kafka相关操作及问题汇总
1. kafka查看队列的消费情况
可以通过kafka-mamager来跟进。
2 kafka常用命令
#启动kafka
cd /usr/hadoop/application/kafka/bin
./kafka-server-start.sh -daemon ../config/server.properties
#创建Topic
./kafka-topics.sh --create --zookeeper 192.168.5.172:2181,192.168.5.173:2181,192.168.5.174:2181 --replication-factor 1 --partitions 1 --topic test
#查看topic
./kafka-topics.sh --list --zookeeper 192.168.5.172:2181,192.168.5.173:2181,192.168.5.174:2181
#创建一个broker,发布者
./kafka-console-producer.sh --broker-list 192.168.5.185:19092 --topic test1
#在一台服务器上创建一个订阅者
./kafka-console-consumer.sh --zookeeper 192.168.5.172:2181,192.168.5.173:2181,192.168.5.174:2181 --topic test1 --from-beginning
#topic清单
list topic
./kafka-topics.sh --zookeeper 192.168.5.172:2181,192.168.5.173:2181,192.168.5.174:2181 --list
# 删除topic
./kafka-topics.sh -delete -zookeeper 192.168.5.172:2181,192.168.5.173:2181,192.168.5.174:2181 -topic test
3 kafka-mamager相关命令
参考kafka管理器kafka-manager部署安装
rm -fr /usr/hadoop/application/kafka-manager-1.3.3.8/RUNNING_PID
cd /usr/hadoop/application/kafka-manager/bin
# 如果端口改了,可以在下面的命令中添加-Dhttp.port=7778,默认端口为9000
nohup ./kafka-manager -Dconfig.file=/usr/hadoop/application/kafka-manager/conf/application.conf &
tail -fn 100 nohup.out
4 python生产kafka数据的实例
# kafka
SCRAPY_KAFKA_HOSTS = '192.168.5.150:19092'
SCRAPY_KAFKA_SPIDER_CONSUMER_GROUP = 'myGroup'
SCRAPY_KAFKA_TOPIC = 'customer'
SCRAPY_KAFKA_TOPIC_DISK = 'customerDisk'
from scrapy.utils.serialize import ScrapyJSONEncoder
from pykafka import KafkaClient
class ItemKfkProducers(object):
def __init__(self):
self.khost = settings.SCRAPY_KAFKA_HOSTS
self.topic = settings.SCRAPY_KAFKA_TOPIC
self.disk = settings.SCRAPY_KAFKA_TOPIC_DISK
self.encoder = ScrapyJSONEncoder()
def producers(self,item):
# item = dict(item)
client = KafkaClient(hosts=self.khost)
topic = client.topics[self.topic]
with topic.get_producer(delivery_reports=True) as producer:
msg = self.encoder.encode(item)
# producer.produce("send item")
producer.produce(msg)
4 pykafka产生消息速度极慢
我遇到和pykafka 写消息时速度极慢,只有 10 mgs / s 正常么?,仔细看代码,发现原来开发工程师的代码是按照这个copy[PyKafka producer.get_delivery_report throwing Queue.empty when block=false
](https://stackoverflow.com/questions/35298796/pykafka-producer-get-delivery-report-throwing-queue-empty-when-block-false),
def producersDisk(self,item):
# item = dict(item)
client = KafkaClient(hosts=self.khost)
topic = client.topics[self.disk]
with topic.get_producer(delivery_reports=True) as producer:
msg = self.encoder.encode(item)
producer.produce(msg)
在【kafka】生产者速度测试找到了答案。需要使用rdkafka,只是windows下面没法安装rdkafka.按照afka python client:PyKafka vs kafka-python中的数据,真没觉得他有多快,我8万条数据执行了好久,也没看到变化。
按照[PyKafka producer.get_delivery_report throwing Queue.empty when block=false
](https://stackoverflow.com/questions/35298796/pykafka-producer-get-delivery-report-throwing-queue-empty-when-block-false),使用get_producer(min_queued_messages=1) 时间由原来的10s产生一条消息,降到了5s中产生一条消息。
5 异步处理
一边要把数据写入到mysql中,一边要把数据利用pykafka写入到kafka中,而写kafka中暂时没有找到方法降低到5s以下,那么是否可以考虑这两个io相关的操作,做成异步呢。
深入理解 Python 异步编程(上)
Python异步并发框架
协程–gevent模块(单线程高并发)
这几篇文章都讲的不错,
6 windows命令窗口执行的问题
在一线工作有时候会遇到莫名其妙秒的问题,不过很有意思。只是10年前我不知道天天写csdn,要不然估计也会就是现在的水平。我通过cmd窗口跑我的python脚本,用鼠标点了一下cmd窗口自身,10分钟都没有打日志,好像夯住了。觉得很奇怪使用Ctrl+C,居然又开始跑了。虽然Ctrl+C是杀进程的命令,但是你不能执行多次,多次就真的删掉了。请教了一下SE,SE说以前使用oracle的命令窗口跑批处理的时候也遇到这个问题,鼠标不能点,点就有这样的bug,按一下Enter键就可以了。有意思。
7 时区问题
从数据库中得到时间稍作处理,比如end_active_date = time.strftime("%Y-%m-%d", time.localtime(kpjxx['endActiveDate']/1000)),我再将这个时间写入到kafka中时间会往后增加8个小时

下面要注意的是时间往数据库和往kafka中写,是有区别的。看代码不详细解释了。
def insert(self,kpjxx):
crmCustomer = self.crmCustomerService.get_by_tax_no(kpjxx['xxxx'])
exist = self.is_exist(kpjxx['Jxx_NO'][0:11])
if crmCustomer and not exist:
active_date = datetime.fromtimestamp(kpjxx['FXSJ']/1000)
end_active_date = active_date.replace(year=2018)
# create_time = time.strftime("%Y-%m-%d %H:%M", time.localtime(kpjxx['FXSJ']/1000))
item = {'id':kpjxx['JSK_NO'][0:11],'product_id':'2.05', 'device_status':'03', 'customer_id':crmCustomer['id'],'active_date':active_date.strftime('%Y-%m-%d')
,'device_no':kpjxx['JSK_NO'],'is_makeup':'1', 'service_charge':'280', 'end_active_date':end_active_date.strftime('%Y-%m-%d')
,'create_time':active_date.strftime('%Y-%m-%d %H:%M:%S')}
depot_id = self.crmXXXService.get_depot_id(crmCustomer['tax_auth_id'])
item['depot_id'] = depot_id
df = pd.DataFrame([item])
try:
df.to_sql('pss_product_item', self.engine, if_exists='append', index=False)
m_time_str = end_active_date.strftime('%Y-%m-%d %H:%M:%S')
m_seconds = time.strptime(m_time_str,'%Y-%m-%d %H:%M:%S' )
m_seconds = long(time.mktime(m_seconds)*1000)
customerDisk = {'customerId':crmCustomer['id'], 'customerName':crmCustomer['cust_name'], 'diskNo':item['device_no']
, 'taxNo':crmCustomer['tax_no'], 'effectiveDate':kpjxx['FXSJ'], 'expirationDate':m_seconds
, 'serviceCharge':item['service_charge'], 'category':'00', 'diskType':'01'}
self.itemKfkProducers.producersDisk(customerDisk)
except Exception, e:
print e
8 kafka无法消费数据
很久没有动kafka,突然一个紧急上线版本,居然kafka无法消费消息,重启kafka没法解决
20:14:16.063 ERROR c.g.l.flume.EventReporter$ReportingJob - Could not submit events to Flume
20:14:40.649 WARN org.apache.kafka.clients.NetworkClient - Error while fetching metadata with correlation id 131 : {customer=INVALID_REPLICATION_FACTOR}
20:14:40.804 WARN org.apache.kafka.clients.NetworkClient - Error while fetching metadata with correlation id 132 : {customer=LEADER_NOT_AVAILABLE}
[2018-04-19 20:11:03,683] WARN Connection to node -1 could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)
[2018-04-19 20:11:03,784] WARN Connection to node -1 could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)
[2018-04-19 20:11:03,884] WARN Connection to node -1 could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)
[2018-04-19 20:11:03,985] WARN Connection to node -1 could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)
[2018-04-19 20:11:04,035] WARN Connection to node -1 could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)
看了zookeeper删除kafka元数据,解决kafka无法消费数据的问题这篇文章
执行下面的命令
zkCli.sh -server 192.168.4.61:2181
ls /brokers/topics
rmr /brokers/topics/customerDisk # 这个customerDisk是自己kafka中的文档,根据每个系统设置的,重启后这些文件将会再生成
接着先重启zookeeper,再重启kafka问题解决。
9 创建topic
./kafka-topics.sh --create --zookeeper 10.101.3.177:2181,10.101.3.178:2181,10.101.3.179:2181 --replication-factor 1 --partitions 1 --topic testTopic
10 java.lang.IllegalArgumentException: requirement failed: No jmx port but jmx polling enabled!
详细异常信息如下:
[error] k.m.a.c.BrokerViewCacheActor - Failed to get broker topic segment metrics for BrokerIdentity(0,192.168.5.185,19092,-1,false)
java.lang.IllegalArgumentException: requirement failed: No jmx port but jmx polling enabled!
at scala.Predef$.require(Predef.scala:224) ~[org.scala-lang.scala-library-2.11.8.jar:na]
at kafka.manager.jmx.KafkaJMX$.doWithConnection(KafkaJMX.scala:39) ~[kafka-manager.kafka-manager-1.3.3.8-sans-externalized.jar:na]
at kafka.manager.actor.cluster.BrokerViewCacheActor$$anonfun$kafka$manager$actor$cluster$BrokerViewCacheActor$$updateBrokerTopicPartitionsSize$1$$anonfun$apply$29$$anonfun$apply$4.apply$mcV$sp(BrokerViewCacheActor.scala:382) ~[kafka-manager.kafka-manager-1.3.3.8-sans-externalized.jar:na]
at kafka.manager.actor.cluster.BrokerViewCacheActor$$anonfun$kafka$manager$actor$cluster$BrokerViewCacheActor$$updateBrokerTopicPartitionsSize$1$$anonfun$apply$29$$anonfun$apply$4.apply(BrokerViewCacheActor.scala:379) ~[kafka-manager.kafka-manager-1.3.3.8-sans-externalized.jar:na]
at kafka.manager.actor.cluster.BrokerViewCacheActor$$anonfun$kafka$manager$actor$cluster$BrokerViewCacheActor$$updateBrokerTopicPartitionsSize$1$$anonfun$apply$29$$anonfun$apply$4.apply(BrokerViewCacheActor.scala:379) ~[kafka-manager.kafka-manager-1.3.3.8-sans-externalized.jar:na]
at scala.concurrent.impl.Future$PromiseCompletingRunnable.liftedTree1$1(Future.scala:24) ~[org.scala-lang.scala-library-2.11.8.jar:na]
at scala.concurrent.impl.Future$PromiseCompletingRunnable.run(Future.scala:24) ~[org.scala-lang.scala-library-2.11.8.jar:na]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[na:1.8.0_141]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[na:1.8.0_141]
at java.lang.Thread.run(Thread.java:748) ~[na:1.8.0_141]
解决方案,参考kafka_0.10.1.0监控及管理
以及如何使用JMX监控Kafka
JMX_PORT=9999 ./kafka-server-start.sh -daemon ../config/server.properties
或者在kafka-server-start.sh中添加export JMX_PORT=9999到下面的位置
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
export JMX_PORT="9999"
fi
11 java.io.FileNotFoundException: application.home_IS_UNDEFINED/logs/application.log
10:13:34,777 |-INFO in ch.qos.logback.core.rolling.RollingFileAppender[FILE] - Active log file name: application.home_IS_UNDEFINED/logs/application.log
10:13:34,777 |-INFO in ch.qos.logback.core.rolling.RollingFileAppender[FILE] - File property is set to [application.home_IS_UNDEFINED/logs/application.log]
10:13:34,778 |-ERROR in ch.qos.logback.core.rolling.RollingFileAppender[FILE] - Failed to create parent directories for [/usr/hadoop/application/kafka-manager-1.3.3.8/application.home_IS_UNDEFINED/logs/application.log]
10:13:34,778 |-ERROR in ch.qos.logback.core.rolling.RollingFileAppender[FILE] - openFile(application.home_IS_UNDEFINED/logs/application.log,true) call failed. java.io.FileNotFoundException: application.home_IS_UNDEFINED/logs/application.log (No such file or directory)
at java.io.FileNotFoundException: application.home_IS_UNDEFINED/logs/application.log (No such file or directory)
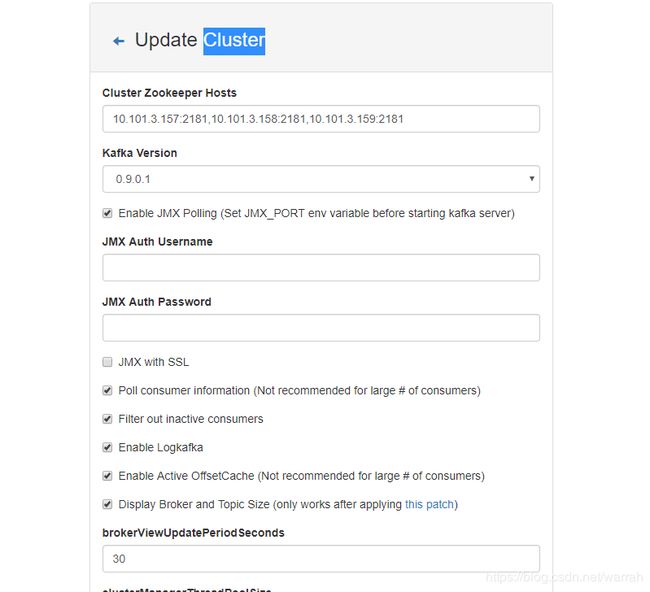
12 Cluster配置
配置上zookeeper集群的地址,以及按下图勾上需要的选项。
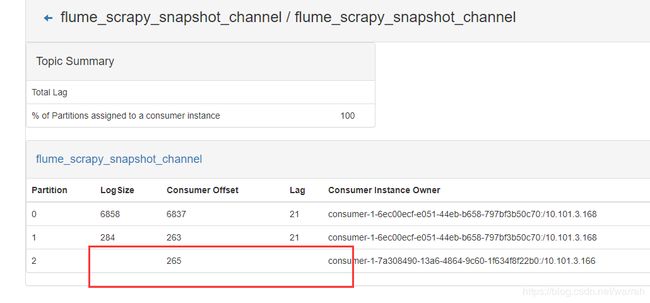
13 Attempt to heart beat failed since coordinator is either not started or not valid, marking it as dead.
三个kafka节点,只有1个节点是正常的,其余两个都不正常,提示下面的错误
22 Jul 2019 15:30:07,708 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.kafka.clients.consumer.internals.AbstractCoordinator$SyncGroupRequestHandler.handle:431) - SyncGroup for group flume_scrapy_snapshot_channel failed due to coordinator rebalance, rejoining the group
22 Jul 2019 15:30:22,820 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.kafka.clients.consumer.internals.AbstractCoordinator$SyncGroupRequestHandler.handle:440) - SyncGroup for group flume_scrapy_snapshot_channel failed due to NOT_COORDINATOR_FOR_GROUP, will find new coordinator and rejoin
22 Jul 2019 15:30:22,820 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.kafka.clients.consumer.internals.AbstractCoordinator.coordinatorDead:529) - Marking the coordinator 2147483646 dead.
查看总结kafka的consumer消费能力很低的情况下的处理方案这篇文章,先尝试增加partition的数量
执行命令很简单,看了为什么Kafka中的分区数只能增加不能减少?,带来的问题是多少个分区才合适呢?如何选择Kafka的分区数和消费者个数,可以先设置跟消费者一样,观察看看效果怎么样。
bin/kafka-topics.sh --alter --zookeeper 10.101.3.180:2181,10.101.3.181:2181,10.101.3.183:2181 --partitions 3 --topic flume_scrapy_snapshot_channel
从下图看到,现在3个节点都运行正常,kafka不需要重启。
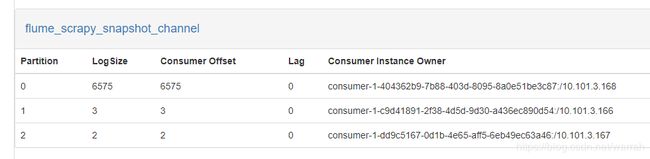
这里可以看到一个consumer对应了一个分区,那么logSize、consumer offset、Lag这些参数里面的数字都代表什么呢?参考Kafka的Lag计算误区及正确实现,我们了解到lag是消息堆积量,也就是没有消费掉得数量,ConsumerOffset:消费位移,表示Partition的某个消费者消费到的位移位置,logSize就是总数了。
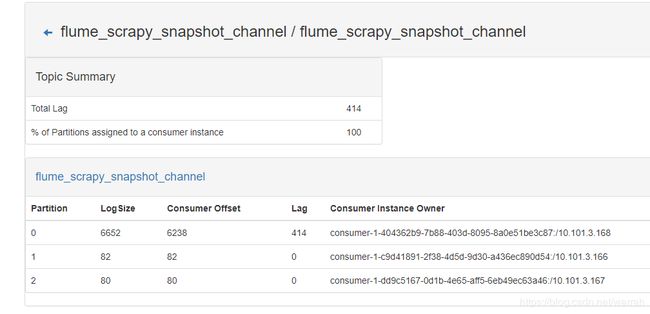
14 org.apache.kafka.clients.consumer.CommitFailedException: Commit cannot be completed due to group rebalance
今天有一节点,提示下面的异常,Kafka 消费过程中遇到的一些问题,这篇文章表述最有效的方法是增加消费水平,或者调整session.timeout.ms
kafka - 消费者其他重要配置描述了每个配置的作用,但这个配置在哪个文件里面呢?Kafka 2.1 Documentation,可以确定应该就是consumer.properties
继续观察,发现此问题依旧,查看kafka的maxPollIntervalMs设置太小引发的惨案
23 Jul 2019 09:10:45,496 ERROR [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler.handle:550) - Error UNKNOWN_MEMBER_ID occurred while committing offsets for group flume_scrapy_snapshot_channel
23 Jul 2019 09:10:45,497 ERROR [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.SinkRunner$PollingRunner.run:158) - Unable to deliver event. Exception follows.
org.apache.kafka.clients.consumer.CommitFailedException: Commit cannot be completed due to group rebalance
at org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler.handle(ConsumerCoordinator.java:552)
at org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler.handle(ConsumerCoordinator.java:493)
at org.apache.kafka.clients.consumer.internals.AbstractCoordinator$CoordinatorResponseHandler.onSuccess(AbstractCoordinator.java:665)
at org.apache.kafka.clients.consumer.internals.AbstractCoordinator$CoordinatorResponseHandler.onSuccess(AbstractCoordinator.java:644)
at org.apache.kafka.clients.consumer.internals.RequestFuture$1.onSuccess(RequestFuture.java:167)
at org.apache.kafka.clients.consumer.internals.RequestFuture.fireSuccess(RequestFuture.java:133)
at org.apache.kafka.clients.consumer.internals.RequestFuture.complete(RequestFuture.java:107)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient$RequestFutureCompletionHandler.onComplete(ConsumerNetworkClient.java:380)
at org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:274)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.clientPoll(ConsumerNetworkClient.java:320)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:213)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:193)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:163)
at org.apache.kafka.clients.consumer.internals.ConsumerCoordinator.commitOffsetsSync(ConsumerCoordinator.java:358)
at org.apache.kafka.clients.consumer.KafkaConsumer.commitSync(KafkaConsumer.java:968)
at org.apache.flume.channel.kafka.KafkaChannel$ConsumerAndRecords.commitOffsets(KafkaChannel.java:684)
at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:567)
at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:151)
at com.bwjf.flume.hbase.flume.sink.MultiAsyncHBaseSink.process(MultiAsyncHBaseSink.java:288)
at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:67)
at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:145)
at java.lang.Thread.run(Thread.java:748)
15 org.apache.kafka.common.errors.NotLeaderForPartitionException
数据没法被消费掉,查看kafka异常问题汇总,在producer.properties中添加,问题解决。不过只是暂时解决,参考第4.1.3章 flume写入数据到hbase中描述,应该将source节点与sink节点分开。source节点中不用配置sink节点,同理sink不用配置source节点,他们之间通过channel节点进行桥接。问题既然出现在资源消耗,那就分而治之。
retries=10
[2019-07-23 10:25:27,637] ERROR [ReplicaFetcherThread-0-2]: Error for partition [__consumer_offsets,46] to broker 2:org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition. (kafka.server.ReplicaFetcherThread)