文本挖掘概要
搞什么的?
- 从大量文本数据中,抽取出有价值的知识,并且利用这些知识更好的组织信息的过程。
目的是什么?
- 把文本信息转化为人们可利用的知识。
举例来说,下面的图表利用文本挖掘技术对库克iphoneX 发布会的内容进行分析,得出此次发布会报告中的几个常青词汇、词频的趋势变化情况。
(一)语料库(Corpus)
在python中,如何根据以往的文档文件搭建一个语料库?
1.什么是语料库
语料库是我们要分析的所有文档的集合。
在日常工作中我们对文章的管理,先是一篇篇的文章不断的积累,我们存了大量的文章之后,会对文章信息进行一些归类的工作,一般体现于建立不同的文件夹来保存不同类别的文章。
同样的,我们把我们需要分析的文本文件,读取内存变量中,然后在内存变量中使用不同的数据结构,对这些文本文件进行存储,以便进行下一步的分析。
这个内存变量就是语料库
2.语料库构建实操
我们通过一个案例来了解语料库构建的过程。
这里,jacky为了分享,整理了一份iphone8发布后,主流新闻网站评论的语料数据。 

我存放iphone 语义文件夹的路
file:///Users/apple/Downloads/Iphone8
如果是windows系统要替换成响应的路径。
1) 如何把语料数据作为语料库导入到内存中
# -*- coding:utf-8 -*-
import os
import os.path
import codecs
filePaths=[]
fileContents=[]
for root,dirs,files in os.walk('Users/apple/Documents/Iphone8'):
for name in files:
filePath=os.path.join(root,name)
filePaths.append(filePath)
f=codecs.open(filePath,'r','utf-8')
fileContent=f.read()
f.close()
fileContents.append(fileContent)
import pandas
corpos=pandas.DataFrame({
'filePath':filePaths,
'fileContent':fileContents
})上述代码注解:
把一个文件夹中,包括嵌套文件夹的全路径,读入到一个内存变量中,我们定义为filePaths数组变量,接着使用os中walk方法,传入这个目录作为参数,就可以遍历该文件中的所有文件了
for root,dirs,files in os.walk中root为文件目录,dirs为root目录下的所有子目录,root目录下的所有文件,我们命名为files,然后进行遍历。
为了拿到root目录下的所有文件,我们再次便利所有的文件(代码:for name in files:)把它追加到filePaths变量中去即可。
os.path.join是拼接文件路径的方法,因为文件路径在windows,mac,linux中的写法是不同的,使用这个方法可以解决在不同系统中使用文件路径要使用不同方法的问题。
最后组建数据框pandas.DataFrame
我们可以print(corpos) 
(二)中文分词(Chinese Word Segmentation)
1.中文分词
英文中单词是以空格作为自然分界符,而中文只是字句和段,能够通过明显的分界符简单化简,唯独词没有一个明显的分界符
将一个汉字序列切分成一个一个单独的词
- 我是数据分析部落的发起人 —-> 我/是/数据/分析/部落/的/发起人(@数据分析-jacky)
2.停用词(Stop Words)
对文章进行分词后,会产生大量的分词,这些分词中并不是每个词都有用的,在我们进行数据处理时,要过滤掉某些字或词
泛滥的词:如web,网站等;
语气助词、副词、介词、连接词等:如的、地、得
3.分词模块-jieba分词包
分词包有很多,jieba分词包是效率高,最简单的分词包
1)jieba基本使用方法-cut方法
import jieba
for w in jieba.cut('我是数据分析-jacky'):
print(w)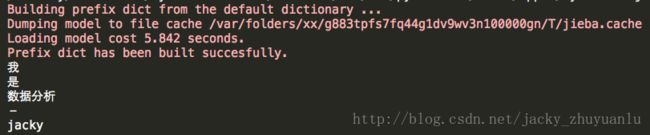
下面是“分词届”最奇葩,也是最津津乐道的分词难题:
工信处女干事
每月经过下属科室都要亲口交代
24口交换机等技术性器件的安装工作
import jieba
for w in jieba.cut('''
工信处女干事
每月经过下属科室都要亲口交代
24口交换机等技术性器件的安装工作
'''):
print(w)
jieba在没有使用自定义分词的情况下,只使用默认词库,效果还是非常好的。
2)导入词库
虽然jieba包已经有默认词库,一般场景使用不会出现什么问题,但是我们要是把分词的功能用于专业的场景,会出现什么状况呢?
# -*- coding:utf-8 -*-
import jieba
seg_list = jieba.cut('天马流星拳和庐山升龙霸哪个更牛逼呢?')
for w in seg_list:
print(w)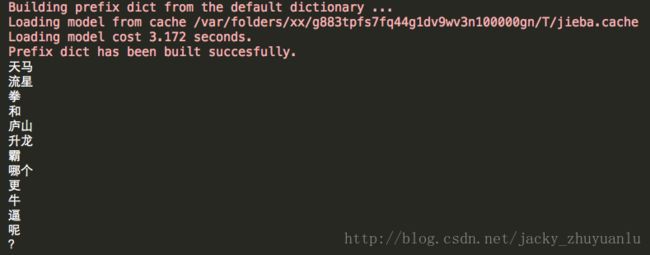
import jieba
jieba.add_word('天马流星拳')
jieba.add_word('庐山升龙霸')
jieba.add_word('牛逼')
seg_list = jieba.cut('天马流星拳和庐山升龙霸哪个更牛逼呢?')
for w in seg_list:
print(w)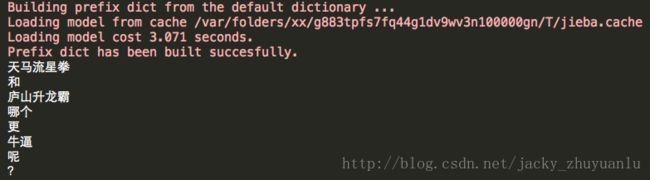
- 我们增加了自定义分词,明显增加了分词效果
- 但是我们要处理的分词很多,使用一个个导入的方法就显得非常不高效了,我们可以使用load_userdict方法一次导入用户自定义词库中
jieba.load_userdict('路径/圣斗士招数.txt')掌握了对单个字符串进行分词后,我们就可以对大量的文字进行分词了,用load_userdict一次性导入自定义词库中
3) 与语料库结合的实操案例
# -*- coding:utf-8 -*-
#搭建预料库
import os
import os.path
import codecs
filePaths=[]
fileContents=[]
for root,dirs,files in os.walk('Iphone8'):
for name in files:
filePath=os.path.join(root,name)
filePaths.append(filePath)
f=codecs.open(filePath,'r','GB2312')
fileContent=f.read()
f.close()
fileContents.append(fileContent)
import pandas
corpos=pandas.DataFrame({
'filePath':filePaths,
'fileContent':fileContents
})
#每个分词后面都要跟着一个信息,那就是这个分词来源是哪篇文章
#因此,我们的结果除了分词,还需要指明分词的出处,以便进行后续的分析
import jieba
segments=[]
filePaths=[]
#接下来,遍历所有文章,使用数据框的方法,我们获取到语料库的每行数据,这样遍历得到的行是一个字典,
#列名index作为key,于是我们可以通过列名,使用字典的值的获取方法,获取到文件路径filePath,和文件内容fileContent
for index,row in corpos.iterrows():
filePath=row['filePath']
fileContent=row['fileContent']
#接着调用cut方法,对文件内容进行分词
segs=jieba.cut(fileContent)
#接着遍历每个分词,和分词对应的文件路径一起,把它加到两列中
for seg in segs:
segments.append(seg)
filePaths.append(filePath)
#最后我们把得到的结果存在一个数据框中
segmentDataFrame=pandas.DataFrame({
'segment':segments,
'filePath':filePaths
})
print(segmentDataFrame)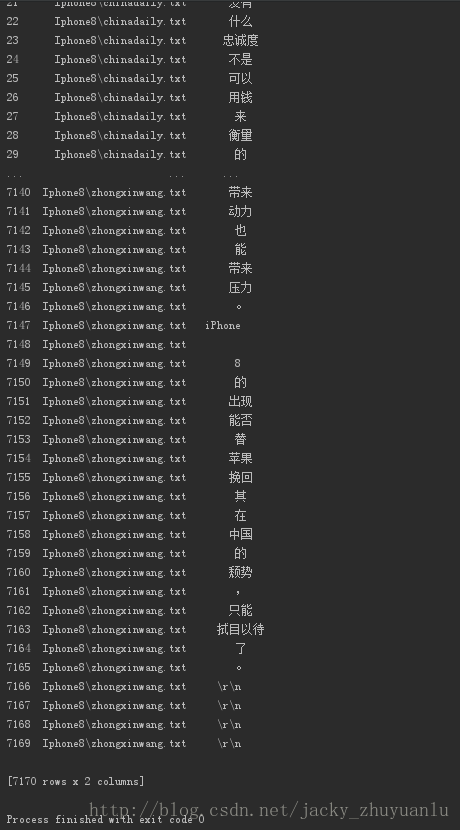
(三)文本挖掘的入口-词频统计
1.词频
某个词在该文档中出现的次数
用词频这个指标来做应用的时候,并不会给定特定的词,而是计算机先对文章进行分词,然后对所得到的所有分词进行词频统计,然后看看哪些词在文章中经常出现。
2.如何使用Python进行词频统计
接着说上面Iphone8发布会语料库的案例,我们已经把语料库搭建好,对语料库进行了分词,上面的案例我们得到了一列为分词(segment),一列为分词所属文件(filePath)的数据框,接下来我们进行词频统计就非常简单了
我们使用分组统计函数,直接在分词变量数据框后调用groupby方法,使用分词字段进行分组,然后聚合函数使用numpy.size函数,也就是对分组字段做一个计数,最后重新设定索引[‘segment’],在根据计算进行倒序排列,得到的结果就是我们词频统计的结果了
import numpy
#进行词频统计
segStat=segmentDataFrame.groupby(
by='segment'
)['segment'].agg({'计数':numpy.size}).reset_index().sort(
columns=['计数'],
ascending=False
)- 这里要特别注意的是:降序计数调用的方法sort函数,需要新版本的pandas库,懒得升新版本不降序也不影响后续的处理,这里小伙伴们可以自己处理。
接下来就是过滤停用词:
#首先判断分词列里面是否包含这些停用词
stopwords=pandas.read_csv(
"路径.txt",
encoding='utf-8',
index_col=False
)
#用isin方法,包含停用词就过滤词,用~符号取反
fSegStat=segStat[
~segStat.segment.isin(stopwords.stopword)
](四)生词词云
#导入WordCloud和matplotlib包
from wordcloud import WordCloud
import matplotlib.pyplot as plt
#生成一个matplot对象,传入一个字体位置的路径和背景颜色即可
wordcloud=WordCloud(
font_path='字体路径\simhei.ttf',
background_color='black'
)
#WordCloud方法接受一个字典结构的输入,我们前面整理出来的词频统计结果是数据框的形式,因此需要转换,转换的方法,首先把分词设置为数据框的索引,然后在调用一个to_dict()的方法,就可以转换为字典的机构
words=fSegStat.set_index('segment').to_dict()
#接着调用fit_words方法来调用我们的词频
wordcloud.fit_words(words['计数'])
#绘图
plt.imshow(wordcloud)
plt.close()(五)完整案例代码展示
# -*- coding:utf-8 -*-
import os
import os.path
import codecs
filePaths=[]
fileContents=[]
for root,dirs,files in os.walk('Users/apple/Documents/Iphone8'):
for name in files:
filePath=os.path.join(root,name)
filePaths.append(filePath)
f=codecs.open(filePath,'r','utf-8')
fileContent=f.read()
f.close()
fileContents.append(fileContent)
import pandas
corpos=pandas.DataFrame({
'filePath':filePaths,
'fileContent':fileContents
})
import jieba
segments=[]
filePaths=[]
for index,row in corpos.iterrows():
filePath=row['filePath']
fileContent=row['fileContent']
segs=jieba.cut(fileContent)
for seg in segs:
segments.append(seg)
filePaths.append(filePath)
segmentDataFrame=pandas.DataFrame({
'segment':segments,
'filePath':filePaths
})
import numpy
segStat=segmentDataFrame.groupby(
by='segment'
)['segment'].agg({'计数':numpy.size}).reset_index().sort(
columns=['计数'],
ascending=False
)
stopwords=pandas.read_csv(
"路径.txt",
encoding='utf-8',
index_col=False
)
fSegStat=segStat[
~segStat.segment.isin(stopwords.stopword)
]
from wordcloud import WordCloud
import matplotlib.pyplot as plt
wordcloud=WordCloud(
font_path='字体路径\simhei.ttf',
background_color='black'
)
words=fSegStat.set_index('segment').to_dict()
wordcloud.fit_words(words['计数'])
plt.imshow(wordcloud)
plt.close()最后,我们来看看效果吧 