一次 ElasticSearch 搜索优化
1. 环境
ES6.3.2,索引名称 user_v1,5个主分片,每个分片一个副本。分片基本都在11GB左右,GET _cat/shards/user

一共有3.4亿文档,主分片总共57GB。

Segment信息:curl -X GET "221.228.105.140:9200/_cat/segments/user_v1?v" >> user_v1_segment
user_v1索引一共有404个段:
cat user_v1_segment | wc -l
404
处理一下数据,用Python画个直方图看看效果:
sed -i '1d' file # 删除文件第一行
awk -F ' ' '{print $7}' user_v1_segment >> docs_count # 选取感兴趣的一列(docs.count 列)
with open('doc_count.txt') as f:
data=f.read()
docList = data.splitlines()
docNums = list(map(int,docList))
import matplotlib.pyplot as plt
plt.hist(docNums,bins=40,normed=0,facecolor='blue',edgecolor='black')大概看一下每个Segment中包含的文档的个数。横坐标是:文档数量,纵坐标是:segment个数。可见:大部分的Segment中只包含了少量的文档(\(0.5*10^7\))
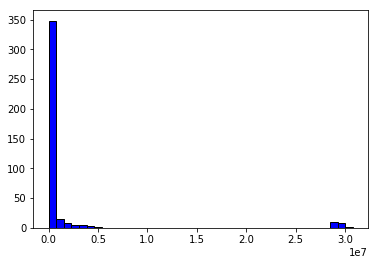
修改refresh_interval为30s,原来默认为1s,这样能在一定程度上减少Segment的数量。然后先force merge将404个Segment减少到200个:
POST /user_v1/_forcemerge?only_expunge_deletes=false&max_num_segments=200&flush=true
但是一看,还是有312个Segment。这个可能与merge的配置有关了。有兴趣的可以了解一下 force merge 过程中这2个参数的意义:
- merge.policy.max_merge_at_once_explicit
- merge.scheduler.max_merge_count
执行profile分析:
1,Collector 时间过长,有些分片耗时长达7.9s。关于Profile 分析,可参考:profile-api
2,采用HanLP 分词插件,Analyzer后得到Term,居然有"空格Term",而这个Term的匹配长达800ms!
来看看原因:
POST /_analyze
{
"analyzer": "hanlp_standard",
"text":"人生 如梦"
}
分词结果是包含了空格的:
{
"tokens": [
{
"token": "人生",
"start_offset": 0,
"end_offset": 2,
"type": "n",
"position": 0
},
{
"token": " ",
"start_offset": 0,
"end_offset": 1,
"type": "w",
"position": 1
},
{
"token": "如",
"start_offset": 0,
"end_offset": 1,
"type": "v",
"position": 2
},
{
"token": "梦",
"start_offset": 0,
"end_offset": 1,
"type": "n",
"position": 3
}
]
}那实际文档被Analyzer了之后是否存储了空格呢?
于是先定义一个索引,开启term_vector。参考store term-vector
PUT user
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"profile": {
"properties": {
"nick": {
"type": "text",
"analyzer": "hanlp_standard",
"term_vector": "yes",
"fields": {
"raw": {
"type": "keyword"
}
}
}
}
}
}
}然后PUT一篇文档进去:
PUT user/profile/1
{
"nick":"人生 如梦"
}查看Term Vector:docs-termvectors
GET /user/profile/1/_termvectors
{
"fields" : ["nick"],
"offsets" : true,
"payloads" : true,
"positions" : true,
"term_statistics" : true,
"field_statistics" : true
}发现存储的Terms里面有空格。
{
"_index": "user",
"_type": "profile",
"_id": "1",
"_version": 1,
"found": true,
"took": 2,
"term_vectors": {
"nick": {
"field_statistics": {
"sum_doc_freq": 4,
"doc_count": 1,
"sum_ttf": 4
},
"terms": {
" ": {
"doc_freq": 1,
"ttf": 1,
"term_freq": 1
},
"人生": {
"doc_freq": 1,
"ttf": 1,
"term_freq": 1
},
"如": {
"doc_freq": 1,
"ttf": 1,
"term_freq": 1
},
"梦": {
"doc_freq": 1,
"ttf": 1,
"term_freq": 1
}
}
}
}
}然后再执行profile 查询分析:
GET user/profile/_search?human=true
{
"profile":true,
"query": {
"match": {
"nick": "人生 如梦"
}
}
}发现Profile里面居然有针对 空格Term 的查询!!!(注意 nick 后面有个空格)
"type": "TermQuery",
"description": "nick: ",
"time": "58.2micros",
"time_in_nanos": 58244,profile结果如下:
"profile": {
"shards": [
{
"id": "[7MyDkEDrRj2RPHCPoaWveQ][user][0]",
"searches": [
{
"query": [
{
"type": "BooleanQuery",
"description": "nick:人生 nick: nick:如 nick:梦",
"time": "642.9micros",
"time_in_nanos": 642931,
"breakdown": {
"score": 13370,
"build_scorer_count": 2,
"match_count": 0,
"create_weight": 390646,
"next_doc": 18462,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 2,
"score_count": 1,
"build_scorer": 220447,
"advance": 0,
"advance_count": 0
},
"children": [
{
"type": "TermQuery",
"description": "nick:人生",
"time": "206.6micros",
"time_in_nanos": 206624,
"breakdown": {
"score": 942,
"build_scorer_count": 3,
"match_count": 0,
"create_weight": 167545,
"next_doc": 1493,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 2,
"score_count": 1,
"build_scorer": 36637,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "nick: ",
"time": "58.2micros",
"time_in_nanos": 58244,
"breakdown": {
"score": 918,
"build_scorer_count": 3,
"match_count": 0,
"create_weight": 46130,
"next_doc": 964,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 2,
"score_count": 1,
"build_scorer": 10225,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "nick:如",
"time": "51.3micros",
"time_in_nanos": 51334,
"breakdown": {
"score": 888,
"build_scorer_count": 3,
"match_count": 0,
"create_weight": 43779,
"next_doc": 1103,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 2,
"score_count": 1,
"build_scorer": 5557,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "nick:梦",
"time": "59.1micros",
"time_in_nanos": 59108,
"breakdown": {
"score": 3473,
"build_scorer_count": 3,
"match_count": 0,
"create_weight": 49739,
"next_doc": 900,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 2,
"score_count": 1,
"build_scorer": 4989,
"advance": 0,
"advance_count": 0
}
}
]
}
],
"rewrite_time": 182090,
"collector": [
{
"name": "CancellableCollector",
"reason": "search_cancelled",
"time": "25.9micros",
"time_in_nanos": 25906,
"children": [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time": "19micros",
"time_in_nanos": 19075
}
]
}
]
}
],
"aggregations": []
}
]
}而在实际的生产环境中,空格Term的查询耗时480ms,而一个正常词语("微信")的查询,只有18ms。如下在分片[user_v1][3]上的profile分析结果:
"profile": {
"shards": [
{
"id": "[8eN-6lsLTJ6as39QJhK5MQ][user_v1][3]",
"searches": [
{
"query": [
{
"type": "BooleanQuery",
"description": "nick:微信 nick: nick:黄色",
"time": "888.6ms",
"time_in_nanos": 888636963,
"breakdown": {
"score": 513864260,
"build_scorer_count": 50,
"match_count": 0,
"create_weight": 93345,
"next_doc": 364649642,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 5063173,
"score_count": 4670398,
"build_scorer": 296094,
"advance": 0,
"advance_count": 0
},
"children": [
{
"type": "TermQuery",
"description": "nick:微信",
"time": "18.4ms",
"time_in_nanos": 18480019,
"breakdown": {
"score": 656810,
"build_scorer_count": 62,
"match_count": 0,
"create_weight": 23633,
"next_doc": 17712339,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 7085,
"score_count": 5705,
"build_scorer": 74384,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "nick: ",
"time": "480.5ms",
"time_in_nanos": 480508016,
"breakdown": {
"score": 278358058,
"build_scorer_count": 72,
"match_count": 0,
"create_weight": 6041,
"next_doc": 192388910,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 5056541,
"score_count": 4665006,
"build_scorer": 33387,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "nick:黄色",
"time": "3.8ms",
"time_in_nanos": 3872679,
"breakdown": {
"score": 136812,
"build_scorer_count": 50,
"match_count": 0,
"create_weight": 5423,
"next_doc": 3700537,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 923,
"score_count": 755,
"build_scorer": 28178,
"advance": 0,
"advance_count": 0
}
}
]
}
],
"rewrite_time": 583986593,
"collector": [
{
"name": "CancellableCollector",
"reason": "search_cancelled",
"time": "730.3ms",
"time_in_nanos": 730399762,
"children": [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time": "533.2ms",
"time_in_nanos": 533238387
}
]
}
]
}
],
"aggregations": []
},由于我采用的是HanLP分词,用的这个分词插件elasticsearch-analysis-hanlp,而采用ik_max_word分词却没有相应的问题,这应该是分词插件的bug,于是去github上提了一个issue,有兴趣的可以关注。看来我得去研究一下ElasticSearch Analyze整个流程的源码以及加载插件的源码了 ::(
以上是一个空格Term造成的查询性能问题。在Profile分析时,还发现,使用SSD的Collector time比机械硬盘快10倍左右。
分片[user_v1][0] 的 Collector time长达7.6秒,而这个分片所在机器的磁盘是机械硬盘。而上面那个分片[user_v1][3]所在的磁盘是SSD,Collector time只有730.3ms。可见SSD与机械硬盘的在Collector time上相差10倍 。下面是分片[user_v1][0]的profile查询分析:
{
"id": "[wx0dqdubRkiqJJ-juAqH4A][user_v1][0]",
"searches": [
{
"query": [
{
"type": "BooleanQuery",
"description": "nick:微信 nick: nick:黄色",
"time": "726.1ms",
"time_in_nanos": 726190295,
"breakdown": {
"score": 339421458,
"build_scorer_count": 48,
"match_count": 0,
"create_weight": 65012,
"next_doc": 376526603,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 4935754,
"score_count": 4665766,
"build_scorer": 575653,
"advance": 0,
"advance_count": 0
},
"children": [
{
"type": "TermQuery",
"description": "nick:微信",
"time": "63.2ms",
"time_in_nanos": 63220487,
"breakdown": {
"score": 649184,
"build_scorer_count": 61,
"match_count": 0,
"create_weight": 32572,
"next_doc": 62398621,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 6759,
"score_count": 5857,
"build_scorer": 127432,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "nick: ",
"time": "1m",
"time_in_nanos": 60373841264,
"breakdown": {
"score": 60184752245,
"build_scorer_count": 69,
"match_count": 0,
"create_weight": 5888,
"next_doc": 179443959,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 4929373,
"score_count": 4660228,
"build_scorer": 49501,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "nick:黄色",
"time": "528.1ms",
"time_in_nanos": 528107489,
"breakdown": {
"score": 141744,
"build_scorer_count": 43,
"match_count": 0,
"create_weight": 4717,
"next_doc": 527942227,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 967,
"score_count": 780,
"build_scorer": 17010,
"advance": 0,
"advance_count": 0
}
}
]
}
],
"rewrite_time": 993826311,
"collector": [
{
"name": "CancellableCollector",
"reason": "search_cancelled",
"time": "7.8s",
"time_in_nanos": 7811511525,
"children": [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time": "7.6s",
"time_in_nanos": 7616467158
}
]
}
]
}
],
"aggregations": []
},结论
查询不仅仅与Segment数量、Collector time等有关,还与索引的mapping定义,查询方式(match、filter、term……)有关,可用Profile API分析查询性能问题。另外也有一些压测工具,比如:esrally
对于中文而言,还要注意 query string 被Analyze成各个token之后,到底是针对了哪些Token查询,这个可以通过term vector进行测试,但生产环境一般不会开启term vector。因此,中文分词算法对搜索命中会有影响。
而至于搜索排序,可先用explain API 分析各个Term的得分,然后也可考虑ES的Function Score功能,针对某些特定的field做调节(field_value_factor),甚至可以用机器学习模型优化搜索排序(learning to rank)
关于ElasticSearch查询效率的提升一些思考:
- FileSystem cache 要足够(堆外内存 vs 堆外内存),数据分布要合理(冷热分离)
- 索引设计要合理(多字段、Analyzer、Index shard数量)、Segment数量(refresh interval 配置)
- 查询语法要合适(term、match、filter),可通过搜索参数调优(terminate_after提前返回、timeout查询响应超时)
- profile分析
参考资料
- 如何知道ES中存储了哪些Token?
- Profile API?
- Profile API中各个字段的意义
- 查看索引的Segment详情?
- github上提了一个issue