异步 IO
关于异步的一些基本了解请 参考这篇文章, 或者 简书的转载文章 https://www.jianshu.com/p/fe146f9781d2
1. Linux 中的五种 IO 模型
内核态和用户态
由于需要限制不同的程序之间的访问能力,防止他们获取别的程序的内存数据,或者获取外围设备的数据,操作系统划分出两个权限等级:用户态和内核态。
内核态:当一个任务(进程)执行系统调用而陷入内核代码中执行时,称进程处于内核运行态(内核态)。
用户态:当进程在执行用户自己的代码时,则称其处于用户运行态(用户态)。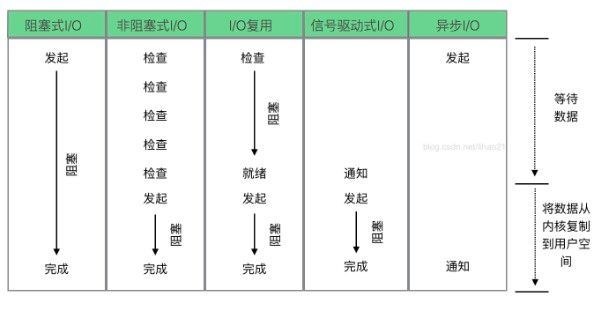
五种 IO 模型中, IO 复用的技术较为成熟,因此使用也比较广泛。而最为理想的是异步 IO,整个过程没有阻塞,而且有通知。2. IO 多路复用
IO 多路复用模型有三种:select poll epoll,它们的性能是层层递增。
2.1 select
sokect 是通过一个 select() 系统调用来监视多个文件描述符,当 select() 返回后,该数组中就绪的文件描述符便会被该内核修改标志位,使得进程可以获得这些文件描述符从而进行后续的读写操作。
select 的优点是支持跨平台,缺点在于单个进程能够监视的文件描述符的数量存在最大限制。
另外 select() 所维护的存储大量文件描述符的数据结构,随着文件描述符数量的增大,其复制的开销也线性增长。同时,由于网络响应时间的延迟使得大量 TCP 连接处于非活跃状态,但调用 select() 会对所有 socket 进行一次线性扫描,所以这也浪费了一定的开销。文件描述符 fd
文件描述符是一个用于表述指向文件的引用的抽象化概念。
文件描述符在形式上是一个非负整数,实际上,它是一个索引值,指内核为每一个进程所维护的进程打开文件的记录的记录表,当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。2.2 poll
poll 和 select 在本质上没有多大差别,但是 poll 没有最大文件描述符数量的限制。
poll 和 select 存在同样一个缺点就是,包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大。
另外,select() 和 poll() 将就绪的文件描述符告诉进程后,如果进程没有对其进行 IO 操作,那么下次调用 select() 和 poll() 的时候将再次报告这些文件描述符,所以它们一般不会丢失就绪的消息,这种方式称为水平触发(Level Triggered)。2.3 epoll
epoll 可以同时支持水平触发和边缘触发(Edge Triggered,只告诉进程哪些文件描述符刚刚变为就绪状态,它只说一遍,如果我们没有采取行动,那么它将不会再次告知,这种方式称为边缘触发),理论上,边缘触发的性能要更高一些,但是代码实现相当复杂。
epoll 同样只告知那些就绪的文件描述符,而且当我们调用 epoll_wait() 获得就绪文件描述符时,返回的不是实际的描述符,而是一个代表就绪描述符数量的值,你只需要去 epoll 指定的一个数组中依次取得相应数量的文件描述符即可,这里也使用了内存映射(mmap)技术,这样便彻底省掉了这些文件描述符在系统调用时复制的开销。
另一个本质的改进在于 epoll 采用基于事件的就绪通知方式。在 select/poll 中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而 epoll 事先通过 epoll_ctl() 来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似 callback 的回调机制,迅速激活这个文件描述符,当进程调用 epoll_wait() 时便得到通知。2.4 select 实例
import socket
from selectors import EVENT_READ, EVENT_WRITE, DefaultSelector
from urllib.parse import urlparse
# DefaultSelector 会根据平台自动选择 select/poll/epoll
selector = DefaultSelector()
urls = ["https://www.baidu.com"] # 请求的 url 列表
stop = False # 停止 loop() 的标志
class Fetcher():
# 连接回调函数
def connected(self, key):
selector.unregister(key.fd)
smsg = "GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(self.path, self.host).encode('utf-8')
self.client.send(smsg)
selector.register(self.client.fileno(), EVENT_READ, self.readable)
# 可读回调函数
def readable(self, key):
d = self.client.recv(1024)
if d:
self.data += d
else:
selector.unregister(key.fd)
data = self.data.decode('utf-8')
html_data = data.split("\r\n\r\n")[1]
print(html_data)
self.client.close()
urls.remove(self.spider_url)
if not urls:
global stop
stop = True # 请求完成标志
def get_url(self, url):
self.data = b""
self.spider_url = url
# 请求 html
url = urlparse(url)
self.host = url.netloc
self.path = url.path
if self.path == "":
self.path = "/"
# 建立 socket
self.client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.client.setblocking(False) # 设置为非阻塞
try:
self.client.connect((self.host, 80))
except BlockingIOError:
pass
# 将 socket 注册到 selector,send 相当于写 EVENT_WRITE
selector.register(self.client.fileno(), EVENT_WRITE, self.connected)
def loop():
# 事件循环, 不停的请求 socket 的状态并调用对应的回调函数
# 1. select 本身是不支持 register 模式的
# 2. socket 状态变化以后的回调应该由程序员完成
while not stop:
ready = selector.select()
for key, mask in ready:
call_back = key.data
call_back(key)
# 回调 + 事件循环 + select
if __name__ == "__main__":
fetcher = Fetcher()
fetcher.get_url(urls[0])
loop()3. asyncio 模块
asyncio 被用作多个提供高性能 Python 异步框架的基础,包括网络和网站服务,数据库连接库,分布式任务队列等等。
asyncio 往往是构建 IO 密集型和高层级结构化网络代码的最佳选择。
3.1 wait 方法
import asyncio
import time
async def foo(arg):
print("start...", arg)
# 使用异步阻塞,不能使用同步阻塞,否则会变成同步的程序
await asyncio.sleep(2)
print("end...", arg)
return "arg"+str(arg)
if __name__ == "__main__":
start_time = time.time()
loop = asyncio.get_event_loop() # 获取一个异步事件循环
tasks = [foo(i) for i in range(1, 4)] # 定义三个任务
# 异步执行多任务,wait 返回的是一个协程
# run_until_complete 会在循环结束之后停止 loop,区别于 run_forever 方法
loop.run_until_complete(asyncio.wait(tasks))
print(time.time() - start_time) # 输出程序耗时执行结果
start... 2
start... 3
start... 1
end... 2
end... 3
end... 1
2.0156099796295166从任务的执行顺序和时间不难看出,这是一个并发程序
3.2 gather 方法
import asyncio
async def foo(n):
print(n)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
group1 = [foo(i) for i in range(2)]
group2 = [foo(i) for i in range(2, 4)]
# 注意这里传参要使用 * 号,
# 该方法通过普通收集参数接收任务, 会将所传的参数都装入一个元组中, 所以要使用 * 号
group1 = asyncio.gather(*group1)
group2 = asyncio.gather(*group2)
# group2.cancel() # 取消任务
# gather 返回的是一个 future, 比 wait 方法更高级
loop.run_until_complete(asyncio.gather(group1, group2))
# python 3.7 及其之后, 可以直接使用 asyncio.run() 来执行异步
async def main():
group1 = [foo(i) for i in range(2)]
group2 = [foo(i) for i in range(2, 4)]
# 注意这里传参要使用 * 号
group1 = asyncio.gather(*group1)
group2 = asyncio.gather(*group2)
asyncio.run(main())4. aiohttp
待写