LSTM神经网络
LSTM是什么
LSTM即Long Short Memory Network,长短时记忆网络。它其实是属于RNN的一种变种,可以说它是为了克服RNN无法很好处理远距离依赖而提出的。
我们说RNN不能处理距离较远的序列是因为训练时很有可能会出现梯度消失,即通过下面的公式训练时很可能会发生指数缩小,让RNN失去了对较远时刻的感知能力。
∂E∂W=∑t∂Et∂W=∑tk=0∂Et∂nett∂nett∂st(∏tj=k+1∂st∂sk)∂sk∂W
解决思路
RNN梯度消失不应该是由我们学习怎么去避免,而应该通过改良让循环神经网络自己具备避免梯度消失的特性,从而让循环神经网络自身具备处理长期序列依赖的能力。
RNN的状态计算公式为 St=f(St−1,xt) ,根据链式求导法则会导致梯度变为连乘的形式,而sigmoid小于1会让连乘小得很快。为了解决这个问题,科学家采用了累加的形式, St=∑tτ=1ΔSτ ,其导数也为累加,从而避免梯度消失。LSTM即是使用了累加形式,但它的实现较复杂,下面进行介绍。
LSTM模型
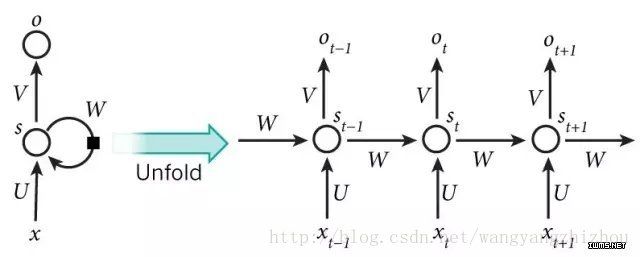
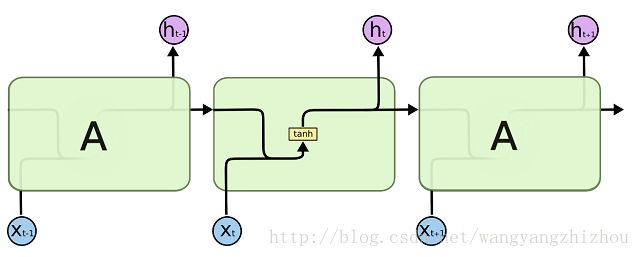
回顾一下RNN的模型,如下图,展开后多个时刻隐层互相连接,而所有循环神经网络都有一个重复的网络模块,RNN的重复网络模块很简单,如下下图,比如只有一个tanh层。
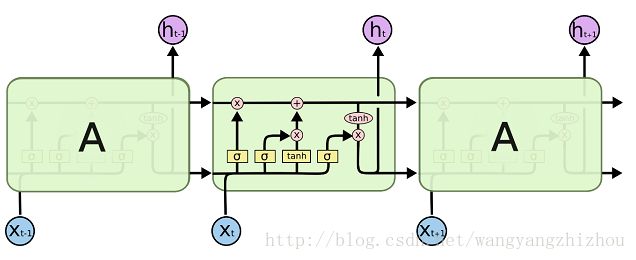
而LSTM的重复网络模块的结构则复杂很多,它实现了三个门计算,即遗忘门、输入门和输出门。每个门负责是事情不一样,遗忘门负责决定保留多少上一时刻的单元状态到当前时刻的单元状态;输入门负责决定保留多少当前时刻的输入到当前时刻的单元状态;输出门负责决定当前时刻的单元状态有多少输出。
每个LSTM包含了三个输入,即上时刻的单元状态、上时刻LSTM的输出和当前时刻输入。
LSTM的机制
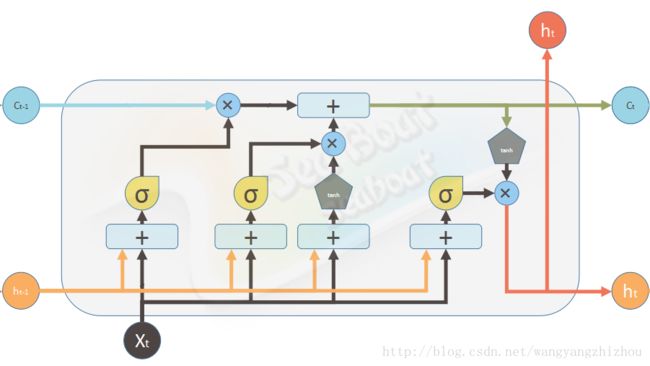
根据上图咱们一步一步来看LSTM神经网络是怎么运作的。
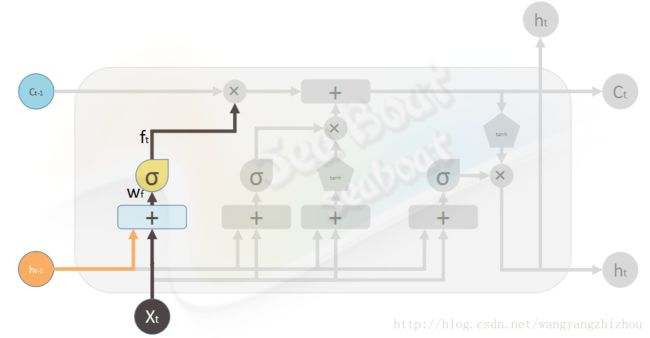
首先看遗忘门,用来计算哪些信息需要忘记,通过sigmoid处理后为0到1的值,1表示全部保留,0表示全部忘记,于是有
ft=σ(Wf⋅[ht−1,xt]+bf)
其中中括号表示两个向量相连合并, Wf 是遗忘门的权重矩阵, σ 为sigmoid函数, bf 为遗忘门的偏置项。设输入层维度为 dx ,隐藏层维度为 dh ,上面的状态维度为 dc ,则 Wf 的维度为 dc×(dh+dx) 。
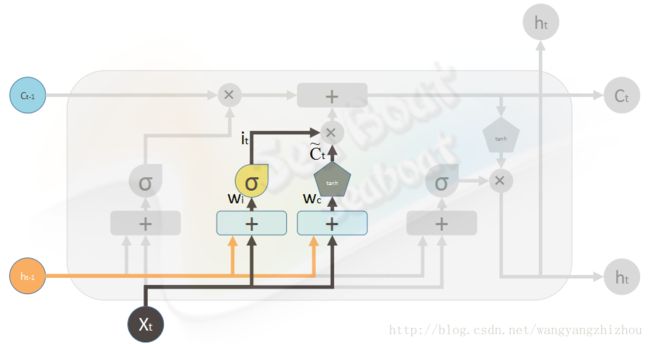
其次看输入门,输入门用来计算哪些信息保存到状态单元中,分两部分,第一部分为
it=σ(Wi⋅[ht−1,xt]+bi)
该部分可以看成当前输入有多少是需要保存到单元状态的。第二部分为
c~t=tanh(Wc⋅[ht−1,xt]+bc)
该部分可以看成当前输入产生的新信息来添加到单元状态中。结合这两部分来创建一个新记忆。
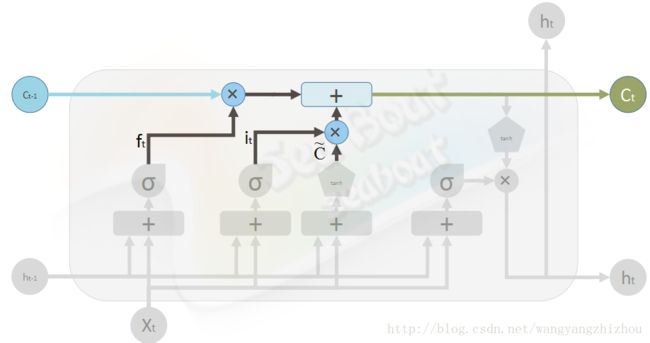
而当前时刻的单元状态由遗忘门输入和上一时刻状态的积加上输入门两部分的积,即
ct=ft∗ct−1+it∗c~t
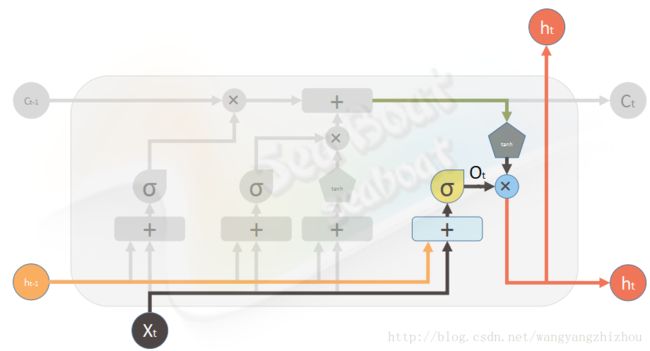
最后看看输出门,通过sigmoid函数计算需要输出哪些信息,再乘以当前单元状态通过tanh函数的值,得到输出。
ot=σ(Wo⋅[ht−1,xt]+bo)
ht=ot∗tanh(ct)
LSTM的训练
化繁为简,这里只讨论包含一个LSTM层的三层神经网络(如果有多个层则误差项除了沿时间反向传播外,还会向上一层传播),LSTM向前传播时与三个门相关的公式如下,
ft=σ(Wf⋅[ht−1,xt]+bf)
it=σ(Wi⋅[ht−1,xt]+bi)
c~t=tanh(Wc⋅[ht−1,xt]+bc)
ct=ft∗ct−1+it∗c~t
ot=σ(Wo⋅[ht−1,xt]+bo)
ht=ot∗tanh(ct)
需要学习的参数挺多的,同时也可以看到LSTM的输出 ht 有四个输入分量加权影响,即三个门相关的 ftitc~tot ,而且其中权重W都是拼接的,所以在学习时需要分割出来,即
Wf=Wfx+Wfh
Wi=Wix+Wih
Wc~=Wc~x+Wc~h
Wo=Wox+Woh
输出层的输入 yit=Wyiht ,输出为 yot=σ(yit) 。
设某时刻的损失函数为 Et=12(yd−yot)2 ,则某样本的损失为
E=∑Tt=1Et
设当前时刻t的误差项 δt=∂E∂ht ,那么误差沿着时间反向传递则需要计算t-1时刻的误差项 δt−1 ,则
δt−1=∂E∂ht−1=∂E∂ht∂ht∂ht−1=δt∂ht∂ht−1
LSTM的输出 ht 可看成是一个复合函数, f[ft(ht−1),it(ht−1),c~t(ht−1),ot(ht−1)] ,由全导数公式有,
其中 netf,tneti,tnetc~,tneto,t 表示对应函数的输入。将上述所有偏导都求出来,
\frac{\partial{{h_t}}}{\partial{{c}_t}}={o}_t \ast (1-\tanh({c}_t)^2) \frac{\partial{{c}_t}}{\partial{{f_{t}}}}={c}_{t-1} \frac{\partial{{f}_t}}{\partial{{net}_{f,t}}}={f}_t \ast (1-{f}_t) \frac{\partial{{net}_{f,t}}}{\partial{{h}_{t-1}}}=W_{fh}
同样地,其他也可以求出来,最后得到t时刻和t-1时刻之间的关系。再设
\delta_{f,t}=\frac{\partial{E}}{\partial{{net}_{f,t}}} \delta_{i,t}=\frac{\partial{E}}{\partial{{net}_{i,t}}} \delta_{\tilde{c},t}=\frac{\partial{E}}{\partial{{net}_{\tilde{c},t}}} \delta_{o,t}=\frac{\partial{E}}{\partial{{net}_{o,t}}}
得到,
接着对某时刻t的所有权重进行求偏导,
对于整个样本,它的误差是所有时刻的误差之和,而与上个时刻相关的权重的梯度等于所有时刻的梯度之和,其他权重则不必累加,最终得到
相关阅读:
循环神经网络
卷积神经网络
机器学习之神经网络
机器学习之感知器
神经网络的交叉熵损失函数
========广告时间========
公众号的菜单已分为“分布式”、“机器学习”、“深度学习”、“NLP”、“Java深度”、“Java并发核心”、“JDK源码”、“Tomcat内核”等,可能有一款适合你的胃口。
鄙人的新书《Tomcat内核设计剖析》已经在京东销售了,有需要的朋友可以购买。感谢各位朋友。
为什么写《Tomcat内核设计剖析》
=========================
欢迎关注:
