什么是ELK STACK
ELK Stack是Elasticserach、Logstash、Kibana三种工具组合而成的一个日志解决方案。ELK可以将我们的系统日志、访问日志、运行日志、错误日志等进行统一收集、存储分析和搜索以及图形展现。相比传统的CTRL+F或者数据库语句来进行数据查询,ELK支持分布式搜搜,数据量可达PB级别,检索速度更快速,接近实时处理,并且更智能,可以去掉一些没有特殊含义的词汇,比如“这,的,是”,还可以进行搜索补全与搜索纠错。
LogStash:
负责日志的收集,并且可以输出到指定位置,如Redis、kafka、以及最主要的ElasticSearch中,通常会在所有需要收集日志的服务器上安装Logstash,然后由Logstash agent端发送到Logstash的Server端
ElasticSearch:
使用JAVA开发、基于Lucene搜索引擎库的全文搜索工具,通过RESTful API(一种接口设计规范,让接口更易懂)隐藏了Lucene原本的复杂性。实现了日志数据的分布式、实时分析,并且可以进行搜索补全与纠错等功能,是ELK最核心的组件。相比MySQL库和表的概念,在ES中把库叫做索引。
Kibana:
负责数据的展示与统计,是一个图形化的管理系统。
下面一一介绍这几个系统的安装搭建。
一、安装Elasticsearch:
1、ElasticSearch默认工作在集群模式下,扩展性很强,并且支持自动发现。所以在实验环境中需要至少2台服务器来搭建,但是为了防止脑裂,建立使用基数台服务器。在部署ElasticSearch前需要先部署JAVA环境,所以第一步是安装JDK,这里偷懒使用yum安装了openjdk,生产环境还是建议用JDK的源码包(暂时不支持JDK 9)。
1 yum install java-1.8.0-openjdk.x86_64
2、下载ElasticSearch,官网地址是www.elastic.co(不是com),其每个Products下都有专门的文档用于参考。
下载tar包解压,然后进入config目录,该目录下除了有一个主配置文件elasticsearch.yml需要配置外,还有一个jvm.options文件用于JVM的调优
1 tar zxf elasticsearch-6.3.tar.gz 2 3 cd elasticsearch-6.3/config
jvm.options文件主要是JVM优化相关,关于垃圾回收这块使用默认配置就可以了,我们要调整的就是最大内存和最小内存的设置。通常设置为一样大小,具体的值可以设置为系统最大内存的一半或三分之二
1 -Xms1g #程序启动时占用内存的大小 2 3 -Xmx1g #程序启动后最大可占用内存的大小
3、修改ElasticSearch的配置,编辑elasticsearch.yml
1 cluster.name: my-application #集群名称,相同集群名称的节点会自动加入到该集群 2 3 node.name: r1 #节点名称,两个节点不能重复 4 5 path.data: /path/to/data #指定数据存储目录 6 7 path.logs: /path/to/logs #指定日志存储目录 8 9 network.host: 0.0.0.0 #本机地址或者4个0 10 11 http.port: 9200 #指定端口 12 13 discovery.zen.ping.unicast.hosts: ["192.168.44.130"] #集群中master节点初始化列表,通过列表中的机器来自动发现其他节点
3、运行bin/elasticsearch 启动服务(加-d是在后台运行)。启动后服务会监听在9200端口,还有个9300端口用于集群间通信。如果配置文件中监听的端口是外网地址,在运行Elasticsearch时会遇到一些内核报错,具体报错和解决方法如下(做好配置后,需要注销用户重新登录才会生效):
(1)don't run elasticsearch as root:
解决办法:Elasticsearch是不允许使用root用户来运行的,所以需要把ElasticSearch目录所有者修改为其他用户,并切换到该用户去执行。用浏览器打开能看到如下信息代表安装成功:

(2)Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c5330000, 986513408, 0) failed; error='Cannot allocate memory' (errno=12):
解决办法:内存不足,升级内存
(3)Exception in thread "main" java.nio.file.AccessDeniedException
解决办法:运行Elasticsearch程序的用户权限不够,把Elasticsearch目录权限修改下即可
(4)max virtual memory areas vm.max_map_count [65530] is too low
解决办法:修改/etc/sysctl.conf,增加一行vm.max_map_count= 262144。然后执行sysctl -p使其生效
(5)max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536]
解决办法:修改/etc/security/limits.conf,做以下配置
1 * soft nproc 65536 2 * hard nproc 65536 3 * soft nofile 65536 4 * hard nofile 65536
(6)max number of threads [3812] for user [elkuser] is too low, increase to at least [4096]
解决办法:修改/etc/security/limits.d/20-nproc.conf,做以下配置
1 * soft nproc 4096 2 * hard nproc 4096
Elasticsearch接口说明:
ES启动后如何验证节点是否在集群中呢?ES是使用RESTful形式的接口对外提供访问,所以我们要访问ES接口的话可以使用curl命令。ES有四类API,作用大概如下:
1、用来检查集群节点、索引当前状态
2、管理集群节点、索引及元数据
3、执行增删改查操作
4、执行高级操作,例如paging,filtering
Elasticsearch 常用API有cat、cluster等,下面是一些简单介绍:
通过curl可以看到cat这个API下有很多子功能
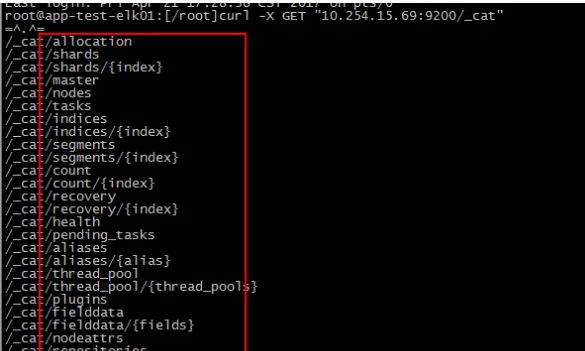
1、Elasticsearch集群健康检查:
通过cat、cluster两个API都可以进行集群健康检查,green代表集群完全正常;yellow代表集群正常,部分副本分片不正常;red代表集群故障,数据可能会丢失
1 http://localhost:9200/_cat/health 2 3 http://localhost:9200/_cat/health?v #显示信息更详尽 4 5 http://localhost:9200/_cluster/health 6 7 http://localhost:9200/_cluster/health?pretty(加上pretty会将内容格式化再输出,更美观)
2、查询所有节点列表
1 http://localhost:9200/_cat/nodes?v
3、查询所有索引
1 http://localhost:9200/_cat/indices?v
curl命令在Elasticsearch中的使用
使用curl可以通过模拟http请求的方式去创建和管理索引,常用选项如下:
-X:指定http的请求方法,如HEAD,POST,PUT,DELETE
-d:指定要传输的数据
-H:指定http请求头信息
1、使用curl新增索引
1 curl -XPUT "localhost:9200/blog_test?pretty" #新增一个blog_test索引
2、删除索引
1 curl -X DELETE "localhost:9200/bolg_test?pretty"
3、查询创建的索引
1 http://localhost:9200/_cat/indices?v
下面是更贴近实际操作的curl命令,插入了两条数据
1 #为blog索引新增两条记录,指定type为article,ID为2和3 2 3 curl -XPUT -H "Content-Type: application/json" 'localhost:9201/blog/article/2?pretty' -d ' 4 5 { 6 7 "title": "test", 8 9 "content":"testsfsdfdsfdsf", 10 11 "PV":10 12 13 }' 14 15 16 17 curl -XPUT -H "Content-Type: application/json" 'localhost:9201/blog/article/3?pretty' -d ' 18 19 { 20 21 "title": "test", 22 23 "content":"testsfsdfdsfdsf", 24 25 "PV":23 26 27 }'
查询索引和数据搜索
1 #通过ID来查询 2 3 curl -XGET 'localhost:9200/blog/article/2?pretty' 4 5 #指定具体的索引和type进行搜索 6 7 curl -XGET 'http://localhost:9200/blog/article/_search?q=title:test'
二、Logstash安装步骤
1、下载Logstash 6.3
依然是在ELK的官方网站www.elastic.co,本文以源码包形式进行Logstash的安装。其实Logstash的安装很简单,只要保证JDK正常运行(目前只支持JDK8),然后直接解压Logstash即可。这里我们解压到了/usr/local/logstash下,并且建立一个软连接
1 tar zxf logstash-6.3.tar.gz 2 3 mv logstash-6.3 /usr/local/ 4 5 ln -s logstash-6.3.logstash
2、配置与命令行启动Logstash
在Logstash目录下有很多子目录,但是大多数是不用去关注和修改的(仅有2个配置文件可能需要略微修改,一个是config/logstash.yml,可能需要修改启动进程数以及日志信息;一个是jvm.options,这个和Elasticsearch是一样的,主要是优化内存)。bin目录下有启动服务需要的脚本,现在可以用命令行来启动Logstash测试是否正常(运行后多等一会儿才有反应):
1 cd logstash-6.3 2 3 bin/logstash -e 'input{ stdin{} } output{ stdout{} }' #-e选项是直接用命令行模式,采用标准输入,标准输出 4 5 Settings: Default pipeline workers: 1 6 7 Pipeline main started 8 9 hello world #这里手动输入的hello world,作为标准输入 10 11 2016-05-19T01:59:03.797Z 0.0.0.0 hello world #标准输出的结果显示在屏幕 12 13 nihao 14 15 2016-05-19T02:00:20.013Z 0.0.0.0 nihao
使用codec指定输出格式(codec是一种解码编码的工具)
1 [root@server bin]# ./logstash -e 'input{ stdin{} } output{ stdout{codec => rubydebug} }' # -e选项是直接用命令行模式,输入采用标准输入,输出采用的codec风格 2 3 Settings: Default pipeline workers: 1 4 5 Pipeline main started 6 7 hello world 8 9 { 10 11 "message" => "hello world", #输入的内容 12 13 "@version" => "1", #版本号 14 15 "@timestamp" => "2016-05-19T02:09:43.921Z", #自动生成时间戳 16 17 "host" => "0.0.0.0" #数据是由哪个节点发过来的
3、自定义Logstash配置文件
生产环境中需要用到的规则更为复杂,使用命令行显然不可取。所以可以自定义规则文件,然后让Logstash根据规则进行工作。下面是通过配置文件指定Logstash的数据输入输出的示例,配置文件里主要是写明input、output规则,filter规则是需要过滤内容时才会有:
1 input{ 2 3 stdin {} 4 5 } 6 7 8 9 output{ 10 11 stdout{ 12 13 codec => rubydebug 14 15 } 16 17 }
启动服务时加上-t选项可以检查配置文件是否正确,-f选项就是配置文件的路径
1 logstash -t -f /etc/logstash.conf
启动成功后会看到Pipeline main started这样的信息出来,这个时候我们就可以输入信息给Logstash了,我们输入的信息会通过标准输出显示到屏幕上,如图:

在Logstash中输入的数据我们可以通过日志文件来获取,当然输出的数据我们也可以指定到自己需要的容器中,如Elasticsearch里。要通过日志文件来获取输入信息的话就需要用到最常用的input插件——file(官方文档里有详细介绍每个input插件的使用方式,output插件同理)。下面是一个使用file插件的简单案例,由于output依然是标准输出,所以会有疯狂刷屏的情况出现:
1 vi etc/logstash.conf 2 3 input { 4 5 file { 6 7 path => [ "/var/log/secure" ] #文件路径 8 9 type => "system" #类似打个标记,自定义 10 11 start_position => "beginning" #从文件头部读取,相反还有end 12 13 } 14 15 } 16 17 18 output { 19 20 stdout { 21 22 codec => rubydebug 23 24 } 25 26 }
file插件使用了一个sincedb文件来记录当前文件读区位置,即使重新启动服务也不会丢失文件的读取位置。默认情况下sincedb文件放在运行Logstash的用户的主目录中,可以用sincedb_path选项自定义存放路径。
总结:在实际工作中Logstash数据收集的一个流程大概是:数据源→通过input插件(如file、redis、stdin)→output插件→写到Elasticsearch。在官网文档中可以看到有很多其他input插件,如图:
下面看看如何将Logstash收集到的数据提交给Elasticsearch。这里需要使用一个output插件——elasticsearch。使用方法也很简单,只需要在配置文件里指定插件就可以了,如下:
1 [root@server ~]# cat /etc/logstash.conf 2 3 input{ 4 5 file{ 6 7 path=> "/var/log/audit/audit.log" 8 9 type=> "system" 10 11 start_position=> "beginning" 12 13 } 14 15 } 16 17 output{ 18 19 elasticsearch{ #输出到es 20 21 hosts=> ["192.168.44.129:9200","192.168.44.130:9200"] 22 23 } 24 25 }
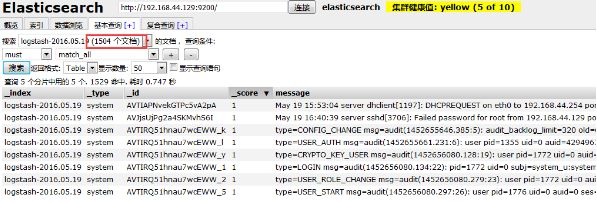
文件设置好了后运行logstash的程序,再到Elasticsearch就可以查看到数据了
1 [root@server ~]# /usr/local/logstash/bin/logstash -f /etc/logstash.conf
在生产环境中启动Logstash都是放后台运行,我们可以一次运行多个程序,因为Logstash不会占用端口,加-w选项可以启动多个线程,提高效率,默认是2,例:
1 nohup /logstash/bin/logstash agent -f /logstash/conf/indexer-xire.conf -w 4 &
三、Kibana安装步骤
继Elasticsearch和Logstash之后,轮到了Kibana。Kibana是为Elasticsearch提供的可视化平台,负责数据的美观展示。Kibana的安装和Logstash一样极其简单,而且不需要在每个客户端都安装,通常想让哪台服务器作为展示就用哪台安装一个kibana,Kibana是从Elasticsearch中获取数据的,即使安装在Elasticsearch集群之外的节点也是没有问题的。
1 tar zxf kibana-6.3-linux-x64.tar.gz 2 3 mv kibana-6.3-linux-x64 /usr/local/ 4 5 ln -s /usr/local/kibana-6.3-linux-x64 /usr/local/kibana
配置很简单,修改配置文件config/kibana.yml里的以下信息即可:
1 vi config/kibana.yml 2 3 server.port: 5601 #服务端口 4 5 server.host: "0.0.0.0" #修改为本机地址 6 7 elasticsearch.url: "http://192.168.44.129:9200" #ES的地址与端口 8 9 kibana.index: ".kibana"
运行bin/kibana可以直接启动服务,但是通常是放后台运行,所以加上nohup吧(从2.x到6.x都是这个方式)
1 nohup kibana &
Kibana服务默认监控在5601端口,浏览器访问http://IP:5601可以打开Kibana的界面(不要用IE内核访问)。第一次访问Kibana会提示配置索引,输入在ES中存在的索引名字后Kibana会自动进行正则匹配(通常用Logstash发送的数据索引名是以logstash打头,用filebeat就是filebeat打头,当然也可以在Logstash配置文件的output段使用index选项自定义索引)
1 output { 2 3 elasticsearh { 4 5 hosts => ["http://127.0.0.1:9200"] 6 7 index => "nginx-%{+YYYY.MM.dd}" 8 9 } 10 11 }

左侧导航栏有很多选项,Discover用于和Elasticsearch交互和展示搜索结果;Visualize用于报表生成,比如有一个银行系统,里面有很多用户,现在想统计每个存钱区间的人数,存款在1万以下有多少人,5万以下有多少人等,用这个报表系统就可以方便的进行操作。

右上角有个时间过滤器,默认是logstash索引最后15分钟的数据,没有的话就会显示No results found。点击过滤器后可以在左侧选择过滤条件,分为了快速查找(Quick)、相对时间(Relative)、绝对时间(Absolute)。

在中间部分有绿色的直方图,点击绿色区域会跳转到对应时间的数据,并且显示该时间内产生了多少数据,如图:

在页面左侧可以选择索引以及字段:

通过kibana进行全文搜索也很简单,只需要在搜索框里输入关键词,然后就会自动把匹配的日志给展示出来:
Kibana的监控页
和Nginx一样,Kibana也有一个监控页用于查看服务器当前状况,当然在生产中最好也使用Nginx做好权限审核,不要让任何人都可以登录,Kibana监控页访问地址是http://URL/status!

至此一个高效多功能的日志系统就初步完成了。