一、写在开头
Java作为一个编程界最流行的语言之一,有着很强的生命力。代码的编写规范也是不容忽视的,今天,我就把自己阅读的国内的互联网巨头阿里巴巴的《阿里巴巴 Java 开发手册》一些精彩内容摘录如下。以飨读者。《阿里巴巴Java开发手册 终极版v1.3.0.pdf》 下载地址

二、精彩摘录
4.1)【命名风格】
【01 强制】抽象类命名使用 Abstract 或 Base 开头;异常类命名使用 Exception 结尾;测试类 命名以它要测试的类的名称开始,以 Test 结尾。
【02 强制】中括号是数组类型的一部分,数组定义如下:String[] args; 反例:使用 String args[]的方式来定义。
【03强制】POJO 类中布尔类型的变量,都不要加 is,否则部分框架解析会引起序列化错误。
==反例:定义为基本数据类型 Boolean isDeleted;的属性,它的方法也是 isDeleted(), 框架在反向解析的时候,“以为”对应的属性名称是 deleted,导致属性获取不到,进而抛出异 常。
【04 强制】包名统一使用小写,点分隔符之间有且仅有一个自然语义的英语单词。包名统一使用 单数形式,但是类名如果有复数含义,类名可以使用复数形式。 正例: 应用工具类包名为 com.alibaba.open.util、类名为 MessageUtils(此规则参考 spring 的框架结构)
【05 推荐】如果模块、接口、类、方法使用了设计模式,在命名时体现出具体模式
【06 推荐】接口类中的方法和属性不要加任何修饰符号(public 也不要加),保持代码的简洁 性,并加上有效的 Javadoc 注释。尽量不要在接口里定义变量,如果一定要定义变量,肯定是 与接口方法相关,并且是整个应用的基础常量。 正例:接口方法签名:void f(); 接口基础常量表示:String COMPANY = "alibaba"; 反例:接口方法定义:public abstract void f(); 说明:JDK8 中接口允许有默认实现,那么这个 default 方法,是对所有实现类都有价值的默 认实现。
【不是很理解--todo】接口和实现类的命名有两套规则:
1)【强制】对于 Service 和 DAO 类,基于 SOA 的理念,暴露出来的服务一定是接口,内部 的实现类用 Impl 的后缀与接口区别。 正例:CacheServiceImpl 实现 CacheService 接口。
2)【推荐】如果是形容能力的接口名称,取对应的形容词做接口名(通常是–able 的形式)。 正例:AbstractTranslator 实现 Translatable。
4.2)【常量定义】
【不是很理解--todo】【强制】不允许任何魔法值(即未经定义的常量)直接出现在代码中。 反例:String key = "Id#taobao_" + tradeId; cache.put(key, value);
4.3)【代码格式】
【01 强制】大括号的使用约定。如果是大括号内为空,则简洁地写成{}即可,不需要换行;如果 是非空代码块则: 1) 左大括号前不换行。 2) 左大括号后换行。 3) 右大括号前换行。 4) 右大括号后还有 else 等代码则不换行;表示终止的右大括号后必须换行。
【02 强制】if/for/while/switch/do 等保留字与括号之间都必须加空格。
【03 强制】任何二目、三目运算符的左右两边都需要加一个空格。 说明:运算符包括赋值运算符=、逻辑运算符&&、加减乘除符号等。
【04 强制】注释的双斜线与注释内容之间有且仅有一个空格。 正例:// 注释内容,注意在//和注释内容之间有一个空格。
4.4)【OOP规约】
【01 强制】Object 的 equals 方法容易抛空指针异常,应使用常量或确定有值的对象来调用 equals。
==正例:"test".equals(object); 反例:object.equals("test"); 说明:推荐使用 java.util.Objects#equals(JDK7 引入的工具类)
【02 强制】所有的相同类型的包装类对象之间值的比较,全部使用 equals 方法比较。
说明:对于 Integer var = ? 在-128 至 127 范围内的赋值,Integer 对象是在 IntegerCache.cache 产生,会复用已有对象,这个区间内的 Integer 值可以直接使用==进行 判断,但是这个区间之外的所有数据,都会在堆上产生,并不会复用已有对象,这是一个大坑, 推荐使用 equals 方法进行判断。
关于基本数据类型与包装数据类型的使用标准如下:
1) 【强制】所有的 POJO 类属性必须使用包装数据类型。
2) 【强制】RPC 方法的返回值和参数必须使用包装数据类型。
3) 【推荐】所有的局部变量使用基本数据类型。
==说明:POJO 类属性没有初值是提醒使用者在需要使用时,必须自己显式地进行赋值,任何 NPE (即空指针异常)问题,或者入库检查,都由使用者来保证。
==正例:数据库的查询结果可能是 null,因为自动拆箱,用基本数据类型接收有 NPE 风险。
==反例:比如显示成交总额涨跌情况,即正负 x%,x 为基本数据类型,调用的 RPC 服务,调用 不成功时,返回的是默认值,页面显示为 0%,这是不合理的,应该显示成中划线。所以包装 数据类型的 null 值,能够表示额外的信息,如:远程调用失败,异常退出。
参考:Java中基本数据类型和包装类
【03 强制】序列化类新增属性时,请不要修改 serialVersionUID 字段,避免反序列失败;如 果完全不兼容升级,避免反序列化混乱,那么请修改 serialVersionUID 值。 说明:注意 serialVersionUID 不一致会抛出序列化运行时异常。
【04 强制】POJO 类必须写 toString 方法。使用 IDE 的中工具:source> generate toString 时,如果继承了另一个 POJO 类,注意在前面加一下 super.toString。 说明:在方法执行抛出异常时,可以直接调用 POJO 的 toString()方法打印其属性值,便于排 查问题。
【05 推荐】当一个类有多个构造方法,或者多个同名方法,这些方法应该按顺序放置在一起, 便于阅读,
【06 推荐】 类内方法定义顺序依次是:公有方法或保护方法 > 私有方法 > getter/setter 方法。
【07 推荐】循环体内,字符串的连接方式,使用 StringBuilder 的 append 方法进行扩展。
==说明:反编译出的字节码文件显示每次循环都会 new 出一个 StringBuilder 对象,然后进行 append 操作,最后通过 toString 方法返回 String 对象,造成内存资源浪费。
==反例: String str = "start"; for (int i = 0; i < 100; i++) { str = str + "hello"; }
【08 推荐】类成员与方法访问控制从严:
1) 如果不允许外部直接通过 new 来创建对象,那么构造方法必须是 private。
2) 工具类不允许有 public 或 default 构造方法。
3) 类非 static 成员变量并且与子类共享,必须是 protected。
4) 类非 static 成员变量并且仅在本类使用,必须是 private。
5) 类 static 成员变量如果仅在本类使用,必须是 private。
6) 若是 static 成员变量,必须考虑是否为 final。
7) 类成员方法只供类内部调用,必须是 private。
8) 类成员方法只对继承类公开,那么限制为 protected。
==说明:任何类、方法、参数、变量,严控访问范围。过于宽泛的访问范围,不利于模块解耦。 思考:如果是一个 private 的方法,想删除就删除,可是一个 public 的 service 方法,或者 一个 public 的成员变量,删除一下,不得手心冒点汗吗?变量像自己的小孩,尽量在自己的 视线内,变量作用域太大,无限制的到处跑,那么你会担心的。
4.5)【集合处理】
【01 强制】关于 hashCode 和 equals 的处理,遵循如下规则:
1) 只要重写 equals,就必须重写 hashCode。
2) 因为 Set 存储的是不重复的对象,依据 hashCode 和 equals 进行判断,所以 Set 存储的 对象必须重写这两个方法。
3) 如果自定义对象做为 Map 的键,那么必须重写 hashCode 和 equals。 说明:String 重写了 hashCode 和 equals 方法,所以我们可以非常愉快地使用 String 对象 作为 key 来使用。
【02 强制】ArrayList的subList结果不可强转成ArrayList,否则会抛出ClassCastException 异常,即 java.util.RandomAccessSubList cannot be cast to java.util.ArrayList.
==说明:subList 返回的是 ArrayList 的内部类 SubList,并不是 ArrayList ,而是 ArrayList 的一个视图,对于 SubList 子列表的所有操作最终会反映到原列表上。
== 例子:https://blog.csdn.net/qq_15118961/article/details/80893780
【03 强制】在 subList 场景中,高度注意对原集合元素个数的修改,会导致子列表的遍历、增加、 删除均会产生 ConcurrentModificationException 异常。
【04 强制】使用集合转数组的方法,必须使用集合的 toArray(T[] array),传入的是类型完全 一样的数组,大小就是 list.size()。
【05 强制】使用工具类 Arrays.asList()把数组转换成集合时,不能使用其修改集合相关的方 法,它的 add/remove/clear 方法会抛出 UnsupportedOperationException 异常。
== 说明:asList 的返回对象是一个 Arrays 内部类,并没有实现集合的修改方法。Arrays.asList 体现的是适配器模式,只是转换接口,后台的数据仍是数组。
==String[] str = new String[] { "you", "wu" }; List list = Arrays.asList(str); 第一种情况:list.add("yangguanbao"); 运行时异常。 第二种情况:str[0] = "gujin"; 那么 list.get(0)也会随之修改。
【06 强制】泛型通配符来接收返回的数据,此写法的泛型集合不能使用 add 方 法,而不能使用 get 方法,做为接口调用赋值时易出错。
==说明:扩展说一下 PECS(Producer Extends Consumer Super)原则:第一、频繁往外读取内 容的,适合用。第二、经常往里插入的,适合用。
【07 强制】c。remove 元素请使用 Iterator 方式,如果并发操作,需要对 Iterator 对象加锁。
【08 强制】 在 JDK7 版本及以上,Comparator 要满足如下三个条件,不然 Arrays.sort, Collections.sort 会报 IllegalArgumentException 异常。
== 说明:三个条件如下 1) x,y 的比较结果和 y,x 的比较结果相反。 2) x>y,y>z,则 x>z。 3) x=y,则 x,z 比较结果和 y,z 比较结果相同。
== 参考资料:https://www.cnblogs.com/shizhijie/p/7657049.html : JAVA Comparator 接口排序用法
【09 推荐】集合初始化时,指定集合初始值大小。
==说明:HashMap 使用 HashMap(int initialCapacity) 初始化,
==正例:initialCapacity = (需要存储的元素个数 / 负载因子) + 1。注意负载因子(即 loader factor)默认为 0.75,如果暂时无法确定初始值大小,请设置为 16(即默认值)。
== 反例:HashMap 需要放置 1024 个元素,由于没有设置容量初始大小,随着元素不断增加,容 量 7 次被迫扩大,resize 需要重建 hash 表,严重影响性能。
【10 推荐】使用 entrySet 遍历 Map 类集合 KV,而不是 keySet 方式进行遍历。
==说明:keySet 其实是遍历了 2 次,一次是转为 Iterator 对象,另一次是从 hashMap 中取出 key 所对应的 value。而 entrySet 只是遍历了一次就把 key 和 value 都放到了 entry 中,效 率更高。如果是 JDK8,使用 Map.foreach 方法。 正例:values()返回的是 V 值集合,是一个 list 集合对象;keySet()返回的是 K 值集合,是 一个 Set 集合对象;entrySet()返回的是 K-V 值组合集合。
== 网络例子: https://blog.csdn.net/lisiben/article/details/84855030
【11 推荐】高度注意 Map 类集合 K/V 能不能存储 null 值的情况,如下表格:
4.6)【集合处理】
【强制】获取单例对象需要保证线程安全,其中的方法也要保证线程安全。 说明:资源驱动类、工具类、单例工厂类都需要注意。
4.7)【控制语句】
【01 强制】在一个 switch 块内,每个 case 要么通过 break/return 等来终止,要么注释说明程 序将继续执行到哪一个 case 为止;在一个 switch 块内,都必须包含一个 default 语句并且 放在最后,即使它什么代码也没有。
【02 强制】在 if/else/for/while/do 语句中必须使用大括号。即使只有一行代码,避免采用 单行的编码方式:if (condition) statements;
【03 推荐】表达异常的分支时,少用 if-else 方式,这种方式可以改写成: if (condition) { ... return obj; } // 接着写 else 的业务逻辑代码;
==正例:超过 3 层的 if-else 的逻辑判断代码可以使用卫语句、策略模式、状态模式等来实现,
== 参考: https://www.cnblogs.com/didiaoxiong/p/9125940.html
【04 推荐】循环体中的语句要考量性能,以下操作尽量移至循环体外处理,如定义对象、变量、 获取数据库连接,进行不必要的 try-catch 操作(这个 try-catch 是否可以移至循环体外)。
4.8)【注释规约】
【01 强制】类、类属性、类方法的注释必须使用 Javadoc 规范,使用/**内容*/格式,不得使用 // xxx 方式。
【02 强制】所有的类都必须添加创建者和创建日期。
【03 强制】方法内部单行注释,在被注释语句上方另起一行,使用//注释。方法内部多行注释 使用/* */注释,注意与代码对齐。
【04 参考】特殊注释标记,请注明标记人与标记时间。注意及时处理这些标记,通过标记扫描, 经常清理此类标记。线上故障有时候就是来源于这些标记处的代码。
== 1) 待办事宜(TODO):( 标记人,标记时间,[预计处理时间]) 表示需要实现,但目前还未实现的功能。这实际上是一个 Javadoc 的标签,目前的 Javadoc 还没有实现,但已经被广泛使用。只能应用于类,接口和方法(因为它是一个 Javadoc 标签)。
== 2) 错误,不能工作(FIXME):(标记人,标记时间,[预计处理时间]) 在注释中用 FIXME 标记某代码是错误的,而且不能工作,需要及时纠正的情况。
4.9)【其他】
【01 强制】后台输送给页面的变量必须加$!{var}——中间的感叹号。 说明:如果 var=null 或者不存在,那么${var}会直接显示在页面上。
【02 强制】注意 Math.random() 这个方法返回是 double 类型,注意取值的范围 0≤x<1(能够 取到零值,注意除零异常),如果想获取整数类型的随机数,不要将 x 放大 10 的若干倍然后 取整,直接使用 Random 对象的 nextInt 或者 nextLong 方法。
【03 强制】获取当前毫秒数 System.currentTimeMillis(); 而不是 new Date().getTime(); 说明:如果想获取更加精确的纳秒级时间值,使用 System.nanoTime()的方式。在 JDK8 中, 针对统计时间等场景,推荐使用 Instant 类。
【04 推荐】任何数据结构的构造或初始化,都应指定大小,避免数据结构无限增长吃光内存。
【05 推荐】及时清理不再使用的代码段或配置信息。 说明:对于垃圾代码或过时配置,坚决清理干净,避免程序过度臃肿,代码冗余。
== 正例:对于暂时被注释掉,后续可能恢复使用的代码片断,在注释代码上方,统一规定使用三 个斜杠(///)来说明注释掉代码的理由。
4.10)【异常处理】
【01 强制】对大段代码进行 try-catch,这是不负责任的表现。catch 时请分清稳定代码和非稳 定代码,稳定代码指的是无论如何不会出错的代码。对于非稳定代码的 catch 尽可能进行区分 异常类型,再做对应的异常处理。
【02 参考】在代码中使用“抛异常”还是“返回错误码”,对于公司外的 http/api 开放接口必须 使用“错误码”;而应用内部推荐异常抛出;跨应用间 RPC 调用优先考虑使用 Result 方式,封 装 isSuccess()方法、“错误码”、“错误简短信息”。
== 说明:关于 RPC 方法返回方式使用 Result 方式的理由: 1)使用抛异常返回方式,调用方如果没有捕获到就会产生运行时错误。 2)如果不加栈信息,只是 new 自定义异常,加入自己的理解的 error message,对于调用 端解决问题的帮助不会太多。如果加了栈信息,在频繁调用出错的情况下,数据序列化和传输 的性能损耗也是问题。
4.11)【日志规约】
【强制】应用中不可直接使用日志系统(Log4j、Logback)中的 API,而应依赖使用日志框架 SLF4J 中的 API,使用门面模式的日志框架,有利于维护和各个类的日志处理方式统一。
【推荐】谨慎地记录日志。生产环境禁止输出 debug 日志;有选择地输出 info 日志;如果使 用 warn 来记录刚上线时的业务行为信息,一定要注意日志输出量的问题,避免把服务器磁盘 撑爆,并记得及时删除这些观察日志。
4.12)【单元测试】
【01 强制】好的单元测试必须遵守 AIR 原则。 说明:单元测试在线上运行时,感觉像空气(AIR)一样并不存在,但在测试质量的保障上, 却是非常关键的。好的单元测试宏观上来说,具有自动化、独立性、可重复执行的特点。
A:Automatic(自动化) I:Independent(独立性) R:Repeatable(可重复)
【02 强制】保持单元测试的独立性。为了保证单元测试稳定可靠且便于维护,单元测试用例之间 决不能互相调用,也不能依赖执行的先后次序。
== 反例:method2 需要依赖 method1 的执行,将执行结果做为 method2 的输入。
【03 强制】对于单元测试,要保证测试粒度足够小,有助于精确定位问题。单测粒度至多是类级 别,一般是方法级别。
【04 推荐】单元测试的基本目标:语句覆盖率达到 70%;核心模块的语句覆盖率和分支覆盖率都 要达到 100%
【05 推荐】对于数据库相关的查询,更新,删除等操作,不能假设数据库里的数据是存在的, 或者直接操作数据库把数据插入进去,请使用程序插入或者导入数据的方式来准备数据。
【06 推荐】单元测试作为一种质量保障手段,不建议项目发布后补充单元测试用例,建议在项 目提测前完成单元测试。
4.13)【安全规约】
【01 强制】用户请求传入的任何参数必须做有效性验证。
== 说明:忽略参数校验可能导致:
page size 过大导致内存溢出
恶意 order by 导致数据库慢查询
任意重定向
SQL 注入
反序列化注入
正则输入源串拒绝服务 ReDoS
==说明:Java 代码用正则来验证客户端的输入,有些正则写法验证普通用户输入没有问题, 但是如果攻击人员使用的是特殊构造的字符串来验证,有可能导致死循环的结果。
【02 强制】在使用平台资源,譬如短信、邮件、电话、下单、支付,必须实现正确的防重放限制, 如数量限制、疲劳度控制、验证码校验,避免被滥刷、资损。 说明:如注册时发送验证码到手机,如果没有限制次数和频率,那么可以利用此功能骚扰到其 它用户,并造成短信平台资源浪费。
【03 推荐】发贴、评论、发送即时消息等用户生成内容的场景必须实现防刷、文本内容违禁词过 滤等风控策略。
4.14)【MySQL数据库】
【01 强制】主键索引名为 pk_字段名;唯一索引名为 uk_字段名;普通索引名则为 idx_字段名。 说明:pk_ 即 primary key;uk_ 即 unique key;idx_ 即 index 的简称。
【02 强制】小数类型为 decimal,禁止使用 float 和 double。
==说明:float 和 double 在存储的时候,存在精度损失的问题,很可能在值的比较时,得到不 正确的结果。如果存储的数据范围超过 decimal 的范围,建议将数据拆成整数和小数分开存储。
【03 强制】varchar 是可变长字符串,不预先分配存储空间,长度不要超过 5000,如果存储长 度大于此值,定义字段类型为 text,独立出来一张表,用主键来对应,避免影响其它字段索 引效率。
【04 推荐】单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。 说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
【05 强制】业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引。
== 说明:不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明 显的;另外,即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据 墨菲定律,必 然有脏数据产生。
【06 强制】在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据 实际文本区分度决定索引长度即可。 说明:索引的长度与区分度是一对矛盾体,一般对字符串类型数据,长度为 20 的索引,区分度会高达 90%以上,可以使用 count(distinct left(列名, 索引长度))/count(*)的区分度 来确定。
【07 推荐】如果有 order by 的场景,请注意利用索引的有序性。order by 最后的字段是组合 索引的一部分,并且放在索引组合顺序的最后,避免出现 file_sort 的情况,影响查询性能。 正例:where a=? and b=? order by c; 索引:a_b_c 反例:索引中有范围查找,那么索引有序性无法利用,如:WHERE a>10 ORDER BY b; 索引 a_b 无法排序。
【08 推荐】利用延迟关联或者子查询优化超多分页场景。
==说明:MySQL 并不是跳过 offset 行,而是取 offset+N 行,然后返回放弃前 offset 行,返回 N 行,那当 offset 特别大的时候,效率就非常的低下,要么控制返回的总页数,要么对超过 特定阈值的页数进行 SQL 改写。
== 正例:先快速定位需要获取的 id 段,然后再关联: SELECT a.* FROM 表 1 a, (select id from 表 1 where 条件 LIMIT 100000,20 ) b where a.id=b.id
【09 推荐】建组合索引的时候,区分度最高的在最左边。
==正例:如果 where a=? and b=? ,a 列的几乎接近于唯一值,那么只需要单建 idx_a 索引即 可。
== 说明:存在非等号和等号混合判断条件时,在建索引时,请把等号条件的列前置。如:where a>? and b=? 那么即使 a 的区分度更高,也必须把 b 放在索引的最前列。
【10 推荐】防止因字段类型不同造成的隐式转换,导致索引失效。
【11 参考】创建索引时避免有如下极端误解: 1)宁滥勿缺。认为一个查询就需要建一个索引。 2)宁缺勿滥。认为索引会消耗空间、严重拖慢更新和新增速度。 3)抵制惟一索引。认为业务的惟一性一律需要在应用层通过“先查后插”方式解决
【12 强制】不要使用 count(列名)或 count(常量)来替代 count(*),count(*)是 SQL92 定义的 标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。 说明:count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
【13 强制】count(distinct col) 计算该列除 NULL 之外的不重复行数,注意 count(distinct col1, col2) 如果其中一列全为 NULL,那么即使另一列有不同的值,也返回为 0。
【14 强制】使用 ISNULL()来判断是否为 NULL 值。
==说明:NULL 与任何值的直接比较都为 NULL。 1) NULL<>NULL 的返回结果是 NULL,而不是 false。 2) NULL=NULL 的返回结果是 NULL,而不是 true。 3) NULL<>1 的返回结果是 NULL,而不是 true。
【15 参考】TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少,但 TRUNCATE 无事务且不触发 trigger,有可能造成事故,故不建议在开发代码中使用此语句。 说明:TRUNCATE TABLE 在功能上与不带 WHERE 子句的 DELETE 语句相同。
4.15)【ORM映射】
【01 推荐】不要写一个大而全的数据更新接口。传入为 POJO 类,不管是不是自己的目标更新字 段,都进行 update table setc1=value1,c2=value2,c3=value3; 这是不对的。执行 SQL 时,不要更新无改动的字段,一是易出错;二是效率低;三是增加 binlog 存储。
【02 参考】中的 compareValue 是与属性值对比的常量,一般是数字,表示相等时带 上此条件;表示不为空且不为 null 时执行;表示不为 null 值时 执行。
三、番外--Git的使用
【01 常见Git命令】
#【001】
统一概念:工作区:改动(增删文件和内容)
暂存区:输入命令:git add 改动的文件名,此次改动就放到了 ‘暂存区’
本地仓库(简称:本地):输入命令:git commit 此次修改的描述,此次改动就放到了 ’本地仓库’,每个 commit,我叫它为一个 ‘版本’。
远程仓库(简称:远程):输入命令:git push 远程仓库,此次改动就放到了 ‘远程仓库’(GitHub 等)
commit-id:输出命令:git log,最上面那行 commit xxxxxx,后面的字符串就是 commit-id
#【002】
#编辑修改等
git show # 显示某次提交的内容 git show $id
git checkout
git revert
#比较diff
git diff
git diff --staged # 比较暂存区和版本库差异
git diff --cached # 比较暂存区和版本库差异
git whatchanged --since='2 weeks ago' #查看两个星期内的改动
git diff --word-diff #详细展示一行中的修改
#查看提交记录
git log -p -2 # 查看最近两次详细修改内容的diff
git blame
git reflog #显示本地更新过 HEAD 的 git 命令记录 ,类似 shell的 history
git log --all --grep='
#Git 本地分支管理
git branch -r # 查看远程分支
git branch
git co
git co $id # 把某次历史提交记录checkout出来,但无分支信息,切换到其他分支会自动删除
git branch -d
git branch -vv 展示本地分支关联远程仓库的情况
git merge
#Git暂存管理
git stash # 暂存
git stash list # 列所有stash
git stash apply # 恢复暂存的内容
git stash drop # 删除暂存区
#Git远程分支管理
git pull --no-ff # 抓取远程仓库所有分支更新并合并到本地,不要快进合并
git push # push所有分支-- 要慎用,还是要push具体的分支好一点 https://www.cnblogs.com/djiankuo/p/6492533.html
git push -u origin develop # 首次将本地develop分支提交到远程develop分支,并且track
git push origin master # 将本地主分支推到远程主分支
git push origin dev_20190513_registrationpath #我们的java项目 数据统计的Git push命令
#Git远程仓库管理
git remote -v # 查看远程服务器地址和仓库名称
git remote show origin # 查看远程服务器仓库状态
【02 】本地仓库“三棵树”
本地仓库由 git 维护的三棵“树”组成。
1)【图01】本地仓库git 三棵树
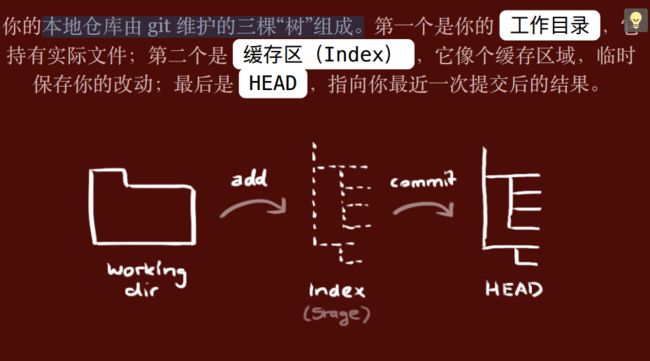
2)【图02】git本地三棵树的相互转化命令:https://josh-persistence.iteye.com/blog/2215214
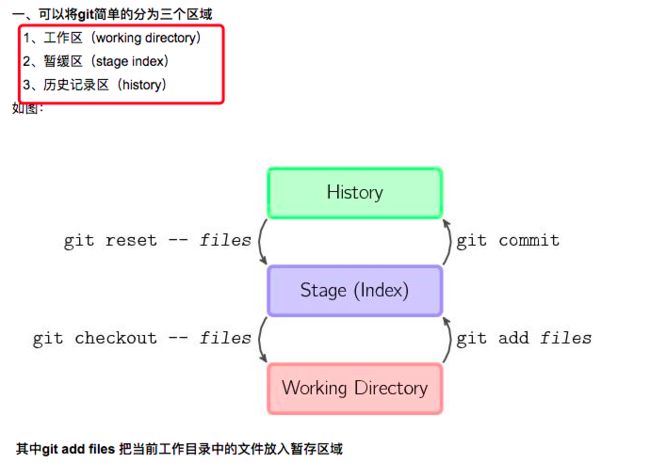
3)三棵树的更详细的命令示意图
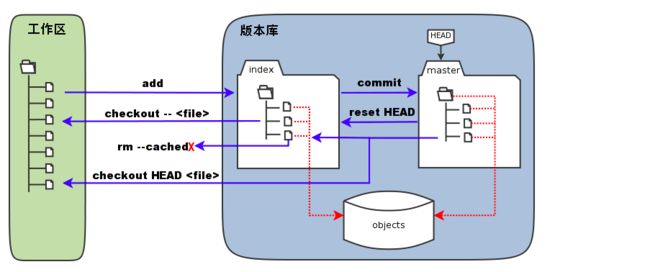
git commit的时候,只是提交的 缓存区内的内容(如果你git add过,否则也等同你本地工作区内容的提交)
== git add可以实现我之前在 云主机上保存临时文件的tmpdjp的操作
==git diff 对比的是工作区和 缓存区的区别
==git diff --cached 对比是 缓冲区和本地的 head版本库的对比
另外需要指出来的是 git stash 不在上面的“三颗树”里,git stash 是暂存区,区别于 缓存区“stage”
git stash的用法见 https://www.cnblogs.com/tocy/p/git-stash-reference.html
四、写在最后
简单的摘录,见仁见智,希望喜欢Java开发的同学能从中收益。
欢迎关注我的微信公众号哈 “ 程序员的文娱情怀” http://t.cn/RotyZtu ?
