目录
0. 引言 1. Kill Process By Kill Command && SIGNAL 2. Kill Process By Resource Limits 3. Kill Process By Code Injection Into Running Process Via GDB 4. Kill Process By Using Cross Process Virtual Memory Modify To Crash Process && process_vm_writev 5. Kill Process By Using ptrace() To Inject .so 6. Kill Process By Writing Garbage Data Into "/proc/PID/mem" Via Loop "/proc/PID/maps" To Crash Process 7. Kill Process By Writing Garbage Data Into "/proc/PID/task/PID/mem" Via Loop "/proc/PID/maps" To Crash Process 8. Kill Process By Writing Garbage Data Into "/dev/mem" Via mmap Target Process's Physical Address 10. Kill/Disabled Process Function By Decreasing Target Process's Priority && setpriority() 11. Protect Process By Three Guardian Against The Process 12. Protect Process By Set SIGNAL Catch Handle Against Kill Command 13. Protect Process By Using Linux Kernel Module To Hook Critical Function By Replacing SYSCALL TABLE Hook 14. Protect Process By Using Linux Security Module(LSM) To Hook Critical Function 15. Protect Process By Checking Who Is Opening The Process Handle 16. Protect Process By Hooking sys_open Via Disable/Remove W(Write) Flag Or Forbidden Syscall 17. Protect Protect-Module Itself 18. Improve Point 19. SourceCode
0. 引言
0x1: Linux系统攻防思想
在linux下进行"进程kill"和"进程保护"的总体思路有以下几个,我们围绕这几个核心思想展开进行研究
1. 直接从外部杀死目标进程 2. 进入到目标进程内部,从内部杀死、毁坏目标进程 3. 劫持目标进程的正常启动、执行流程,从而杀死进程 4. 利用系统原生的机制来"命令"进程结束 5. 从内核态进程进程杀死
对于系统级攻防的对抗,我们需要明白,如果防御者和攻击者所处的层次维度是相同的(Ring3 against Ring3、Ring0 against Ring0),在这种情况下,防御者对于黑客是没有任何优势的,要做到有效的防御,就需要防御者能站在比攻击者更高(底层)的逻辑层次上,即底层防御思想。在这种思想的指导下,我们可以将系统级攻防的方法论分为以下2种
1. 边界防御思想 在攻击向量的入口做鉴权、恶意检测 一个典型的实践做法就是杀软会在驱动层做自我保护,防止恶意模块进入内核,而一旦恶意模块已经进入了Ring0,则杀软则选择"信任"这个模块 2. 数据流分析思想 从数据流动的角度对攻击向量进行分析,这个分析模型要求研究员能够充分考虑到数据从入口到输出整条链路上的各种流支,即考虑各种情况,分析数据在流动过程中可能会产生哪些畸形、变异
0x2: Linux下信号的概念
Linux下信号的概念是KILL命令的原理基础,属于Linux进程间通信的一种方式
关于Linux下信号SIGNAL的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3867214.html 搜索:0x1: 信号量(Signals)
0x3: Linux Kernel Writing to Read-Only Memory
控制寄存器(Control Register)是改变、控制CPU行为的一个很重要的"电子设备组件",目前已知的控制寄存器有
//Control registers in x86 series 1. CR0 2. CR1 3. CR2 4. CR3 5. CR4 //Additional Control registers in x86-64 series 1. EFER 2. CR8
1. CR0
The CR0 register is 32 bits long on the 386 and higher processors. On x86-64 processors in long mode, it (and the other control registers) is 64 bits long. CR0 has various control flags that modify the basic operation of the processor.
CR0各个bit位代表的含义
31 bit: PG: Paging If 1, enable paging and use the CR3 register, else disable paging 30 bit: CD: Cache disable Globally enables/disable the memory cache 29 bit: NW: Not-write through Globally enables/disable write-through caching 18 bit: AM: Alignment mask Alignment check enabled if AM set, AC flag (in EFLAGS register) set, and privilege level is 3 16 bit: WP: Write protect Determines whether the CPU can write to pages marked read-only when privilege level is 0 5 bit: NE: Numeric error Enable internal x87 floating point error reporting when set, else enables PC style x87 error detection 4 bit: ET: Extension type On the 386, it allowed to specify whether the external math coprocessor was an 80287 or 80387 3 bit: TS: Task switched Allows saving x87 task context upon a task switch only after x87 instruction used 2 bit: EM: Emulation If set, no x87 floating point unit present, if clear, x87 FPU present 1 bit: MP: Monitor co-processor Controls interaction of WAIT/FWAIT instructions with TS flag in CR0 0 bit: PE: Protected Mode Enable If 1, system is in protected mode, else system is in real mode
2. CR1
Reserved
3. CR2
Contains a value called Page Fault Linear Address (PFLA). When a page fault occurs, the address the program attempted to access is stored in the CR2 register.
4. CR3
Used when virtual addressing is enabled, hence when the PG bit is set in CR0. CR3 enables the processor to translate linear addresses into physical addresses by locating the page directory and page tables for the current task. Typically, the upper 20 bits of CR3 become the page directory base register(PDBR), which stores the physical address of the first page directory entry.
5. CR4
Used in protected mode to control operations such as virtual-8086 support, enabling I/O breakpoints, page size extension and machine check exceptions.
21 bit: SMAP: Supervisor Mode Access Protection Enable If set, access of data in a higher ring generates a fault[1] 20 bit: SMEP: Supervisor Mode Execution Protection Enable If set, execution of code in a higher ring generates a fault 18 bit: OSXSAVE: XSAVE and Processor Extended States Enable 17 bit: PCIDE: PCID Enable If set, enables process-context identifiers (PCIDs). 14 bit: SMXE: Safer Mode Extensions Enable see Trusted Execution Technology (TXT) 13 bit: VMXE: Virtual Machine Extensions Enable see Intel VT-x 10 bit: OSXMMEXCPT: Operating System Support for Unmasked SIMD Floating-Point Exceptions If set, enables unmasked SSE exceptions. 9 bit: OSFXSR: Operating system support for FXSAVE and FXRSTOR instructions If set, enables SSE instructions and fast FPU save & restore 8 bit: PCE: Performance-Monitoring Counter enable If set, RDPMC can be executed at any privilege level, else RDPMC can only be used in ring 0. 7 bit: PGE: Page Global Enabled If set, address translations (PDE or PTE records) may be shared between address spaces. 6 bit: MCE: Machine Check Exception If set, enables machine check interrupts to occur. 5 bit: PAE: Physical Address Extension,If set,changes page table layout to translate 32-bit virtual addresses into extended 36-bit physical addresses. 4 bit: PSE: Page Size Extension If unset, page size is 4 KiB, else page size is increased to 4 MiB (or 2 MiB with PAE set). 3 bit: DE: Debugging Extensions If set, enables debug register based breaks on I/O space access 2 bit: TSD: Time Stamp Disable If set, RDTSC instruction can only be executed when in ring 0, otherwise RDTSC can be used at any privilege level. 1 bit: PVI: Protected-mode Virtual Interrupts If set, enables support for the virtual interrupt flag (VIF) in protected mode. 0 bit: VME: Virtual 8086 Mode Extensions If set, enables support for the virtual interrupt flag (VIF) in virtual-8086 mode.
Relevant Link:
http://en.wikipedia.org/wiki/Control_register http://en.wikipedia.org/wiki/Protected_mode http://lxr.free-electrons.com/source/arch/x86/kernel/paravirt.c#L341 http://badishi.com/kernel-writing-to-read-only-memory/
1. Kill Process By Kill Command && SIGNAL
kill命令用来终止一个进程的运行。通常,终止一个前台进程可以使用Ctrl+C键,但是,对于一个后台进程就须用kill命令来终止。kill命令是通过向进程发送指定的信号来结束相应进程的
在默认情况下,采用编号为15的SIGTERM信号。TERM信号将终止所有不能捕获该信号的进程。对于那些可以捕获该信号的进程就要用编号为9的SIGKILL信号,强制"杀掉"该进程
这里所谓的"是否能够捕获该信号",指的是目标进程是否设置了对指定信号的"处理例程",类似于C/C++中的try-catch编程模式,对于设置了指定信号处理例程的目标进程来说,KILL默认发送的TERM信号可以被目标进程所捕获,并不会导致自杀
而9号信号"SIGKILL"是一个特例,目标进程的处理例程是不允许注册监听这个信号的,所以无法"屏蔽"外部发送的SIGKILL信号,只能进行自杀
kill [参数] [进程号] 1. 参数 1) -(ASCII / number): 显示指定要发送的信号(ASCII字符 / 数字编号),若果不加信号的编号参数,则使用"-l"参数会列出全部的信号名称 2) -a: 当处理当前进程时,不限制命令名和进程号的对应关系 3) -p: 指定kill命令只打印相关进程的进程号,而不发送任何信号 4) -s (ASCII / number): 指定发送信号(ASCII字符 / 数字编号) 5) -u: 指定用户 2. 进程号: 可以通过ps、top命令获得
0x1: kill -s 9 PID / kill -s SIGKILL PID
强制、尽快终止进程,这个命令迫使进程在运行时突然终止,进程在结束后不能自我清理。危害是导致系统资源无法正常释放,一般不推荐使用,除非其他办法都无效
0x2: kill PID / kill -s 15 PID / kill -s SIGTERM PID
给父进程发送一个TERM信号,试图杀死它和它的子进程
Relevant Link:
http://blog.csdn.net/andy572633/article/details/7211546 http://tieba.baidu.com/p/347592186 http://blog.csdn.net/fxzhang/article/details/5398880 http://www.dewen.io/q/1159/%E5%A6%82%E4%BD%95%E9%98%B2%E6%AD%A2%E8%BF%9B%E7%A8%8B%E8%A2%ABkill%3F http://klinux.h.baike.com/article-81742.html http://www.live-in.org/archives/887.html http://www.cnblogs.com/peida/archive/2012/12/20/2825837.html http://www.makeuseof.com/tag/6-different-ways-to-end-unresponsive-programs-in-linux/
2. Kill Process By Resource Limits
Linux下的所有进程都需要依赖于一定的系统资源,可能是以下的项目,这个资源限制是Linux下的一个全局设置,对Linux下所有的进程都生效起作用的,注意要和ulimit命令的作用范围区分开
1. RLIMIT_CPU: CPU time in ms CPU时间的最大量值(秒),当超过此软限制时向该进程发送SIGXCPU信号 2. RLIMIT_FSIZE: Maximum file size 可以创建的文件的最大字节长度,当超过此软限制时向进程发送SIGXFSZ 3. RLIMIT_DATA: Maximum size of the data segment 数据段的最大字节长度 4. RLIMIT_STACK: Maximum stack size 栈的最大长度 5. RLIMIT_CORE: Maximum core file size 设定最大的core文件,当值为0时将禁止core文件非0时将设定产生的最大core文件大小为设定的值 6. RLIMIT_RSS: Maximum resident set size 最大驻内存集字节长度(RSS)如果物理存储器供不应求则内核将从进程处取回超过RSS的部份 7. RLIMIT_NPROC: Maximum number of processes 每个实际用户ID所拥有的最大子进程数,更改此限制将影响到sysconf函数在参数_SC_CHILD_MAX中返回的值 8. RLIMIT_NOFILE: aximum number of open files 每个进程能够打开的最多文件数。更改此限制将影响到sysconf函数在参数_SC_CHILD_MAX中的返回值 9. RLIMIT_MEMLOCK: Maximum locked-in-memory address space The maximum number of bytes of virtual memory that may be locked into RAM using mlock() and mlockall(). 10. RLIMIT_AS: Maximum address space size in bytes The maximum size of the process virtual memory (address space) in bytes. This limit affects calls to brk(2), mmap(2) and mremap(2), which fail with the error ENOMEM upon exceeding this limit. Also automatic stack expansion will fail (and generate a SIGSEGV that kills the process when no alternate stack has been made available). Since the value is a long, on machines with a 32-bit long either this limit is at most 2 GiB, or this resource is unlimited. 11. LOCKS: Maximum file locks held 12. SIGPENDING: Maximum number of pending signals 13. MSGQUEUE: Maximum bytes in POSIX mqueues 14. NICE: Maximum nice prio allowed to raise to 15. RTPRIO: Maximum realtime priority
The Linux kernel provides the getrlimit and setrlimit system calls to get and set resource limits per process. Each resource has an associated soft and hard limit.
1. soft limit: the value that the kernel enforces for the corresponding resource. 1) an unprivileged process may only set its soft limit to a value in the range from 0 up to the hard limit, and (irreversibly) lower its hard limit 2) A privileged process (one with the CAP_SYS_RESOURCE capability) may make arbitrary changes to either limit value. 2. hard limit: acts as a ceiling for the soft limit 1) A privileged process (one with the CAP_SYS_RESOURCE capability) may make arbitrary changes to either limit value.
每个进程都有一组资源限制,其中某一些可以用getrlimit和setrlimit函数查询和更改
int getrlimit(int resource, struct rlimit *rlptr); int setrlimit(int resource, const struct rlimit rlptr); int prlimit(pid_t pid, int resource, const struct rlimit *new_limit, struct rlimit *old_limit);
struct rlimit
struct rlimit { //要取得或设置的资源软限制的值 rlim_t rlim_cur; //要取得或设置的资源硬限制的值 rlim_t rlim_max; };
这两个值的设置有一个小的约束
1. 任何进程可以将软限制改为小于或等于硬限制 2. 任何进程都可以将硬限制降低,但普通用户降低了就无法提高,该值必须等于或大于软限制 3. 只有超级用户可以提高硬限制 一个无限的限制由常量RLIM_INFINITY指定(The value RLIM_INFINITY denotes no limit on a resource)
0x1: setrlimit、getrlimit、prlimit编程示例
#define _GNU_SOURCE #define _FILE_OFFSET_BITS 64 #include#include #include #include #include #define errExit(msg) do { perror(msg); exit(EXIT_FAILURE); \ } while (0) int main(int argc, char *argv[]) { struct rlimit old, new; struct rlimit *newp; pid_t pid; if (!(argc == 2 || argc == 4)) { fprintf(stderr, "Usage: %s [ ", argv[0]); exit(EXIT_FAILURE); } pid = atoi(argv[1]); /* PID of target process */ newp = NULL; if (argc == 4) { new.rlim_cur = atoi(argv[2]); new.rlim_max = atoi(argv[3]); newp = &new; } /* Set CPU time limit of target process; retrieve and display previous limit */ if (prlimit(pid, RLIMIT_CPU, newp, &old) == -1) { errExit("prlimit-1"); } printf("Previous limits: soft=%lld; hard=%lld\n", (long long) old.rlim_cur, (long long) old.rlim_max); /* Retrieve and display new CPU time limit */ if (prlimit(pid, RLIMIT_CPU, NULL, &old) == -1) { errExit("prlimit-2"); } printf("New limits: soft=%lld; hard=%lld\n", (long long) old.rlim_cur, (long long) old.rlim_max); exit(EXIT_FAILURE); }]\n
Relevant Link:
http://man7.org/linux/man-pages/man2/setrlimit.2.html http://blog.csdn.net/liangkwok/article/details/6413158
0x2: 使用ulimit杀死目标进程
这种方法的核心思想是将当前系统的资源限制降低到一个很低的水准,目标进程因为超过这个资源限制rlimit,Linux系统会自动向目标进程发送相应的"资源警告信号",目标进程如果未捕获指定信号或者设计为捕获到指定信号就强制退出,则达到kill目标进程的目的
1. 修改当前shell交互终端的limit值: 针对当前会话SESSION(同一个SID的进程组)的进程有效
ulimit为shell内建指令,可用来控制shell启动进程所使用的资源
ulimit [-acdfHlmnpsStvw] [size] -a: 显示目前资源限制的设定 -c: 设定core文件的最大值,单位为区块 -d: <数据节区大小> 程序数据节区的最大值,单位为KB -f: <文件大小> shell所能建立的最大文件,单位为区块 -H: 设定资源的硬性限制,也就是管理员所设下的限制 -m: <内存大小> 指定可使用内存的上限,单位为KB -n: <文件数目> 指定同一时间最多可开启的文件数 -p: <缓冲区大小> 指定管道缓冲区的大小,单位512字节 -s: <堆叠大小> 指定堆叠的上限,单位为KB -S: 设定资源的弹性限制 -t: 指定CPU使用时间的上限,单位为秒 -u: <程序数目> 用户最多可开启的程序数目 -v: <虚拟内存大小> 指定可使用的虚拟内存上限,单位为KB
要达到kill process的目的,我们可以修改以下几个资源限制参数
ulimit -m 5: 限制目标进程可以使用的内存 ulimit -t 1: 限制目标进程可以使用的CPU时间 ulimit -s 1024: 限制目标进程可以使用的堆栈大小 ulimit -n 10: 限制同一时间内可打开的文件数量,在Linux下,一切皆文件,包括用于网络连接的socket也是文件
使用ulimit需要注意的是它的作用范围,limit 限制的是当前 shell 进程以及其派生的子进程。举例来说,如果用户同时运行了两个 shell 终端进程,只在其中一个环境中执行了 ulimit – s 100,则该 shell 进程里创建文件的大小收到相应的限制,而同时另一个 shell 终端包括其上运行的子程序都不会受其影响
测试一下效果
echo "test ulimit" > test ls test -l //通过上面的 ulimit 设置我们已经把当前 shell 所能使用的最大内存限制在 1000KB 以下 ulimit -d 1000 -m 1000 -v 1000 ls test -l

从上面的结果可以看到,此时 ls 运行失败。根据系统给出的错误信息我们可以看出是由于调用 libc 库时内存分配失败而导致的 ls 出错
2. 修改linux的软硬件限制文件/etc/security/limits.conf: 对指定用户起作用、跨会话有效、每次重启都有效
vim /etc/security/limits.conf
# /etc/security/limits.conf # #Each line describes a limit for a user in the form: # ## #Where: # can be: # - a user name # - a group name, with @group syntax # - the wildcard *, for default entry # - the wildcard %, can be also used with %group syntax, for maxlogin limit # # can have the two values: # - "soft" for enforcing the soft limits # - "hard" for enforcing hard limits # # - can be one of the following: # - core - limits the core file size (KB) # - data - max data size (KB) # - fsize - maximum filesize (KB) # - memlock - max locked-in-memory address space (KB) # - nofile - max number of open file descriptors # - rss - max resident set size (KB) # - stack - max stack size (KB) # - cpu - max CPU time (MIN) # - nproc - max number of processes # - as - address space limit (KB) # - maxlogins - max number of logins for this user # - maxsyslogins - max number of logins on the system # - priority - the priority to run user process with # - locks - max number of file locks the user can hold # - sigpending - max number of pending signals # - msgqueue - max memory used by POSIX message queues (bytes) # - nice - max nice priority allowed to raise to values: [-20, 19] # - rtprio - max realtime priority # #* soft core 0 #* hard rss 10000 #@student hard nproc 20 #@faculty soft nproc 20 #@faculty hard nproc 50 #ftp hard nproc 0 #@student - maxlogins 4 # End of file
需要注意的是,对配置文件的修改不会立即生效,rlimit没有hot reload机制,需要手工reboot之后才能让新的配置生效
3. 修改 /proc 下的配置文件对整个系统的资源使用做一个总的限制: 全局有效、重启后失效
1. /proc/sys/kernel/pid_max 2. /proc/sys/net/ipv4/ip_local_port_range ...
关于Linux下/proc的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3883713.html
Relevant Link:
http://stackoverflow.com/questions/437433/limit-the-memory-and-cpu-available-for-a-user-in-linux http://limimgjie.iteye.com/blog/691270 http://blog.csdn.net/ithomer/article/details/8589168 https://www.ibm.com/developerworks/cn/linux/l-cn-ulimit/
3. Kill Process By Code Injection(Replace) Into Running Process Via GDB
Linux下没有Windows下的CreateRemoteThread()直接向远程进程创建(注入)新线程的机制,不能直接在目标进程中创建一个新的自杀线程去kill,而是需要采用GDB调试debug的方式,将"Kill Function Shellcode"直接注入到目标进程的内存空间中,本质就是实现对目标进程的内存修改以实现函数劫持。为了实现这种技术,我们需要先了解几个Linux下的几个基本原理
0x1: Linux ELF
http://www.cnblogs.com/LittleHann/p/3871092.html
0x2: Linux GDB Debug
http://blog.csdn.net/21cnbao/article/details/7385161 http://www.cs.cmu.edu/~gilpin/tutorial/
0x3: 实验示例程序准备
1. dynlib.h + dynlib.c: 动态(共享)库libdynlib.so,用于演示被注入(替换)的目标函数 2. app.c: 目标主程序,会链接libdynlib.so库,调用其中的目标函数 3. injection.c: 用于注入的hooked函数

1. dynlib.h + dynlib.c
//dynlib.h extern void print(); //dynlib.c #include#include #include #include "dynlib.h" extern void print() { static unsigned int counter = 0; ++counter; printf("%d : PID %d : In print()\n", counter, getpid()); }
2. app.c
//app.c #include#include #include "dynlib.h" int main() { while(1) { print(); printf("Going to sleep...\n"); sleep(3); printf("Waked up...\n"); } return 0; }
3. injection.c
//injection.c #includeextern void print(); extern void injection() { print(); //原本的工作,调用print()函数 system("date"); //添加的额外工作 }
0x4: 编译并运行程序
//动态库libdynlib.so在编译时指定了-fPIC选项,用来生成地址无关的程序 gcc -g -Wall dynlib.c -fPIC -shared -o libdynlib.so //app gcc -g app.c -ldynlib -L ./ -o app //injection.o gcc -Wall injection.c -c -o injection.o //libdynlib.so编译完成后,需要将生成的libdynlib.so文件拷贝到/usr/lib/目录下,再执行该程序 cp ./libdynlib.so /usr/lib64/ ./app

0x5: 调试目标程序: app
//4837是目标进程的PID gdb app 4847

0x6: 将注入代码加载到可执行程序的内存中
目标文件injection.o初始并不包含在app可执行进程镜像中,我们首先需要将injection.o加载到进程的内存地址空间。可以通过mmap()系统调用,该系统调用可以将injection.o文件映射到app进程地址空间中
//利用O_RDWR(值为2)的读/写权限打开injection.o文件。一会之后我们在加载注入代码时做写修改,因此需要写权限 (gdb) call open("injection.o", 2) //返回值为系统分配的文件描述符,可以看到值为3 $1 = 3 /* 调用mmap()系统调用将该文件载入进程的地址空间 1560代表injection.o的文件size为1560 mmap()函数原型如下 #includevoid *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset); 1. start: 映射区的开始地址,设置为0时表示由系统决定映射区起始地址 2. length: 映射区的长度,这里为injection.o文件的长度,我们在编译生成.o文件的时候需要记下它的size 3. prot: 期望的内存保护标志(即映射权限),不能与文件的打开模式冲突,这里为1|2|4(即PROT_READ | PROT_WRITE | PROT_EXEC,读/写/执行) 4. flags: 指定映射对象的类型,映射选项和映射页是否可以共享 5. fd: 表示已经打开的文件描述符,这里为3 6. offset: 表示被映射对象内容的起点,这里为0 */ (gdb) call mmap(0, 1560, 1|2|4, 1, 3, 0) //如果函数执行成功,则返回被映射文件在映射区的起始地址 $2 = 714252288 (gdb)

查看/proc/[pid]/maps的内容(这里pid为要注入的可执行进程的pid,本例为4953),我们可以确定injection.o文件实际被映射到的进程地址空间,在Linux系统中,文件包含当前正在运行的进程的内存布局信息
cat /proc/4953/maps 00400000-00401000 r-xp 00000000 08:02 912254 /zhenghan/gdbkill/app 00600000-00601000 rw-p 00000000 08:02 912254 /zhenghan/gdbkill/app 00c34000-00c55000 rw-p 00000000 00:00 0 [heap] 3cbf600000-3cbf620000 r-xp 00000000 08:02 41 /lib64/ld-2.12.so 3cbf81f000-3cbf820000 r--p 0001f000 08:02 41 /lib64/ld-2.12.so 3cbf820000-3cbf821000 rw-p 00020000 08:02 41 /lib64/ld-2.12.so 3cbf821000-3cbf822000 rw-p 00000000 00:00 0 3cbfe00000-3cbff8a000 r-xp 00000000 08:02 43 /lib64/libc-2.12.so 3cbff8a000-3cc018a000 ---p 0018a000 08:02 43 /lib64/libc-2.12.so 3cc018a000-3cc018e000 r--p 0018a000 08:02 43 /lib64/libc-2.12.so 3cc018e000-3cc018f000 rw-p 0018e000 08:02 43 /lib64/libc-2.12.so 3cc018f000-3cc0194000 rw-p 00000000 00:00 0 7fdf2a71b000-7fdf2a71e000 rw-p 00000000 00:00 0 7fdf2a71e000-7fdf2a71f000 r-xp 00000000 08:02 145931 /usr/lib64/libdynlib.so 7fdf2a71f000-7fdf2a91e000 ---p 00001000 08:02 145931 /usr/lib64/libdynlib.so 7fdf2a91e000-7fdf2a91f000 rw-p 00000000 08:02 145931 /usr/lib64/libdynlib.so 7fdf2a92a000-7fdf2a92b000 rwxs 00000000 08:02 912259 /zhenghan/gdbkill/injection.o 7fdf2a92b000-7fdf2a92d000 rw-p 00000000 00:00 0 7fffe21c4000-7fffe21d9000 rw-p 00000000 00:00 0 [stack] 7fffe21ff000-7fffe2200000 r-xp 00000000 00:00 0 [vdso] ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
可以看到/zhenghan/gdbkill/injection.o起始于进程地址空间的0x7fdf2a92a000地址处,终止于地址空间的0x7fdf2a92b000地址处。以上输出同时包含了其它动态库的映射信息。现在我们已经将所有需要的组件加载到可执行进程的内存空间中了
0x7: 重定位
readelf -r app Relocation section '.rela.dyn' at offset 0x480 contains 1 entries: Offset Info Type Sym. Value Sym. Name + Addend 000000600a08 000100000006 R_X86_64_GLOB_DAT 0000000000000000 __gmon_start__ + 0 Relocation section '.rela.plt' at offset 0x498 contains 4 entries: Offset Info Type Sym. Value Sym. Name + Addend 000000600a28 000300000007 R_X86_64_JUMP_SLO 0000000000000000 puts + 0 000000600a30 000400000007 R_X86_64_JUMP_SLO 0000000000000000 __libc_start_main + 0 000000600a38 000500000007 R_X86_64_JUMP_SLO 0000000000000000 sleep + 0 000000600a40 000600000007 R_X86_64_JUMP_SLO 0000000000000000 print + 0
从readelf的执行结果中,我们可以得到以下结论
1. print符号重定位位于app程序的绝对(虚拟)地址: 000000600a40偏移处 2. 重定位的类型为: R_X86_64_JUMP_SLO 3. 在程序被加载到内存且在运行之前,重定位地址是一个绝对虚拟地址 4. 该重定位驻留在程序二进制镜像的.rel.plt段内。PLT即"Procedure Linkage Table"的缩写,是为函数间接调用提供的表,即在app调用print函数不是直接跳转到函数的位置,而是首先跳转到"Procedure Linkage Table"的入口处,之后再从PLT跳转到函数的实际代码处 5. 在"Procedure Linkage Table"这种模式下,如果要调用的函数位于一个动态库中(如本例中的libdynlib.so),那么这种做法是必要的,因为我们不可能提前知道动态库会被加载到进程空间的什么位置,以及动态库中的第一个函数是什么(本例中为print()函数)。所有这些信息只在程序被加载到内存之后且运行之前有效,这时系统的动态链接器(Linux系统中为ld-linux.so)会解决重定位的问题,使请求的函数能够被正确调用 6. 在本文的例子中,动态链接器会将libdynlib.so加载到可执行进程的地址空间,找到print()函数在库中的地址,并将该地址赋值到重定位地址: 000000600a40,即间接跳转表中,这样,app进程在执行过程中,通过间接跳转表,就可以正确调用到动态链接库中的指定函数
我们的目标是用injection.o目标文件中的injection()函数地址替换print()函数的地址,而injection()函数在程序启动的时候并不包含在app的进程空间中
//查看print()函数的地址 (gdb) p & print $3 = (void (*)()) 0x7ffc537625bcp/x * 0x000000600a40 (gdb) p/x * 0x000000600a40 $4 = 0x537625bc //injection()函数的地址可以通过对injection.o文件运行readelf –s(显示目标文件的符号表)得到: readelf -s injection.o Symbol table '.symtab' contains 12 entries: Num: Value Size Type Bind Vis Ndx Name 0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND 1: 0000000000000000 0 FILE LOCAL DEFAULT ABS injection.c 2: 0000000000000000 0 SECTION LOCAL DEFAULT 1 3: 0000000000000000 0 SECTION LOCAL DEFAULT 3 4: 0000000000000000 0 SECTION LOCAL DEFAULT 4 5: 0000000000000000 0 SECTION LOCAL DEFAULT 5 6: 0000000000000000 0 SECTION LOCAL DEFAULT 7 7: 0000000000000000 0 SECTION LOCAL DEFAULT 8 8: 0000000000000000 0 SECTION LOCAL DEFAULT 6 9: 0000000000000000 26 FUNC GLOBAL DEFAULT 1 injection 10: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND print 11: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND system //函数(符号)injection位于injection.o文件.text段的偏移0处 //.text段起始于injection.o文件的偏移0x00000040处 readelf -S injection.o Section Headers: [Nr] Name Type Address Offset Size EntSize Flags Link Info Align [ 0] NULL 0000000000000000 00000000 0000000000000000 0000000000000000 0 0 0 [ 1] .text PROGBITS 0000000000000000 00000040 000000000000001a 0000000000000000 AX 0 0 4 [ 2] .rela.text RELA 0000000000000000 000005b8 0000000000000048 0000000000000018 11 1 8 [ 3] .data PROGBITS 0000000000000000 0000005c 0000000000000000 0000000000000000 WA 0 0 4 [ 4] .bss NOBITS 0000000000000000 0000005c 0000000000000000 0000000000000000 WA 0 0 4 [ 5] .rodata PROGBITS 0000000000000000 0000005c 0000000000000005 0000000000000000 A 0 0 1 [ 6] .comment PROGBITS 0000000000000000 00000061 000000000000002e 0000000000000001 MS 0 0 1 [ 7] .note.GNU-stack PROGBITS 0000000000000000 0000008f 0000000000000000 0000000000000000 0 0 1 [ 8] .eh_frame PROGBITS 0000000000000000 00000090 0000000000000038 0000000000000000 A 0 0 8 [ 9] .rela.eh_frame RELA 0000000000000000 00000600 0000000000000018 0000000000000018 11 8 8 [10] .shstrtab STRTAB 0000000000000000 000000c8 0000000000000061 0000000000000000 0 0 1 [11] .symtab SYMTAB 0000000000000000 00000470 0000000000000120 0000000000000018 12 9 8 [12] .strtab STRTAB 0000000000000000 00000590 0000000000000024 0000000000000000 0 0 1
0x8: 用injection()函数替换print()函数
injection.o文件已经被加载到app进程内存空间的地址0x:7ffc5396e000。因此injection()函数的最终绝对虚拟地址为0x7ffc5396e000+0x40 = 0x7ffc5396e040
我们接下来用0x7ffc5396e040替换print()函数的重定位地址: 0x000000600a40
(gdb) set *0x000000600a40 = 0x7ffc5396e000+0x40
0x9: 解决injection()函数的重定位
injection()函数的代码目前还不能运行,因为我们仍有3个重定位没有解决
readelf -r injection.o Relocation section '.rela.text' at offset 0x5b8 contains 3 entries: Offset Info Type Sym. Value Sym. Name + Addend 00000000000a 000a00000002 R_X86_64_PC32 0000000000000000 print - 4 00000000000f 00050000000a R_X86_64_32 0000000000000000 .rodata + 0 000000000014 000b00000002 R_X86_64_PC32 0000000000000000 system - 4 Relocation section '.rela.eh_frame' at offset 0x600 contains 1 entries: Offset Info Type Sym. Value Sym. Name + Addend 000000000020 000200000002 R_X86_64_PC32 0000000000000000 .text + 0 /* 1. print重定位引用libdynlib.so库中的print()函数调用 2. .rodata重定位指向保存在.rodata只读数据段的"date"常量字符串(即system(date)调用中的"date") 3. system重定位引用系统的system()函数调用 需要注意的是所有这三个重定位是驻留在.rel.text段中的,因此它们的偏移是相对于.text段而言的 */ //我们需要手动解决以上三个重定位,为这三个内存位置设置适当的地址。程序进程地址空间中的这些重定位地址是通过求和计算出来的: 1. injection.o在进程地址空间中的起始地址: 0x7ffc5396e000 2. .text段在injection.o目标文件中的起始偏移量: 0x40 3. 相对于.text段的重定位偏移量 1) print: 0x00000000000a 2) .rodata: 0x00000000000f 3) system: 0x000000000014
可以看到print与system的重定位类型为R_X86_64_PC32,意味着要设置的重定位地址的值应该利用程序计数寄存器PC来计算,这样才是相对于重定位地址的
(gdb) p & system // system()函数的地址 $5 = 0x3cbfe3e8f0(gdb) p * (0x7ffc5396e000 + 0x40 + 0x000000000014) // system符号重定位的加数 $6 = 0 (gdb) set * (0x7ffc5396e000 + 0x40 + 0x000000000014) = 0x3cbfe3e8f0 - (0x7ffc5396e000 + 0x40 + 0x000000000014) - 4 (gdb) p & print // print()函数的地址 $7 = (void (*)()) 0x7ffc537625bc (gdb) p * (0x7ffc5396e000 + 0x40 + 0x00000000000a) // print符号重定位的加数 $8 = 0 (gdb) set * (0x7ffc5396e000 + 0x40 + 0x00000000000a) = 0x7ffc537625bc - (0x7ffc5396e000 + 0x40 + 0x00000000000a) - 0 (gdb) p * (0x7ffc5396e000 + 0x40 + 0x00000000000f) // .rodata符号重定位的加数 $9 = 0 //0x0000005c.rodata 段在injection.o目标文件中的偏移(见第七节结尾处) (gdb) set * (0x7ffc5396e000 + 0x40 + 0x00000000000f) = 0x7ffc5396e000 + 0x0000005c //解决了injection()函数代码中的所有3个重定位,那么要做的准备工作就做完了,可以退出gdb调试器了。应用程序会继续运行,并且在此之后,除了继续之前的打印工作,程序同时还会输出当前的日期 q
回到我们本小节的最终目的来看,使用GDB调试技术进行Process Kill
1. 使用GDB Debugger挂载Attach到目标进程上,调用: call exit(0),强制目标进程退出 2. 使用GDB Debugger挂载Attach到目标进程上,向其中注入一段hooked函数,劫持目标进程的核心功能,或者直接退出 3. 使用GDB Debugger挂载Attach到目标进程上,对其中关键的代码偏移位置进行修改,典型地如关键if判断语句,强制目标进程偏离正常代码逻辑,导致退出
Relevant Link:
http://www.freebuf.com/articles/system/6388.html http://blog.chinaunix.net/uid-29482215-id-4135833.html http://www.codeproject.com/Articles/33340/Code-Injection-into-Running-Linux-Application
4. Kill Process By Using Cross Process Virtual Memory Modify To Crash Process && process_vm_writev
通过跨进程虚拟内存修改、破坏,从而迫使目标进程退出。在基于虚拟内存(Vitual Memory)机制的前提下,即使单个进程的虚拟内存遭到了清零攻击,Linux系统下的其他进程也会正常运行而不受任何影响
write_zero_crack.c
#include#include #include int main(int argc, char* argv[]) { if (argc != 2) return -1; int pid = atoi(argv[1]); int size = 1024; int nwrite; struct iovec local; struct iovec remote; void *buf = malloc(size); void* p = 0; //write zero to the target process while (p < 0xffffffff) { local.iov_base = buf; local.iov_len = size; remote.iov_base = (void*)p; p += size; remote.iov_len = size; nwrite = process_vm_writev(pid, &local, 1, &remote, 1, 0); } free(buf); return 0; }
通过这种暴力的方法,实现对目标进程的虚拟内存的破坏,从而达到KILL Process的目的
Relevant Link:
http://man7.org/linux/man-pages/man2/process_vm_readv.2.html http://www.ibm.com/developerworks/library/l-kernel-memory-access/
5. Kill Process By Using ptrace() To Inject .so
需要明白的是"基于GDB挂载的代码注入技术"本质上就是利用的ptrace注入技术,即GDB是基于ptrace实现的
0x1: ptrace简介
ptrace的原型
#includelong int ptrace(enum __ptrace_request request, pid_t pid, void * addr, void * data) /* ptrace参数 1. request: 决定ptrace做什么: /usr/include/sys/ptrace.h 1) PTRACE_TRACEME PTRACE_TRACEME是被父进程用来跟踪子进程的.正如前面所说的,任何信号(除了SIGKILL),不管是从外来的还是由exec系统调用产生的,都将使得子进程被暂停,由父进程决定子进程的行为.在request为PTRACE_TRACEME情况下,ptrace()只干一件事,它检查当前进程的ptrace标志是否已经被设置,没有的话就设置ptrace标志,除了request的任何参数(pid,addr,data)都将被忽略. 2) PTRACE_ATTACH request为PTRACE_ATTACH也就意味着,一个进程想要控制另外一个进程.需要注意的是,任何进程都不能跟踪控制起始进程init,一个进程也不能跟踪自己.某种意义上,调用ptrace的进程就成为了ID为pid的进程的’父’进程.但是,被跟踪进程的真正父进程是ID为getpid()的进程. 3) PTRACE_DETACH: 用来停止跟踪一个进程.跟踪进程决定被跟踪进程的生死.PTRACE_DETACH会恢复PTRACE_ATTACH和PTRACE_TRACEME的所有改变.父进程通过data参数设置子进程的退出状态(exit code).子进程的ptrace标志就被复位,然后子进程被移到它原来所在的任务队列中.这时候,子进程的父进程的ID被重新写回子进程的父进程标志位.可能被修改了的single-step标志位也会被复位.最后,子进程被唤醒,貌似神马都没有发生过;参数addr会被忽略 4) PTRACE_PEEKTEXT, PTRACE_PEEKDATA, PTRACE_PEEKUSER: 这些宏用来读取子进程的内存和用户态空间(user space).PTRACE_PEEKTEXT和PTRACE_PEEKDATA从子进程内存读取数据,两者功能是相同的.PTRACE_PEEKUSER从子进程的user space读取数据.它们读一个字节的数据,保存在临时的数据结构中,然后使用put_user()(它从内核态空间读一个字符串到用户态空间)将需要的数据写入参数data,返回0表示成功. 对PTRACE_PEEKTEXT和PTRACE_PEEKDATA而言,参数addr是子进程内存中将被读取的数据的地址.对PTRACE_PEEKUSER来说,参数addr是子进程用户态空间的偏移量,此时data被无视. 5) PTRACE_POKETEXT, PTRACE_POKEDATA, PTRACE_POKEUSER: 这些宏行为与上面的几个是类似的.唯一的不同是它们用来写入data 6) PTRACE_SYSCALL, PTRACE_CONT: 这些宏用来唤醒暂停的子进程.在每次系统调用之后,PTRACE_SYSCALL使子进程暂停,而PTRACE_CONT让子进程继续运行.子进程的返回状态都是由ptrace()参数data设置的.但是,这只限于返回状态是有效的情况.ptrace()重置子进程的single-step位,设置/复位syscall-trace位,然后唤醒子进程;参数addr被无视. 7) PTRACE_SINGLESTEP PTRACE_SINGLESTEP的行为与PTRACE_SYSCALL无异,除了子进程在每次机器指令后都被暂停(PTRACE_SYSCALL是使子进程每次在系统调用后被暂停).single-step会被设置,跟PTRACE_SYSCALL一样,参数data包含返回状态,参数addr被无视. 8) PTRACE_KILL PTRACE_KILL被用来终止子进程.”谋杀”是这样进行的: 首先ptrace() 查看子进程是不是已经死了.如果不是, 子进程的返回码被设置为sigkill. single-step位被复位.然后子进程被唤醒,运行到返回码时子进程就死掉了. 2. pid: 被跟踪进程的ID 3. addr: 进程空间偏移量 3. data: 存储从进程空间偏移量为addr的地方开始将被读取/写入的数据 ptrace返回值 1. EPERM: 权限错误,进程无法被跟踪. 2. ESRCH: 目标进程不存在或者已经被跟踪. 3. EIO: 参数request的值无效,或者从非法的内存读/写数据. 4. EFAULT: 需要读/写数据的内存未被映射. */
0x2: ptrace编程示例
#include#include #include #include #include #include #include #include #include int main(void) { long long counter = 0; /* machine instruction counter */ int wait_val; /* child's return value */ int pid; /* child's process id */ puts("Please wait"); switch (pid = fork()) { case -1: perror("fork"); break; case 0: /* child process starts */ ptrace(PTRACE_TRACEME, 0, 0, 0); /* * must be called in order to allow the * control over the child process */ execl("/bin/ls", "ls", NULL); /* * executes the program and causes * the child to stop and send a signal * to the parent, the parent can now * switch to PTRACE_SINGLESTEP */ break; /* child process ends */ default:/* parent process starts */ wait(&wait_val); /* * parent waits for child to stop at next * instruction (execl()) */ while (wait_val == 1407 ) { counter++; if (ptrace(PTRACE_SINGLESTEP, pid, 0, 0) != 0) perror("ptrace"); /* * switch to singlestep tracing and * release child * if unable call error. */ wait(&wait_val); /* wait for next instruction to complete */ } /* * continue to stop, wait and release until * the child is finished; wait_val != 1407 * Low=0177L and High=05 (SIGTRAP) */ } printf("Number of machine instructions : %lld\n", counter); return 0; }
0x3: 基于ptrace向运行中进程注入.so并执行相关函数
我们已经学习了如何通过GDB单步调试的方式将.so注入到目标进程中,并手工完成函数地址重定位、以及目标函数replace hook替换,从而实现代码注入函数劫持的目的
通过ptrace,我们可以更方便的完成这个目的
1. 让目标进程执行一段代码,通过dlopen把需要注入的"inject.so"加载到目标进程的空间中 1) 在目标进程中找到存放"加载inject.so的实现代码"的空间(通过mmap实现) 2) 把"加载inject.so的实现代码"写入目标进程指定的空间 3) 启动执行 2. dlopen会自动完成inject.so的载入和函数重定位这些事情 3. 使用"inject.so"中的函数replace目标进程中的指定函数,完成function replace hook
Relevant Link:
http://blog.csdn.net/myarrow/article/details/9630377 http://blog.csdn.net/yyttiao/article/details/7777032 http://man7.org/linux/man-pages/man2/ptrace.2.html http://godorz.info/2011/02/process-tracing-using-ptrace/
6. Kill Process By Writing Garbage Data Into "/proc/PID/mem" Via Loop "/proc/PID/maps" To Crash Process
/proc/是Linux下的一个特殊的文件,它将Ring3和Ring0连接了起来,允许管理员直接从用户态Ring3对内核态Ring0进行读写操作,关于Linux下/proc/的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3883713.html 搜索:3. 进程信息
/proc/pid/maps中保存的目标进程的内存分布信息,以此为索引进行对/proc/pid/mem进行内存遍历
#! /usr/bin/env python import re import sys def main(): if len(sys.argv) != 2: return try: pid = int(sys.argv[1]) except Exception, e: return fmaps = open('/proc/%d/maps' % (pid)) fmem = open('/proc/%d/mem' % (pid), 'w') for line in fmaps: m = re.match('^([^-]+)-([^ ]+) .w', line) if m: addr_start = int(m.group(1), 16) addr_end = int(m.group(2), 16) fmem.seek(addr_start) fmem.write('x' * (addr_end - addr_start)) fmaps.close() fmem.close() if __name__ == '__main__': main()
7. Kill Process By Writing Garbage Data Into "/proc/PID/task/PID/mem" Via Loop "/proc/PID/task/PID/maps" To Crash Process
Linux下没有Windows下的那种严格的进程/线程概念,所有的进程/线程都被统一抽象成了"任务task"的概念,而例如Apache这种多线程应用在Linux下是以一种"进程组"的形式存在,子线程和父进程之间同属于一个"进程组",它们共享一个"TGID"
关于Linux下进程标识号的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/4026781.html 搜索:2. Linux进程的相关标识
而在/proc/PID/task下保存的就是指定进程的进程组相关的成员信息,在这个目录下,保存着和/proc/PID下相同的一套元数据,它们都可以直接对内核态中的进程相关数据结构进行读写操作
#! /usr/bin/env python import re import sys def main(): if len(sys.argv) != 2: return try: pid = int(sys.argv[1]) except Exception, e: return fmaps = open('/proc/%d/task/%d/maps' % (pid)) fmem = open('/proc/%d/task/%d/mem' % (pid), 'w') for line in fmaps: m = re.match('^([^-]+)-([^ ]+) .w', line) if m: addr_start = int(m.group(1), 16) addr_end = int(m.group(2), 16) fmem.seek(addr_start) fmem.write('x' * (addr_end - addr_start)) fmaps.close() fmem.close() if __name__ == '__main__': main()
Relevant Link:
http://www.cnblogs.com/LittleHann/p/4026781.html
8. Kill Process By Writing Garbage Data Into "/dev/mem" Via mmap Target Process's Physical Address
0x1: "/dev/mem"简介
"dev/mem"是物理内存的全镜像。可以用来从用户态访问全部物理内存
1. dev/mem 用来访问物理IO设备,例如 访问显卡的物理内存,或嵌入式中访问GPIO。用法一般就是open,然后mmap,接着可以使用map之后的地址来访问物理内存。这其实就是实现用户空间驱动的一种方法 /* 标准VGA 16色模式的实模式地址是A000:0000,而线性地址则是A0000。设定显存大小为0x10000,则可以如下操作 mem_fd = open( "/dev/mem", O_RDWR ); vga_mem = mmap( 0, 0x10000, PROT_READ | PROT_WRITE, MAP_SHARED, mem_fd, 0xA0000 ); close( mem_fd ); */ 2. 通过/dev/mem设备文件和mmap系统调用,可以将线性地址描述的物理内存映射到进程 的地址空间,然后就可以直接访问这段内存了
0x2: /dev/mem的读写限制
由于kernel对user space访问/dev/mem是有限制的,需要内核编译选项的支持
CONFIG_STRICT_DEVMEM
只有在.config文件中设置CONFIG_STRICT_DEVMEM=n才能获得对整个memory的访问权限,在默认情况下,CONFIG_STRICT_DEVMEM=y
\linux-3.15.5\arch\x86\Kconfig.debug
config STRICT_DEVMEM bool "Filter access to /dev/mem" ---help--- If this option is disabled, you allow userspace (root) access to all of memory, including kernel and userspace memory. Accidental access to this is obviously disastrous, but specific access can be used by people debugging the kernel. Note that with PAT support enabled, even in this case there are restrictions on /dev/mem use due to the cache aliasing requirements. If this option is switched on, the /dev/mem file only allows userspace access to PCI space and the BIOS code and data regions. This is sufficient for dosemu and X and all common users of /dev/mem. If in doubt, say Y.
CONFIG_X86_PAT
这个选项也是默认开启的,但是要关闭这个选项还需要开启CONFIG_EXPERT
设置好这三个编译选项后,重新编译kernel,这个时候就可以从用户态对/dev/mem进行读写操作了
0x3: 对/dev/mem进行内存读写
#include#include #include #include #include #include int main() { unsigned char * map_base; FILE *f; int n, fd; fd = open("/dev/mem", O_RDWR|O_SYNC); if (fd == -1) { return (-1); } map_base = mmap(NULL, 0xff, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0x20000); if (map_base == 0) { printf("NULL pointer!\n"); } else { printf("Successfull!\n"); } unsigned long addr; unsigned char content; int i = 0; for (;i < 0xff; ++i) { addr = (unsigned long)(map_base + i); content = map_base[i]; printf("address: 0x%lx content 0x%x\t\t", addr, (unsigned int)content); map_base[i] = (unsigned char)i; content = map_base[i]; printf("updated address: 0x%lx content 0x%x\n", addr, (unsigned int)content); } close(fd); munmap(map_base, 0xff); return (1); }
要实现Process Kill的目的,我们的思路如下
1. 在用户态将/dev/mem用mmap映射出来 2. 通过内存搜索得到目标进程的起始位置(物理内存地址) 3. 对指定进程的内存空间写入垃圾数据,达到Kill Process的目的
Relevant Link:
http://blog.csdn.net/skyflying2012/article/details/8930689 http://blog.sina.com.cn/s/blog_6f5b220601012xbc.html http://blog.csdn.net/zhanglei4214/article/details/6653568
10. Kill/Disabled Process Function By Decreasing Target Process's Priority && setpriority()
从最终的实现效果来看,Kill Process的目的是使得目标进程的服务不可用,例如一个防御系统的响应时间周期是1s,如果通过降低它的进程优先级,使得它的响应时间周期降低到10s甚至更长,从某种程度上也实现了Kill Process的目的,因为黑客可以将这个被延长的时间周期内完成攻击动作,从而躲避防御系统的检测
系统中运行的每个进程都有一个优先级("nice值"),其范围从
1. -20(最高优先级) ~ 2. 19 (最低优先级)
默认情况下,进程的优先级是0("基本"调度优先级)
1. 一般用户只能降低它们自己进程的优先级别,并限于 0 ~ 19 之间 2. 超级用户(root)可以将任何进程的优先级设定为任何值
0x1: 查看进程的优先级
使用top指令,看到的"PR"字段就是进程的优先级,值得注意的是,使用ps -efl指令看到的是进程的内核调度优先级,这2个是不同的概念
renice new_pri -p pid
0x2: 修改进程优先级
#include#include #include #include #include #include int main(void) { pid_t pid; int stat_val = 0; int oldpri, newpri; printf("nice study\n"); pid = fork(); switch( pid ) { case 0: printf("Child is running, Curpid is %d, Parentpid is %d\n", pid, getppid()); oldpri = getpriority(PRIO_PROCESS, getpid()); printf("Old priority = %d\n", oldpri); newpri = nice(2); printf("New priority = %d\n", newpri); exit(0); case -1: perror("Process creation failed\n"); break; default: printf("Parent is running,Childpid is %d, Parentpid is %d\n", pid, getpid()); break; } wait(&stat_val); exit(0); }
Relevant Link:
http://man.chinaunix.net/linux/mandrake/101/zh_cn/Command-Line.html/process-priority.html http://freeloda.blog.51cto.com/2033581/1189104 http://www.ibm.com/developerworks/cn/linux/l-lpic1-v3-103-6/ http://www.groad.net/bbs/thread-869-1-1.html
11. Protect Process By Three Guardian Against The Process
0x1: Linux下双守护、三守护进程
大多数情况下,Linux下多进程互守护是这样的架构
1. 守护进程: 服务例程(service),定时的监控其他被守护进程,如果发现被守护进程被关闭,则主动启动恢复被守护进程 2. 被守护进程: 普通进程,同时被守护进程也具有守护进程的功能,对守护例程(server)进行监控,并在需要的时候启动恢复守护例程
0x2: Linux下Deamon守护进程
Daemon是长时间运行的进程,通常在系统启动后就运行,在系统关闭时才结束。一般说Daemon程序在后台运行,是因为它没有控制终端,无法和前台的用户交互。Daemon程序一般都作为服务程序使用,等待客户端程序与它通信。我们也把运行的Daemon程序称作守护进程。
Daemon程序编写原则
1. 首先是程序运行后调用fork,并让父进程退出。子进程获得一个新的进程ID,但继承了父进程的进程组ID 2. 调用setsid创建一个新的session,使自己成为新session和新进程组的leader,并使进程没有控制终端(tty) 3. 改变当前工作目录至根目录,以免影响可加载文件系统。或者也可以改变到某些特定的目录 4. 设置文件创建mask为0,避免创建文件时权限的影响 5. 关闭不需要的打开文件描述符。因为Daemon程序在后台执行,不需要于终端交互,通常就关闭STDIN、STDOUT和STDERR。其它根据实际情况处理。另一个问题是Daemon程序不能和终端交互,也就无法使用printf方法输出信息了 6. Daemon程序不能和终端交互,也就无法使用printf方法输出信息了。我们可以使用syslog机制来实现信息的输出,方便程序的调试
deamontest.c
#include#include #include #include #include #include #include int daemon_init(void) { pid_t pid; if((pid = fork()) < 0) { return(-1); } else if(pid != 0) { exit(0); /* parent exit */ } /* child continues */ setsid(); /* become session leader */ chdir("/"); /* change working directory */ umask(0); /* clear file mode creation mask */ close(0); /* close stdin */ close(1); /* close stdout */ close(2); /* close stderr */ return(0); } void sig_term(int signo) { if(signo == SIGTERM) /* catched signal sent by kill(1) command */ { syslog(LOG_INFO, "program terminated."); closelog(); exit(0); } } int main(void) { if(daemon_init() == -1) { printf("can't fork self/n"); exit(0); } openlog("daemontest", LOG_PID, LOG_USER); syslog(LOG_INFO, "program started."); signal(SIGTERM, sig_term); /* arrange to catch the signal */ while(1) { sleep(1); /* put your main program here */ } return(0); }
编译、运行
ps axj | grep deamon

Deamon进程不直接和前台UI交互,需要使用kill命令来结束Deamon进程
Relevant Link:
http://www.oschina.net/code/snippet_237505_8650 http://blog.csdn.net/ast_224/article/details/3860680 http://www.nenew.net/linux-c-program-daemon-example.html http://man7.org/linux/man-pages/man3/daemon.3.html http://linux.die.net/man/3/daemon 辅助:crontab周期检查
12. Protect Process By Set SIGNAL Catch Handle Against Kill Command
我们知道,信号是在软件层次上对中断机制的一种模拟,在原理上,一个进程收到一个信号与处理器收到一个中断请求可以说是一样的。信号是异步的,一个进程不必通过任何操作来等待信号的到达,事实上,进程也不知道信号到底什么时候到达
当向一个进程发送一个信号的时候,目标进程一定会产生"中断",如果在进程中没有对其进行捕获的话,进程在收到它们时,会终止,当然,还有不可捕获的SIGKILL(9)(Ctrl+C发出的就是SIGKILL信号)与SIGSTOP(19)
0x1: 可屏蔽、不可屏蔽信号的分类
1. 不可屏蔽信号 信号不可屏蔽,意味着我们无法针对这类信号设置"信号处理例程",则如果目标进程收到这类信号,一定会终止进程 1) SIGKILL: Kill (terminate immediately): 常用的Ctrl+C 发出的是SIGKILL信号 2) SIGSTOP: Stop executing temporarily 2. 默认屏蔽信号 1) SIGCHLD: Child process terminated, stopped (or continued*) 3. 可屏蔽信号 对于可屏蔽信号,如果在进程中没有对其进行捕获处理的话,进程在收到它们时,会终止 ,SIGUSR2 1) SIGABRT: Process aborted 2) SIGALRM: Signal raised by alarm 3) SIGFPE: Floating point exception: "erroneous arithmetic operation" 4) SIGPIPE: Write to pipe with no one reading 5) SIGINT: Interrupt 6) SIGHUP: Hangup 7) SIGILL: Illegal instruction 8) SIGQUIT: Quit and dump core 9) SIGSEGV: Segmentation violation 10) SIGTERM: Termination (request to terminate) 11) SIGUSR1: User-defined 1 12) SIGUSR2: User-defined 2
0x2: 设置对指定信号的捕获
通过使用signal函数,实现对目标信号的捕获机制,这样在收到目标信号后,程序会继续运行
typedef void (*sighandler_t)(int); sighandler_t signal(int signum, sighandler_t handler); /* 1. signum: 目标信号 2. handler: 处理方法 1) 自定义的函数,也可以是 2) SIG_IGN: 目标信号将被忽略 3) SIG_DFL: 将被忽略的信号恢复 */
catch_signal.c
#include#include #include #include #include void handler() { printf("capture a SIGALRM signal\n"); } int main() { //设置对SIGALRM信号的捕获 signal(SIGTERM, handler); //等待外部传入信号 pause(); //如果打印了这行就说明我们对信号进行了正确的捕获,程序收到信号后正常运行 printf("the process will run normally\n"); }
编译运行
gcc catch_signal.c -o catch_signal ./catch_signal ps -ef | grep catch_signal kill 12233 //程序成功对kill指令发出的SIGTERM信号进行了捕获,并继续正常运行

通过设置SIGNAL信号的捕获函数实现对KILL指令的屏蔽是一个很好的思路,但是要注意的是,这种方法同样会屏蔽正常管理员对目标程序的KILL操作,在实现进程保护的时候,需要特别考虑的问题是,我们需要为进程保护设立一个"可信通道方式",即要允许管理员有方法能够对目标进行KILL操作,而对非法未授权用户禁止KILL操作
0x3: 通过发送信号KILL进程
可以向其他进程发送SIGNAL信号的"C API"
1. kill int kill(pid_t pid, int sig); 2. sigqueue int sigqueue(pid_t pid, int sig, const union sigval value);
可以向其他进程发送SIGNAL信号的"系统调用"
1. sys_kill: 向进程或进程组发信号
需要明白的是,Linux下使用KILL、KILLALL...指令进行Process Kill本质上是在调用C API
send.c
#ifndef _APUE_H_ #define _APUE_H_ #include#include #include #include #include <string.h> #include #include #include #include #include #include #include #include void err_exit(char *m) { perror(m); exit(EXIT_FAILURE); } #endif /* _APUE_H_ */ int main(int argc, char *argv[]) { if(argc != 2) { fprintf(stderr, "usage: ./%s pid\n", argv[0]); } pid_t pid = atoi(argv[1]); union sigval v; v.sival_int = 100; sigqueue(pid, SIGTERM, v); return 0; }
编译运行
gcc send.c -o send ps -ef | grep catch_signal ./send 12436

一个好的安全实践是:
1. 防护模块应该保持足够的第三方独立性,而不应该将防御机制侵入到待保护进程的代码中 2. 可以灵活地指定需要保护的目标进程、需要屏蔽的信号 3. 要对Linux下的SIGNAL信号进行监控、审核,针对信号本身进行Hook无法实现,只能针对信号产生的源头函数(系统调用)进行Hook审计 1) kill 2) sigqueue
Relevant Link:
http://biancheng.dnbcw.info/linux/350564.html http://hallen.blog.51cto.com/1820469/1182335
13. Protect Process By Using Linux Kernel Module To Hook Critical Function By Replacing SYSCALL TABLE Hook
对于进程保护,我们这里不考虑在Ring3层进行Ring3 Function Replace Hook,我们采用对syscall hook的方式进行底层防御,因为所有的Ring3层的指令和C API最终都会调用到系统底层
0x1: Linux下syscall table replace hook
关于Linux下实现系统调用表hook的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3854977.html
Relevant Link:
http://roclinux.cn/?p=1422 http://www.ibm.com/developerworks/cn/linux/kernel/syscall/part1/appendix.html
0x2: 编程实例
我们的防御策略如下
1. sys_kill 1) 只允许"指定进程"向"受保护进程"发起KILL系统调用:/usr/bin/topMonitor kill protected_process 2. sys_delete_module 1) 只允许指定进程卸载保护模块:topMonitor rmmod syscall_hk 2) 禁止非指定进程卸载保护模块(保护自己):other process can't rmmod syscall_hk 3) 非指定进程可以卸载其他模块:other process can rmmod other module 3. sys_ptrace 1) 禁止任何程序调试、挂载"受保护进程":any process can't debug protected_process 4. sys_process_vm_writev 1) 禁止任何程序向"受保护进程"进行跨进程虚拟内存读写 5. topMonitor 1) 开机自动insmod加载保护模块:insmod syscall_hk.ko when start up
driverp.c
相关的代码详见文章的末尾
Relevant Link:
http://lixiang7.lofter.com/post/1b42fc_96d3e4 http://www.gilgalab.com.br/hacking/programming/linux/2013/01/11/Hooking-Linux-3-syscalls/ http://www.cnblogs.com/l137/p/3480671.html
14. Protect Process By Using Linux Security Module(LSM) To Hook Critical Function
对这个LSM回调进行注册、函数实现。实现对kill系统调用的禁用保护
/source/security/security.c
int security_task_kill(struct task_struct *p, struct siginfo *info, int sig, u32 secid) { return security_ops->task_kill(p, info, sig, secid); }
使用LSMs可以在Linux Source Code层次上进行串行的审计、阻断,关于LSMs的相关知识,请参阅另一篇文章
Relevant Link:
http://www.cnblogs.com/LittleHann/p/4134939.html
15. Protect Process By Checking Who Is Opening The Process Handle
在windows上,将目标进程的进程句柄的"入口操作权限"处作限制,使用双守护,一个常驻服务进程、一个前台UI进程
1. 如果是白名单的常驻服务进程在打开目标进程的进程句柄,则开放读写权限给这个句柄 2. 如果是非可信的进程在打开目标进程的进程句柄,则将写权限flag去掉,使黑客无法kill目标进程
Linux下没有像windows那样对系统中运行的所有对象都抽象出了一个统一的句柄这个接口概念,所以这个思路放在这里作为参考学习之用
16. Protect Process By Hooking sys_open Via Disable/Remove W(Write) Flag Or Forbidden Syscall
针对黑客向/proc/pid/mem、/proc/pid/task/pid/mem、/dev/mem写入垃圾数据的攻击方式,我们需要对文件系统的读写操作进行Hook保护
对于文件系统的读写保护,我们需要实现的目标、以及需要注意的几点如下
0x1: 使用inode id实现对打开文件路径的识别
Linux下的"磁盘路径"不是一个强概念,在Linux下,各级层次目录本质上是由一些inode节点互相挂载连接而成的,我们打开一个绝对路径的文件,本质上也是在根据inode节点进行逐级的递归寻找,关于Linux Inode的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/4208619.html
基于对Linux Inode的了解,我们可以发现一种绕过防御的方法
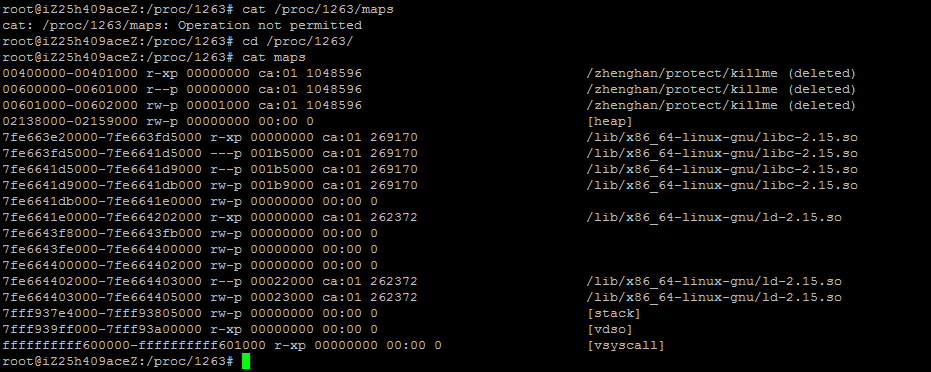

为了解决这个问题,我们可以采用inode id(文件节点id)实现对文件绝对路径的精确识别
unsigned long getInodeIDbyFilename(const char *filename) { unsigned long proc_ino = 0; struct file *filp = filp_open(filename, O_RDONLY, 0); if( !IS_ERR(filp) ) { proc_ino = filp->f_dentry->d_inode->i_ino; filp_close(filp, 0); } else { proc_ino = 0; } return proc_ino; }
driverp.c
相关的代码详见文章的末尾
相关的数据结构,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3865490.html 搜索:4. 文件系统相关数据结构
Relevant Link:
http://baike.baidu.com/link?url=s9hV7V1UxT2K8ER2KqA-UzwL2mUO0m1mdDF5A1ohUg-_CNSIOdf2aGrt22IgDn3F1XepksKqODb6zPlshRAM0_ http://blog.csdn.net/ccwwff/article/details/6158788 http://x-slam.com/tag/filp_close http://www.360doc.com/content/09/0415/21/26398_3145185.shtml
0x2: 对文件读写操作的权限进行精细化控制
读写权限精确控制:对sys_open的保护进行精细化处理,去除所有调用请求的写权限,保留原始的其他权限
因为如果我们只是简单的禁止一切对/proc/pid/mem、/proc/pid/task/pid/mem、/dev/mem的sys_open请求,可能会造成对合法"读请求"的误杀,而实际上我们要做的只是禁止对这些文件的写请求
flags = (flags & ( ~ ( O_WRONLY | O_RDWR | O_TRUNC | O_APPEND))) | O_RDONLY;
打印sys_open的flag的相关的参数的代码可以这样写
#include#include #include #include main() { printf("O_RDONLY:%d\n", O_RDONLY); printf("O_WRONLY:%d\n", O_WRONLY); printf("O_RDWR:%d\n", O_RDWR); printf("O_TRUNC:%d\n", O_TRUNC); printf("O_APPEND:%d\n", O_APPEND); }

Relevant Link:
http://insidethekernel.blogspot.com/2005/02/sysopen-implementation-details.html http://man7.org/linux/man-pages/man2/open.2.html http://books.msspace.net/mirrorbooks/networksecuritytools/0596007949/networkst-CHP-7-SECT-2.html
17. Protect Protect-Module Itself
对于保护驱动模块本身,我们需要采取技术手段对其进行保护
0x1: 禁止非法用户卸载保护驱动
对delete_module进行hook,禁止用户非法卸载保护驱动
0x2: 从lsmod命令中隐藏我们的模块
lsmod命令是通过/proc/modules来获取当前系统模块信息的。而/proc/modules中的当前系统模块信息是内核利用struct modules结构体的表头遍历内核模块链表、从所有模块的struct module结构体中获取模块的相关信息来得到的。结构体struct module在内核中代表一个内核模块
list_del_init(&__this_module.list);
0x3: 从sysfs中隐藏我们的模块
使用断链法,对驱动模块进行隐藏
http://www.cnblogs.com/LittleHann/p/3879961.html 搜索: 4. 基于断链法的内核模块隐藏技术
Relevant Link:
http://www.freebuf.com/articles/system/54263.html
18. Improve Point
0x1: 保护模块通用性
要做到通用型的进程保护模块,即protect.ko应该是一个目标进程独立的保护模块,受保护进程不需要进行额外的修改就可以享受到保护模块的保护
在内核态的保护模块protect.ko中开放一个Ring0-Ring3通信接口,允许由Ring3传入"受保护进程元数据"
1. Protect PID、 2. Protect Process Name
针对PID、进程名进行进程保护
0x2: 建立可信通道
进程保护需要考虑的一个很重要的问题是,除了防止黑客去KILL受保护目标进程,还要能够透明地接入原本的业务流程,让原始可信的管理员(或者控制服务端)能够通过一个"受信任通道"的方式去"合法"地杀死进程
1. 基于进程间通信+简单加密防重放验证,在受保护进程中增加一个进程间通信接口,当收到指定的"KILL信号"的时候,在程序逻辑内部调用exit()自杀 2. 对于可信KILL指令通道的设计,可以考虑在kill(int pid, int sig)的sig参数中,设计一个加密过的特别参数,用于指定这个kill请求是合法的,不过这种方法存在被破解的可能 3. 基于系统调用发起方的"进程绝对路径",例如,如果是"/usr/local/trust/trust_process"发起的kill()系统调用,则予以放行,获取进程绝对路径的方法请参阅另一篇文章 http://www.cnblogs.com/LittleHann/p/3927316.html 4. 在保护模块内部建立一个状态标示量(int state) 1) 默认初始值为false,表示目前处于"保护状态" 2) 对sys_open进行Hook监控,当发现当前正在打开一个特定名称的文件时候(例如"secrect.txt"),表明现在是"原始可信管理员"在进行可信操作,则将state状态量设置为true,表明当前处于"非保护状态",保护模块对操作放行 5. 参考rootkit的自我隐藏技术 1) 在/proc下新建一个新节点: rt 2) 劫持/proc的读写操作句柄,对rt节点进行隐藏 3) 在/proc/rt节点的写操作函数中对输入进行判断,如果检测到一个预定的"secrect"(例如"marry Christmas"),则表明可信管理员希望卸载保护模块或者系统kill目标进程 http://www.cnblogs.com/LittleHann/p/3879961.html 搜索:"6. Sample Rootkit for Linux"
0x3: 对磁盘文件的保护
进程保护是一个全方位的概念,除了内存中的Runing Process,还需要考虑到对磁盘文件的保护
1. 进程在磁盘上的文件,保护不被非法用户删除 2. 很多程序会将运行中的"临时文件"、"缓存文件"保存在磁盘上,并且强依赖这些磁盘上的文件,如果磁盘上的对应依赖文件遭到破坏会直接导致进程退出 3. 在内核底层直接对sys_open、sys_write、sys_read等系统调用Hook 4. 在Linux VFS层对文件的读写操作进行审计
0x4: 建立边界防御
采取边界防御的思想,我们的防御保护模块运行在系统的Ring0层,我们就需要最大限度的防止非法用户也进入Ring0层加载攻击驱动
1. 对init_module驱动加载的入口系统调用进行监控、审计禁止非法用户加载驱动 2. 建立白名单,只允许合法的可信进程加载驱动
0x5: 建立白名单机制
1. 允许指定可信进程对受保护路径进行文件读写 2. 允许指定可信进程加载、卸载驱动 3. 允许指定可信进程kill受保护进程
19. SourceCode
需要Replace Hook的对象
1. sys_kill: 禁止非法用户向目标进程发送信号 http://lxr.oss.org.cn/source/kernel/signal.c /source/kernel/signal.c int kill(pid_t pid, int sig); 判断发送系统调用的"发起进程",只允许白名单中可信的进程向受保护进程发送"信号"(我们要假设目标受保护进程没有设立对应的信号捕获机制) 1) 判断发起系统调用的进程的pid、进程名(只允许白名单) 2. sys_delete_module: 禁止非法用户卸载保护驱动 http://lxr.oss.org.cn/source/kernel/module.c /source/kernel/module.c int delete_module(const char *name, int flags); 判断发送系统调用的"发起进程",只允许白名单中可信的进程卸载我们的保护模块 1) 判断发起系统调用的进程的pid、进程名(只允许白名单) 2) 判断传入的待卸载的驱动的名字(保护自己) 3. sys_ptrace: 禁止非法用户去附加调试目标程序 http://lxr.oss.org.cn/source/kernel/ptrace.c#L1183 long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data); 1) 判断发起系统调用的进程的pid、进程名(只允许白名单) 2) 判断待调试挂载ptrace的目标进程pid、进程名(禁止目标受保护进程被调试 4. sys_process_vm_writev: 禁止非法用户向目标进程的虚拟内存中写入数据 http://lxr.oss.org.cn/source/include/linux/syscalls.h#L840 long sys_process_vm_writev(pid_t pid, const struct iovec __user *lvec, unsigned long liovcnt, const struct iovec __user *rvec, unsigned long riovcnt, unsigned long flags); 1) 判断传入的待写入进程的pid、进程名(保护目标进程不被跨进程内存读写破坏) 5. sys_open http://lxr.free-electrons.com/source/fs/open.c#L1036 long sys_open(const char *filename, int flags, int mode); 1) 针对进程内存破坏进行防御 1.1) /proc/pid/mem 1.2) /proc/pid/task/pid/mem 1.3) /dev/mem 2) 实现精细化读写权限控制,如果匹配到受保护目录,则将本次调用请求的写权限去掉,使调用者无法进行实际地写操作 6. sys_init_module http://lxr.free-electrons.com/source/kernel/module.c long sys_init_module(init_module, void __user *, umod, unsigned long, len, const char __user *, uargs) 1) 保护驱动加载后,建立防御边界,禁止非法进程再去加载新的驱动,将攻击者挡在Ring3层
code
#include#include #include #include #include #include #include // loops_per_jiffy #include #include string.h> #include #include #include //for O_RDONLY #include //for PATH_MAX #include #include #include #include #define CR0_WP 0x00010000 // Write Protect Bit (CR0:16) #define BUF_SIZE 1024 /* Just so we do not taint the kernel */ MODULE_LICENSE("GPL"); void **syscall_table; unsigned long **find_sys_call_table(void); long (*orig_sys_kill)(int pid, int sig); long (*orig_sys_delete_module)(const char *name, unsigned int flags); long (*orig_sys_ptrace)(long request, long pid, unsigned long addr, unsigned long data); long (*orig_sys_process_vm_writev)(pid_t pid, const struct iovec __user *lvec, unsigned long liovcnt, const struct iovec __user *rvec, unsigned long riovcnt, unsigned long flags); long (*orig_sys_open)(const char __user *filename, int flags, int mode); long (*orig_sys_init_module)(void __user * umod, unsigned long len, const char __user * uargs); unsigned long **find_sys_call_table() { unsigned long ptr; unsigned long *p; for (ptr = (unsigned long)sys_close; ptr < (unsigned long)&loops_per_jiffy; ptr += sizeof(void *)) { p = (unsigned long *)ptr; if (p[__NR_close] == (unsigned long)sys_close) { printk(KERN_DEBUG "Found the sys_call_table!!!\n"); return (unsigned long **)p; } } return NULL; } char* getNameByPid( pid_t pid ) { struct task_struct * task = NULL, * p = NULL; struct list_head * pos = NULL; char *callProcess; task = & init_task; list_for_each( pos, &task->tasks ) { p = list_entry( pos, struct task_struct, tasks ) ; //printk( KERN_ALERT "%d/t%s/n" , p->pid, p->comm ) ; if (p->pid == pid) { callProcess = p->comm; } } return callProcess; } int getPidByName( char* processName ) { struct task_struct * task = NULL, * p = NULL; struct list_head * pos = NULL; int callPid = 1; task = & init_task; list_for_each( pos, &task->tasks ) { p = list_entry( pos, struct task_struct, tasks ) ; //printk( KERN_ALERT "%d/t%s/n" , p->pid, p->comm ) ; if ( (strcmp(processName, p->comm) == 0) ) { callPid = p->pid; } } return callPid; } /* 根据task_struct、fd(文件描述符)获取当前工作路径 */ char* getfullpath(struct task_struct *mytask, int fd) { struct file *myfile = NULL; struct files_struct *files = NULL; char path[100] = {'\0'}; char *ppath = path; files = mytask->files; if (!files) { printk("files is null..\n"); goto OUT; } myfile = files->fdt->fd[fd]; if (!myfile) { printk("myfile is null..\n"); goto OUT; } ppath = d_path(&(myfile->f_path), ppath, 100); OUT: return ppath; } unsigned long getInodeIDbyFilename(const char *filename) { unsigned long proc_ino = 0; struct file *filp = filp_open(filename, O_RDONLY, 0); if( !IS_ERR(filp) ) { proc_ino = filp->f_dentry->d_inode->i_ino; filp_close(filp, 0); } else { proc_ino = 0; } return proc_ino; } long my_sys_init_module(void __user * umod, unsigned long len, const char __user * uargs) { long ret; //禁止加载驱动 ret = -1; return ret; } long my_sys_open(const char __user *filename, int flags, int mode) { long ret; unsigned long proc_mem_ino; unsigned long proc_maps_ino; unsigned long task_mem_ino; unsigned long task_maps_ino; unsigned long dev_mem_ino; unsigned long current_proc_ino; //获取指定进程的PID,默认为1:init进程 int pid = getPidByName("killme"); char proc_mem[512] = {0}; char proc_maps[512] = {0}; char task_mem[512] = {0}; char task_maps[512] = {0}; char dev_mem[512] = {0}; char buffer_filename[512] = {0}; //将用户态的filename拷贝到内核态,防止出现panic copy_from_user((char *)buffer_filename, filename, 512); //设置要修复的目标受保护路径 sprintf(proc_mem, "/proc/%d/mem", pid); sprintf(proc_maps, "/proc/%d/maps", pid); sprintf(task_mem, "/proc/%d/task/%d/mem", pid); sprintf(task_maps, "/proc/%d/task/%d/maps", pid); sprintf(dev_mem, "/dev/mem"); //获取指定路径的inode id proc_mem_ino = getInodeIDbyFilename(proc_mem); proc_maps_ino = getInodeIDbyFilename(proc_maps); task_mem_ino = getInodeIDbyFilename(task_mem); task_maps_ino = getInodeIDbyFilename(task_maps); dev_mem_ino = getInodeIDbyFilename(dev_mem); current_proc_ino = getInodeIDbyFilename(buffer_filename); //路径保护判断策略 if ( (current_proc_ino == proc_mem_ino) || (current_proc_ino == proc_maps_ino) || (current_proc_ino == task_mem_ino) || (current_proc_ino == task_maps_ino) || (current_proc_ino == dev_mem_ino) ) { flags = (flags & ( ~ ( O_WRONLY | O_RDWR | O_TRUNC | O_APPEND))) | O_RDONLY; ret = orig_sys_open(filename, flags, mode); } else { ret = orig_sys_open(filename, flags, mode); } return ret; } long my_sys_kill(int pid, int sig) { long ret; char *callProcess; char *destinationProcess; //获取系统调用发起者的进程名 callProcess = current->comm; //获取kill指令的目标进程名 destinationProcess = getNameByPid(pid); //禁止"受保护进程"被KILL if ( (strcmp(destinationProcess, "killme") == 0) ) { //相同,禁止执行,返回值:-1 ret = -1; } else { //不相同,放行继续执行 ret = orig_sys_kill(pid, sig); } return ret; } long my_sys_delete_module(const char *name, unsigned int flags) { long ret; if ( (strcmp(name, "driverp") == 0) ) { //相同,禁止执行,返回值:-1 ret = -1; } else { //不相同,放行继续执行 ret = orig_sys_delete_module(name, flags); } return ret; } long my_sys_ptrace(long request, long pid, unsigned long addr, unsigned long data) { long ret; char *destinationProcess; //获取目标进程名 destinationProcess = getNameByPid(pid); //禁止"受保护进程"被KILL if ( (strcmp(destinationProcess, "killme") == 0) ) { //相同,禁止执行,返回值:-1 ret = -1; } else { //不相同,放行继续执行 ret = orig_sys_ptrace(request, pid, addr, data); } return ret; } long my_sys_process_vm_writev(pid_t pid, const struct iovec __user *lvec, unsigned long liovcnt, const struct iovec __user *rvec, unsigned long riovcnt, unsigned long flags) { long ret; char *destinationProcess; //获取目标进程名 destinationProcess = getNameByPid(pid); //禁止"受保护进程"被KILL if ( (strcmp(destinationProcess, "killme") == 0) ) { //相同,禁止执行,返回值:-1 ret = -1; } else { //不相同,放行继续执行 ret = orig_sys_process_vm_writev(pid, lvec, liovcnt, rvec, riovcnt, flags); } return ret; } static int __init syscall_init(void) { int ret; unsigned long addr; unsigned long cr0; syscall_table = (void **)find_sys_call_table(); if (!syscall_table) { printk(KERN_DEBUG "Cannot find the system call address\n"); return -1; } cr0 = read_cr0(); write_cr0(cr0 & ~CR0_WP); //将syscall_table附近的3个内存页(page)的内存页面的读写权限打开, addr = (unsigned long)syscall_table; ret = set_memory_rw(PAGE_ALIGN(addr) - PAGE_SIZE, 3); if(ret) { printk(KERN_DEBUG "Cannot set the memory to rw (%d) at addr %16lX\n", ret, PAGE_ALIGN(addr) - PAGE_SIZE); } else { printk(KERN_DEBUG "3 pages set to rw"); } orig_sys_kill = syscall_table[__NR_kill]; orig_sys_delete_module = syscall_table[__NR_delete_module]; orig_sys_ptrace = syscall_table[__NR_ptrace]; orig_sys_process_vm_writev = syscall_table[__NR_process_vm_writev]; orig_sys_init_module = syscall_table[__NR_init_module]; orig_sys_open = syscall_table[__NR_open]; syscall_table[__NR_kill] = my_sys_kill; syscall_table[__NR_delete_module] = my_sys_delete_module; syscall_table[__NR_ptrace] = my_sys_ptrace; syscall_table[__NR_process_vm_writev] = my_sys_process_vm_writev; syscall_table[__NR_init_module] = my_sys_init_module; syscall_table[__NR_open] = my_sys_open; write_cr0(cr0); return 0; } static void __exit syscall_release(void) { unsigned long cr0; cr0 = read_cr0(); write_cr0(cr0 & ~CR0_WP); syscall_table[__NR_kill] = orig_sys_kill; syscall_table[__NR_delete_module] = orig_sys_delete_module; syscall_table[__NR_ptrace] = orig_sys_ptrace; syscall_table[__NR_process_vm_writev] = orig_sys_process_vm_writev; syscall_table[__NR_init_module] = orig_sys_init_module; syscall_table[__NR_open] = orig_sys_open; write_cr0(cr0); } module_init(syscall_init); module_exit(syscall_release);
需要注意的是,sys_kill的禁用需要对init进程开放白名单,因为reboot的时候,init进程会向当前进程列表发送kill信号,如果被禁用,将导致无法reboot
Copyright (c) 2014 LittleHann All rights reserved