mysql数据库集群实战——实现mysql数据库的读写分离(mysql-proxy)
文章目录
- 1.mysql数据库的读写分离的基础知识(为什么要进行读写分离)
- 2.读写分离的实现方式
- 3.搭建实验环境
- 4.在server1和server2先配置主从复制
- 5.接下来配置server3代理端(mysql-proxy)
- 6.接下来测试读写分离
1.mysql数据库的读写分离的基础知识(为什么要进行读写分离)
对于很多大型网站(pv值百万、千万)来说,在所处理的业务中,其中有80%的业务是查询(select)相关的业务操作 (新闻网站,插入一条新闻,查询操作) 剩下的则是写(insert、update、delete,只要能对MySQL的数据造成更改的操作都叫写操作)操作
在使用负载均衡集群之后,可以很大程度的提升网站的整体性能,但是最终的数据处理的压力还是会落到MySQL数据库上
所有很有必要使用一些技术来提升MySQL的负载能力。(读写分离) 写专门交给写服务器处理(一般网站来说写是比较少的 读写比 4:1)
那么需要把读的任务分配多台服务器来完成的架构,就叫做读写分离
2.读写分离的实现方式
(1)php程序上自己做逻辑判断,写php代码的时候,自己在程序上做逻辑判读写匹配。select,insert、update、delete做正则匹配,根据结果选择写服务器(主服务器)。如果是select操作则选择读服务器(从服务器器) mysql_connect(‘读写的区分’)
(2)MySQL- Proxy是实现"读写分离(Read/Write Splitting)"的一个软件(MySQL官方提供 ,也叫中间件),基本的原理是让主数据库处理写操作(insert、update、delete),而从数据库处理查询操作(select)。而数据库的一致性则通过主从复制来实现。所以说主从复制是读写分离的基础。
注意:MySQL-proxy 它能实现读写语句的区分主要依靠的是内部一个lua脚本(能实现读写语句的判断)
注意:如果只在主服务器(写服务器)上完成数据的写操作话;这个时候从服务器上没有执行写操作,是没有数据的
这个时候需要使用另外一个技术来实现主从服务器的数据一致性,这个技术叫做 主从复制技术, 所以说主从复制是读写分离的基础
读写分离(MySQL- Proxy)是指让master处理写操作,让slave处理读操作,非常适用于读操作量比较大的场景,可减轻master的压力
使用mysql-proxy实现mysql的读写分离,mysql-proxy实际上是作为后端mysql主从服务器的代理,它直接接受客户端的请求
对SQL语句进行分析,判断出是读操作还是写操作,然后分发至对应的mysql服务器上
因为数据库的写操作相对读操作是比较耗时的,所以数据库的读写分离,解决的是数据库的写入,影响了查询的效率
3.搭建实验环境
主机名 角色 服务
server1 master mysqld
server2 slave mysqld
server3 代理端 mysql-proxy
应用:把写和读分开 如果业务压力不是很大的时候要做读写分离,取决于硬盘读取的性能,客户才满意 读库(配置低),写库(配置高:固态硬盘,高速存储) 读写分离->mysql集群、分布式、代理、高可用 数据不一定来源于同一个地方 还会有测试库,模拟上线,测试服务器 proxy,相当于一个代理 实验一共需要量三台主机: server1做读、写库 server2做读库 server3做proxy代理 并且两个库(server1和server2)要实现读写分离,但是还要实现数据同步,基于gtid的异步复制(主从复制)
4.在server1和server2先配置主从复制
把环境还原到基于gtid的主从复制模式
(1)在server1上面设置:master节点(基于gtid的异步复制)
[root@server1 ~]# systemctl stop mysqld
[root@server1 ~]# netstat -ntlp
[root@server1 ~]# cd /var/lib/mysql
[root@server1 mysql]# rm -fr *
[root@server1 mysql]# ls
[root@server1 ~]# vim /etc/my.cnf
[root@server1 mysql]# systemctl start mysqld
root@server1 mysql]# vim /etc/my.cnf
加入:
server_id=1
log-bin=mysql-bin
gtid_mode=ON
enforce_gtid_consistency=true

[root@server1 mysql]# grep password /var/log/mysqld.log
[root@server1 mysql]# mysql -uroot -p Enter password:
mysql> alter user root@localhost identified by 'Haha+123';
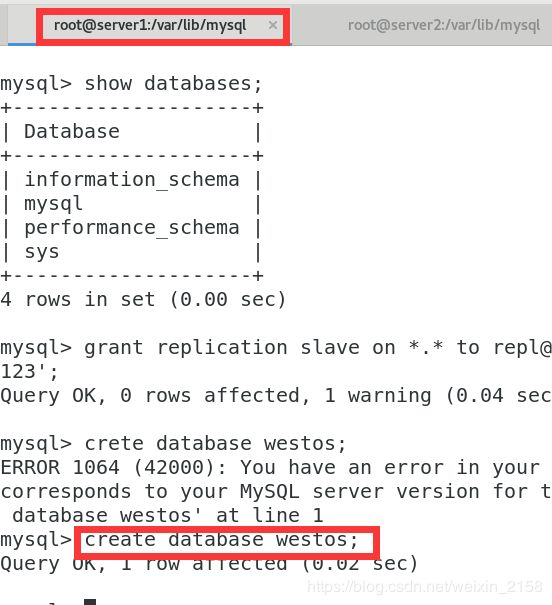
mysql> show databases; mysql> grant replication slave on *.* to repl @'192.168.0.%' identified by 'Haha+123kou';
mysql> show master status;


server2做同样操作:
(2)在server2上面设置:salve节点(基于gtid的异步复制)
[root@server2 ~]# systemctl stop mysqld
[root@server2 ~]# cd /var/lib/mysql
[root@server2 mysql]# ls
[root@server2 mysql]# rm -rf *
[root@server2 mysql]# ls
[root@server2 mysql]# vim /etc/my.cnf 加入: server_id=2 log-bin=mysql-bin gtid_mode=ON enforce_gtid_consistency=true
[root@server2 mysql]# systemctl start mysqld
[root@server2 mysql]# ls
[root@server2 mysql]# grep password /var/log/mysqld.log
[root@server2 mysql]# mysql -uroot -p Enter password:
mysql> alter user root@localhost identified by 'Haha+123';
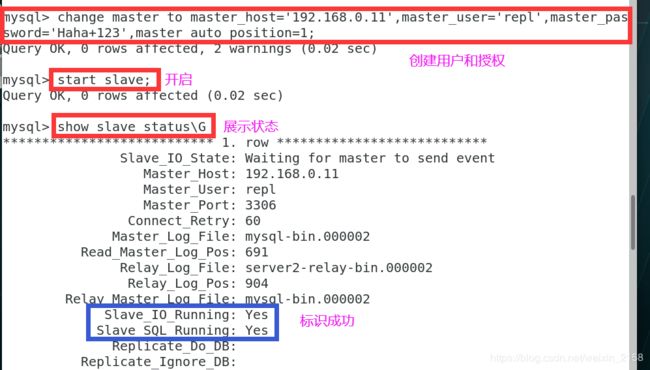
mysql> change master to master_host='192.168.0.1',master_user='repl',master_password='haha+123',master_auto_position=1;
mysql> start slave;
mysql> show slave status\G


测试:
因为80的访问都在20%的数据上
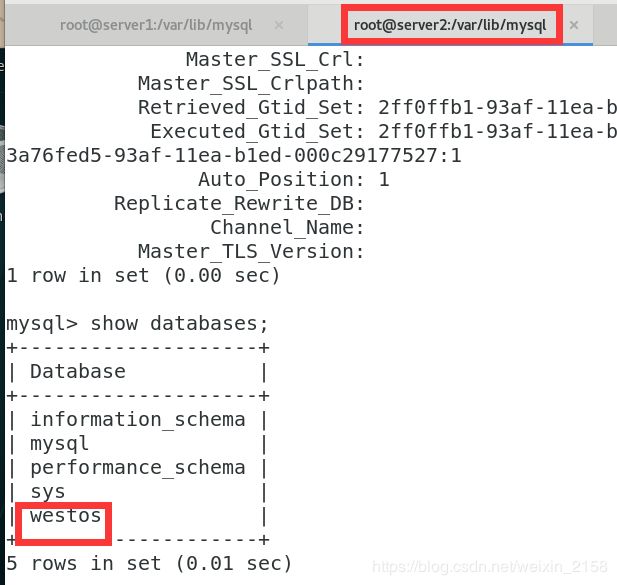
现在server1(master节点)和server2(slave节点)两个数据库已经准备好,基于gtid的主从复制
5.接下来配置server3代理端(mysql-proxy)
server3上面:搭建proxy代理服务器(实现客户端写在server1上面、客户端读server2上的数据)
(1)真机给代理server3传送代理安装包
在server3上:
不用编译可直接使用(注foundation应是server3)



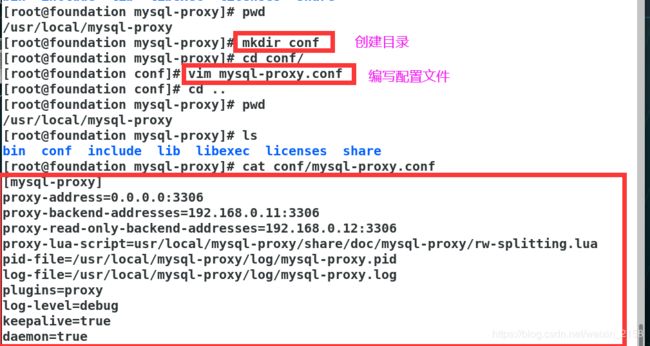
1 [mysql-proxy]
2 proxy-address=0.0.0.0:3306 ##mysql-proxy运行的端口
3 proxy-read-only-backend-addresses=192.25.0.2:3306 ##slave节点:只读
4 proxy-backend-addresses=192.25.0.1:3306 ##master节点:可读可写
5 proxy-lua-script=/usr/local/mysql-proxy/share/doc/mysql-proxy/rw-splitting.lua ##lua脚本的路径
6 pid-file=/usr/local/mysql-proxy/log/mysql-proxy.pid 进程pid的位置
7 log-file=/usr/local/mysql-proxy/log/mysql-proxy.log ##日志位置
8 plugins=proxy
9 log-level=debug ##定义日志级别
10 keepalive=true ##mysql-proxy崩溃时尝试重启
11 daemon=true ##打入后台


从这主机名开始更改为server3正常了

修改lua脚本


6.接下来测试读写分离
(1)在server1上面:创建新的用户并且授权,创建test数据库
让远程用户登录


`开始测试读写分离``
server3安装lsof
[root@server3 log]# yum install lsof

在真机上第连续三次连接数据库代理server3
先安装myriadb:

![]()
[root@foundation ~]# mysql -h 192.168.0.13 -uhaha -pHaha+123
在server3上面:lsof -i:3306
发现开始读写分离(用户多的时候)

测试:







当访问数据库的真机(用户)数量很多的时候,数据库的代理就会把后端的数据库实现读写分离 我的server1是写的数据库 我的server2是读的数据库 当我的server1和server2满足gtid的异步复制的时候,真机往数据库写入的东西其实是写入了server1,并没有写入server2,server2上面的数据是复制过去的 因此server1、server2、真机上面都能查到刚刚写进去的数据,其实真机查的是server2(读) 当关闭server1和server2的异步复制的时候,真机往数据库写入数据的东西只写进了server1,没有写进去server2,server2也没有复制一份 因为server1可以查看到,server2和真机上面都查不到刚刚写进去的数据,此时的真机读的是server2