CV论文研读笔记
文章目录
- 基础
- 论文研读
- Region Proposal by Guided Anchoring
- Feature Selective Anchor-Free Module for Single-Shot Object Detection
- Image Segmetation With Deep Learning
- 3D-SIS: 3D Semantic Instance Segmentation of RGB-D Scans
- Structured Knowledge Distillation for Semantic Segmentation
基础
- ReLU作为CNN的激活函数,其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。
- 训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。
- 在CNN中使用最大池化。平均池化具有模糊化效果。
- 在CNN中让池化重叠。让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
- 增加LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。(后被认为基本没用)
- 对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。在很多网络中,都使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5x5卷积核。
- CNN由于固定的几何结构,导致其对几何形变的建模受到限制。为了加强CNN对形变的建模能力,文献”deformable convolution network的”提出了deformable convolution和 deformable RoI pooling两种网络结构单元。deformable convolution 和 deformable RoI pooling都是基于通过学习一个额外的偏移(offset),使卷积核对输入feature map的采样的产生偏移,集中于感兴趣的目标区域。可以将deformable convolution , deformable RoI pooling加入现有的CNN中,并可进行端到端训练。
- ROIs Pooling顾名思义,是Pooling层的一种,而且是针对RoIs的Pooling,他的特点是输入特征图尺寸不固定,但是输出特征图尺寸固定。因为可能输入的feature map需要先投影出region proposal(物体检测中),而region proposal的大小是不固定的,但是我们又需要对其进行分类和回归,所以就需要使用ROIs Pooling,先将region proposal划分为尽可能等大的几个section(section数目与输出特征图尺寸维度相关),然后对每个section进行max pooling,获得输出大小固定的特征图。
- ROIs Pooling操作中两次量化(边框长宽除以步长可能为小数;将量化后的边界区域平均分割成 n x m 个单元(section),对每一个单元的边界进行量化。)造成的区域不匹配(mis-alignment)的问题。实验显示,在检测测任务中将 ROI Pooling 替换为 ROI Align可以提升检测模型的准确性。ROI Align的思路很简单:遍历每一个候选区域,保持浮点数边界不做量化;将候选区域分割成k x k个单元,每个单元的边界也不做量化;’在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
- BN层为了使得数据的拟合、分类更简单,加快收敛速度,我们需要对数据进行归一化(0均值,所有数据减去均值;单位方差,去相关性)
- 激活函数是神经网络中非线性的来源,因为如果去掉这些函数,那么整个网络就只剩下线性运算,线性运算的复合还是线性运算的,最终的效果只相当于单层的线性模型.
- RPN:在一个小区域上可以生成k个anchor boxes(所有anchor boxes的中心点坐标是一样的,就是对应这个小区域的中心点)。RPN就是在这些anchor boxes上找到可能存在目标的boxes,并进一步回归坐标,得到proposals输给后面的网络。
论文研读
Region Proposal by Guided Anchoring
物体检测器自己学Anchor,以往使用滑窗对图像进行按步长的探测,以框内是否有问物体为判断结果。但是因为物体的形状是无法确定的,对于长宽比悬殊的我物体来说,这样固定大小的窗口并不能有效的检测到物体的位置。
这篇论文的关键就在于怎么生成一个自适应物体形状的Anchor。
Anchor 的概率分布被分解为两个条件概率分布,也就是给定图像特征之后 anchor 中心点的概率分布,和给定图像特征和中心点之后的形状概率分布:
![]()
Anchor的生成使用上述公式。其中x, y, w, h为坐标和长宽。因此,需要做的就是位置预测和形状预测。
位置预测主要是预测物体的中心区域。我们将整个 feature map 的区域分为物体中心区域,外围区域和忽略区域,大概思路就是将 ground truth 框的中心一小块对应在 feature map 上的区域标为物体中心区域,在训练的时候作为正样本,其余区域按照离中心的距离标为忽略或者负样本。
形状预测使用IoU 作为监督,因为IoU可回归,设置训练目标是使IoU最大,得到Anchor的w和h。
Feature Selective Anchor-Free Module for Single-Shot Object Detection
主要是为了解决物体检测的尺度问题,小物体的检测误差常常较大。普遍的方法是FPN(Feature Pyramid Network),它利用多级的feature map去预测不同尺度大小的物体,其中高层特征带有高级语义信息和较大的感受野,适合检测大物体,浅层特征带有低级的细节语义信息和较小的感受野,适合检测小物体。FPN逐步融合深层特和浅层特征,使得逐步增加浅层的特征的高级语义信息来提高特征表达能力,提升检测效果。
物题检测的feature map是多层的,高层的feature map分辨率高,得到的anchor数量多尺寸小,浅层的feature map分辨率低,得到的anchor数量少尺寸大。原先根据anchor size的大小将GT分配。但是现在优化为FSAF模块,不再根据instance size选择feature层而是根据instance content。
Image Segmetation With Deep Learning
语义分割是将输入图片在像素级别上分区域或者稂据物体通过边缘分割图片。
条件随机场旨在模式化像素间的关系 , 一般来讲, 自然图像中像素之间具备以下特点 :1. 相邻的 像素更有可能相同的标签。2. 具有类似颜色 的像素更有可能属于同一标签。3. 根据图像的特性,有些标签的像素点更有可能和其他类别的像萦在一起,通俗地讲,在 “椅子”标签上的像素更有可能属于“人类”, 而不太可能是 “飞机” 标签。 4. 分割的结果一般会经过不断迭代进行细化。
全卷积网络的提出 , 语义分割任务则转变成一个端到端的网络 。 目前主流的语义分割任务则是输入一张任意尺寸的输入 , 输出一张分割好的图片 , 按照每个像素的标签对每个像素进行标色 。
全卷积神经网络( Fully Convolutional Network ,FCN) , 成为近几年语义分割网络的基准网络。 在FCN之前由于全连接层和GPU显卡显存的局限 ,语义分割一直无法实现end-to-end的训练模式 , FCN通过全卷积实现这一功能并在 Pascalvoc 数据集上远远超过其他方法 。 但由于直接拿来分类或者检测网络框架会导致分割框架丢失很多局部信 息 ,导致边缘十分模糊。 Liang Chen M 等人提出了在网络后加入全连接的条件随机场( Conditional Random Field ,CRF)来细化边缘 , 全连接的 CRF 在一定程度上解决了 FCN 边缘不细化的问题。 Shuai等人更巧妙的将 CRF 用卷积神经网络来实现成为一个递归神经网络( Recurrent Neural Network, RNN ) 并作为一个可训练的模块 , 该网络称作 CRFasRNN 。 类似马尔科夫场等其他概率图模型也被应用于语义分割中 , 同 时 也取得了不错的效果。
FCN将CNN的全连接层改换为多层卷积。因为卷积是逐层筛选特征的,所以这就导致最后的结果特征图十分粗糙。
针对全卷积网络输出 特征图被降采样到很小尺寸的间题 ,FCN使用上采样的方法使粗糙特征图可以 输出一张和原图大小一样并得到每个像素所属的类别, 这样的输出称为 Dense prediction。 FCN 中使用的上采样方式是二线性插值 , 该方法通过输入四个特征图的值来计算 ( i ,j ) 位置的输出y ij , 具体公式如下 :
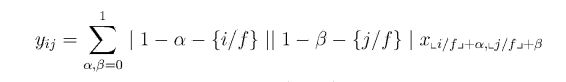
SegNet结构是语义分割的一个变体,该网络最大的特性就是可以实时分割街 图片 , 旨在应用于自 动驾驶和智能机器人。
FCN 中使用线性插值作为上采样恢复特征图 尺寸从而输出和原图一样的分割好的图片,Hyeonwoo Noh 等人提出了DeconvNet 使用学习的反卷积核 ( Deconvolution ) 对特征图行上采样实现高精度的语义分割。
语义分割网络也越来越多地使用了多层信息融合的技术, 比如 Refinenet 就使用残差单元对多层特征进行融合 。
为了解决分割问题中数据量缺失的问题 , 很多研究者在分割问题中引入了迁移学习(transferlearning) 和 弱监督 ( weaklysupervised ) 学习的方法 。 迁移学习主要是解决像素级别样本量不足, 而弱监督学习则是在没有像素级别标注但是具有图像类别标签数据集的一种解决方式。
医学图像的自动分割一般是对各种疾病以及各种年龄患者的预评估步骤, 现在已经在非增强 T1 加权 的图像中取得了不错的分割结果。由于病变区域和部分组织相对于整张图片过小 , 所以为了更精准的分割 , Moeskops 等人提出了一种多尺度融合的 CNN 来增加分割细节和空间一致性的鲁棒性 。部分医学图像 , 由于成像或者患者特性 , 具有组织分辨率低、 噪声多等挑战 。 所以为了克服这些挑战 , Zhang 等人M 设计了一种结合多模态医学图像的 CNN , 该网络使用了不同信号加权的图像作为输入 , 从尽可能多的模态中提取出更多的信息。
3D-SIS: 3D Semantic Instance Segmentation of RGB-D Scans
3d RPN 有两个分支,一个分支是卷积核为1*1*1的卷积层,表示分类,将通道数变成2*Nanchors, Nanchors=(3,11)。2表示前景和背景的分类得分。另一个分支也是卷积核为1*1*1的卷积层,表示位置回归,将通道数变成6*Nanchors,6表示3d bounding box的位置参数(Δx,Δy,Δz,Δw,Δh,Δl),定义如下。类似fast r-cnn的回归表示。
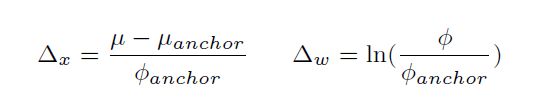
分类的loss选用二分类交叉熵loss。回归分支选用Huber loss,定义如下:
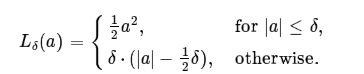
训练时当anchor与ground truth的IoU大于等于0.35时,当作正样本,参与分类与回归loss的计算,当IoU小于0.15,当作负样本,只参与分类loss计算。
3d实例分割 与前面介绍的3d bounding box检测没有共享网络和权重,而是另起一个网络,使用相同的输入。在实例分割的网络中,使用全卷积,每个卷积的操作,输出都保留原输入的大小不变,这样可以提高分割的准确性。在输出的特征体中,利用检测网络生成的3d bounding box截取出实例分割的结果,在输出的特征体中,每个体素都有c个通道,c是类别的总数。由于检测网络生成的3d bbox不一定准,所以在训练过程中,3d bbox与ground truth的IoU大于0.5才会参与训练。
Structured Knowledge Distillation for Semantic Segmentation
通过知识蒸馏的思想利用复杂网络(Teacher)来训练简单网络(Student),目的是为了让简单的网络能够达到和复杂网络相同的分割结果。为了得到两个网络相同的结果就要保证两个网络在训练过程中的一致性。因此通过设计训练过程中的损失函数来是两者达到一致效果。
首先当输入的图像分别经过两个网络之后会生成两个维度相同的特征表示。通过两个像素之间的相似性关系来提升网络的效果。
为了匹配Teacher 网络与Student网络产生的分割图的高阶关系,引入了条件生成对抗学习的思想。