行人重识别综述
一般来说,行人重识别属于各种ID识别方法的一个子类。我们姑且将ID识别定义为通过可测量的人类生物特征对人们ID进行鉴别的一种技术。一般而言,我们会使用传感器或者摄像头等来读取生物的特征信息,将读取的信息和用户在数据库中的特征信息比对,来鉴别人物的ID。生物特征分为身体特征和行为特征。身体特征包括指纹、掌型、视网膜、虹膜、人体气味、脸型、手的血管和DNA等;行为特征包括签名、语音、行走步态等。ID识别有两方面的作用,一是作用于门禁、支付等身份认证系统,另一个是作用于监控系统。在身份认真领域,我们可以使用指纹识别、人脸识别等技术;在监控领域,一种常用的方式是人脸识别。但是在很多情况下,由于监控摄像头清晰度的问题,我们很难获得清晰的人脸图,这个时候利用人体全身图的特征进行ID分析可能是更好的选择,这就是所谓的行人重识别。行人重识别与人脸识别十分相似,都是为了解决ID识别问题,不同的是人脸识别主要分析人脸图片,而行人重识别则是分析人的全身图。目前学术界做行人重识别的人,很多都是做人脸识别的那波人转过来的,因为好发论文。
行人重识别问题定义
本文将行人重识别一般问题表述如下:给定一个我们关心的人物的全身图片(query),通过某些算法,从行人全身图数据库(gallery)中找出与该人最为接近的一张或几张图片。
上述过程又可以划分为两种方案。第一种情况是,随机给定两个人的图片,将这两张图片作为系统输入,我们希望系统输出一个概率值,表示两张图属于同一个ID的概率,这就归结为一个二分类问题。但是这种方案的问题在于,阈值不好设定。目前主流的方案中,还是将行人重识别过程当作一个检索(retrieval)问题,系统一般会将query在与gallery中的图集逐一对比,然后进行相似度排名,返回一个candidate list。基于检索的行人识别方案带来的问题是,运算复杂度随着gallery集增加而增大,而且不好做成实时系统。
基于图片的行人重识别问题
如果我们的query集和gallery集的数据单位都是单帧的图片,这就属于基于图片(image-based)的行人重识别问题。由于行人重识别问题还存在很多技术问题有待研究,因此大家一般会将目标检测和重识别放在两个框架下来做,也就是说query集和gallery集都是经过detector裁剪好的行人框,我们只需专注于重识别问题即可。当然也有人用摄像头采集的原始图片直接作为gallery集,将原图行人检测问题+重识别问题放在一起,做成一个end-to-end模型。end-to-end模型的一个典型做法是,将各种detector和recogniser进行随机组合,来观测不同组合的效果。总的来说detector的准确率和效率会影响recogniser的检测结果。
基于视频的行人重识别问题
如果我们的query集和gallery集的数据样本不是单张图,而是一段连续帧的图集,这样图集由于包含了时序信息,系统准确率肯定高于基于图片的重识别方法。目前,已经有一些video-based的行人重识别数据集,比如MARS。当然,凡是涉及到时序相关的深度学习方法,必然涉及到LSTM或者GRU这些时序网络(RNN)。显然,GPU处理起RNN来要比CNN困难许多,效率也更低。
行人重识别论文笔记
A Multi-task Deep Network for Person Re-identification
这篇文章主要做了loss设计和跨数据集训练两方面的工作。
在训练神经网络的过程中,作者采用了多任务的训练方法,即在不同的网络层,设计出不同的损失函数,交叉地训练神经网络。首先,以三张图片(其中两张ID相同)作为输入,在神经网络的第二层卷积层提取图片特征, 以图片特征的距离函数作为损失函数,希望相同ID的图片之间的距离函数取值尽可能大,不同ID图片之间的距离函数值尽可能小;上述损失函数被称作triplet loss。其次,以两张图片作为输入,在神经网络的末端输出二分类信息(即两张图片ID相同的概率),以CE作为损失函数。上述两个过程一般交叉进行。作者对此给出的解释是,图片在浅层神经网络提取的特征一般表现细节信息,所以用距离损失函数来度量两张图片的差异性;而在深层网络的特征一般表现高层语义信息,所以直接用二分类损失函数来训练。
在最近的学术研究中,基于多个损失函数的多任务训练方式被广泛使用,损失函数的设计也各式各样,如center loss,coupled clusters loss,structured loss,quadruplet loss,以及各种改进版本,但是其中真正有意义设计的并不多。
在行人重识别这个领域,单一数据集的规模实在太小了,同时由于不同数据集的数据分布方差过大,因此也不能将这些数据集通通放在一起进行训练。因此作者提出了一种cross domain的架构。将非目标数据集作为辅助训练集,以提升模型在目标数据集上的表现。其思路为:在目标数据集选取一对image pair,提取联合特征Fa,并打上标签label1(0表示两张图同id,1则相反);同时在辅助训练集选取一对image pair,提取联合特征Fb,并打上标签label2;记y=label1 XNOR label2;最后用如下损失函数来微调网络:

除了这片文章的思路,其他的数据增强技术还有GAN方法、非监督性学习、半监督性学习等。
Re-ranking Person Re-identification with k-reciprocal Encoding
这篇文章的主要工作主要放在re-rank上面。这种方法方法显得略微丑陋,给人的感觉是不够“智能”。但是目前来说,re-rank方法的各种变体为大家广泛使用,而且效果很不错。re-rank的核心思路在于:如果给定query A,系统从gallery中找出规模为k的candidate list,其中就包含了B;然后再给定 query B ,系统给出的candidate list返回了A,那么这种情况下,我们是不是应该认为A与B属于同一ID的可能性更高呢?或者说A与B在candidate list中的位置是不是应该提前呢?
论文中给出如下定义:如果B出现在A的candidate中,同时A也出现在了B的candidate 中,那么A和B就互为k-reciprocal neibours(k为candidate list的长度)。这样一来,person-reid的过程可分为两步:首先,根据query A给出相应的candidate list;然后根据candidate list中的元素与query A的reciprocal neibours关系进行re-rank,得到最终的candidate list。
在实际过程中,本文将不同图片之间的reciprocal关系进行了0-1编码,在系统初始化阶段就完成了全部图片的互惠近邻关系计算;也就是说对于一个规模为N的gallery集,每张图需要一个N*1的向量来表示其近邻关系,总共需要维护一个N*N的稀疏矩阵,我们姑且称之为互惠最近邻矩阵。随着时间推移,gallery会添加新的图片,系统则每过一段时间互更新一次矩阵。对于有些新加入gallery的图片,可能没有及时更新其互惠近邻信息,作者则采用Local Query Expansion方法来做近似处理。
SVDNet for Pedestrian Retrieval
这篇文章的工作主要工作在于将SVD应用到了feature工程上面,是一个不错的思路。目前尚不清楚这种方法是否由作者最先提出,但该方法也可能运用于其他任务的神经网络训练中。
在理想状态下,我们总是希望深度学习能自动解决机器学习的特征提取问题,但是现实往往并非如此,数据样本的匮乏,让我们不得不做一些人工干预。
一方面,根据对训练好的网络进行观察,作者发现全连接层的权重向量(weight vectors)之间通常具有很高的相关性。对于高相关性的问题,作者认为有两个可能的原因:1.训练样本不是随机分布的。这个原因在最后一个全连接层尤为明显。因为最后一层中每个神经元的输出表示输入图片与对应的identity之间的相似程度。2.由于训练CNN的过程中缺少将参数向正交化方向学习的限制,因此很可能自然就学习到相关性很高的权重向量。
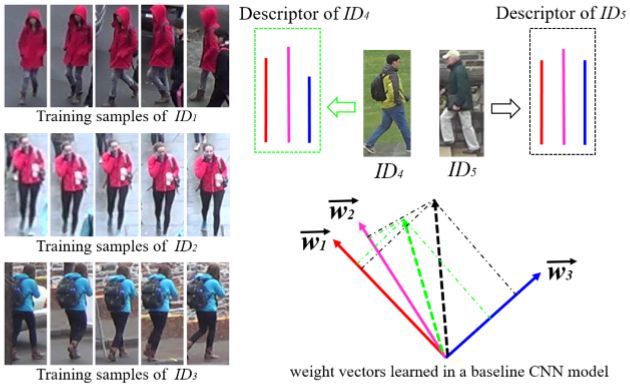
另一方面,使用特征向量的距离函数(如欧式距离等)进行相似性判断时,我们一般要基于一个核心的假设:特征向量之间应该是相互独立的。然而当权重向量之间相关性很高的时候,对应层输出的特征向量的每个分布也具有相关性。从而使得利用欧式距离判断相似性的时候存在误差。如上图所示,两个不同的人经过网络之后得到绿色和黑色的两个特征向量,由于他们投影到红色和粉色weight vector上的距离很近,而投影到蓝色weight vector上的距离较远。在这种情况下,利用欧式距离将有可能忽略蓝色weight vector的影响,从而认为两者是相似的。这是论文作者给出的解释,我认为还是比较有说服力的。
为了去除权重向量之间的相关性,作者提出采用SVD方法来对权重向量进行调整。作者将这个调整过程明名为RRI(Restraint and Relaxation Iteration),其主要步骤如下:
1. Decorrelation:首先基于某个baseline得到pre-trained的网络模型,随后用W_=US替换原有的W,并在网络模型末端加入一个新的网络层,作者称之为Eigenlayer。
2.Restraint:固定Eigenlayer层,对其前面的网络参数进行微调。这个过层主要是对 EigenLayer 层之前的网络参数进行调整。
3.Relaxation:微调整个网络,这一步中EigenLayer层的参数也要进行同步调整。
SVD的分解过程为W=USV‘。作者证明在用W_替代US的情况下, 原来网络的性能不会损失,但是原来已经收敛的网络由于进行了一波降维,变得不再收敛,于是我们又可以愉快地进行训练了。重复上述三步,得到最终的网络模型,作者称之为SVDNet。作者给出的数据声称,在原baseline的基础上,该方法使得模型准确率提高了接近10%。
总结
本文中提到的三篇论文基本上涵盖了person-reid的各个方面(只针对image-based的方法而言),侧重点不尽相同,而且都能一定层度上提升准确率。我们对这些方法进行组合,再添加一些trick,一般就能取得不错的效果。
Zheng L, Yang Y, Hauptmann A G. Person Re-identification: Past, Present and Future[J]. 2016.
Chen W, Chen X, Zhang J, et al. A Multi-task Deep Network for Person Re-identification[J]. 2016.
Zhong Z, Zheng L, Cao D, et al. Re-ranking Person Re-identification with k-reciprocal Encoding[J]. 2017.
Sun Y, Zheng L, Deng W, et al. SVDNet for Pedestrian Retrieval[J]. 2017.