis实例中,每当set新的数据时候,总会有两个实例中有相同的数据。这是因为,在创建集群的时候,使用了如下命令:
./redis-trib.rb create --replicas 1 192.168.213.129:7001 192.168.213.129:7002 192.168.213.129:7003 192.168.213.129:7004 192.168.213.129:7005 192.168.213.129:7006
参数 -replicas 1中,1代表的是一个比例,就是主节点数与从节点数的比例。那么想一想,在创建集群的时候,哪些节点是主节点呢?哪些节点是从节点呢?答案是将按照命令中IP:PORT的顺序,先是3个主节点,然后是3个从节点。
其次,注意slot的概念。slot对于Redis集群而言,就是一个存放数据的地方,就是一个槽。对于每一个Master而言,会存在一个slot的范围,而Slave则没有。在Redis集群中,依然是Master可以读、写,而Slave只读。
数据的写入,实际上是分布的存储在slot中,这和以前1.X的主从模式是不一样的(主从模式下Master/Slave数据存储是完全一致的),因为Redis集群中3台Master的数据存储并不一样。