xxl-job
系统说明
安装
安装部署参考文档:分布式任务调度平台xxl-job
功能
定时调度、服务解耦、灵活控制跑批时间(停止、开启、重新设定时间、手动触发)
XXL-JOB是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用
概念
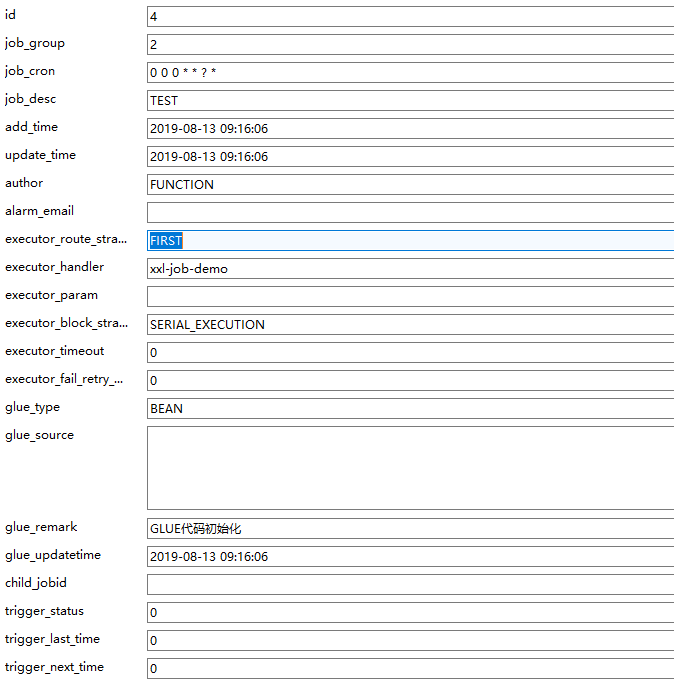
执行器列表:一个执行器是一个项目
任务:一个任务是一个项目中的 JobHandler
一个xxl-job服务可以有多个执行器(项目),一个项目下可以有多个任务(JobHandler),他们是如何关联的?
页面操作:
- 在管理平台可以新增执行器(项目)
- 在任务列表可以指定执行器(项目)下新增多个任务(JobHandler)
代码操作:
- 项目配置中增加 xxl.job.executor.appname = "执行器名称"
- 在实现类中增加 @JobHandler(value="xxl-job-demo") 注解,并继承 IJobHandler
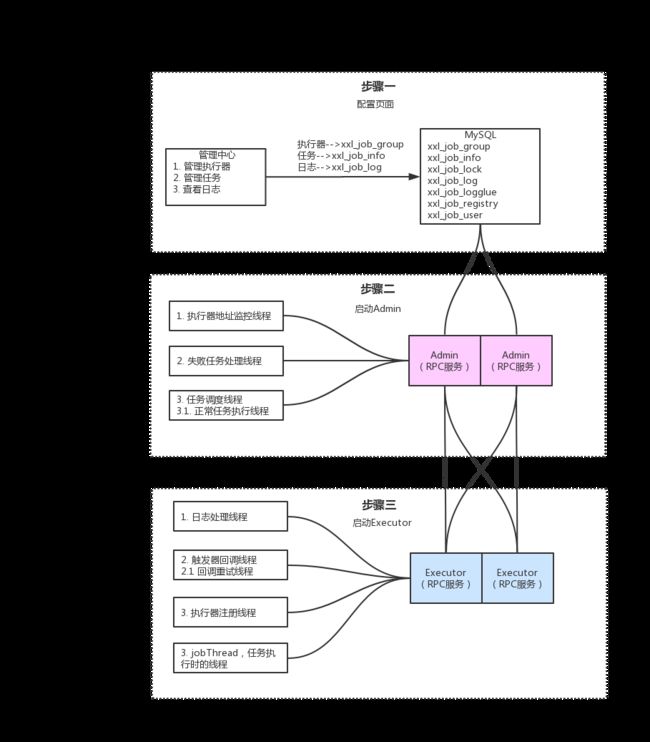
架构图

抛出疑问
- 调度中心启动过程?
- 执行器启动过程?
- 执行器如何注册到调度中心?
- 调度中心怎么调用执行器?
- 集群调度时如何控制一个任务在该时刻不会重复执行
- 集群部署应该注意什么?
系统分析
执行器依赖jar包
com.xuxueli:xxl-job-core:2.1.0
com.xuxueli:xxl-registry-client:1.0.2
com.xuxueli:xxl-rpc-core:1.4.1
调度中心启动过程
// 1. 加载 XxlJobAdminConfig,adminConfig = this
XxlJobAdminConfig.java
// 启动过程代码
@Component
public class XxlJobScheduler implements InitializingBean, DisposableBean {
private static final Logger logger = LoggerFactory.getLogger(XxlJobScheduler.class);
@Override
public void afterPropertiesSet() throws Exception {
// init i18n
initI18n();
// admin registry monitor run
// 2. 启动注册监控器(将注册到register表中的IP加载到group表)/ 30执行一次
JobRegistryMonitorHelper.getInstance().start();
// admin monitor run
// 3. 启动失败日志监控器(失败重试,失败邮件发送)
JobFailMonitorHelper.getInstance().start();
// admin-server
// 4. 初始化RPC服务
initRpcProvider();
// start-schedule
// 5. 启动定时任务调度器(执行任务,缓存任务)
JobScheduleHelper.getInstance().start();
logger.info(">>>>>>>>> init xxl-job admin success.");
}
......
}执行器启动过程
@Override
public void start() throws Exception {
// init JobHandler Repository
// 将执行 JobHandler 注册到缓存中 jobHandlerRepository(ConcurrentMap)
initJobHandlerRepository(applicationContext);
// refresh GlueFactory
// 刷新GLUE
GlueFactory.refreshInstance(1);
// super start
// 核心启动项
super.start();
}
public void start() throws Exception {
// 初始化日志路径
// private static String logBasePath = "/data/applogs/xxl-job/jobhandler";
XxlJobFileAppender.initLogPath(this.logPath);
// 初始化注册中心列表 (把注册地址放到 List)
this.initAdminBizList(this.adminAddresses, this.accessToken);
// 启动日志文件清理线程 (一天清理一次)
// 每天清理一次过期日志,配置参数必须大于3才有效
JobLogFileCleanThread.getInstance().start((long)this.logRetentionDays);
// 开启触发器回调线程
TriggerCallbackThread.getInstance().start();
// 指定端口
this.port = this.port > 0 ? this.port : NetUtil.findAvailablePort(9999);
// 指定IP
this.ip = this.ip != null && this.ip.trim().length() > 0 ? this.ip : IpUtil.getIp();
// 初始化RPC 将执行器注册到调度中心 30秒一次
this.initRpcProvider(this.ip, this.port, this.appName, this.accessToken);
}执行器注册到调度中心
执行器
// 注册执行器入口
XxlJobExecutor.java->initRpcProvider()->xxlRpcProviderFactory.start();
// 开启注册
XxlRpcProviderFactory.java->start();
// 执行注册
ExecutorRegistryThread.java->start();
// RPC 注册代码
for (AdminBiz adminBiz: XxlJobExecutor.getAdminBizList()) {
try {
ReturnT registryResult = adminBiz.registry(registryParam);
if (registryResult!=null && ReturnT.SUCCESS_CODE == registryResult.getCode()) {
registryResult = ReturnT.SUCCESS;
logger.debug(">>>>>>>>>>> xxl-job registry success, registryParam:{}, registryResult:{}", new Object[]{registryParam, registryResult});
break;
} else {
logger.info(">>>>>>>>>>> xxl-job registry fail, registryParam:{}, registryResult:{}", new Object[]{registryParam, registryResult});
}
} catch (Exception e) {
logger.info(">>>>>>>>>>> xxl-job registry error, registryParam:{}", registryParam, e);
}
} 调度中心
// RPC 注册服务
AdminBizImpl.java->registry();数据库

调度中心调用执行器
/* 调度中心执行步骤 */
// 1. 调用执行器
XxlJobTrigger.java->runExecutor();
// 2. 获取执行器
XxlJobScheduler.java->getExecutorBiz();
// 3. 调用
ExecutorBizImpl.java->run();
/* 执行器执行步骤 */
// 1. 执行器接口
ExecutorBiz.java->run();
// 2. 执行器实现
ExecutorBizImpl.java->run();
// 3. 把jobInfo 从 jobThreadRepository (ConcurrentMap) 中获取一个新线程,并开启新线程
XxlJobExecutor.java->registJobThread();
// 4. 保存到当前线程队列
JobThread.java->pushTriggerQueue();
// 5. 执行
JobThread.java->handler.execute(triggerParam.getExecutorParams());调度中心(Admin)
实现 org.springframework.beans.factory.InitializingBean类,重写 afterPropertiesSet 方法,在初始化bean的时候都会执行该方法
DisposableBean spring停止时执行
结束加载项
- 停止定时任务调度器(中断scheduleThread,中断ringThread)
- 停止触发线程池(JobTriggerPoolHelper)
- 停止注册监控器(registryThread)
- 停止失败日志监控器(monitorThread)
- 停止RPC服务(stopRpcProvider)
手动执行方式
JobInfoController.java
@RequestMapping("/trigger")
@ResponseBody
//@PermissionLimit(limit = false)
public ReturnT triggerJob(int id, String executorParam) {
// force cover job param
if (executorParam == null) {
executorParam = "";
}
JobTriggerPoolHelper.trigger(id, TriggerTypeEnum.MANUAL, -1, null, executorParam);
return ReturnT.SUCCESS;
} 定时调度策略
调度策略执行图

调度策略源码
JobScheduleHelper.java->start();路由策略
第一个
固定选择第一个机器
ExecutorRouteFirst.java->route();最后一个
固定选择最后一个机器
ExecutorRouteLast.java->route();轮询
随机选择在线的机器
ExecutorRouteRound.java->route();
private static int count(int jobId) {
// cache clear
if (System.currentTimeMillis() > CACHE_VALID_TIME) {
routeCountEachJob.clear();
CACHE_VALID_TIME = System.currentTimeMillis() + 1000*60*60*24;
}
// count++
Integer count = routeCountEachJob.get(jobId);
count = (count==null || count>1000000)?(new Random().nextInt(100)):++count; // 初始化时主动Random一次,缓解首次压力
routeCountEachJob.put(jobId, count);
return count;
}随机
随机获取地址列表中的一个
ExecutorRouteRandom.java->route();一致性HASH
一个job通过hash算法固定使用一台机器,且所有任务均匀散列在不同机器
ExecutorRouteConsistentHash.java->route();
public String hashJob(int jobId, List addressList) {
// ------A1------A2-------A3------
// -----------J1------------------
TreeMap addressRing = new TreeMap();
for (String address: addressList) {
for (int i = 0; i < VIRTUAL_NODE_NUM; i++) {
long addressHash = hash("SHARD-" + address + "-NODE-" + i);
addressRing.put(addressHash, address);
}
}
long jobHash = hash(String.valueOf(jobId));
// 取出键值 >= jobHash
SortedMap lastRing = addressRing.tailMap(jobHash);
if (!lastRing.isEmpty()) {
return lastRing.get(lastRing.firstKey());
}
return addressRing.firstEntry().getValue();
} 最不经常使用
使用频率最低的机器优先被选举
把地址列表加入到内存中,等下次执行时剔除无效的地址,判断地址列表中执行次数最少的地址取出
频率、次数
ExecutorRouteLFU.java->route();
public String route(int jobId, List addressList) {
// cache clear
if (System.currentTimeMillis() > CACHE_VALID_TIME) {
jobLfuMap.clear();
CACHE_VALID_TIME = System.currentTimeMillis() + 1000*60*60*24;
}
// lfu item init
HashMap lfuItemMap = jobLfuMap.get(jobId); // Key排序可以用TreeMap+构造入参Compare;Value排序暂时只能通过ArrayList;
if (lfuItemMap == null) {
lfuItemMap = new HashMap();
jobLfuMap.putIfAbsent(jobId, lfuItemMap); // 避免重复覆盖
}
// put new
for (String address: addressList) {
if (!lfuItemMap.containsKey(address) || lfuItemMap.get(address) >1000000 ) {
// 0-n随机数,包括0不包括n
lfuItemMap.put(address, new Random().nextInt(addressList.size())); // 初始化时主动Random一次,缓解首次压力
}
}
// remove old
List delKeys = new ArrayList<>();
for (String existKey: lfuItemMap.keySet()) {
if (!addressList.contains(existKey)) {
delKeys.add(existKey);
}
}
if (delKeys.size() > 0) {
for (String delKey: delKeys) {
lfuItemMap.remove(delKey);
}
}
/*********************** 优化 START ***********************/
// 优化 remove old部分
Iterator iterable = lfuItemMap.keySet().iterator();
while (iterable.hasNext()) {
String address = iterable.next();
if (!addressList.contains(address)) {
iterable.remove();
}
}
/*********************** 优化 START ***********************/
// load least userd count address
// 从小到大排序
List> lfuItemList = new ArrayList>(lfuItemMap.entrySet());
Collections.sort(lfuItemList, new Comparator>() {
@Override
public int compare(Map.Entry o1, Map.Entry o2) {
return o1.getValue().compareTo(o2.getValue());
}
});
Map.Entry addressItem = lfuItemList.get(0);
String minAddress = addressItem.getKey();
addressItem.setValue(addressItem.getValue() + 1);
return addressItem.getKey();
} 最近最久未使用
最久未使用的机器优先被选举
用链表的方式存储地址,第一个地址使用后下次该任务过来使用第二个地址,依次类推(PS:有点类似轮询策略)
与轮询策略的区别:
- 轮询策略是第一次随机找一台机器执行,后续执行会将索引加1取余
- 轮询策略依赖 addressList 的顺序,如果这个顺序变了,索引到下一次的机器可能不是期望的顺序
- LRU算法第一次执行会把所有地址加载进来并缓存,从第一个地址开始执行,即使 addressList 地址顺序变了也不影响
次数
ExecutorRouteLRU.java->route();
public String route(int jobId, List addressList) {
// cache clear
if (System.currentTimeMillis() > CACHE_VALID_TIME) {
jobLRUMap.clear();
CACHE_VALID_TIME = System.currentTimeMillis() + 1000*60*60*24;
}
// init lru
LinkedHashMap lruItem = jobLRUMap.get(jobId);
if (lruItem == null) {
/**
* LinkedHashMap
* a、accessOrder:ture=访问顺序排序(get/put时排序);false=插入顺序排期;
* b、removeEldestEntry:新增元素时将会调用,返回true时会删除最老元素;可封装LinkedHashMap并重写该方法,比如定义最大容量,超出是返回true即可实现固定长度的LRU算法;
*/
lruItem = new LinkedHashMap(16, 0.75f, true);
jobLRUMap.putIfAbsent(jobId, lruItem);
}
/*********************** 举个例子 START ***********************/
// 如果accessOrder为true的话,则会把访问过的元素放在链表后面,放置顺序是访问的顺序
// 如果accessOrder为flase的话,则按插入顺序来遍历
LinkedHashMap lruItem = new LinkedHashMap(16, 0.75f, true);
jobLRUMap.putIfAbsent(1, lruItem);
lruItem.put("192.168.0.1", "192.168.0.1");
lruItem.put("192.168.0.2", "192.168.0.2");
lruItem.put("192.168.0.3", "192.168.0.3");
String eldestKey = lruItem.entrySet().iterator().next().getKey();
String eldestValue = lruItem.get(eldestKey);
System.out.println(eldestValue + ": " + lruItem);
eldestKey = lruItem.entrySet().iterator().next().getKey();
eldestValue = lruItem.get(eldestKey);
System.out.println(eldestValue + ": " + lruItem);
// 输出结果:
192.168.0.1: {192.168.0.2=192.168.0.2, 192.168.0.3=192.168.0.3, 192.168.0.1=192.168.0.1}
192.168.0.2: {192.168.0.3=192.168.0.3, 192.168.0.1=192.168.0.1, 192.168.0.2=192.168.0.2}
/*********************** 举个例子 END ***********************/
// put new
for (String address: addressList) {
if (!lruItem.containsKey(address)) {
lruItem.put(address, address);
}
}
// remove old
List delKeys = new ArrayList<>();
for (String existKey: lruItem.keySet()) {
if (!addressList.contains(existKey)) {
delKeys.add(existKey);
}
}
if (delKeys.size() > 0) {
for (String delKey: delKeys) {
lruItem.remove(delKey);
}
}
// load
String eldestKey = lruItem.entrySet().iterator().next().getKey();
String eldestValue = lruItem.get(eldestKey);
return eldestValue;
} 故障转移
按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度
ExecutorRouteFailover.java->route();忙碌转移
按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度
ExecutorRouteBusyover.java->route();分片广播
广播触发对应集群中所有机器执行一次任务,同时传递分片参数;可根据分片参数开发分片任务
阻塞处理策略
为了解决执行线程因并发问题、执行效率慢、任务多等原因而做的一种线程处理机制,主要包括 串行、丢弃后续调度、覆盖之前调度,一般常用策略是串行机制
ExecutorBlockStrategyEnum.java
SERIAL_EXECUTION("Serial execution"), // 串行
DISCARD_LATER("Discard Later"), // 丢弃后续调度
COVER_EARLY("Cover Early"); // 覆盖之前调度
ExecutorBizImpl.java->run();
// executor block strategy
if (jobThread != null) {
ExecutorBlockStrategyEnum blockStrategy = ExecutorBlockStrategyEnum.match(triggerParam.getExecutorBlockStrategy(), null);
if (ExecutorBlockStrategyEnum.DISCARD_LATER == blockStrategy) {
// discard when running
if (jobThread.isRunningOrHasQueue()) {
return new ReturnT(ReturnT.FAIL_CODE, "block strategy effect:"+ExecutorBlockStrategyEnum.DISCARD_LATER.getTitle());
}
} else if (ExecutorBlockStrategyEnum.COVER_EARLY == blockStrategy) {
// kill running jobThread
if (jobThread.isRunningOrHasQueue()) {
removeOldReason = "block strategy effect:" + ExecutorBlockStrategyEnum.COVER_EARLY.getTitle();
jobThread = null;
}
} else {
// just queue trigger
}
} 单机串行
对当前线程不做任何处理,并在当前线程的队列里增加一个执行任务
丢弃后续调度
如果当前线程阻塞,后续任务不再执行,直接返回失败
覆盖之前调度
创建一个移除原因,新建一个线程去执行后续任务
运行模式
ExecutorBizImpl.java->run();BEAN
java里的bean对象
GLUE(Java)
利用java的反射机制,通过代码字符串生成实体类
IJobHandler originJobHandler = GlueFactory.getInstance().loadNewInstance(triggerParam.getGlueSource());
GroovyClassLoaderGLUE(Shell Python PHP Nodejs PowerShell)
按照文件命名规则创建一个执行脚本文件和一个日志输出文件,通过脚本执行器执行
失败重试次数
任务失败后记录到 xxl_job_log 中,由失败监控线程查询处理失败的任务且失败次数大于0,继续执行
任务超时时间
把超时时间给 triggerParam 触发参数,在调用执行器的任务时超时时间,有点类似HttpClient的超时时间
执行器(Exector)
注册自己的机器地址
注册项目中的 JobHandler
提供被调度中心调用的接口
public interface ExecutorBiz { /** * 供调度中心检测机器是否存活 * * beat * @return */ public ReturnTbeat(); /** * 供调度中心检测机器是否空闲 * * @param jobId * @return */ public ReturnT idleBeat(int jobId); /** * kill * @param jobId * @return */ public ReturnT kill(int jobId); /** * log * @param logDateTim * @param logId * @param fromLineNum * @return */ public ReturnT log(long logDateTim, long logId, int fromLineNum); /** * 执行触发器 * * @param triggerParam * @return */ public ReturnT run(TriggerParam triggerParam); }
总结
学到了什么
- 算法(LFU、LRU、轮询等)
- JDK动态代理对象(详细研究)
- 用到了Netty(详细研究)
- FutureTask
- GroovyClassLoader