之前曾经写了一篇《String类型为什么设计成不可变的》,然后在评论区有人问String、StringBuilder、StringBuffer三者的区别,于是终于把这篇文章补了进来,这篇文章就分析一下这三个类。
一、认识String
String类型是不可变类型,为了保持文章的独立性,还是拿出来这个老掉牙的例子,
public class Test2 {
public static void main(String[] args) {
String a="张三";
System.out.println(a);
a="李四";
System.out.println(a);
}
}
//output:
//张三
//李四
在这里我们一开始给变量a赋值为“张三”,后来又赋值为"李四",是不是有个疑问,不是说String类型不可变嘛,在这里怎么变了,想要解决这个问题,我们还要深入String源码。下面是jdk1.8_171中String类型的一部分源码:
public final class String
implements java.io.Serializable, Comparable, CharSequence {
/** The value is used for character storage. */
private final char value[];
......
}
这里最核心的就是这个value字符串数组。也就是说我们的String的内容其实是被分割成了一个一个字符保存在了value数组当中,而且我们的String类型是final类型,value也是final类型,这就意味着我们再被集成和修改了。但是为什么我们还可以对上述的a对象赋值了两次呢?下面用一张图你就明白了。
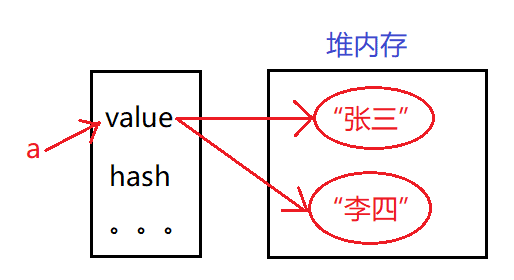
现在明白了吧, 也就是说我们的a对象其实没有改变,改变的是value数组指向的内容,因为value是数组也是引用类型,所以指向的内容可以随之改变,而且每一次赋值一个字符串,都会在内存中创建一个新的对象。当然了也有办法可以改变String类型,比如通过反射。
OK,到这里你应该对String有一个基本的了解了,其实通过上面的图相信你也应该能明白为什么有了String还需要StringBuilder和StringBuffer。那是因为String每一次增删改的操作都是在内存中创建了一个新的字符串,如果增删改的操作很多,那对我们的内存将造成极大的浪费,为此还需要StringBuilder和StringBuffer去解决这个问题。
二、StringBuilder和StringBuffer
StringBuilder和StringBuffer是可变的,也就说我们的增删改都是在原字符串的基础上操作的,操作次数再多内存也不会被白白的浪费,那他们俩又有什么区别呢?
StringBuffer是线性安全的,支持并发操作,适合多线程。
StringBuilder线性不安全,不支持并发操作,适合单线程。
也就是说他们俩区别就在于支不支持并发操作,使用上基本上类似,你知道上面的区别之后就可以根据自己的业务需求来决定具体使用哪一个。这里就以StringBuffer为例说明一下吧。
1、构造方法
//第一种:直接new出一个空对象
StringBuffer s = new StringBuffer();
//第二种:new一个对象,并为其分配1024个字节缓冲区
StringBuffer s=new StringBuffer(1024);
//第三种:new一个带有内容的对象
StringBuffer sb2=new StringBuffer(“张三”)
2、增删改操作
//第一种:增加内容
//1、增加内容:相当于字符串拼接
s.append("Java的架构师技术栈");
//2、增加内容:在指定位置插入
s.insert(2,"张三");
//第二种:删除内容
//1、删除内容:下表从0开始,删除指定字符
s. deleteCharAt(1);
//2、删除内容:从下表2一直到6的字符全部删掉
s. delete (2,6);
//第三种:更改内容
//1、将内容反转
sbreverse();
//2、对指定位置字符进行更改
s.setCharAt(2,’李’);
对于他们俩的使用基本上操作类似,这里就先写到这,毕竟不是专门看他们的源码的。别忘了我们最主要的任务是对其进行一个对比分析。
三、三者之间的性能测试
在这里其实就是对于其基本操作谁的效率最快的问题。
第一步:测试String执行1万次增加操作
public static void testString () {
String s="";
long begin = System.currentTimeMillis();
for(int i=0; i<10000; i++){
s += "java";
}
long end = System.currentTimeMillis();
System.out.println("String需要的时间为:"+(end-begin)+"毫秒");
}
第二步:测试StringBuilder执行1万次增加操作
public static void testStringBuilder () {
StringBuilder sb = new StringBuilder();
long begin = System.currentTimeMillis();
for(int i=0; i<10000; i++){
sb.append("java");
}
long end = System.currentTimeMillis();
System.out.println("StringBuilder需要的时间为:"+(end-begin)+"毫秒");
}
第三步:测试StringBuffer执行1万次增加操作
public static void testStringBuffer () {
StringBuffer sb = new StringBuffer();
long begin = System.currentTimeMillis();
for(int i=0; i<10000; i++){
sb.append("java");
}
long over = System.currentTimeMillis();
System.out.println("StringBuilder需要的时间为:"+(end-begin)+"毫秒");
}
第四步:测试一下:
public class Main {
public static void main(String[] args) {
testString();
testStringBuffer();
testStringBuilder();
}
}
看一下输出吧:
Sting需要的时间为:8876毫秒
StringBuffer需要的时间为:4毫秒
StringBuilder需要的时间为:3毫秒
这个结果其实已经很明显了:
StringBuilder 和StringBuffer >的效率远远大于String。因为这里是在单线程中去测试的,所以StringBuilder的时间比StringBuffer的稍微少一点,但是多线程可能就不一定了。所以他们两者其实是没法比较的。
四、String中的一个小问题
这一部分其实算是我附加的内容,因为当时在写String类型为什么不可变时,没有添加进来,因此借此机会加了进来。首先我们看一下如下代码:
String s1="张三";
String s2="张三";
String s3=new String("张三");
String s4=new String("张三");
System.out.println(s1==s2);//true
System.out.println(s1==s3);//false
System.out.println(s3==s4);//false
这个四行代码看起来好像是做了同一个操作,现在问题来了。问题后面的结果是不是和你想的有一点不一样呢?如果不一样,那就继续往下看。
首先还是先从编译器和运行期的jvm内存说起,我们的String不可变对象在编译期间会生成字面常量以及符号引用,存储在class文件常量池中,也就是运行期间方法区的常量池。我们看前两行代码:
s1="张三",s2=“张三”。执行这两句代码的时候都会生成字面常量以及符号引用,存储在class文件常量池中。但是问题就在于这个字面常量和符号引用,JVM执行引擎会直接在运行时常量池查找,一看他们长得一模一样,于是就保留了一份在运行时常量池中。因此在你执行s1==s2判断两者是否相等的时候,其实判断是同一个。
但是String s3=new String("张三");就不一样了,只要看到有new,就会直接在堆中创建一个新的对象,因此不管和谁去判断相等,肯定都是不一样的对象。
现在应该明白了吧,这三者的区别其实就是效率问题和使用场景的问题,同时String还有一个需要注意的点,关于String其实里面会涉及大量的问题和面试题,而且面试出现的频率还超级高。如有问题,还请批评指正。
