正题开始:
这篇文章是入门级的特征处理的打包解决方案的python实现汇总,如果想get一些新鲜血液的朋友可以叉了,只是方便玩数据的人进行数据特征筛选的代码集合,话不多说,让我们开始。
首先,让我们看一张入门级别的数据预处理的基本操作图,网上有很多版本,这个是我自己日常干活的时候必操作的行为罗列,其中数据整理部分已经在上一篇文章中给出了,下面我们讲一起来看看特征筛选这块。此图请尊重一下我,别拿出去传播,纯属个人的方法论,大家看看就行,谢谢。网上有其他版本的,你们去传播那些就ok了~

方差选择法
def var_filter(data, k=None):
var_data = data.var().sort_values()
if k is not None:
new_data = VarianceThreshold(threshold=k).fit_transform(data)
return var_data, new_data
else:
return var_data
这个方法的思路很明确,我们筛掉方差过小的feature,也很好理解,一列值完全或者几乎完全一致的feature对于我们去训练最后的模型没有任何好处。熵理论也同样印证了这一点。
线性相关系数衡量
def pearson_value(data, label, k=None):
label = str(label)
# k为想删除的feature个数
Y = data[label]
x = data[[x for x in data.columns if x != label]]
res = []
for i in range(x.shape[1]):
data_res = np.c_[Y, x.iloc[:, i]].T
cor_value = np.abs(np.corrcoef(data_res)[0, 1])
res.append([label, x.columns[i], cor_value])
res = sorted(np.array(res), key=lambda x: x[2])
if k is not None:
if k < len(res):
new_c = [] # 保留的feature
for i in range(len(res) - k):
new_c.append(res[i][1])
return res, new_c
else:
print('feature个数越界~')
else:
return res
当你明确了自变量与因变量之间存在线性关系的时候,你就需要剔除掉一些关心比较弱的变量,奥卡姆剃刀原理告诉我们,在尽可能压缩feature个数大小的情况下去得到效果最优的模型才是合理模型。
共线性检验
def vif_test(data, label, k=None):
label = str(label)
# k为想删除的feature个数
x = data[[x for x in data.columns if x != label]]
res = np.abs(np.corrcoef(x.T))
vif_value = []
for i in range(res.shape[0]):
for j in range(res.shape[0]):
if j > I:
vif_value.append([x.columns[i], x.columns[j], res[i, j]])
vif_value = sorted(vif_value, key=lambda x: x[2])
if k is not None:
if k < len(vif_value):
new_c = [] # 保留的feature
for i in range(len(x)):
if vif_value[-i][1] not in new_c:
new_c.append(vif_value[-i][1])
else:
new_c.append(vif_value[-i][0])
if len(new_c) == k:
break
out = [x for x in x.columns if x not in new_c]
return vif_value, out
else:
print('feature个数越界~')
else:
return vif_value
2-3年前面试必考题,什么叫做共线性?如何解决共线性?答案之一就是共线性检验啊,判断feature之间的相关性,剔除相关性较高的feature,在R语言里面有个VIF函数可以直接求的。除此之外,采用非线性函数做特征拆解也是很好的方法。共线性严重的情况下,会导致泛化误差异常大,需着重注意~
Mutual Information互信息
def MI(X, Y):
# len(X) should be equal to len(Y)
# X,Y should be the class feature
total = len(X)
X_set = set(X)
Y_set = set(Y)
if len(X_set) > 10:
print('%s非分类变量,请检查后再输入' % X_set)
sys.exit()
elif len(Y_set) > 10:
print('%s非分类变量,请检查后再输入' % Y_set)
sys.exit()
# Mutual information
MI = 0
eps = 1.4e-45
for i in X_set:
for j in Y_set:
indexi = np.where(X == i)
indexj = np.where(Y == j)
ijinter = np.intersect1d(indexi, indexj)
px = 1.0 * len(indexi[0]) / total
py = 1.0 * len(indexj[0]) / total
pxy = 1.0 * len(ijinter) / total
MI = MI + pxy * np.log2(pxy / (px * py) + eps)
return MI
def mic_entroy(data, label, k=None):
# mic_value值越小,两者相关性越弱
label = str(label)
# k为想删除的feature个数
x = data[[x for x in data.columns if x != label]]
Y = data[label]
mic_value = []
for i in range(x.shape[1]):
if len(set(x.iloc[:, i])) <= 10:
res = MI(Y, x.iloc[:, I])
mic_value.append([x.columns[i], res])
mic_value = sorted(mic_value, key=lambda x: x[1])
return mic_value
本来我想偷懒,直接import minepy然后就得了,发现真的是特么难装,各种报错,一怒之下自己写了,这边求大佬告知,为什么pip install minepy会有这样的问题:
xcrun: error: invalid active developer path (/Library/Developer/CommandLineTools), missing xcrun at: /Library/Developer/CommandLineTools/usr/bin/xcrun
error: command '/usr/bin/clang' failed with exit status 1
----------------------------------------
Command "/Users/slade/anaconda3/bin/python -u -c "
import setuptools, tokenize;__file__='/private/var/folders/hv/kfb7n4lj06590hqxjv6f3dd00000gn/T/pip-build-hr9ej0lw/minepy/setup.py';
f=getattr(tokenize, 'open', open)(__file__);
code=f.read().replace('\r\n', '\n');f.close();
exec(compile(code, __file__, 'exec'))" install --record /var/folders/hv/kfb7n4lj06590hqxjv6f3dd00000gn/T/pip-30cn7rbs-record/install-record.txt --single-version-externally-managed --compile" failed with error code 1 in /private/var/folders/hv/kfb7n4lj06590hqxjv6f3dd00000gn/T/pip-build-hr9ej0lw/minepy/
回到正题,互信息其实很简单,我们看个公式I(X;Y)=H(X)-H(X|Y),看完是不是超级清晰了,其实就是X发生的概率中去掉Y发生后X发生的概率,或者说是一个随机变量由于已知另一个随机变量而减少的不肯定性。
计算公式如下,你们也可以在上面的代码里找到影子。
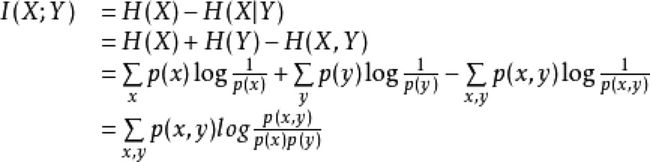
最后还是吐槽下,这个minepy太难装了,为了个互信息,不至于不至于~
递归特征消除法
def wrapper_way(data, label, k=3):
# k 为要保留的数据feature个数
label = str(label)
label_data = data[label]
col = [x for x in data.columns if x != label]
train_data = data[col]
res = pd.DataFrame(
RFE(estimator=LogisticRegression(), n_features_to_select=k).fit_transform(train_data, label_data))
res_c = []
for i in range(res.shape[1]):
for j in range(data.shape[1]):
if (res.iloc[:, i] - data.iloc[:, j]).sum() == 0:
res_c.append(data.columns[j])
res.columns = res_c
return res
这边开始的代码就基本上是方法梳理了,没啥亮点,我就大概和大家聊聊,递归特征消除法,用R语言里面的step()函数是一毛一样的东西,都是循环sample特征,选一个对于当前模型,特征组合最好的结果。如果数据量大,你会有非一般的感觉,这边就有小trick了,以后有空可以和大家分享~
l1/l2正则方法
def embedded_way(data, label, way='l2', C_0=0.1):
label = str(label)
label_data = data[label]
col = [x for x in data.columns if x != label]
train_data = data[col]
res = pd.DataFrame(SelectFromModel(LogisticRegression(penalty=way, C=C_0)).fit_transform(train_data, label_data))
res_c = []
for i in range(res.shape[1]):
for j in range(data.shape[1]):
if (res.iloc[:, i] - data.iloc[:, j]).sum() == 0:
res_c.append(data.columns[j])
res.columns = res_c
return res
正则理论参考:总结:常见算法工程师面试题目整理(二),这边要提一点,并不是所有情况下都需要正则预处理的,很多算法自带正则,比如logistic啊,比如我们自己去写tensorflow神经网络啊,模型会针对性的解决问题,而这边单纯用的logstic方法来筛选,相对而言内嵌的效果会更好的。
基于树模型特征选择
def tree_way(data,label):
label = str(label)
label_data = data[label]
col = [x for x in data.columns if x != label]
train_data = data[col]
res = pd.DataFrame(SelectFromModel(GradientBoostingClassifier()).fit_transform(train_data, label_data))
res_c = []
for i in range(res.shape[1]):
for j in range(data.shape[1]):
if (res.iloc[:, i] - data.iloc[:, j]).sum() == 0:
res_c.append(data.columns[j])
res.columns = res_c
return res
这边用的是决策树每次分支下,如果改变一列值为随机值,观察对整体数据效果的影响。举个通俗易懂的例子,看看你在公司的重要性,就去和你老板提离职,要是老板疯狂给你加工资做你的思想工作,代表你很重要;如果你的老板让你去财务结账,代表你没啥意义。这里你就是这个feature,你老板就是数据效果的检验指标,常见的就是oob之类的。
这边facebook有个非常好的拓展的思路,但是大家都吹的多实际应用很少,我最近在搞这事情,等下更完这边的特征工程和下面一个nlp的case后,我想专门聊聊这个事情,用的就是决策树的另一角度,以叶子结点代替原feature,做到了非线性的特征融入线性模型,虽然很老套,但是我稍稍做了测试,效果斐然:

最后的最后,感谢大家阅读,希望能够给大家带来收获,谢谢~
欢迎大家关注我的个人bolg,更多代码内容欢迎follow我的个人Github,如果有任何算法、代码疑问都欢迎通过公众号发消息给我哦。
